pytorch LSTM的股价预测
股价预测一直以来都是幻想能够被解决的问题,本文中主要使用了lstm模型去对股价做一个大致的预测,数据来源是tushare,非常感谢tushare的数据!!
为什么要用LSTM?
LSTM是一种序列模型,是RNN中最典型的一个网络结构,对RNN做了一些改进同时具有RNN的特性,可以更好的处理时序数据。
如果可以实现对股价的预测,作为一个股民,可以更好的掌握买卖点,以及辅助自己做决策等等,以此提高自己的收益率。你可以合理地决定什么时候买股票,什么时候卖股票来获利。这就是时间序列建模的用武之地。你需要一个好的机器学习模型,它可以观察一系列数据的历史,并正确预测序列的未来元素是什么。
股票市场价格高度不可预测和波动。这意味着,在数据中没有一致的模式可以让你在一段时间内对股票价格进行近乎完美的建模。然而,我们不要一直认为这只是一个随机或随机的过程,机器学习是没有希望的。让我们看看您是否能够至少对数据建模,以便您所做的预测与数据的实际行为相关联。换句话说,你不需要确切的未来股票价值,而需要股票价格的变动(也就是说,如果它在不久的将来会上涨或下跌)。
import torch
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
import tushare as ts
from copy import deepcopy as copy
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
获取数据
获取数据部分使用了一个专业获取股票数据的第三方库:tushare
tushare非常强大,各种有关股票的数据都可以很方便的下载,甚至包括股票新闻数据。最近在搞NLP,下次有机会后尝试加入一些股票新闻和公司公告等文本信息帮助预测股票走势,应该会有较大提升。
老版本:http://tushare.org/
新版本:https://tushare.pro/

我这里仅仅是做了一个demo,仅供参考思路,并没有用到过多的股票数据特征所以就使用了老版本的历史行情数据接口API:ts.get_hist_data(stock_id)
更多信息详见官网:

这里我使用了开盘价、收盘价、最高价、最低价、成交量这五个特征,使用每天的收盘价作为学习目标,每个样本都包含连续几天数据作为一个序列样本,处理出训练集和测试集。
class GetData:
def __init__(self, stock_id, save_path):
self.stock_id = stock_id
self.save_path = save_path
self.data = None
def getData(self):
self.data = ts.get_hist_data(self.stock_id).iloc[::-1]
self.data = self.data[["open", "close", "high", "low", "volume"]]
self.close_min = self.data['close'].min()
self.close_max = self.data["close"].max()
self.data = self.data.apply(lambda x: (x - min(x)) / (max(x) - min(x)))
self.data.to_csv(self.save_path)
# self.data = self.data.apply(lambda x: x-min(x)/(max(x)-min(x)))
return self.data
def process_data(self, n):
if self.data is None:
self.getData()
feature = [
self.data.iloc[i: i + n].values.tolist()
for i in range(len(self.data) - n + 2)
if i + n < len(self.data)
]
label = [
self.data.close.values[i + n]
for i in range(len(self.data) - n + 2)
if i + n < len(self.data)
]
train_x = feature[:500]
test_x = feature[500:]
train_y = label[:500]
test_y = label[500:]
return train_x, test_x, train_y, test_y搭建LSTM模型
使用了一个单层单向lstm网络,加一个全连接层输出。
class Model(nn.Module):
def __init__(self, n):
super(Model, self).__init__()
self.lstm_layer = nn.LSTM(input_size=n, hidden_size=128, batch_first=True)
self.linear_layer = nn.Linear(in_features=128, out_features=1, bias=True)
def forward(self, x):
out1, (h_n, h_c) = self.lstm_layer(x)
a, b, c = h_n.shape
out2 = self.linear_layer(h_n.reshape(a*b, c))
return out2训练与测试
训练
还是pytorch训练三部曲:
- 计算损失loss
- 损失 backward
- 优化器 step
(不要忘记优化器清零梯度)
def train_model(epoch, train_dataLoader, test_dataLoader):
# 训练模型
best_model = None
train_loss = 0
test_loss = 0
best_loss = 100
epoch_cnt = 0
for _ in range(epoch):
total_train_loss = 0
total_train_num = 0
total_test_loss = 0
total_test_num = 0
for x, y in tqdm(train_dataLoader,
desc='Epoch: {}| Train Loss: {}| Test Loss: {}'.format(_, train_loss, test_loss)):
x_num = len(x)
p = model(x)
# print(len(p[0]))
loss = loss_func(p, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item()
total_train_num += x_num
train_loss = total_train_loss / total_train_num
for x, y in test_dataLoader:
x_num = len(x)
p = model(x)
loss = loss_func(p, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_test_loss += loss.item()
total_test_num += x_num
test_loss = total_test_loss / total_test_num
# early stop
if best_loss > test_loss:
best_loss = test_loss
best_model = copy(model)
epoch_cnt = 0
else:
epoch_cnt += 1
if epoch_cnt > early_stop:
torch.save(best_model.state_dict(), '../data/lstm_.pth')
break测试
测试部分很简单,我就不赘述了
def test_model(test_dataLoader_):
pred = []
label = []
model_ = Model(5)
model_.load_state_dict(torch.load("../data/lstm_.pth"))
model_.eval()
total_test_loss = 0
total_test_num = 0
for x, y in test_dataLoader_:
x_num = len(x)
p = model_(x)
print('##', len(p), len(y))
loss = loss_func(p, y)
total_test_loss += loss.item()
total_test_num += x_num
pred.extend(p.data.squeeze(1).tolist())
label.extend(y.tolist())
test_loss = total_test_loss / total_test_num
# print('##', len(pred), len(label))
return pred, label, test_loss可视化效果
可视化了一下,绿线预测,蓝线是真实数据,在真实曲线上加了短的红线作为趋势预测。
def plot_img(data, pred):
# plt.figure(figsize=(18, 9))
plt.plot(range(len(pred)), pred, color='green')
# plt.plot(range(len(data)), data)
plt.plot(range(len(data)), data, color='b')
for i in range(0, len(pred)-3, 5):
price = [data[i]+pred[j]-pred[i] for j in range(i, i+3)]
plt.plot(range(i, i+3), price, color='r')
plt.xlabel('Date', fontsize=18)
plt.ylabel('Close', fontsize=18)
plt.show()代码跑起来
if __name__ == '__main__':
# 参数
days_num = 5
epoch = 20
fea = 5
batch_size = 20
early_stop = 5
# 初始化模型
model = Model(fea)
# 数据处理部分
GD = GetData(stock_id='000963', save_path='../data/data.csv')
x_train, x_test, y_train, y_test = GD.process_data(days_num)
# print(x_train)
x_train = torch.tensor(x_train)
x_test = torch.tensor(x_test)
y_train = torch.tensor(y_train)
y_test = torch.tensor(y_test)
train_data = TensorDataset(x_train, y_train)
train_dataLoader = DataLoader(train_data, batch_size=batch_size)
test_data = TensorDataset(x_test, y_test)
test_dataLoader = DataLoader(test_data, batch_size=batch_size)
# 损失函数和优化器
loss_func = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_model(epoch, train_dataLoader, test_dataLoader)
p, y, test_loss = test_model(test_dataLoader)
print(len(p), len(y))
# 画图
pred = [ele * (GD.close_max - GD.close_min) + GD.close_min for ele in p]
data = [ele * (GD.close_max - GD.close_min) + GD.close_min for ele in y]
plot_img(data, pred)
print(test_loss)
效果与总结
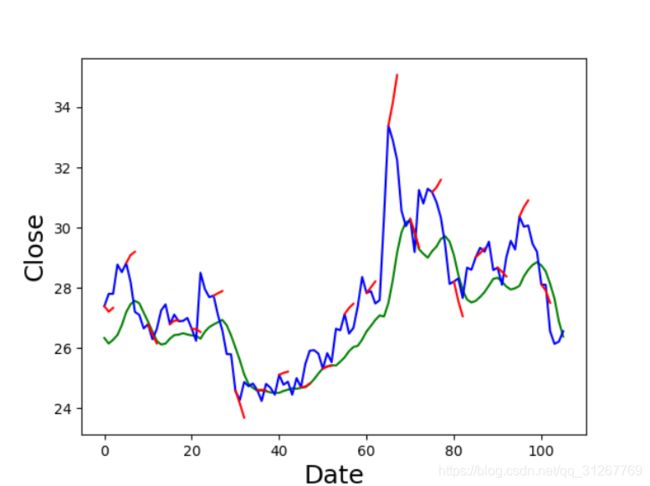
可以看到绿线是预测的曲线,蓝线是真实的曲线。绿线已经大致模仿出了蓝线的走势,感觉效果很不错,但是这当中存在一个很大的问题,如果我们把epoch调大,把earlystop去掉,让lstm完全的拟合这个曲线,其实远远没有过拟合,loss在波动的下降。会出现这样的情况:
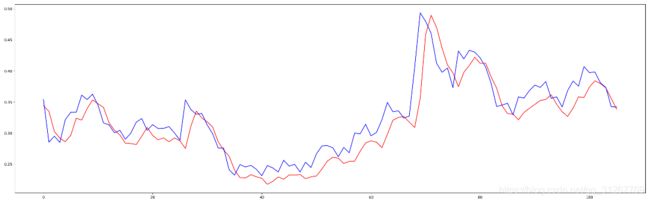
可以看到红线是预测的曲线,蓝线是真实的曲线,两条曲线的形状几乎是完全相同了。但是红线相对蓝线整体向右平行移动了一天。实际上网络学到的策略是,尽量把上一天的价格作为当前的预测输出,就是模型倾向于保留之前的趋势。这和人的想法很相似,对于一个股市小白来说,只给他开盘价、收盘价、最高价、最低价、成交量这五个特征,让他判断接下来股票走势,他也只能把之前的趋势当作下一天的趋势了。
这个模型只提供一个思路,不能作为股市实战的决策依据,谨慎使用。这个模型还有很多可以改进的地方,例如增加特征,给收盘价加个扰或者不使用收盘价作为特征,加入其他模态的信息,例如文本信息等等,也可以加入一些人工特征,例如爬取一些某股票全网点击量,搜索量等等。
或者换一个思路,训练一个分类模型判断上涨还是下跌,这样的准确率应该会好于回归的方式。我还看到一些博主提到波动率预测的思路,由于我对股票了解有限,还没有想到很好的方法,有思路欢迎补充。