Python-数据科学库-pandas基础
Pandas
- Pandas
-
- pandas常用数据类型
- 创建Series
- Series切片和索引
- 读取外部数据
- 创建DataFrame
- 基础属性
- 取行取列
- 缺失数据处理
- join
- merge
- 分组和聚合
- 索引和符合索引
-
- Series索引
- DataFrame符合索引
- 时间序列
- 重采样
Pandas
用来处理字符
pandas常用数据类型
Series:一维,带标签数组
DataFrame:二维,Series容器
创建Series
创建Series
import pandas as pd
a=pd.Series([1,7,8,9,10],index=list("abcde"))
print(a)
b_dict={
"name":"xiaohong","age":22}
b=pd.Series(b_dict)
print(b)
输出结果:
a 1
b 7
c 8
d 9
e 10
dtype: int64
name xiaohong
age 22
dtype: object
Series切片和索引
Series对象本质上由两个数组构成,一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键->值。ndarray的很多方法都可以运用于series类型,比如argmax,clip,series具有where方法,但是结果和ndarray不同
t[2:10:2]# 截取第2到8的元素 每隔2个取1个
t[1]
t[t>4]
t[[2,4,6]]#按照下标
t["a","f","g"]# 按照index
t.index#查看
t.value
读取外部数据
#读取读取CSV
pd.read_csv()
#读取MySQL
pd.read_sql()
创建DataFrame
c=pd.DataFrame(np.arange(12).reshape(3, 4))
print(c)
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
Dataframe时象既有行索引,又有列索引
行索引,表明不同行,横向索引 ,叫 index,0轴,axis-0
列索引,表名不同列,纵向索引,叫 columns,1轴,ais-1
#创建dataframe
d1={
"name":["xiaohong","xiangfang"],"age":[17,28]}
t= pd.DataFrame(d1)
print(t)
d2=[{
"name":"xiaohong","age":17},{
"name":"xiaolv","age":22}]
t= pd.DataFrame(d1)
print(t)
t= pd.DataFrame(d2)
print(t)
输出结果:
1 xiangfang 28
name age
0 xiaohong 17
1 xiangfang 28
name age
0 xiaohong 17
1 xiaolv 22
#创建dataframe为横纵坐标命名
t= pd.DataFrame(np.arange(12).reshape((3, 4)),
index=List(string. ascii_uppercase[: 3]), columns=list(string.ascii_uppercase[-4:]))
print(t)
输出结果:
W X Y Z
A 0 1 2 3
B 4 5 6 7
C 8 9 10 11
基础属性
df=pd.DataFrame(…)
df, shape#行数列数
df. dtypes#列数据类型
df,ndim#数据维度
df. index#行索引
df. columns#列索引
df. values#对象值,二维 ndarray数组
df.head(3)#显示头部几行,默认5行
df.tail(3)#显示末尾几行,默认5行
df.info()#相关信息概览:行数,列数,列索引,列非空值个数,列类型,列类型,内存占用
df. describe()#快速综合统计结果:计数,均值,标准差,最大值,四分位数,最小值
取行取列
#传入数字取行
df[:20]#取前20行
#传入字符串取列
df[first_labels]
也可以使用
df.loc 通过标签索引行数据
d.iloc 通过位置获取行数据
t= pd.DataFrame(np.arange(12).reshape((3, 4)),
index=List(string. ascii_uppercase[: 3]), columns=list(string.ascii_uppercase[-4:]))
print(t)
输出结果:
W X Y Z
A 0 1 2 3
B 4 5 6 7
C 8 9 10 11
print(t.loc["A","W"])
print(t.loc["A",["X","W"]])
print(type(t.loc["A",["X","W"]]))# dataframe每行是series
print(t.loc[["A","C"],["X","W"]])#A C两行的X W列
print(t.loc["A":"D",["X","W"]])#从A取到D包含D
输出结果:
0
X 1
W 0
Name: A, dtype: int32
<class 'pandas.core.series.Series'>
X W
A 1 0
C 9 8
X W
A 1 0
B 5 4
C 9 8
iloc和loc相似,只不过是将字符串换成了数字
布尔索引
#统计Animalname出现超过800次的数据
df[ df["Count_Animalname" ]>800]
# &且 |或 行标签长度大于4并且动物名出现超过700次的
df[(df["Row_Labels"].str.len ()>4)&(df["Count_Anima Lname"]>700)]

缺失数据处理
判断数据是否为NaN: pd.isnull(t), pd.notnull(t)
处理方式1:填充数据, t. fillna(t.mean()), t fianna(t.median()), t.fillna(0)
(只修改1列 t[“age”]=t["age].fillna(t.mean())…)
处理为0的数据:[t==0]= np.nan
处理方式2:删除nan所在的行列 drona(axis=0,how=‘any’, inplace=False)#inplace 原地替换
计算平均值等情况,nan是不参与计算的,但是0会
join
join默认情况下他是把行索引相同的数据合并到一起
t1.join(t2)以t1的行数为准
t2.join(t1)以t2的行数为准
merge
merge按照指定的列把数据按照一定的方式合并到一起
inner,交集 默认的合并方式
outer 并集,NaN补全
merge left,左边为准,NaN补全
merge right,右边为准,NaN补全

分组和聚合
grouped =df. groupby(by="columns_name")
#grouped是一个 Dataframe groupby.对象,是可迭代的
#grouped中的每一个元素是一个元组元组里面是(索引(分组的值),分组之后的 Dataframe
Dataframegroupby的方法:

grouped =df. groupby(by="columns_name").count()
索引和符合索引
Series索引
获取 lindex: df.index
指定 index: dfindex=[“x”,“y”]
重新设置 lindex:df. reindex(list(" abcedf")
实则是 dataframe进行取行指定某一列作为 index: df.set_index(" Country", drop= False)
返回 indexf的唯一值: df.set_index(" Country").index. unique0
drop为假表示之充当索引的列称依然保存为非索引列
swaplevel()用于交换索引的里外层 只适用于series 否则报错
import pandas as pd
df = pd.DataFrame({
'a': range(7),'b': range(7, 0, -1),'c': ['one','one','one','two','two','two', 'two'],'d': list("hjklmno")})
print(df)
df1=df.set_index(["c","d"])
print(df1)
df2=df.set_index(["c","d"],drop=False)
print(df2)
df3=df.set_index(["c","d"])["a"]#将c d 设为索引 获取a列后变成series
print(df3)
df4=df1["a"].swaplevel()#将索引由c d顺序 变为 d c从而可以直接拿内层索引
print(df4["h"])
输出结果
a b c d
0 0 7 one h
1 1 6 one j
2 2 5 one k
3 3 4 two l
4 4 3 two m
5 5 2 two n
6 6 1 two o
a b
c d
one h 0 7
j 1 6
k 2 5
two l 3 4
m 4 3
n 5 2
o 6 1
a b c d
c d
one h 0 7 one h
j 1 6 one j
k 2 5 one k
two l 3 4 two l
m 4 3 two m
n 5 2 two n
o 6 1 two o
c d
one h 0
j 1
k 2
two l 3
m 4
n 5
o 6
Name: a, dtype: int64
c
one 0
Name: a, dtype: int64
DataFrame符合索引
import pandas as pd
df = pd.DataFrame({
'a': range(7),'b': range(7, 0, -1),
'c': ['one','one','one','two','two','two', 'two'],'d': list("hjklmno")})
print(df)
df1=df.set_index(["c","d"])
print(df1)
df2=df1[["a"]].loc["one"]
print(df2)
df3=df1[["a"]].loc["one"].loc["h"]#结果仍旧是dataframe
print(df3)
df4=df1[["a"]].swaplevel().loc["h"]
print(df4)
输出结果:
a b c d
0 0 7 one h
1 1 6 one j
2 2 5 one k
3 3 4 two l
4 4 3 two m
5 5 2 two n
6 6 1 two o
a b
c d
one h 0 7
j 1 6
k 2 5
two l 3 4
m 4 3
n 5 2
o 6 1
a
d
h 0
j 1
k 2
a 0
Name: h, dtype: int64
a
c
one 0
时间序列
生成时间戳
pd.date_range(start, end, periods ,freq)
start和end以及freq配合能够生成 start和end范围内以频率freq的一组时间索引
start和 periods以及freq配合能够生成从start开始的频率为freq的 periods个时间索引
生成时间段
periods = pd.PeriodIndex(year=data["year"],
month=data["month"],day=data["day"],hour=data["hour"],freq="H")
freq参数

重采样
指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降釆样,低频率转化为高频率为升采样。pandas提供了一个 resample的方法来帮助我们门实现频率转化
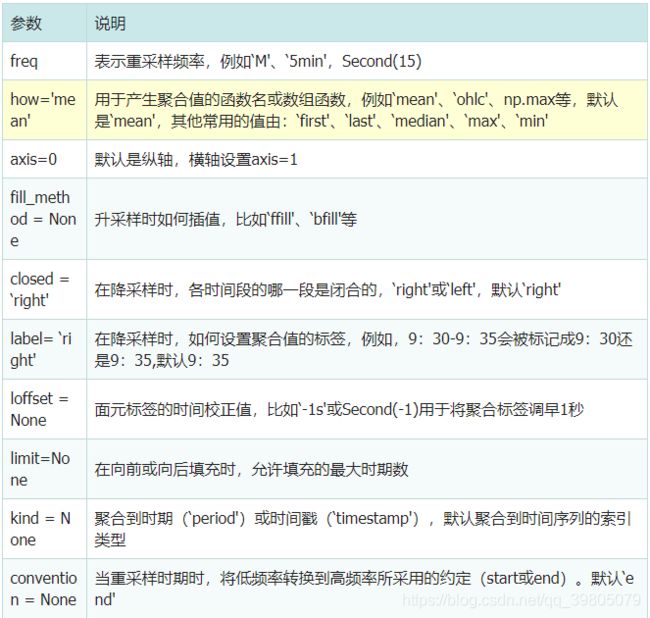
resample参数
DataFrame.resample(
rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start',
kind=None, loffset=None, limit=None, base=0)