【Python】爬虫案例——租房网站房间信息的全量抓取
这里对爬虫的基础知识就不过多的阐述了,直接上案例。当数据需求被激发后,怎样利用爬虫技术区获取数据?那么,顺藤摸瓜是最好的方法。所需数据是互联网数据吗?该数据是公开的吗?数据是什么格式?数据的位置有什么规则?简单说,把目标网站的结构摸透,写爬虫规则便完全没问题。其他的就看个人的‘修炼’,怎样摆脱网站的反爬虫机制了!
获取代理IP
在爬虫中,代理IP是高频词。它能隐藏爬取者的真实IP,避免真实IP被封禁的发生。代理IP在各大网站有免费的(质量较差),当然,也能花钱买到高质量的代理IP。这里给大家分享一个从西刺代理获取大量免费代理IP的爬虫代码块:
`
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
import random
import time
import numpy as np
start=int(input("从第几页开始爬取代理IP?请输入起始页数值:"))
end=int(input("在第几页结束爬取代理IP?请输入结束页数值:"))
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
url_1 = 'https://www.xicidaili.com/nn/'
#https://www.xicidaili.com/nn/2
xc_ip_Pool=pd.DataFrame()
for i in range(start,end+1):
try:
print("爬取 总%d页 剩%d页......"%(end-start+1,end-i+1))
if i == 0:
url = url_1
else:
url=url_1+str(i)
requests.adapters.DEFAULT_RETRIES = 5
s = requests.session()
s.keep_alive = False
response_ip = s.get(url, headers=header)
soup_ip = BeautifulSoup(response_ip.text,'lxml')
xc_ip_=[]
for i in range(1,len(soup_ip.select('tr'))):
ip=soup_ip.select('tr')[i].find_all('td')[1].text
dk=soup_ip.select('tr')[i].find_all('td')[2].text
IP='http'+ip+':'+dk
Life_time=soup_ip.select('tr')[i].find_all('td')[8].text
Life_time1=int(re.compile(r'[0-9]*').findall(Life_time)[0])
Life_time2=re.compile(r'分钟|天').findall(Life_time)[0]
xc_ip_.append([IP,Life_time1,Life_time2])
xc_ip=pd.DataFrame(xc_ip_,columns=['IP','Life_time1','Life_time2'])
#关闭上一次服务器请求 释放内存
response_ip.close()
del(response_ip)
xc_ip_Pool=pd.concat([xc_ip_Pool,xc_ip],ignore_index=True)
time.sleep(random.randint(3,5))
except Exception:
print('An error or warning occurred:')
finally:
time.sleep(random.randint(2,5))
xc_ip_Pool.to_excel("西刺代理池.xlsx",index=False)#将代理ip存入本地路径
print("爬取取结束,已建立西刺代理池: xc_ip_Pool ,约计%d条IP!"%(xc_ip_Pool.shape[0]))
`
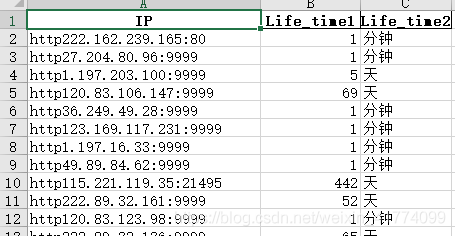
这里是爬取的部分西刺代理免费IP:
网页结构的探索
对网页结构探索的深度决定了爬取数据的准度,数据在网页中的位置规律被爬取者摸透了,爬到的数据才一定是我们在网页浏览时的可见数据。
探索网站服务的城市城区
为了能够深度爬取网站的各城区的租房数据,我们的从网站拿到各城区的网页链接。拿到URL后就能够嵌入爬虫框架中获取整个网站的全部城区的租房数据了。
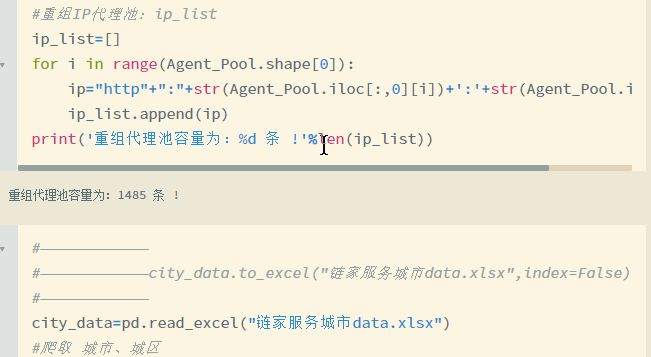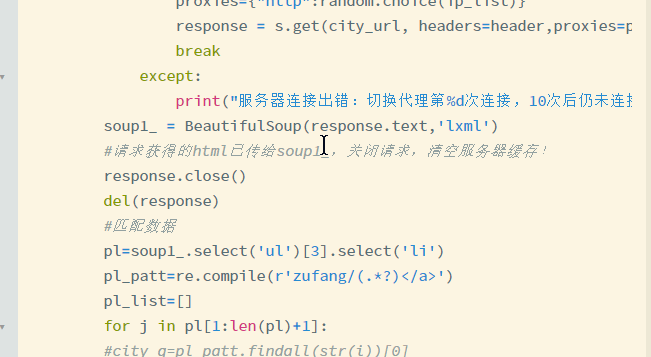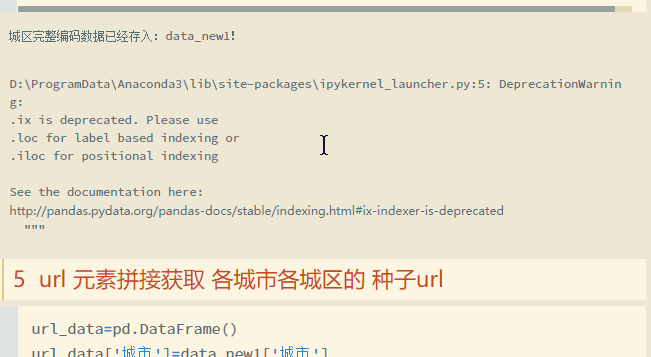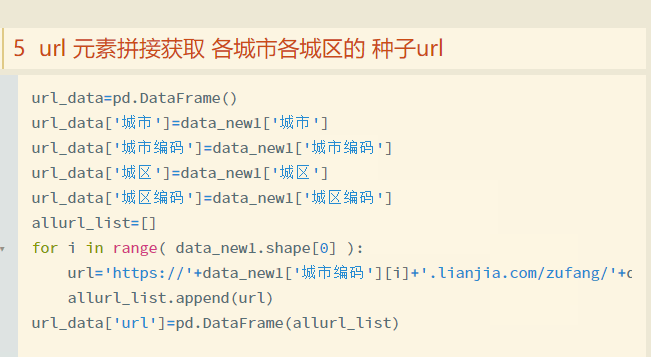
获得各城区的url列表如下。
创建爬虫框架
何谓爬虫框架?就当做是码代码了。这堆代码能够向网站发出并获得链接请求,然后解读获得html文件。最后从该文件中匹配并储存规整的目标数据为表到本地路径。
在堆代码的时候,至少要特别注意的问题是:
1.代理ip的替换
2.请求的最大重连接次数设置
3.关闭多余链接以及清空上次请求缓存
4.设置程序休眠时段
5.错误接收处理
6.空白网页的跳跃
7.爬取数据的暂存与合并
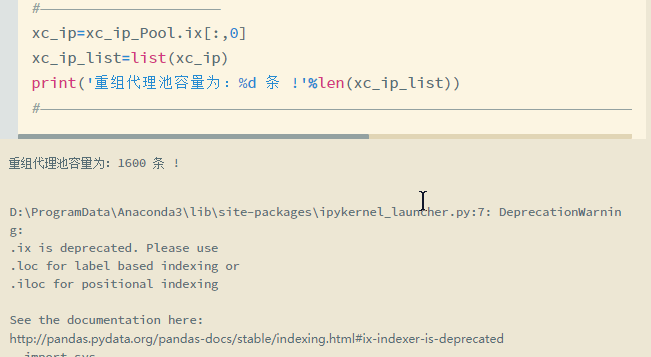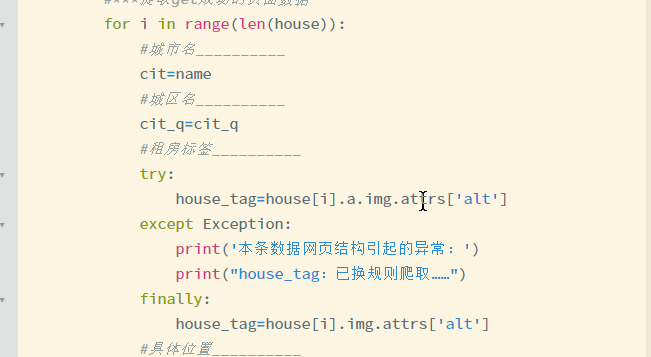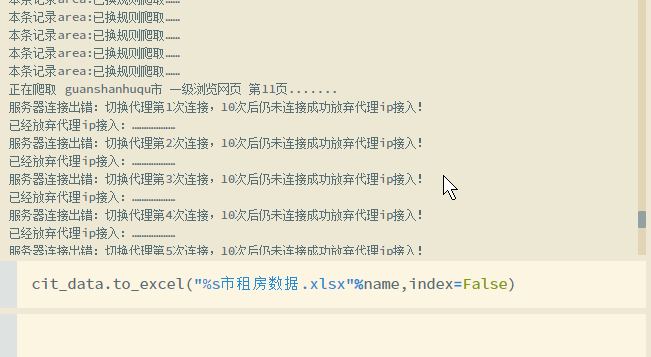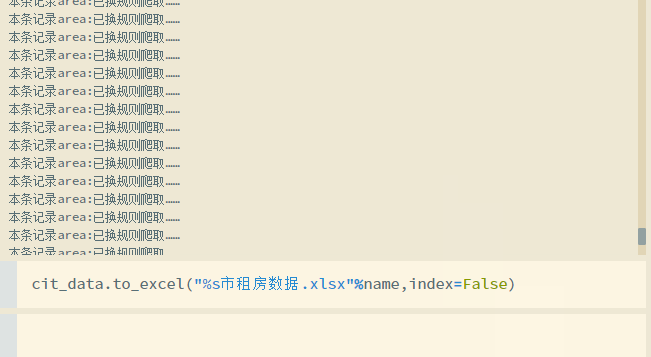
最后展示爬取的部分数据:
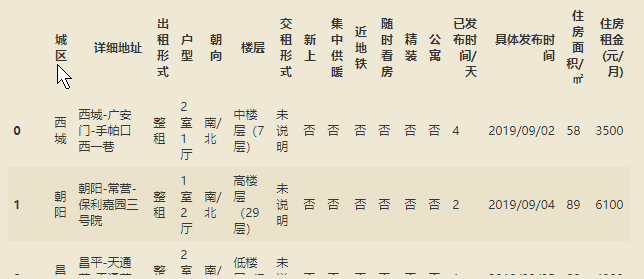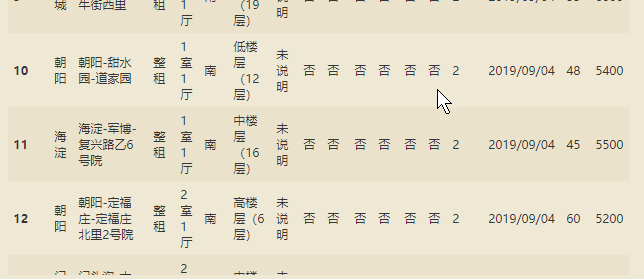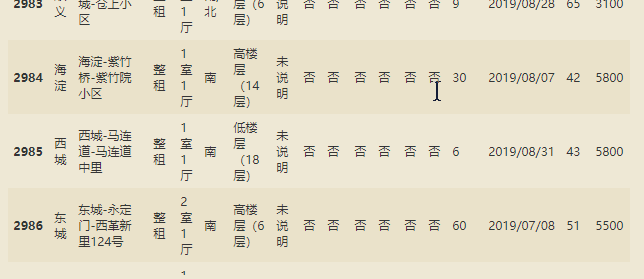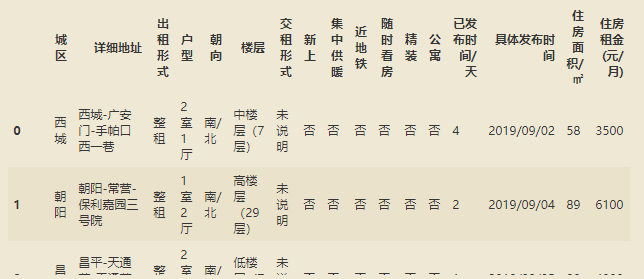
爬取的网页数据进行初步清洗,得到较为干净的数据:
对该网站的数据爬取到数据清洗也就基本完成了。在爬虫的框架构建中,要尽可能的模仿自然网页点击模式。也就是反反爬虫的机制要好,既然是爬虫,就要舍得时间,只要代码能正常工作,在能接受的时间段内,速度慢的像虫子一样的爬虫框架才是好的爬虫框架。好了,分享就到这里………………