十四、MapReduce中的Join操作
众所周知,MapReduce中最主要的两个过程是Map阶段和Reduce阶段,对于Join操作来说,当然也分Map Join和Reduce Join。本文主要介绍MapReduce中的Join操作,关注专栏《破茧成蝶——大数据篇》查看相关系列的文章~
目录
一、Reduce Join
1.1 Reduce Join工作原理
1.2 Reduce Join示例
1.2.1 需求与数据
1.2.2 首先定义Bean类
1.2.3 编写Mapper类
1.2.4 编写Comparator类
1.2.5 编写Reducer类
1.2.6 编写Driver驱动类
1.2.7 测试
二、Map Join
2.1 Map join介绍
2.2 Map Join示例
2.2.1 需求与数据
2.2.2 编写Mapper类
2.2.3 编写Driver驱动类
2.2.4 测试
一、Reduce Join
1.1 Reduce Join工作原理
Map端为来自不同表或文件的k/v对打标签以区分不同来源的记录。然后用连接字段作为key其余部分和新加的标志作为value,最后进行输出。Reduce端以连接字段作为key的分组已经完成,我们只需要在每个分组中将那些来源于不同文件的记录分来,最后进行合并就行了。
1.2 Reduce Join示例
1.2.1 需求与数据
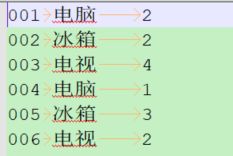
先来看看数据,此处有两个文件,一个是订单文件orders,一个是商品信息info,其中orders内容如下:

三列分别代表着订单id(id)、商品id(gid)、数量(amount)。下面再看一下info文件的内容:

两列分别代表着商品id(gid)和商品名称(name)。
现有如下需求:将info文件中的数据根据商品id合并到orders文件中。如果这两个文件是两张数据表的话,那么这个需求使用SQL来实现见如下语句:
select a.id, b.name, a.amount from orders a left join info b on a.gid = b.gid;如果我们使用代码要怎样实现呢?首先我们通过将关联条件作为Map端输出的key,将两表满足Join条件的数据并携带数据所来源的文件信息,发往同一个Reduce Task,在Reduce中进行数据的串联。具体实现代码及过程一起来看一下吧~
1.2.2 首先定义Bean类
package com.xzw.hadoop.mapreduce.join.reducejoin;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/16 11:24
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderBean implements WritableComparable {
private String id;
private String gid;
private int amount;
private String name;
@Override
public String toString() {
return id + '\t' + amount + "\t" + name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getGid() {
return gid;
}
public void setGid(String gid) {
this.gid = gid;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public int compareTo(OrderBean o) {
int compare = this.gid.compareTo(o.gid);
if (compare == 0) {
return o.name.compareTo(this.name);
} else {
return compare;
}
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(gid);
out.writeInt(amount);
out.writeUTF(name);
}
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF();
this.gid = in.readUTF();
this.amount = in.readInt();
this.name = in.readUTF();
}
}
1.2.3 编写Mapper类
package com.xzw.hadoop.mapreduce.join.reducejoin;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/16 11:30
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderMapper extends Mapper {
private OrderBean orderBean = new OrderBean();
private String fileName;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit fs = (FileSplit) context.getInputSplit();
fileName = fs.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
if (fileName.equals("orders")) {
orderBean.setId(fields[0]);
orderBean.setGid(fields[1]);
orderBean.setAmount(Integer.parseInt(fields[2]));
orderBean.setName("");
} else {
orderBean.setId("");
orderBean.setGid(fields[0]);
orderBean.setAmount(0);
orderBean.setName(fields[1]);
}
context.write(orderBean, NullWritable.get());
}
}
1.2.4 编写Comparator类
package com.xzw.hadoop.mapreduce.join.reducejoin;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* @author: xzw
* @create_date: 2020/8/16 11:43
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderComparator extends WritableComparator {
public OrderComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean oa = (OrderBean) a;
OrderBean ob = (OrderBean) b;
return oa.getGid().compareTo(ob.getGid());
}
}
1.2.5 编写Reducer类
package com.xzw.hadoop.mapreduce.join.reducejoin;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* @author: xzw
* @create_date: 2020/8/16 11:43
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderReducer extends Reducer {
@Override
protected void reduce(OrderBean key, Iterable values, Context context) throws IOException, InterruptedException {
//拿到迭代器
Iterator iterator = values.iterator();
iterator.next();//迭代器指针下移一位,获取第一个OrderBean中的name。
String name = key.getName();
while (iterator.hasNext()) {
iterator.next();//迭代器指针下移,获取需要写入的文件内容
key.setName(name);//替换掉原先的name内容
context.write(key, NullWritable.get());
}
}
}
1.2.6 编写Driver驱动类
package com.xzw.hadoop.mapreduce.join.reducejoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author: xzw
* @create_date: 2020/8/16 12:19
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"e:/input", "e:/output"};
Job job = Job.getInstance(new Configuration());
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
job.setGroupingComparatorClass(OrderComparator.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
1.2.7 测试

二、Map Join
2.1 Map join介绍
Map Join适用于一张小表,一张大表的场景。Map Join会将小表整个加载到内存,这种操作避免了数据倾斜的问题。下面以一个具体的例子来看一下这个过程吧。
2.2 Map Join示例
2.2.1 需求与数据
使用1.2.1中的数据,需求也跟之前的一样,唯一不同的是将info作为小表(此处只是为了做测试,所以实际场景中,要根据实际业务来区分)。
2.2.2 编写Mapper类
package com.xzw.hadoop.mapreduce.join.mapjoin;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.*;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
/**
* @author: xzw
* @create_date: 2020/8/16 13:40
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderMapper extends Mapper {
private Map map = new HashMap<>();
private Text text = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] cacheFiles = context.getCacheFiles();
String path = cacheFiles[0].getPath().toString();
//本地流
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(new FileInputStream(path)));
//HDFS流
// FileSystem fileSystem = FileSystem.get(context.getConfiguration());
// FSDataInputStream bufferedReader = fileSystem.open(new Path(path));
String line;
while (StringUtils.isNotEmpty(line = bufferedReader.readLine())) {
String[] fields = line.split("\t");
map.put(fields[0], fields[1]);
}
IOUtils.closeStream(bufferedReader);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
String name = map.get(fields[1]);
text.set(fields[0] + "\t" + name + "\t" + fields[2]);
context.write(text, NullWritable.get());
}
}
2.2.3 编写Driver驱动类
package com.xzw.hadoop.mapreduce.join.mapjoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
/**
* @author: xzw
* @create_date: 2020/8/16 12:19
* @desc:
* @modifier:
* @modified_date:
* @desc:
*/
public class OrderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"file:///e://input//info", "e:/input/orders", "e:/output"};
Job job = Job.getInstance(new Configuration());
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setNumReduceTasks(0);
//作为小表一次性全部读取到内存中
job.addCacheFile(URI.create(args[0]));
FileInputFormat.setInputPaths(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
2.2.4 测试
至此,本文就讲解完了,你们在这个过程中遇到了什么问题,欢迎留言,让我看看你们遇到了什么问题~