三十、Hive的数据类型以及常用的属性配置
上篇文章我们在服务器上部署了Hive并将它的Metastore存储在了MySQL上,本文介绍一下Hive的数据类型以及常用的一些属性配置。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
一、Hive的数据类型
1.1 基本数据类型
1.2 集合数据类型
1.2.1 介绍
1.2.2 示例
1.3 数据类型转换
二、常用的属性配置
2.1 HiveServer2服务
2.2 Hive的交互命令
2.3 Hive的其他命令
2.4 常用的属性配置
2.4.1 查询显示表头信息
2.4.2 显示当前数据库名称
2.4.3 配置Hive数据仓库位置
2.4.4 配置Hive运行日志信息存放位置
2.4.5 参数配置的优先级
一、Hive的数据类型
1.1 基本数据类型
Hive的基本数据类型有10种,如下所示:
| Hive数据类型 |
对应的Java数据类型 |
长度 |
| TINYINT |
byte |
1byte有符号整数 |
| SMALINT |
short |
2byte有符号整数 |
| INT |
int |
4byte有符号整数 |
| BIGINT |
long |
8byte有符号整数 |
| BOOLEAN |
boolean |
布尔类型,true或者false |
| FLOAT |
float |
单精度浮点数 |
| DOUBLE |
double |
双精度浮点数 |
| STRING |
string |
字符系列,可以指定字符集,可以使用单引号或者双引号。相当于数据库的varchar类型 |
| TIMESTAMP |
|
时间类型 |
| BINARY |
|
字节数组 |
1.2 集合数据类型
1.2.1 介绍
| 数据类型 |
描述 |
语法示例 |
| STRUCT |
通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{one STRING, two STRING},那么第1个元素可以通过字段.one来引用。 |
struct() 例如struct |
| MAP |
MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’one’->’xzw’和’two’->’yxy’,那么可以通过字段名[‘two’]获取最后一个元素 |
map() 例如map |
| ARRAY |
数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘one’, ‘two’],那么第2个元素可以通过数组名[1]进行引用。 |
Array() 例如array |
Hive有三种复杂数据类型STRUCT、ARRAY和MAP。STRUCT与C语言中的Struct类似,它封装了一个命名字段集合。ARRAY和MAP与Java中的Array和Map类似。复杂数据类型允许任意层次的嵌套。
1.2.2 示例
1、现有如下的数据
[{
"name": "xzw",
"loc": ["qd" , "zb"],
"city": {
"ta": 4,
"qd": 3
}
"subject": {
"dm": "Python" ,
"reg": "bigdata"
}
},
{
"name": "yxy",
"loc": ["bj" , "sh"],
"city": {
"bj": 1,
"sh": 3
}
"subject": {
"dm": "Java" ,
"reg": "AI"
}
}]2、首先我们需要构造一下导入Hive中的数据文件,数据文件如下所示:
xzw,qd|zb,ta:4|qd:3,Python|bigdata
yxy,bj|sh,bj:1|sh:3,Java|AI值得注意的是,MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用“|”。构造好的test.txt文件放到/root/files目录下。

3、创建Hive表
create table test(
name string,
loc array,
city map,
subject struct
)
row format delimited fields terminated by ','
collection items terminated by '|'
map keys terminated by ':'
lines terminated by '\n'; 
4、加载数据到Hive表中
load data local inpath '/root/files/test.txt' into table test;
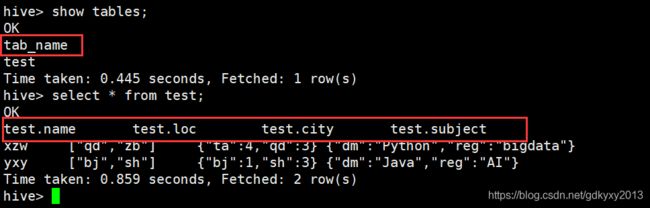
5、查询测试

1.3 数据类型转换
Hive的数据类型是可以进行隐式转换的,其规则如下:
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
(2)所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
(3)TINYINT、SMALLINT、INT都可以转换为FLOAT。
(4)BOOLEAN类型不可以转换为任何其它的类型。
(5)可以使用CAST操作显示进行数据类型转换。例如CAST('1' AS INT)将把字符串'1' 转换成整数1;如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。二、常用的属性配置
在讲解常用的属性配置之前,我们先来看一下怎样访问或者是连接Hive以及Hive常用的一些交互命令等,这对后续属性配置的讲解有一个打基础的作用。
2.1 HiveServer2服务
HiveServer2(HS2)是服务器接口,使远程客户端执行对Hive的查询和检索结果。换句话说,可以使用JDBC通过HiveServer2服务对Hive进行访问。以下便是如何开启HiveServer2服务。
1、首先通过以下命令启动HiveServer2服务:
hiveserver22、启动beeline
beeline
3、连接HiveServer2服务
通过以下命令连接HiveServer2服务:
!connect jdbc:hive2://master:10000
2.2 Hive的交互命令
可以通过如下命令,查看Hive都有哪些交互命令:
hive -help

常用的交互命令可以参考我的另外一篇博客:《Hive通过-f调用sql文件并进行传参》。
2.3 Hive的其他命令
1、在命令行查看hdfs文件系统
dfs -ls /;
2、在命令行查看本地文件系统
!ls /root/files;
3、查看在Hive中输入的历史命令
在根目录下有一个叫做.hivehistory的命令,如下图所示:

2.4 常用的属性配置
2.4.1 查询显示表头信息
在hive-site.xml中添加如下配置:
hive.cli.print.header
true
2.4.2 显示当前数据库名称
在hive-site.xml中添加如下配置:
hive.cli.print.current.db
true

2.4.3 配置Hive数据仓库位置
默认数据仓库的最原始位置是在hdfs上的/user/hive/warehouse路径下。在仓库目录下,没有对默认的数据库default创建文件夹。如果某张表属于default数据库,它会直接在数据仓库目录下创建一个文件夹。在hive-site.xml中添加如下配置解决此问题:
hive.metastore.warehouse.dir
/user/hive/warehouse/default
location of default database for the warehouse
并修改执行权限:
hdfs dfs -chmod g+w /user/hive/warehouse/default在default数据库中新建一张表进行测试:

可以发现在default数据库中新建的表都出现在了hdfs上的default目录下:

2.4.4 配置Hive运行日志信息存放位置
默认情况下,Hive的日志信息存放在/tmp/root/目录下:

修改hive-log4j.properties文件将日志信息放到指定位置,这里有个问题出现了,有的小伙伴发现在hive测conf目录下,没有这个配置文件,所以,在修改这个配置文件之前,还需要进行一步下面的操作:

此时,修改配置文件中的对应参数即可:

2.4.5 参数配置的优先级
在Hive的参数配置中,有三种参数的配置方式,分别如下。
1、通过配置文件。默认的配置文件是hive-default.xml,用户自定义的配置文件是hive-site.xml。用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。2、在命令行中通过set添加配置,例如:set mapred.reduce.tasks=100;。这种方式是临时修改配置文件,当Hive下次启动时,将会失效。3、在启动Hive时通过设置参数-hiveconf来设置,例如:hive -hiveconf mapred.reduce.tasks=10。同样的,这种方式是临时修改配置文件,当Hive下次启动时,将会失效。
上述三种设定方式的优先级为修改配置文件<命令行参数<参数声明。
本文到此就接近尾声了,你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题~