python初试——模拟登陆
许多网页必须先登录再抓取信息,也遇到了一个网站抓取不到内容,但在模拟登陆之后就抓到了内容。一开始模拟登陆也踩了坑,所以在这里以模拟登陆泰晤士报为例。
这里采用requests和lxml实现模拟登陆
1. 引入requests

2. 查看网页登录的请求内容

(可以使用错误的用户名密码登录,方便找到post)由此可见实际的请求url为https://login.thetimes.co.uk/
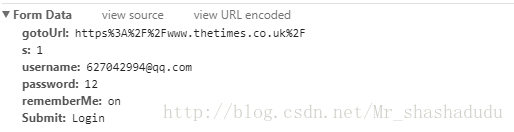
我们可以看到请求数据中包含【gotoUrl、s、username、password、rememberMe、Submit】这几部分内容,所以可以将这些写进我们的请求中
values = {
'gotoUrl': 'https%3A%2F%2Fwww.thetimes.co.uk%2F', 's': '1', 'username': '*****', 'password': '******', 'rememberMe': 'on', 'Submit': 'Login'}3.请求代码
URL_login= r'https://login.thetimes.co.uk/'
s = requests.session()
f= s.post(URL_login,data=values,headers = headers)使用requests的session方法登录,将url、values、headers写入。(默认头部是带有python的,可能会被网站识别为爬虫而遭拒绝,所以可以自己传入头部,比如自己使用的浏览器)
url = 'https://www.thetimes.co.uk'
html = s.get(url,headers = headers).content
root = etree.HTML(html.decode('utf-8','ignore'))之后就可以使用请求成功之后的session进入网站抓取所需的内容。具体代码可参考我的github