python电影评分数据分析
今天来试一个数据表连接及数据分析的小应用,步骤如下 :
1、 下载数据
2、 数据解读
3、 数据分析
4、总结
一、 下载数据
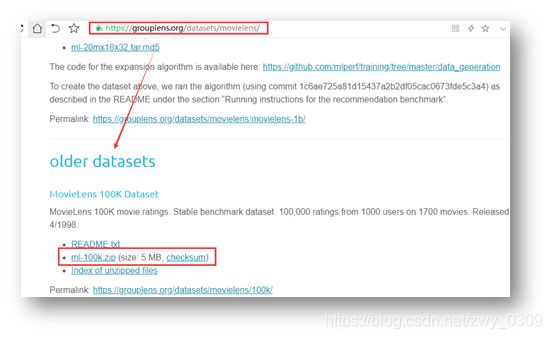
下载地址:https://grouplens.org/datasets/movielens/
下载内容:
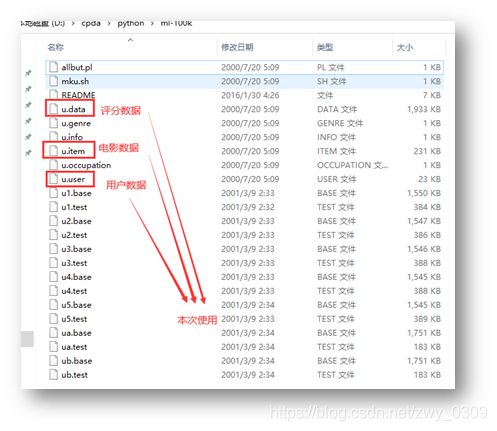
二、 数据解读
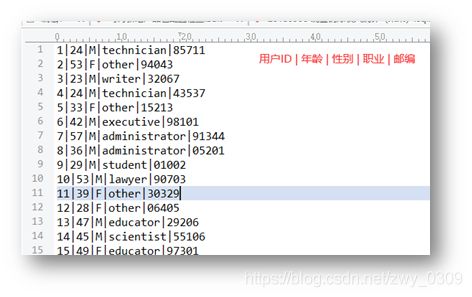
1、用户表:
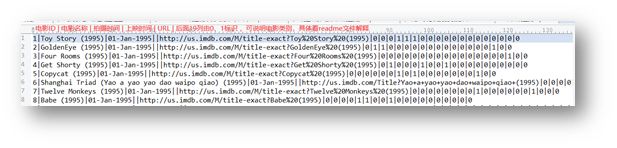
2、电影表
3、评分表
三、 数据分析
首先读入数据,该数据的文件类型与平时我们看到的不一样,但pandas的read_table可直接读取该类文件,方法如下:
【脚本】
ucolName = ['userId', 'age', 'gender', 'occupation', 'zip']
user = pd.read_table(r'D:\cpda\python\ml-100k\u.user', sep='|', header=None, names=ucolName)
print(user.head(2)) #取前2行看一下
【结果】
userId age gender occupation zip
0 1 24 M technician 85711
1 2 53 F other 94043
同理,读取评分文件并赋给变量ratings,表头为:
rColName = [‘userId’, ‘mID’, ‘rating’, ‘time’]
读取电影文件并赋给变量movies,表头为:
mColName = [‘mID’, ‘title’, ‘day1’, ‘day2’, ‘url’, ‘unkown’, ‘Action’,
‘Adventure’, ‘Animation’, ‘Children’, ‘Comedy’, ‘Crime’,
‘Documentary’, ‘Drama’, ‘Fantasy’, ‘Film-Noir’, ‘Horror’,
‘Musical’, ‘Mystery’, ‘Romance’, ‘Sci-Fi’,
‘Thriller’, ‘War’, ‘Western’ ]
【说明】
1、在读取电影文件时,如果read_table的参数同前两个文件的方式一样,则会报错“UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xe9 in position 3: invalid continuation byte”
解决方法有两种:
方法1:在setting Editor File Encodings Project Encoding框,选择成:ISO-8859-1
方法2:在代码中,增加参数encoding=‘ISO-8859-1’
2、如果想显示全部数据,则增加一句这样的代码:pd.set_option(‘display.max_rows’,None)
接下来做分析:
1、 查看男女评分的平均分,看是否有差异
【脚本】
print( frame['rating'].groupby(frame['gender']).mean() )
【结果】
gender
F 3.531507
M 3.529289
2、 按四舍五入的方法,将年龄每10岁分成一段,再看每个年龄段的评分
【脚本】
print(frame['rating'].groupby(frame['age'].apply(round, args=[-1])).mean())
【结果】
age
10 3.436195
20 3.484513
30 3.476950
40 3.594775
50 3.618863
60 3.660908
70 3.589212
【说明】
args=[-1]:表示四舍五入到十位。
3、 按四舍五入的方法,将年龄每10岁分成一段,再看每个年龄段不同性别的的评分
【脚本】
print(frame['rating'].groupby([frame['age'].apply(round, args=[-1]), frame['gender']] ).mean())
【结果】
age gender
10 F 3.327327
M 3.504726
20 F 3.440927
M 3.499035
30 F 3.479584
M 3.476111
40 F 3.701125
M 3.544587
50 F 3.533639
M 3.651328
60 F 3.600423
M 3.667023
70 F 3.239437
M 3.649635【说明】
注意:这时的groupby()中有两个参数,这两个参数是一个列表,所以需要写成groupby([字段1,字段2]),只是第一个字段增加了一个应用。
4、 按性别统计每部电影的平均得分,并且按从高到低的顺序排序
【脚本】
print(frame2['rating'].groupby( [frame2['title'], frame2['gender']] ).mean().sort_values(ascending=False))
【结果】
title gender
Faster Pussycat! Kill! Kill! (1965) F 5.0
Great Day in Harlem, A (1994) M 5.0
【说明】
这里的统计结构就是frame[‘待计算或排序的列名’].groupby([‘需要分组的列名’]).计算公式.排序
5、 按性别统计每部电影的平均得分和评分人数
【问题】
根据以上的统计结构,可以思考一下,这个评分人数的统计信息要放在哪里?显然这个属于计算公式,但是两个计算公式怎样放到一起呢?
【解答】
使用agg()方法可以集成多个聚合函数,该方法是DataFrame提供的。
【脚本】
print(frame2['rating'].groupby( [frame2['title'], frame2['gender']] ).agg(['mean','count']) )
【结果】
mean count
title gender
'Til There Was You (1997) F 2.200000 5
M 2.500000 4
1-900 (1994) F 1.000000 1
M 3.000000 4
【思考】
Agg()在调用多个聚合函数时,参数是个列表,且聚合函数后不再加括号,这一点是不是和apply()调用聚合函数时有点像?
6、 按性别统计每部电影的平均得分和评分人数,并且按平均得分从高到低的顺序
【问题】
仍根据“frame[‘待计算或排序的列名’].groupby([‘需要分组的列名’]).计算公式.排序”结构,思考排序多聚合函数的排序怎么处理呢?
是的,放到最后,用.sort_values(by=[],ascending=[])这样的结构处理
【脚本】
print(frame2['rating'].groupby( [frame2['title'], frame2['gender']] ).agg(['mean','count'])
.sort_values(by=['mean','count'],ascending=[False,True]) )
【结果】
mean count
title gender
Aiqing wansui (1994) M 5.0 1
Delta of Venus (1994) M 5.0 1
Entertaining Angels: The Dorothy Day Story (1996) M 5.0 1
7、 使用透视图
我们通过以下案列来逐步学习透视图的写法:
1)每部电影的男女评分情况,并按女性评分排序
【脚本】
print(frame2.pivot_table('rating', index='title', columns='gender', aggfunc='mean').sort_values(by='F', ascending=False))
【结果】
gender F M
title
Prefontaine (1997) 5.0 5.000000
Faster Pussycat! Kill! Kill! (1965) 5.0 2.666667
2)点评超过100次的电影的男女评分情况
【脚本】
rate_by_title = frame2.groupby('title').size()
print(frame2.pivot_table('rating', index='title', columns='gender', aggfunc='mean').loc[rate_by_title.index[rate_by_title > 100]])
【结果】
gender F M
title
101 Dalmatians (1996) 3.116279 2.772727
12 Angry Men (1957) 4.269231 4.363636
【说明】
size()与count()不同,count()会把各个列有多少行都统计出来,而size()只统计记录的个数,不按列统计。
结构是frame.pivot_table(‘待计算字段’,index=‘行’,columns=‘列’,aggfunc=‘计算方法’).loc[[索引]]
3)点评超过100次的电影的男女评分差值情况,按从大到小的顺序排列
【脚本】
rate_by_title = frame2.groupby('title').size()
frame3 = frame2.pivot_table('rating', index='title', columns='gender', aggfunc='mean').loc[rate_by_title.index[rate_by_title > 100]]
frame3['diff'] = (frame3['F'] - frame3['M']).apply('abs')
print(frame3.sort_values('diff',ascending=False))
【结果】
gender F M diff
title
Good, The Bad and The Ugly, The (1966) 3.187500 3.950413 0.762913
First Wives Club, The (1996) 3.491525 2.742574 0.748951
True Romance (1993) 3.000000 3.727273 0.727273
四、 总结
今天的知识点有点多,总结一下我个人认为较为重要的知识点:
分组聚合统计结构:frame[‘待计算或排序的列名’].groupby([‘需要分组的列名’]).agg([‘计算公式1’, ‘计算公式2’]).sort_values(by=[‘’,’’], ascending=[‘’,’’] )
透视表结构:frame.pivot_table(‘待计算字段’,index=‘行’,columns=‘列’,aggfunc=‘计算方法’).loc[[索引]]