Kafka文件存储机制
1、Kafka部分名词解释
在一套 Kafka 架构中有多个 Producer,多个 Broker,多个 Consumer,每个 Producer 可以对应多个 Topic,每个 Consumer 只能对应一个 Consumer Group。
整个 Kafka 架构对应一个 ZK 集群,通过 ZK 管理集群配置,选举 Leader,以及在 Consumer Group 发生变化时进行 Rebalance。

- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Segment:partition物理上由多个segment组成。
2、分析过程
- topic中partition存储分布
- partiton中文件存储方式
- partiton中segment文件存储结构
- 在partition中如何通过offset查找message
3、topic中partition存储分布
只有一个broker的情况
假设实验环境中kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka的broker中server.properties文件配置(参数log.dirs=xxx/message-folder),例如创建2个topic名 称分别为info_add、info_update, partitions数量都为partitions=4。
存储路径和目录规则为:
|–info_add-0
|–info_add-1
|–info_add-2
|–info_add-3
|–info_update-0
|–info_update-1
|–info_update-2
|–info_update-3
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
多broker分布的情况
Kafka集群partition replication,默认自动分配
(1)下面以一个Kafka集群中4个Broker举例,创建1个topic包含4个Partition,2 Replication;数据Producer流动如图所示:

(2)当集群中新增2个节点,Partition增加到6个节点时的分布情况如下:

副本分配逻辑规则
在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
上述图中的Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
上述图中每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
副本分配算法
将所有N个Broker和待分配的i个Partition排序。
将第i个Partition分配到第(i mod n)个Broker上。
将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上。
4、partiton中文件存储方式
下面示意图形象说明了partition中文件存储方式:
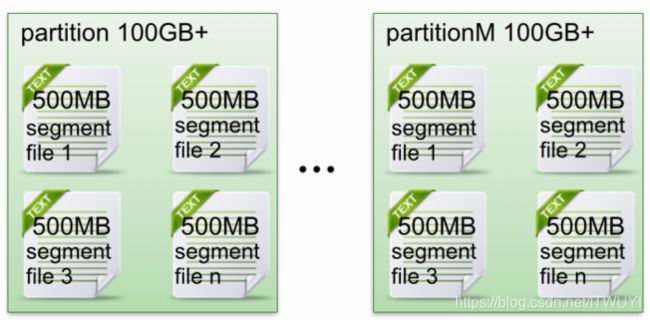
每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
5、partition中segment文件存储结构
下面深入分析partition中segment file组成和物理结构。
segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件。
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个全局partition的最大offset(偏移message数)。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
在Kafka broker上做一个实验,创建一个topicXXX包含1 partition,设置每个segment大小为500MB,并启动producer向Kafka broker写入大量数据,如下图所示的segment文件列表正好形象说明了上述2个规则:

以上述图中的一对segment file文件为例,说明segment中index<—->data file对应关系物理结构如下:

上述图中的索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
segment data file由许多message组成,下面详细说明message物理结构:

参数说明:

6、在partition中如何通过offset查找message
例如读取offset=368776的message,需要通过下面2个步骤查找。
(1)查找segment file
00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0。第二个文件00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1。同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset 二分查找文件列表,就可以快速定位到具体文件。
当offset=368776时定位到00000000000000368769.index|log。
(2)通过segment file 查找message
通过第(1)步定位到segment flie,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和 00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到 offset=368776为止。
这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
7、Kafka服务端配置及其优化
每个kafka broker中配置文件server.properties默认必须配置的属性如下:
broker.id=0
num.network.threads=2
num.io.threads=8
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=2
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=60000
log.cleaner.enable=false
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=1000000
server.properties中所有配置参数说明(解释)如下列表:

8、Kafka文件存储机制–实际运行效果
实验环境:
Kafka集群:由2台虚拟机组成
cpu:4核
物理内存:8GB
网卡:千兆网卡
jvm heap: 4GB
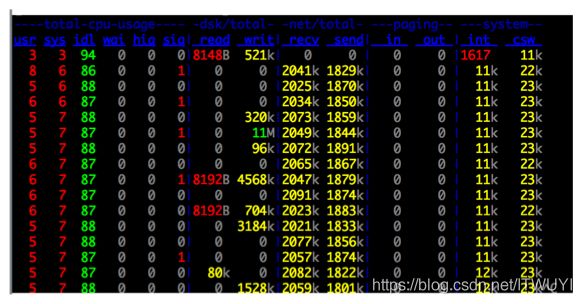
从上述图中可以看出基本没有大量读磁盘的操作,只有(定期批量)写磁盘操作。之所以操作磁盘这么高效,这跟Kafka文件存储设计中读写message是息息相关的。
Kafka中读写message有如下特点:
写message
(1)消息从java堆转入Page Cache(即物理内存)。
(2)由异步线程刷盘,消息从pagacache刷入磁盘。
读message
(1)消息直接从Page Cache(数据在虚拟内存)转入socket发送出去。
(2)当从Page Cache没有找到相应数据时,此时会产生磁盘IO,从磁盘Load消息到Page Cache,然后直接从socket发出去。
9、总结
Kafka高效文件存储设计特点
(1)Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
(2)通过索引信息可以快速定位message和确定response的最大大小。
(3)通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
(4)通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
参考:
https://www.open-open.com/lib/view/open1421150566328.html