撰文/ 李荣谦
编辑/ Ryan
来源:有道技术团队(ID: youdaotech)
0 序言
本期文章中,有道精品课技术团队将和大家分享有道精品课数据中台的架构演进过程以及 Doris 作为一个 MPP 分析型数据库是如何为不断增长的业务体量提供有效支撑并进行数据赋能的。
本文以我们在实时数仓选型的经验为切入点,进一步着重分享使用 Doris 过程中遇到的问题,以及我们针对这些问题所做出的调整和优化。
1 背景概述
1.1 业务场景
根据业务需求,目前有道精品课的数据层架构上可分为离线和实时两部分。
离线系统主要处理埋点相关数据,采用批处理的方式定时计算。而实时流数据主要来源于各个业务系统实时产生的数据流以及数据库的变更日志,需要考虑数据的准确性、实时性和时序特征,处理过程非常复杂。
有道精品课数据中台团队依托于其实时计算能力在整个数据架构中主要承担了实时数据处理的角色,同时为下游离线数仓提供实时数据同步服务。
数据中台主要服务的用户角色和对应的数据需求如下:
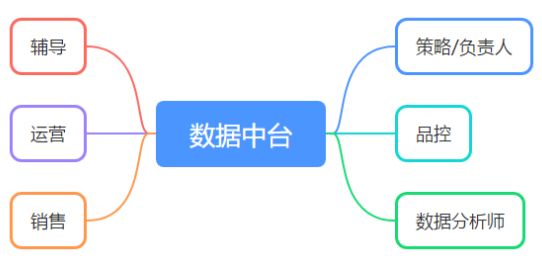
- 运营/策略/负责人主要查看学生的整体情况,查询数据中台的一些课程维度实时聚合数据;
- 辅导/销售主要关注所服务学生的各种实时明细数据;
- 品控主要查看课程/老师/辅导各维度整体数据,通过T+1的离线报表进行查看;
- 数据分析师对数据中台 T+1 同步到离线数仓的数据进行交互式分析;
1.2 数据中台前期系统架构及业务痛点
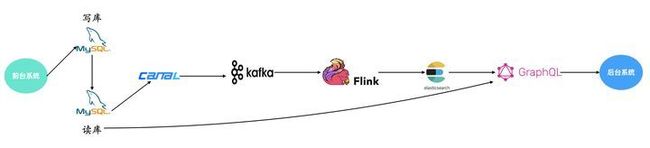
如上图所示,在数据中台1.0架构中我们的实时数据存储主要依托于 Elasticsearch,遇到了以下几个问题:
- 聚合查询效率不高
- 数据压缩空间低
- 不支持多索引的 join,在业务设计上我们只能设置很多大宽表来解决问题
- 不支持标准 SQL,查询成本较高
2、实时数仓选型
基于上面的业务痛点,我们开始对实时数仓进行调研,调研了 Doris、ClickHouse、TiDB+TiFlash、Druid、Kylin,考虑到查询性能、社区发展、运维成本等多种因素,我们最后选择 Doris 作为我们的实时数仓。

3、基于Apache Doris的数据中台2.0
3.1 架构升级
在完成了实时数仓的选型后,我们针对 Doris 做了一些架构上的改变,以发挥它最大的作用,主要分为以下几个方面:
>>>>Flink双写
将所有 Flink Job 改写,在写入Elasticsearch的时候旁路输出一份数据到 Kafka,并对复杂嵌套数据创建下游任务进行转化发送到 Kafka,Doris 使用 Routine Load 导入数据。

>>>>Doris On Es
由于之前我们的实时数仓只有 Es,所以在使用 Doris 的初期,我们选择了通过 Doris 创建 Es 外表的方式来完善我们的 Doris 数仓底表,同时也降低了查询成本,业务方可以无感知的使用数仓底表。

>>>>数据同步
原来我们使用 Es 的时候,由于很多表没有数据写入时间,数据分析师需要每天扫全表导出全量数据到 Hive,这对我们的集群有很大压力,并且也会导致数据延迟上升,我们在引入了 Doris 后,对所有数仓表都添加 eventStamp, updateStamp, deleted 这三个字段。
- eventStamp:事件发生时间
- updateStamp:Doris数据更新时间,在Routine Load中生成
- deleted:数据是否删除,由于我们很多实时数仓需要定时同步到离线数仓,所以数据需要采取软删除的模式。
数据同步我们采用了多种方式,通过 hive 表名后缀来决定不同同步场景:
- _f:每天/每小时全量同步,基于 Doris Export 全量导出
- _i:每天/每小时增量同步,基 于Doris Export 按分区导出/网易易数扫表导出
- _d:每天镜像同步,基于 Doris Export 全量导出

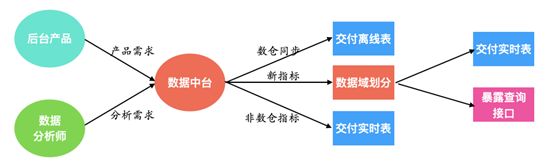
>>>>指标域划分/数据分层
将 Elasticsearch 中的数据进行整理并结合后续的业务场景,我们划分出了如下四个指标域:
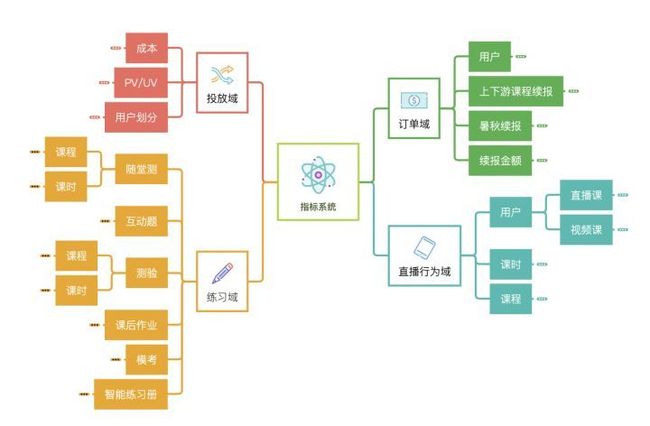
根据上面的指标域,我们基于星型模型开始构建实时数仓,在 Doris 中构建了20余张数仓底表以及10余张维表,通过网易易数构建了完整的指标系统。

>>>>定时生成 DWS/ADS 层
基于 Doris insert into select 的导入方式,我们实现了一套定时根据 DWD 层数据生成 DWS/ADS 层数据的逻辑,延迟最低可以支持到分钟级。

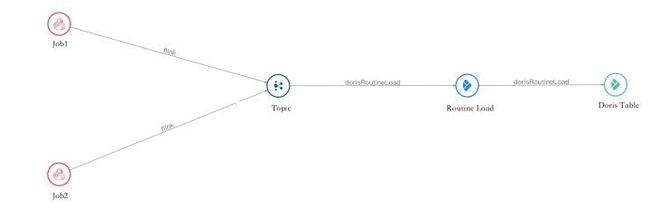
>>>数据血缘
我们基于 Routine Load 和 Flink 实现了数据中台完善的数据血缘,供数据开发/数据分析师进行查询。
3.2 数据中台2.0架构
基于围绕 Doris 的系统架构调整,我们完成了数据中台2.0架构:
- 使用网易易数数据运河替换 Canal,拥有了更完善的数据订阅监控
- Flink计算层引入 Redis/Tidb 来做临时/持久化缓存
- 复杂业务逻辑拆分至 Grpc 服务,减轻Flink中的业务逻辑
- 数据适配层新增 Restful 服务,实现一些 case by case 的复杂指标获取需求
- 通过网易易数离线调度跑通了实时到离线的数据同步
- 新增了数据报表/自助分析系统两个数据出口
数据中台2.0架构的数据流转如下图所示:

我们对数据中台整体架构进行梳理,整体结构如下图所示:

4、Doris带来的收益
1. 数据导入方式简单,我们针对不同业务场景使用了三种导入方式:
- Routine Load:实时异步数据导入
- Broker Load:定时同步离线数仓数据,用于查询加速
- Insert into:定时通过 DWD 层数仓表生成 DWS/ADS 层数仓表
2. 数据占用空间降低,由原来Es中的1T左右降低到了200G左右。
3. 数仓使用成本降低:
Doris 支持 Mysql 协议,数据分析师可以直接进行自助取数,一些临时分析需求不需要再将 Elasticsearch 数据同步到 Hive 供分析师进行查询。
一些在 Es 中的明细表我们通过 Doris 外表的方式暴露查询,大大降低了业务方的查询成本。
同时,因为 Doris 支持 Join,原来一些需要查询多个 Index 再从内存中计算的逻辑可以直接下推到 Doris 中,提升了查询服务的稳定性,加快了响应时间。
聚合计算速度通过物化视图和列存优势获得了较大提升。
5、上线表现
目前已经上线了数十个实时数据报表,在线集群的 P99 稳定在 1s 左右。同时也上线了一些长耗时分析型查询,离线集群的 P99 稳定在 1min 左右。
同时,也形成了一套完善的开发体系使数据需求的日常迭代更加迅速。


6、总结规划
Doris 的引入推进了有道精品课数据分层的构建,加速了实时数仓的规范化进程,数据中台团队在此基础上一方面向全平台各业务线提供统一的数据接口,并依托于 Doris 生产实时数据看板,另一方面定时将实时数仓数据同步至下游离线数仓供分析师进行自助分析,为实时和离线场景提供数据支撑。
对于后续工作的开展,我们做了如下规划:
- 基于Doris明细表生成更多的上层聚合表,降低Doris计算压力,提高查询服务的整体响应时间。
- 基于Flink实现Doris Connector,实现Flink对Doris的读写功能
- 开发Doris On Es支持嵌套数据的查询。
最后,感谢各业务方对数据中台的支持,目前数据中台还在迅速发展中,欢迎志同道合的朋友加入我们。