YOLOv5训练自己的数据集之详细过程篇
软硬件配置:Ubuntu + Tesla m40 24GB + cuda10.2 + anaconda
一、环境部署
1、源码下载
https://github.com/ultralytics/yolov5
2、环境配置
创建虚拟环境
source create -n yolov5 python=3.7
激活虚拟环境
source activate yolov5
安装依赖库(cd到yolov5根目录requirements.txt下)
pip install -r requirements.txt
or 清华镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
windows可能会出现以下错误:
ERROR: Could not find a version that satisfies the requirement torch>=1.6.0 (from -r requirements.txt (line 12)) (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)
ERROR: No matching distribution found for torch>=1.6.0 (from -r requirements.txt (line 12))
原因是pytorch和torchvision的下载需要,我们需另外下载
附pytorch和torchvision网盘链接:
链接:https://pan.baidu.com/s/1Rm69ehzWaVAXmbXk4LND6w
提取码:sd3m
Ubuntu上一切很顺利,不知道pytorch的安装是不是和系统有关
还素比较简单滴,集成好的依赖库就是香啊
二、训练yolov5
1、准备数据集
数据存放位置和数据结构
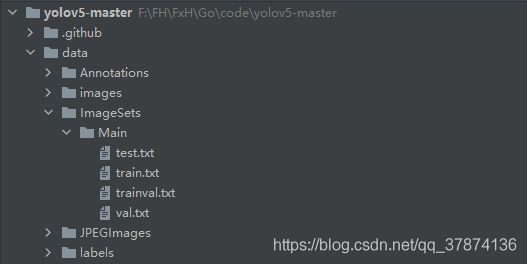
(1)新建如上图所示的文件夹,文件名要一致
(2)在JPEGImages中存放原图(可不用,只是为了保证完整格式)
(3)在image中存放原图
(4)在Annotations中存放xml格式的标签文件,每个xml文件对应JPEGImages的一张图片
(5)在ImageSets的Main文件夹下存放train.txt、val.txt 、trainval.txt、test.txt。分别存放的是训练集、验证集、训练集加验证集、测试集的图片名称,只包含名称不包含后缀和路径。这四个文件需要使用脚本生成。
import os
import random
trainval_percent = 0.8 # 训练集和验证集所占比例,剩下的0.2是测试集比例
train_percent = 0.8 # 训练集所占比例
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
trainval_percent = 0.8,train_percent = 0.8,可自己进行调整
(6)在labels中存放txt格式的标签信息,可用脚本读取Annotations生成txt
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['corner']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
2、修改文件
(1)修改数据集方面的yaml文件
打开yolov5/data/coco.yaml
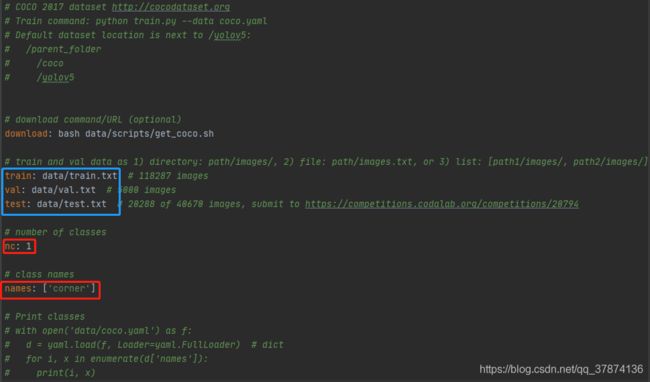 修改红框中的标签信息和蓝框中的路径
修改红框中的标签信息和蓝框中的路径
(2)修改网络参数方面的yaml文件
打开yolov5/models/yolov5l.yaml
yolov5s -> yolov5m -> yolov5l -> yolov5sx. 网络层数越深,宽度越宽
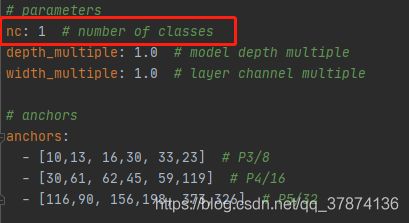
修改红框中的标签信息
也可以将anchor换成符合自己数据集的尺寸
(3)修改train中的一些参数
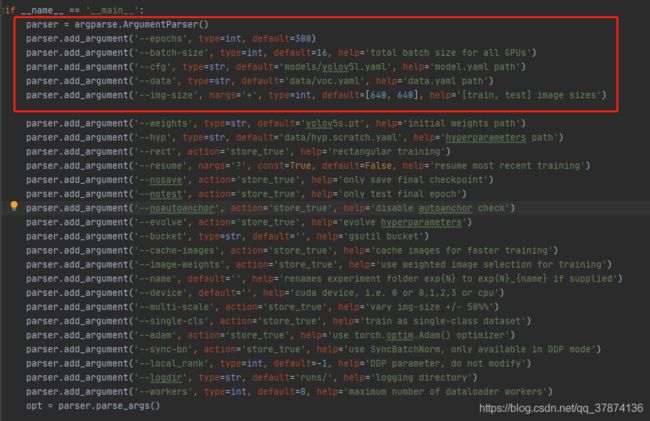 可自行调整红框中的参数和路径
可自行调整红框中的参数和路径
(据自身体验,img_size = 640效果最好)
3、训练模型
python train.py
等待~~~~~
模型保存在yolov5/runs/exp/weights,保存有best.pt和last.pt

三、检测模型
1、将需要检测的图片放在一个文件夹,修改yolov5/detect.py

黄框:模型路径
绿框:测试图片路径
蓝框:结果保存路径
2、可修改yolov5/utils/datasets.py,读取test.txt的检测图片路径进行检测

将黄框替换成红框即可
----------------------------------------------end----------------------------------------------------------