论文《Chinese NER Using Lattice LSTM》 心得总结
大家好,这是本人第一次认证撰写的一篇关于自然语言处理的文章,希望大家多多支持。谢谢啦。
这次分享的论文是《Chinese NER Using Lattice LSTM》, 标题中有两个关键字Chinese NER,Lattice LSTM.我们先来讲讲Chinese NER 。全称为Chinese Named Entity Recongination,即中文命名实体识别,这是自然语言处理中重要的任务之一。
1. NER 介绍
命名实体识别可以识别出文本中的实体边界和对应实体类型,同时可以将其添加到现有的知识库中。
文本中的实体包含充足的语义内容藐视一个重要的语言单元,命名实体识别从原始的文本中可恶意提取上述包含丰富语义的实体和实体指代项。,并将实体划分到对应的实体类型中。通常实体类型是人名,地名,组织名。例如在一段文本中“2015年10月获得诺贝尔生理学或医学奖,理由是她发现了青蒿素,这种药瓶可以降低疟疾患者的死亡率,她成为首个获得科学类诺贝尔奖的中国人”,文章包含有时间实体,医学实体,国家实体,人名实体总共六个命名实体,由此可见,命名实体是构建文本语义解析的重要组成部分。
1991 年,Rau 等人首次提出命名实体识别任务在第七届IEEE人工智能应用会议;将人工编写规则与启发式算法结合实现从自然文本中提取公司名称的命名实体。
1996年,命名实体识别作为信息抽取的子任务被引入MUC-6,随后被添加给各类的评测任务中;
这些任务数据集大多数针对英文文本,英文文本由于词与词之间存在空格的分割,可研究性比较高,现有的英文数据集的命名实体识别的准确度, 召回率,F1值均可以达到90%,由于中文必须对文本进行中文分词处理,相较于英文,中文命名实体识别难度较大。但是还是有该方面的研究者取得不俗的成绩。
综上所示,命名实体识别技术是自然语言处理的关键,通过命名实体的抽取和归类可以用于解决海量文本中数据冗余和数据爆炸问题,为当前的大数据环境下解决数据爆炸式增长问题提供新的思路。命名实体识别从最初的基于规则和基于字典的方法到传统机器学习再到现有的深度学习方法。命名实体识别方法不断提高非结构化文本转化为结构文本的质量与效率。
命名实体识别任务如果得到有效的处理,那么将为随后的实体消歧,知识库构建,机器翻译,自动问答等任务提供一个良好的基础。
命名实体识别最早由基于词典和规则的方法到传统的机器学习方法,后来到现有的基于深度学习的方法,一直到现有的bert预处理模型+微调模型和图神经网络等研究方法。技术发展趋势如下图所示:
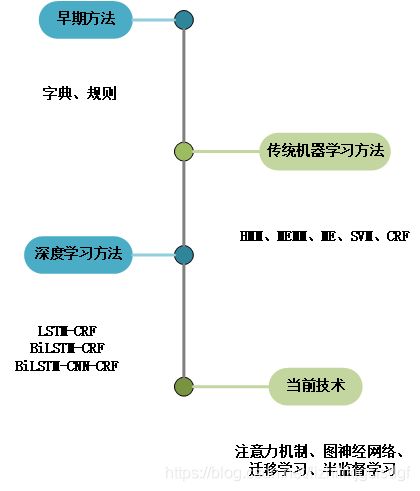
目前,NER的方法主要分为三大类。
1.1 基于规则方法
基于规则的方法和字典的方法式最初的实体识别的使用的方法,这些方法采用语言学家通过人工方式,依据数据特征的特定模板或者特定的词典,规则包含关键字,位置词,方位词,中心词,指示词,统计信息,标点符号,词典由特征的词典与外部词典共同组成,外部词典指已有的常识分词词典,制定好规则和词典之后,通常使用基于匹配的方法啊,对文本进行处理。但是基于规则方法不仅仅需要消耗巨大的人力,且不容易实现在其他数据集上迁移,即无法适应新的数据。大多数情况下是将基于规则和机器学习方法结合使用。
1.2 基于机器学习方法
基于传统的基于机器学习的方法,其中,命名实体识别被视为序列标注问题,与分类问题不一样,序列标注问题的当前预测不仅仅与当前的输入特征有关,而且与之前的预测标签有关,即预测标签序列之间存在相互依赖关系,采用传统机器学习的方法主要包含隐形马尔可夫模型,最大熵模型,最大熵马尔可夫模型,支持向量机模型。条件随机场模型等。
1.3 基于深度学习方法
基于深度学习的方法,深度学习模型不需要进行特征工程与领域知识,Collbert 首次提出基于神经网络的命名实体识别方法,该方法每个单词具有固有的窗口,单词标注取决于相邻单词,但是没有考虑到长距离单词之间的有效信息,为了克服限制,Chinu 和Nichols 提出基于双向LSTM-CNN架构,该架构会自动检测单词和字符界别的特征。摆脱传统方法的特征工程,有效考虑到单词的上下文。Ma和Hovy 京一部将其扩展到BiLSTM-CNN-CRF,将CRF模块添加用来优化序列标签。
深度学习神经网络是一种外绝潜在特征的多层神经网络。每一层输出是该语句一种的抽象表示,语言本省是一种抽象表达。因此在大量训练数据基础上生成基于向量的特征表示,利用神经网络进行NER任务是目前学者正在探索的方法,由于中英文语言特征的差异,中文命名实体识别首先是对文本进行分词,分词错误会导致在NER上错误累加。因此,已有证明基于字符的方法在中文NER上优于基于词的模型,不会导致分词错误累加是字符级模型的优势,但是从另一方面也是该方法的缺点,因为有些单词信息蕴含的词义信息可以使得字符级模型在识别实体时候产生歧义,例如南京市长江大桥,因此我们使用一种基于字和词混合的网格Lattice LSTM结构,这个结构能够实现对于句子中的专有名词进行识别,将潜在的单词信息整合到字符的LSTM CRF结构中。
1.4 NER 发展研究
现阶段,命名实体识别的研究难点分别式:垂直领域命名识别的局限性,命名实体表达的多样性与歧义性,命名实体的复杂性与开放性。这篇文章主要解决的就是第二个问题:减少命名实体表达的多样性与歧义性
2. Lattice LSTM模型
最近由于在处理字符级别信息与单词级别信息融合上有些问题,所以就去仔细阅读相关文献资料,于是发现《Chinese NER Using Lattice-LSTM》这篇文章。
目前英文NER模型效果最好的是LSTM-CRF, 对于中文NER,我们也可以使用这种模型,不过,中文文本不同于英文文本,需要对其进行分词(基于词的方法),尽管分词工具有很多(中科院ICTCLAS,哈工大语言云,Pyhton jieba和SnowNLP等),但是分词效果不可能是完美的
- 可能其中会出现各种分词方法不一致(尤其是在专业文本领域中:医疗命名实体识别)
- 可能分词结果会出现不统一的情况。即分词的细粒度不同。
简单来说,NER 就是通过序列标注对实体边界和实体类别进行预测,从而识别和提取相应的的命名实体,所以一旦出现分词错误,就会直接影响实体边界的预测,导致识别错误,这在开放域这种是个很严重的问题。
为了避免上述问题,研究者们开始尝试基于字符的方法,该方法不需要进行分词,以每个字符为单位进行训练,虽然训练集规模巨大,训练时间变长,但是研究表明,基于中文NER,基于字符的方法优于基于词的方法,但是可以想到,由于没有进行分词,所以基于字符的方法无法利用文本中的单词信息,这也会使得识别效果有瑕疵,举一个例子:比如一句话:"南京市长江大桥", 如果没有单词信息,识别结果很有可能为:“南京”,“市长”,“江大桥”。所以使用基于字符模型嫌弃信息少,使用基于基于单词模型又嫌弃有错误。
2.1 数据集介绍
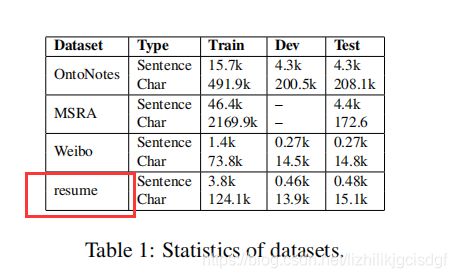
表1 表示的是这篇文章所用到的四个数据集,文章代码中只显示resume数据库,分别还有对应数据集的包含的语料类型,训练集,验证集和测试集的数据量。
- OntoNotes:新闻邻域语料 采用报告开发实验
- MSRA:新闻预料
- Weibo:数据集来自于社交媒体新浪微博
- resume:从新浪财经上获取的关于中文简历信息。其中包含中国股市上市公司高管的简历信息,本文随机选择1027个简历摘要,并且使用YEDDA系统手工标注8种命名实体。采用BMES实体标注方法,本文代码中提供的就是resume语料库
对于OntoNotes 和MSRA 数据集,训练中采用黄金分割标准

表2 显示的是resume 数据库中的统计的实体类型和各类实体数量,包含国家,教育机构。地点。人名,组织,职业,背景,指称八个实体类别,还有各个实体类别在训练集,验证集,测试集中的个数。整个resume数据集训练集有13438个实体,验证集有1497个实体,测试集有1620个实体。
2.2 传统模型介绍
好了,现在进入正文,本篇文章作者提出针对于中文命名实体识别提出一种网格结构的LSTM模型(Lattice LSTM),如下图所示,相较于基于字符的方法(characte-based),能够充分利用单词和词序两者信息,相较于词的方法(word-based),不会因为分词错误影响识别结果。为了清楚只管感受这几个模型结构的异同,我们先从基于字符模型开始。
为了准确提取命名实体,不仅仅需要语料选择合适的学习方法,还要给出特征集,丰富的特征工程可以提高模型的学习能力和识别准确率。特征工程对象有:字符特征,词性特征,词典特征。
2.2.1 基于字符的方法
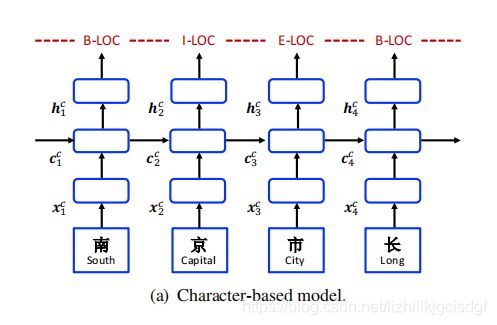
我们先来介绍一下基于字符的方法,下面图所示,输入文本都是中文字符,![]() 代表字符在embedding中的向量,通过LSTM模型得到当前时序的的状态信息
代表字符在embedding中的向量,通过LSTM模型得到当前时序的的状态信息![]() 与隐藏层信息
与隐藏层信息![]() ,当前时序状态
,当前时序状态![]() 作为下一个时序信息生成的输入,与此同时,隐藏层信息
作为下一个时序信息生成的输入,与此同时,隐藏层信息![]() 通过线并行变换得到对应的标签预测。标签预测方法为BMES字标注方法。下图显示的单项LSTM,没有显示具体的LSTM具体的门控单元信息,为的是达到简化图片的效果。
通过线并行变换得到对应的标签预测。标签预测方法为BMES字标注方法。下图显示的单项LSTM,没有显示具体的LSTM具体的门控单元信息,为的是达到简化图片的效果。
Char+bichar:
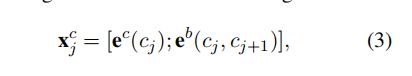
通过将字符与下一个字符组成二元结构进行嵌入向量表示,然后将上述特征表示与原有的字符表示进行凭借,得到输入向量。
Char+ softword(需要进行分词):

通过字符在词典中的标签的特征与原有字符的特征表示进行拼接,softward表示字符在词典的标签(BMES方法),得到输入向量。但是这边究竟得到是分词的类别标签还是边界标签,还是两个都有。我倾向第三个。
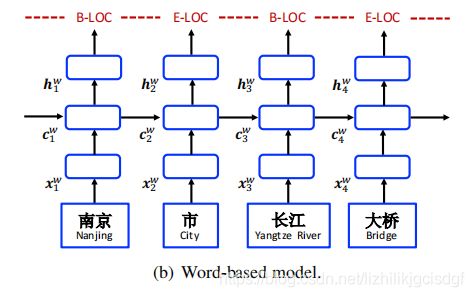
2.2.2 基于单词的方法
我们接下来聊一聊基于单词的方法,下图就是基于单词的模型示意图,输入![]() 均是经过处理过后的分词,所以
均是经过处理过后的分词,所以![]() 表达的是基于分词的特征表示。将这些各个时序中的
表达的是基于分词的特征表示。将这些各个时序中的![]() 输入LSTM模块中,得到两个输出:当前单词的单元状态输出和隐藏状态输出,当前单词单元状态输出将会作为下一个时序状态的信息输入
输入LSTM模块中,得到两个输出:当前单词的单元状态输出和隐藏状态输出,当前单词单元状态输出将会作为下一个时序状态的信息输入![]() ,隐藏状态信息
,隐藏状态信息![]() 则会通过线性变换得到相应的标签预测。
则会通过线性变换得到相应的标签预测。

上面公式表示单词序列特征表示来自两方面表示,一个是单词自生的特征表示,另一个是单词的字符特征表示
Word+ char LSTM
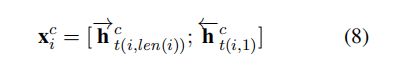
我个人理解这里是两层LSTM,第一层是计算每个词中所有字向量的输出作为公式7中的第二个元素,然后呢,公式8中的元素含义:第一个->第i个词最后一个字的正向的隐含层h;第二个->第i个词第一个字的反向的隐含层h。
上面模型使用双向LSTM学习关于字符的隐藏状态输出,t()中包含两个参数,第一个参数表示第几个单词,第二表示单词中的第几个字符。将上述学习得到单词中的字符表示与原有的单词表示进行融合。
Word + char CNN
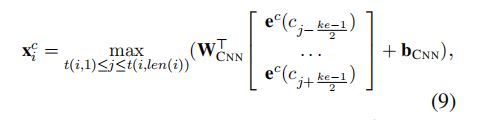
每个单词序列使用标准CNN结构,获得单词中的字符表示,超参数ke=3,一般窗口长度为3,采用最大池化提取特征信息。
最大池化的作用简要的介绍:主要优势是提升训练速度;
2.2.3 基于Lattice LSTM的方法

最终我们谈一下最终的Lattice LSTM模型,可以将它看作是基于字符的模型的扩展,整合基于单词的单元和用于控制信息流的附加门。模型的输入是一个字符序列。以及与词典D中的单词相互匹配的所有的字符子序列,词典D 是由自动分段的原始文本构建的D。该模型涉及四种类型的向量,即输入向量,输出向量,单元向量以及门向量(遗忘门,输出门,输入门)。
2.3 Lattice LSTM 具体架构
从上图可以看出,模型中的红色圈圈,也就是红色的Cell,他们是句子中潜在的词汇产生的信息(由词典D产生,有多个分词器操作取得交集。),同主干LSTM相应的Cell连接起来构成类似于网格的结构,也就是对应题目中的Lattice,那么红色的cell如何融入到主干LSTM呢?所以我们必须要看一下其中架构。
该模型的核心思想是:通过lattice LSTM表示句子中的词,将潜在的词汇信息融合到基于字符的LSTM-CRF模型,实际上,该模型的主干部分依然是基于字符的LSTM-CRF,只不过这个LSTM每个cell内部信息处理方式与基本的LSTM不一致。因此,只要理解这一点,就能掌握该模型的工作原理,下面是对于模型具体讲解。
这就需要我们先看LSTM模型和Lattice LSTM的模型的基本架构。
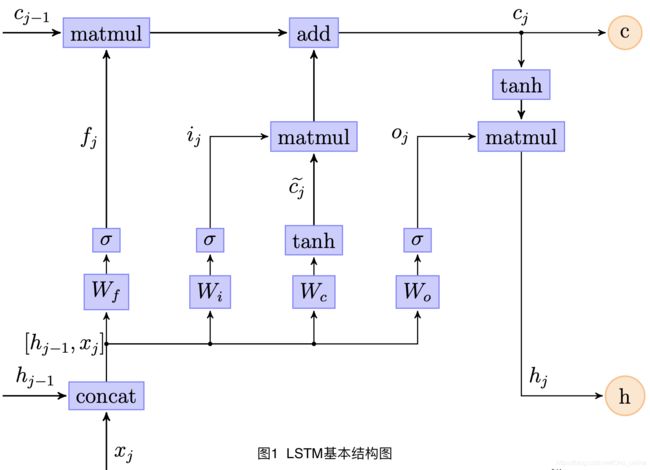
2.3.1 LSTM
如下图所示,基本LSTM结构中,每个Cell含有输入门因子,遗忘门因子和输入门因子,他们是0-1小数(默认激活函数为Sigmod),根据当前的输入和前一个Cell的输出计算得到的,还有一个核心元素就是Cell State (单元状态信息),也就是上面的从左到右的箭头,它从头走到尾。记录整个序列的信息,输入门决定当前的输入有多少加入Cell State;遗忘门决定Cell State 要保留多少信息,输出门决定更新后的CellState 有多少可以可以输入。
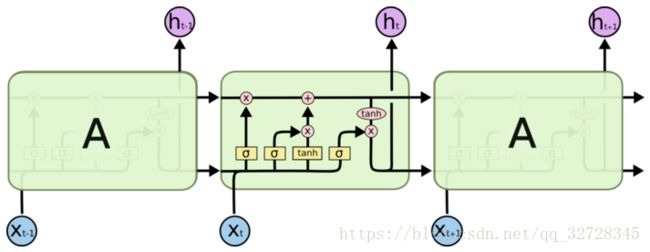
基本LSTM的Cell 内部算法结构如下,其中的参数,函数以及符号均为基础知识 ,可以参见我上一篇博客。
下面是LSTM单元运算的公式。
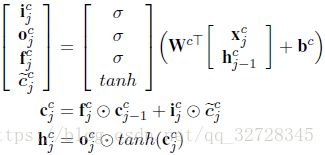
步骤解释:
- 将当前输入的字向量
 与上一步的隐藏层
与上一步的隐藏层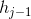 输入concat为[;]到LSTM 中,获得遗忘门因子
输入concat为[;]到LSTM 中,获得遗忘门因子 ,输入门因子
,输入门因子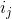 ,当前状态
,当前状态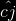 ,输出门因子
,输出门因子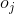 。
。 - 遗忘门因子通过sigmod函数激活当前的字向量和上一步隐藏信息的concat[;]。
- 输入门因子通过sigmod函数激活当前的字向量和上一步隐藏信息的concat[;]。
- 当前状态
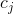 通过tanh函数操作当前的字向量和上一步的隐藏信息的concat[;]。
通过tanh函数操作当前的字向量和上一步的隐藏信息的concat[;]。 - 输出门因子通过sigmod函数激活当前的字向量和上一步隐藏信息的concat[;]。
- 通过遗忘门决定将上一状态
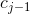 的输入程度。
的输入程度。 - 输入门因子与当前状态进行矩阵相乘。
- 将第六步与第七步进行相加,得到输出状态cj,对应上面第一个公式,最为下一步的状态信息输入。
- 将第八步得到的信息进行tanh操作,对应上面第二个公式,作为对现在时序信息的控制们因子。
- 将输出门因子与第九步结果进行矩阵相乘得到这一步隐藏层输入hj,作为下一步的隐藏状态信息。对应上面第二个公式。
2.3.2 Lattice LSTM

这里进行总结就是总共有三个LSTM结构,第一个lSTM是模型的主干结构,是基于字符的模型,主要任务是将上一个字符的信息作为输入得到两个输出,一个输出为当前时序的字符单元信息![]() ,用于接下来与第二个,通过遗忘门因子进行取舍。还有一个输出是当前字符的隐藏状态信息
,用于接下来与第二个,通过遗忘门因子进行取舍。还有一个输出是当前字符的隐藏状态信息![]() 。用于接下来与潜在的单词序列
。用于接下来与潜在的单词序列![]() 进行来进行链接。通过sigmod 函数进行激活得到遗忘门因子。同时得到当前的单词序列的状态信息和经过遗忘门的字符序列进行链接。
进行来进行链接。通过sigmod 函数进行激活得到遗忘门因子。同时得到当前的单词序列的状态信息和经过遗忘门的字符序列进行链接。
- 将当前输入的字向量
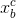 与上一步的隐藏层
与上一步的隐藏层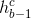 输入concat为[;]到LSTM 中,获得遗忘门因子
输入concat为[;]到LSTM 中,获得遗忘门因子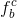 ,输入门因子
,输入门因子 ,当前状态
,当前状态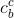 ,输出门因子
,输出门因子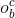 。
。 - 输入门因子通过sigmod函数激活当前的字向量和上一步隐藏信息的concat[;]
- 遗忘门因子直接取1-输入门因子
- 当前状态通过tanh函数操作当前的字向量和上一步的隐藏信息的concat[;]。
- 输出门因子通过sigmod函数激活当前的字向量和上一步隐藏信息的concat[;]。
- 通过遗忘门决定将上一状态的输入程度。
- 输入门因子与当前状态进行矩阵相乘。
- 将第六步与第七步进行相加,得到输出状态。
- 将第八步得到的信息进行tanh操作,得到隐藏状态信息
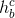 。
。 - 将输出门因子与第九步结果进行矩阵相乘得到这一步隐藏层输入。
- 将第十步结果与
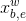 作为输入进行concat,作为[;]。
作为输入进行concat,作为[;]。 - Lattice LSTM遗忘门因子
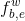 通过sigmod函数激活当前的词向量和上一步隐藏信息的concat[;]得到
通过sigmod函数激活当前的词向量和上一步隐藏信息的concat[;]得到 - Lattice LSTM输入门因子
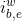 通过sigmod函数激活当前的词向量和上一步隐藏信息的concat[;]得到
通过sigmod函数激活当前的词向量和上一步隐藏信息的concat[;]得到 - Lattice LSTM当前状态
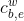 通过tanh函数操作当前的词向量和上一步隐藏信息的concat[;]得到
通过tanh函数操作当前的词向量和上一步隐藏信息的concat[;]得到 - Lattice LSTM的遗忘门因子与LSTM的输出进行矩阵相乘
- Lattice LSTM的输入门因子与Lattice LSTM当前状态进行矩阵相乘
- 将第十五步与第十六步操作进行相加
- 将与第三个LSTM输出结果
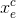 进行concat 操作
进行concat 操作 - 将第三个LSTM输出结果进行softmax操作得到
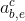
- 将第十九个步结果与进行矩阵相乘
- 将第三个LSTM输出结果进行softmax操作得到
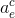
- 将第二十一步结果与第三个LSTM生成的当前字符信息进行矩阵相乘
- 将第二十二步结果与第二十步结果进行相加,得到最终的输出结果cce
- 将第三个LSTM输出的输出门因子与被tanh 函数激活后的输出结果cce进行矩阵相乘,得到最终的隐藏状态输出。
结论:门控循环允许我们模型从一个句子中选择最相关的字符和单词获得更好的实体识别效果。
回到本文的Lattice LSTM模型(截取部分进行说明),例如“桥”字,句子中的潜在的以它结尾的词汇有:“长江大桥”,“桥”,因此当前字符Cell除了“桥”以外,还要考虑到这两个词汇,从图上卡门就是两个红色Cell引出两个绿色箭头,代表了两个词汇的信息
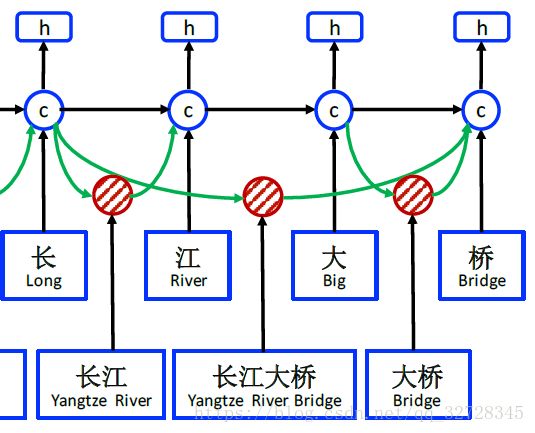
文章中对于词汇信息的算法如下图所示,每个词汇的红色Cell 类似于LSTM Cell且相互独立,因为序列标记是以字符为级别,所以这个Cell 中没有输出门,cell state 即为词汇信息。如上图所示,我们将通过匹配一个句子和一个自动获得的大词典来构建单词-字符格。因此,我们不需要分词器。
其中,矩阵中的x和h 分别表示词向量和词首字符Cell的输出
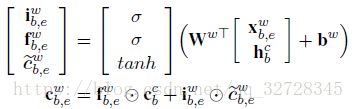
上面公式遗忘门因子负责遗忘前面的开头字符表示输入程度,输入门因子负责当前单词的状态信息输入程度,将两个进行相加得到新的单词特征表示。
根据LSTM的思想可知,这些词汇信息不会全部融入当前字符的Cell,因此要进行取舍,文章提出额外的门控单元(Addational Gate),根据当前字符和词汇信息来计算词汇信息权重。如下图公式所示。
其中,矩阵X和c 分别代表当前的字符向量和当前词汇的Cell State。
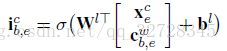
输入门因子是将当前最后的字符表示与单词表示进行融合,进行sigmod函数激活都得到的因子。
然后,文章提出一种归一化算法求出当前字符Cell各种输入的权重,类似于softmax函数,如下图公式所示,分母看起来有点复杂,其实就是句子中以当前词结尾的所有词汇的权重记忆当前字符输入门的求和(取以e 为底的指数使得结果为正)
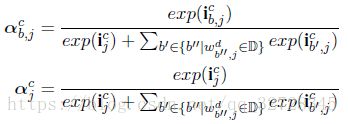
最后,当前字符的Cell State就可以算出来了

第一个是连加符号表示将所有当前字符作为结尾的单词特征表示,同时加上当前的字符作为
cc7 为桥的时候。icb,e 包含两个词的信息:IC6,7(大桥)和IC6,7(长江大桥),xc7我们是知道的向量计算出两个门之后,计算cc7时就是公式15了。相当与计算的时候不用公式11中上一个cc6了,而是使用之前的词信息,当j=6时候,不存在以大为结尾的词,也就不存在b ,那么公式15 的计算就是公式11了。


y 代表任意序列,w是CRF特有的boing参数。我们是哟那一阶维比特算法,在基于单词和基于字符的输入序列中找到得分最高的标签序列,给定一组标记的训练数据,使用带有正则花的几句子级别的对数似然函数 来寻连模型/
这里为什么没有遗忘门??,我的理解是:计算词汇信息时候用到主干Cell State,因此计算当前字符的Cell State时候通过门控单元来取舍词汇信息的过程中,其实就是在对主干Cell State 进行取舍,相当于隐藏的一个遗忘门。
2.4 Lattice LSTM 模型参数设置
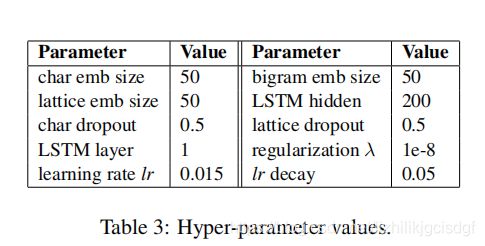
表3 显示的是模型中的超参数设置,可以看到char emb 和bigram emb size Lattice emb size 三个嵌入向量是一致的,为的是以后的特征融合更加方便。模型中LSTM只有一层。char dropout 和lattice drop都是取值0.5.
- lr decay(学习率衰减因子):
- regularization :
2.5 模型效果显示

表4 表示的是将目前的模型根据能否分词的判定进行划分,首先基于单词模型及其改进方法被划分到自动分词这个一部分,另一部分是Lattice LSTM模型和基于字符模型,有表可知,还是Lattice LSTM的整体指标要由于各个模型。数据集来自OntoNotes,但是之前我们看过的论文中显示基于字符的方法要优于基于单词的模型。但是这里面的结果并不是???
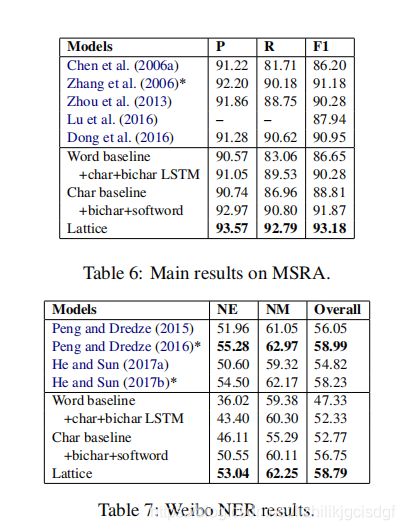
表六显示各个模型在MSRA数据集上的表现,可见本文模型LatticeLSTM无论是准确度还是召回率还是F1值,都是最好的。
表七显示各个模型在MSRA数据集上的表现,可见本文模型LatticeLSTM无论是准确度还是召回率还是F1值,都是最好的。
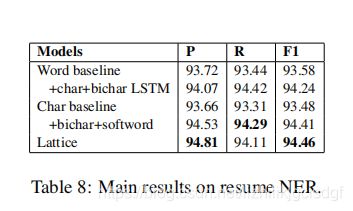
论文中表八显示各个模型在resume NER 数据集上的表现,可见本文模型的准确度和F1值是五个模型中最好的,但是召回率相较于Char+bichar+softword模型要差一点。
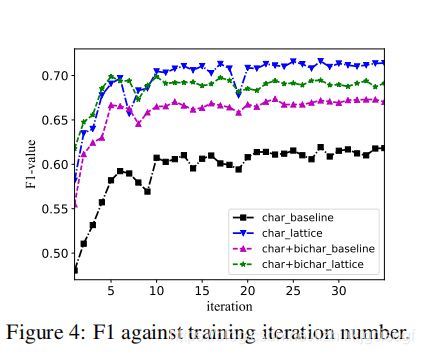
图四显示训练次数为四十轮中,各个模型的F1值的变化情况,明显的是,基于字符的极限模型效果是最差的,但是本文模型Lattice LSTM相比较于char+bichar_lattice和char+bichar两个模型要高出一点。

图五显示以输入文本长度为变量,比较各个方法的F1值的变化,由此可见,基于字符模型要好于基于单词模型,其中Lattice LSTM的模型效果最好,这就显示在长度越长的情况下,Lattice LSTM 的鲁棒性要由于其他几个模型。看这里,句子如果不是很长,可以优先考虑基于词的。
3. 参考资料
Zhang Y , Yang J . Chinese NER Using Lattice LSTM[J]. 2018.
https://github.com/jiesutd/LatticeLSTM
论文阅读总结——Chinese NER Using Lattice LSTM