Hive-学习笔记
文章目录
- 前言(Hive 1.2.1)
- 1.概念
- 2.优缺点
- 3.Hive架构原理
- 4.运行机制
- 5.Hive与数据库的比较
- 6.Hive数据类型
- 7.DDL数据定义
- 8.DML数据操作
- 9.查询
- 10.函数
- 11.压缩
- 12.存储
- 13.优化
- 14.练习Demo
- 总结
前言(Hive 1.2.1)
本文分享本菜鸟的Hive学习笔记
Hive广泛应用于大数据数仓项目,是大数据必学技术之一。
文章涉及的内容比较多,最好参照目录直接跳转。
本菜鸟QQ:599903582
比心心 ~
提示:以下是本篇文章正文内容,下面案例可供参考
1.概念
Hive是基于Hadoop的一个数据仓库工具,可以讲结构化的数据文件映射为一张表,并提供类SQL的查询功能;
本质:将HQL转化成MapReduce程序;
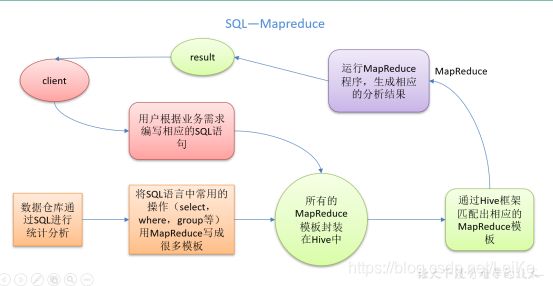
Hive处理的数据存储在HDFS
Hive分析数据底层的默认实现为MapReduce
执行程序运行在Yarn上
2.优缺点
优点:
操作接口采用类SQL语法,提供快速开发的能力;
避免了去写MapReduce,减少开发人员的学习成本;
Hive的延迟比较高,因此Hive常用语数据分析,对实时性要求不高的场合;
Hive优势在于处理大数据,对于小数据处理没有优势,因为Hive的执行延迟比较高
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点:
Hive的HQL表达能力有限
迭代式算法无法表达
数据挖掘方面不擅长
Hive’的效率比较低
Hive自动生成的MapReduce作业,通常情况下不够智能化
Hive调优比较困难,颗粒较粗;
3.Hive架构原理

1.Client 用户接口
2,Metastore 元数据 包含 表名、表所述的数据库、等表的属性
3,Hadoop 使用HDFS存储,MapReduce计算
4,驱动器 Driver
解析器
编译器
优化器
执行器
4.运行机制
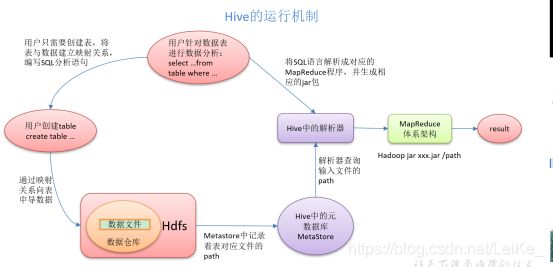
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
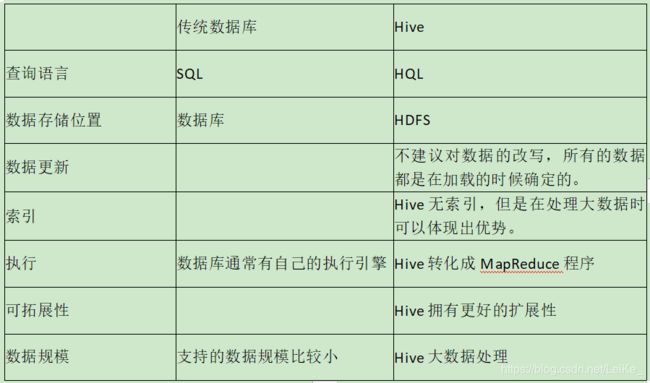
5.Hive与数据库的比较
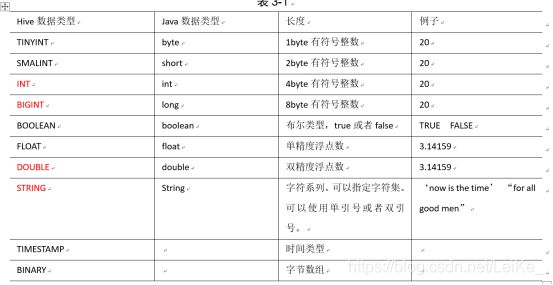
6.Hive数据类型
基本数据类型:
集合数据类型:

类型转换:
隐式:
- 任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。
- 所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
- TINYINT、SMALLINT、INT都可以转换为FLOAT。 (4)BOOLEAN类型不可以转换为任何其它的类型
显式:
- 可以使用CAST操作显示进行数据类型转换;
CAST('1' AS INT);
7.DDL数据定义
创建数据库
create database db_hive;
create database if not exist db_hive;
create database db_hive location '/db_hive.db' 指定数据库在HDFS上存放的位置
查询数据库
show databases; 显示数据库
show databases like ‘db_hive*’; 注意此处的通配符使用 '*'
查看数据库详情
desc database db_hive;
desc extended database db_hive; 显示数据库详细信息;
切换数据库
use db_hive;
修改数据库
alter database hive set dbproperties('createtime'='20170830');
删除数据库
drop database db_hive;
drop database if not exists db_hive;
drop database db_hive cascade; 数据库中有数据,(级联)强制删除
创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
解释:
EXTERNAL 创建外部表
COMMENT 为表和列添加注释
PAETITIONED BY 创建分区表
CLUSTERED BY 创建分桶表
ROW FORMAT DELIMITED fields terminated by '\t' 行中的属性 指定分隔符
创建表:
create table if not exists student(
id int,
name string)
row format delimited fields terminated by '\t'
stored as textfile
location '/db_hive.db/student';
根据查询结果创建表
create table if not exists student3 as select id, name from student;
根据已经存在的表结构创建表
create table if not exists student4 like student; 只是拷贝表结构不拷贝数据
查询表的类型
desc formatted student2;
外部表:
认为Hive并不是完全拥有这份数据.删除数据时并不会删除这份数据,只会删除表的元数据信息;
内部表 又可以称为 管理表
管理表和外部表的相互转换:
alter table student2 set tblproperties('EXTERNAL'='TRUE');
注意:区分大小写
alter table student3 set tblpeoperties('EXTERNAL'='FALSE');
分区表:
实际上就是对应一个HDFS文件夹;分区就是分目录;
创建分区表:
create table dept_partition(
deptno int,
dname string,
loc string
)
partitioned by (month string) // 指定分区字段,上传文件的时候需要指定该字段的值
row format delimited fields terminated by '\t';
加载数据到分区表中:
load data local inpath '/opt/module/datas/dept.txt'
into table default.dept_partition partition(month='201709'); //指定分区字段的值
查看分区表中的数据:
select * from dept_partition where month='201709';
增加分区
alter table dept_partition add partition(month='201706') ;
alter table dept_partition add partition(month='201705') partition(month='201704');
同时创建多个分区时用空格分开
删除分区
alter table dept_partition drop partition (month='201704');
alter table dept_partition drop partition (month='201705'), partition (month='201706');
同时删除多个分区时用逗号隔开
查看有多少分区
show partitions dept_partition;
查看分区结构
desc formatted dept_partition;
创建二级分区表:
create table dept_partition2(
deptno int,
dname string,
loc string
)
partitioned by (month string, day string) //指定二级分区的两个字段
row format delimited fields terminated by '\t';
加载二级分区:
load data local inpath '/opt/module/datas/dept.txt' into table
default.dept_partition2 partition(month='201709', day='13');
查询二级分区:
select * from dept_partition2 where month='201709' and day='13';
把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式:
上传数据
dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=201709/day=12;
dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=201709/day=12;
1,执行修复命令才能查询到数据
msck repair table dept_partition2;
2,上传数据后添加分区
alter table dept_partition2 add partition(month='201709', day='11');
3,创建文件夹后load数据到分区
load data local inpath '/opt/module/datas/dept.txt' into table dept_partition2 partition(month='201709',day='10');
注意:这个方法最重要的是元数据中是否有HDFS中的映射;
修改表:
重命名:
ALTER TABLE table_name RENAME TO new_table_name
添加列:
alter table dept_partition add columns(deptdesc string);
查询表结构:
desc dept_partition;
更新列:
alter table dept_partition change column deptdesc desc int;
替换列:
alter table dept_partition replace columns(deptno string, dname string, loc string);
删除表:
drop table dept_partition;
8.DML数据操作
load:
load data local inpath '/opt/module/datas/student.txt' into table default.student;
- load data:表示加载数据
- local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
- inpath:表示加载数据的路径
- overwrite:表示覆盖表中已有数据,否则表示追加
- into table:表示加载到哪张表
- student:表示具体的表
- partition:表示上传到指定分区
insert:
insert into table student partition(month='201709') values(1,'wangwu');
insert overwrite table student partition(month='201708')
select id, name from student where month='201709'
import:
import table student2 partition(month='201709') from '/user/hive/warehouse/export/student';
数据导出: Insert、dfs -get、Shell、Export。也可以使用Sqoop工具导出。
Insert导出:
将查询结果导出到本地:
insert overwrite local directory '/opt/module/datas/export/student' select * from student;
将查询结果格式化导出到本地:
insert overwrite local directory '/opt/module/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from student;
将查询结果导出到HDFS上(没有local):
insert overwrite directory '/user/atguigu/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
dfs -get:导出到本地
fs -get /user/hive/warehouse/student/month=201709/000000_0 /opt/module/datas/export/student3.txt;
Shell命令导出:
bin/hive -e 'select * from default.student;' > /opt/module/datas/export/student4.txt;
Export导出到HDFS:
导出有元数据信息。
export table default.student to '/user/hive/warehouse/export/student';
清除表中的数据:
truncate table student;
9.查询
全表查询:select * from emp;
特定列查询:select empno, ename from emp;
列起别名:select ename AS name, deptno dn from emp;
算数运算符:A+B、A-B、A*B、A/B、A%B(取余)、A&B(按位与)、A|B(按位或)、A^B(按位异或)、~A(按位取反)
常用函数:count() , max(),min(),sum(),avg();
Limit语句:select * from emp limit 5;
Where语句:select * from emp where sal >1000;
比较运算符:[NOT] Between、In、Is [NOT] Null、[NOT] Rlike
like: _表示一个字符;%表示0或多个字符
Rlike : 跟java的正则表达式
select * from emp where sal between 500 and 1000;
select * from emp where comm is null;
select * from emp where sal IN (1500, 5000);
select * from emp where sal LIKE '2%';
select * from emp where sal LIKE '_2%';
select * from emp where sal RLIKE '[2]';
逻辑运算符: And、Or、Not
select * from emp where sal>1000 and deptno=30;
select * from emp where sal>1000 or deptno=30;
select * from emp where deptno not IN(30, 20);
Group by (having):
select t.deptno, avg(t.sal) avg_sal from emp t group by t.deptno;
select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
having与where不同点:
- where针对表中的列发挥作用,查询数据;having针对查询结果中的列发挥作用,筛选数据。
- where后面不能写聚合函数,而having后面可以使用聚合函数。
- having只用于group by分组统计语句。
Join:join(内连接)、left join(左外连接)、right join(右外连接)、full join(满外连接)
select e.empno, e.ename, d.deptno from emp e join dept d on e.deptno = d.deptno;
select e.empno, e.ename, d.deptno from emp e left join dept d on e.deptno = d.deptno;
select e.empno, e.ename, d.deptno from emp e right join dept d on e.deptno = d.deptno;
select e.empno, e.ename, d.deptno from emp e full join dept d on e.deptno = d.deptno;
**注意**:连接 **n**个表,至少需要**n-1**个连接条件。例如:连接三个表,至少需要两个连接条件。
笛卡尔积产生场景:
- 省略连接条件
- 连接条件无效
- 所有表中的所有行互相连接
连接谓词中不支持Or,On语句中不能出现Or。
排序:
Order by(全局排序,一个Reducer)、
Sort by(每个Reducer内部排序,整体不排序)、
Distribute by(分区排序,需要结合Sort by使用)、
Cluster by(当Sort by 和 Distribute by字段一致时,可以替换)。
select * from emp order by sal desc;
select * from emp sort by empno desc;
select * from emp distribute by deptno sort by empno desc;
select * from emp cluster by deptno;
分桶:
分区和分桶的区别:分区针对的存储路径;分桶针对的数据文件
分桶表的创建:
create table stu_buck(id int, name string)
clustered by(id) into 4 buckets //确定分桶表的个数
row format delimited fields terminated by '\t';
查看分桶表结构:desc formatted stu_buck;
注意:想要实现分桶的效果,需要开启分桶功能,设置MapReduce的线程为**-1**,需要使用MapReduce程序将数据插入到表中才能实现分桶的效果
set hive.enforce.bucketing=true;
set mapreduce.job.reduces=-1;
insert into table stu_buck select id, name from stu;
分桶抽样查询:
select * from stu_buck tablesample(bucket 1 out of 4 on id);
select * from stu_buck tablesample(bucket x out of y on id);
x表示从哪个bucket开始,x的值必须小于等于y的值
分桶数/y 表示取样数,一般是总bucket的倍数或者因子
空字段赋值:NVL(String l, replace_with)
select nvl(comm,-1) from emp;
时间类函数:
date_format(): select date_format('2019-06-29','yyyy-MM-dd'); => 2019-06-29
date_add():select date_add('2019-06-29',5); => 2019-07-04
date_sub():select date_sub('2019-06-29',5); => 2019-06-24
datediff():select datediff('2019-06-29','2019-06-24'); => 5
CASE WHEN:
case sex when '男' then 1 else 0 end
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;
行转列:
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;注意:只能是字符串类型字段之间的拼接
COLLECT_SET(col):属于聚合函数,函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
列转行:
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行; 如UDTF为每个输入行生成零个或多个输出行。 Lateral View 首先将UDTF应用于基表的每一行,然后将结果输出行连接到输入行,以形成具有提供的表别名的虚拟表。
select
movie,
category_name
from
movie_info lateral view explode(category) table_tmp as category_name;
窗口函数:
用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。窗口函数与聚合函数计算方式一样,窗口函数也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,窗口函数可以为每组返回多个值。
OVER():
开窗函数,指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化;开窗函数OVER()指定一组行,开窗函数计算从窗口函数输出的结果集中各行的值。开窗函数不需要使用GROUP BY就可以对数据进行分组,还可以同时返回基础行的列和聚合列。
1.指定分组(partitionby)
2.指定取哪个值(order by)
可以加在over函数里面的:
CURRENT ROW:当前行;
n PRECEDING:往前n行数据;
n FOLLOWING:往后n行数据;
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点;
DISTRIBUTE BY + SORT BY
PARTITION BY + ORDER BY
加在OVER()函数前面的:https://blog.csdn.net/wangpei1949/article/details/81437574
LAG(col,n):往前第n行数据;
LEAD(col,n):往后第n行数据;
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,
对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
select name,count(*) over () //开窗
from business
where substring(orderdate,1,7) = '2017-04'
group by name;
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
RANK():排序相同时会重复,总数不变。 1 1 3 4
DENSE_RANK():排序相同时会重复,总数会交闪 1 1 2 3
ROW_NUMBER():根据顺序计算 1 2 3 4
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp, //指定分组和和排序
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
注意:
- SQL 语言大小写不敏感。
- SQL 可以写在一行或者多行
- 关键字不能被缩写也不能分行
- 各子句一般要分行写。
- 使用缩进提高语句的可读性。
10.函数
https://blog.csdn.net/u010839779/article/details/105648412?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-6.control
https://www.cnblogs.com/lrxvx/p/10974341.html
查询系统自带的函数:
show functions;
显示自带的函数的用法:
desc function upper;
详细显示自带函数的用法
desc function extended upper;
自定义函数:
UDF:一进一出
UDAF:多进一出
UDTF:一进多出
步骤:UDF
pom文件
工程依赖:
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
- (1)继承org.apache.hadoop.hive.ql.UDF
- (2)需要实现evaluate函数;evaluate函数支持重载;
- (3)在hive的命令行窗口创建函数
a)添加jar :add jar linux_jar_path
b)创建function:create [temporary] function [dbname.]function_name AS class_name; - 在hive的命令行窗口删除函数:
Drop [temporary] function [if exists] [dbname.]function_name;
注意:UDF必须要有返回类型,可以返回null,但是返回类型不能为void;
11.压缩
想要支持Snappy压缩,需要自行编译Hadoop
MR支持的压缩格式:
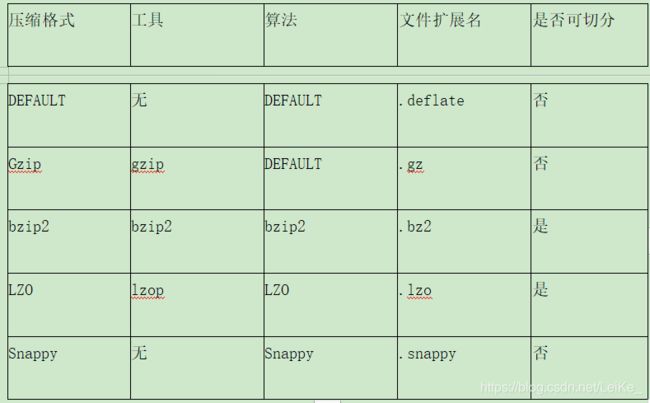
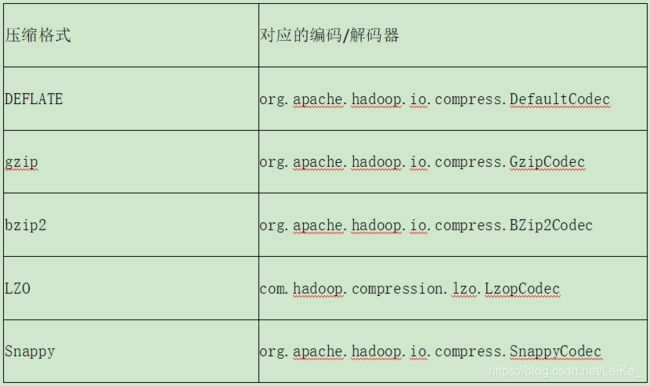
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器
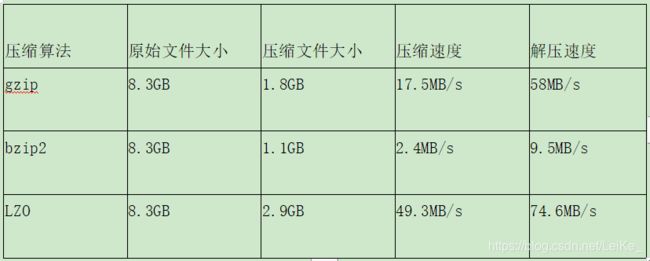
压缩性能的比较:
SNAPPY: On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
根据具体需要选择需要的压缩格式。
压缩参数配置:(mapred-site.xml)

开启Map输出阶段压缩:
1.开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
2.开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
3.设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
4.执行查询语句
hive (default)> select count(ename) name from emp;
开启Reduce输出阶段压缩:
1.开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
2.开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
3.设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
4.设置mapreduce最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5.测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory
'/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
12.存储
Hive支持的文件存储的格式主要有:TEXTFILE,SEQUENCEFILE,ORC,PARQUET
列式存储和行式存储:
1.行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
2.列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
TEXTFILE:
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
Orc格式:
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
如图所示可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念,不过大小由4MB->250MB,这样应该能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
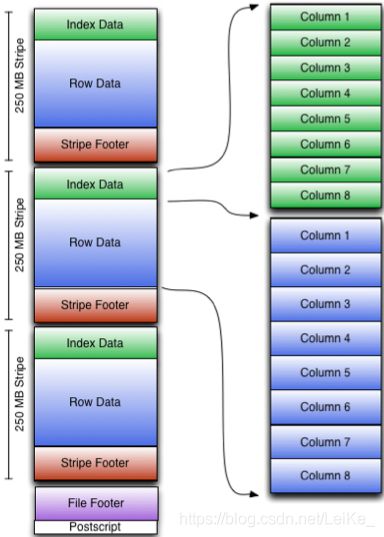
- Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
- Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
- Stripe Footer:存的是各个Stream的类型,长度等信息。 每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
Parquet格式:
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如图所示。
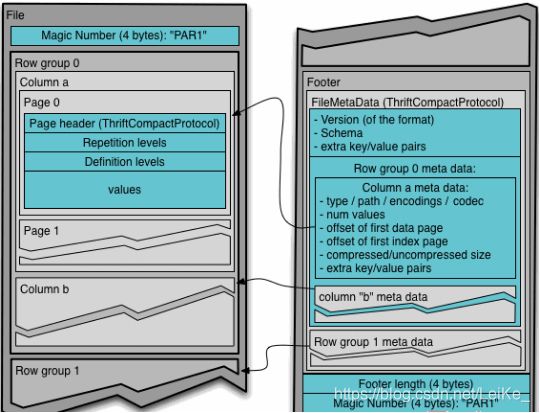
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
13.优化
https://www.cnblogs.com/swordfall/p/11037539.html
Fetch抓取 more(新版本,不走mr) minimal(老版本) none(都会执行mapreduce程序)
本地模式
表的优化:
大表,小表 Join
大表Join小表
MapJoin
Group by
Count(Distinct) 去重统计
避免笛卡尔积
行列过滤
动态分区调整
分桶
分区
MR优化
并行执行
严格模式
JVM重用
推测执行
压缩
执行计划 explain
14.练习Demo
==============================================================
数据位置:https://download.csdn.net/download/LeiKe_/14045737
表结构:
gulivideo_orc
col_name data_type comment
videoid string 视频id
uploader string 上传者
age int 年龄
category array<string> 类别
length int 大小
views int 观看次数
rate float 评分
ratings int 流量
comments int 评论数
relatedid array<string> 相关视频id
gulivideo_user_orc
字段 备注 字段类型
uploader 上传者用户名 string
videos 上传视频数 int
friends 朋友数量 int
建表语句:
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as orc;
create table gulivideo_user_orc(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as orc;
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as textfile;
create table gulivideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as textfile;
注意:ORC格式是列式存储的表,不能直接从本地文件导入数据,只有当数据源表也是ORC格式存储时,才可以直接加载,否则报错。
数据导入:
load data local inpath '/opt/data/guiliVideo/user/2008/0903' into table gulivideo.gulivideo_user_ori;
load data local inpath '/opt/data/guiliVideo/video/2008/0222' into table gulivideo.gulivideo_ori;
insert into gulivideo.gulivideo_user_orc select * from gulivideo.gulivideo_user_ori;
insert into gulivideo.gulivideo_orc select * from gulivideo.gulivideo_ori;
需求实现sql:
--统计视频观看数Top10
select videoid,views
from gulivideo_orc
order by views desc
limit 10;
--统计视频类别热度Top10
1,查找视频-类别,炸开
select category_name
from gulivideo_orc
lateral view explode(category) temp as category_name;t1
2,根据类别分组计数排序
select category_name,count(*) cnt
from
(select category_name
from gulivideo_orc
lateral view explode(category) temp as category_name)t1
group by category_name
order by cnt desc
limit 10;
--统计视频观看数Top20所属类别以及类别包含的Top20的视频个数
1,查询Top20的视频
select videoid,category,views
from gulivideo_orc
order by views desc
limit 20;t1
2,炸开类别
select videoid,category_name
from (select videoid,category,views
from gulivideo_orc
order by views desc
limit 20)t1
lateral view explode(category) temp as category_name;t2
3,根据类别分组计数
select category_name,count(*)
from (select videoid,category_name
from (select videoid,category,views
from gulivideo_orc
order by views desc
limit 20)t1
lateral view explode(category) temp as category_name)t2
group by category_name;
--统计视频观看数Top50所关联视频的所属类别排名
1,查询视频观看数Top50
select relatedid,views
from gulivideo_orc
order by views desc
limit 50;t1
2,将关联视频炸裂开
select relatedid_ids
from (select relatedid,views
from gulivideo_orc
order by views desc
limit 50)t1
lateral view explode(relatedid) temp as relatedid_ids;t2
3,将关联视频与原表连接查询类别
select category
from (select relatedid_ids
from (select relatedid,views
from gulivideo_orc
order by views desc
limit 50)t1
lateral view explode(relatedid) temp as relatedid_ids)t2
join gulivideo_orc
on t2.relatedid_ids = gulivideo_orc.videoid;t3
4,将类别炸裂开并排序
select category_name, count(*) cnt
from (
select
t2.relatedIds relatedIds,
category
from (select relatedIds
from (select views,relatedId
from gulivideo_orc
order by views desc
limit 50)t1
lateral view explode(relatedId) table_tmp as relatedIds)t2
join gulivideo_orc g
on t2.relatedIds = g.videoId)t3
lateral view explode(category) table_tmp as category_name
group by category_name
order by cnt desc;
--统计每个类别中视频流量Top10
1,查询每个类别
select videoid,views,category,rank()over(partition by category order by views) rk
from gulivideo_orc;t1
2.取前十
select videoid,views,category
from (select videoid,views,category,rank()over(partition by category order by views) rk
from gulivideo_orc)t1
where rk <= 10;
--统计上传视频最多的用户Top10以及他们上传的全部视频top20
gulivideo_user_orc
col_name data_type comment
uploader string
videos int
friends int
1.获取上传视频数最多的用户Top10
select uploader, videos
from gulivideo_user_orc
order by videos desc
limit 10;t1
2.获取他们上传的全部视频,然后根据views排序
select videoId, uploader, views
from gulivideo_orc t1
join t2
on t1.uploader = t2.uploader
order by views desc
limit 20;
select videoId, t1.uploader, views
from gulivideo_orc t1
join (select uploader, videos
from gulivideo_user_orc
order by videos desc
limit 10)t2
on t1.uploader = t2.uploader
order by views desc
limit 20;
--统计每个类别视频观看数Top10
1.炸开类别
select
videoid,
category_name,
rank() over(partition by category_name order by views desc) rk
from gulivideo_orc
lateral view explode(category) table_tmp as category_name;t1
2.取前十
select category_name, videoid, rk
from t1
where rk <= 10;
select category_name, videoid, rk
from (select
videoid,
category_name,
rank() over(partition by category_name order by views desc) rk
from gulivideo_orc
lateral view explode(category) table_tmp as category_name)t1
where rk <= 10;
总结
本文分享了本菜鸟的Hive’学习笔记,内容还是比较丰富的,最后也是展示了小Demo,可以参考目录进行观看,Hive的学习最最最最基本的就是sql的书写,熟练的掌握sql很有必要。
本菜鸟QQ:599903582
笨鸟先飞,熟能生巧 ~
比心心 ~