目标检测YOLOv1、v2、v3学习总结
初步总结SSD和YOLO目标检测算法并进行对比。
YOLO
yolo v1算法、yolo v2 算法、yolo v3算法
主要是通过这篇文章为主、其他零星文章进行补充,然后也是主要让自己在之后、看到这些点能把整个架子想起来就可以,细节问题我们可以再讨论
YOLO v1
算法首先把输入图像(feature map)划分成S*S的格子,然后对每个格子都预测2个bounding boxes,每个bounding box都包含5个预测值:x,y,w,h和confidence, x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;w和h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)
注:2是v1用的预测个数
另外每个格子都预测C个假定类别的概率。在本文中作者取S=7,B=2,C=20(因为PASCAL VOC有20个类别),所以最后有7x7x30个tensor(每格对应一个30维tensor 包含confidence(IOU)和预测box的左边)。如Fig2,比较好理解
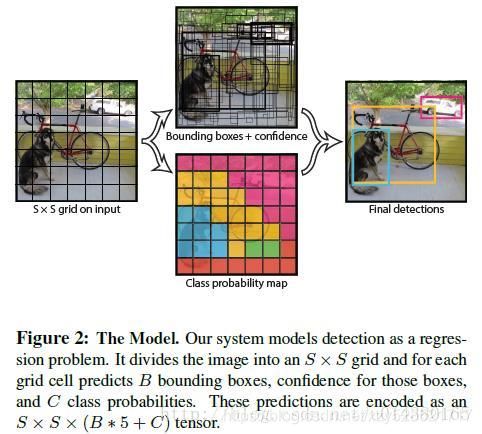
每个bounding box都对应一个confidence score,confidence score等于预测的box和ground truth的IOU值,每个grid cell都预测C个类别概率(一个预测坐标,一个预测类) 之后每个bounding box的confidence和每个类别的score相乘,在某个类别中(即矩阵的某一行对类进行过滤),将得分少于阈值(0.2)的设置为0,然后再按得分从高到低排序。最后再用NMS算法去掉重复率较大的bounding box(在一类中用NMS把所有bounding box都算了) 然后再选最大的
网络方面:重点是最后的输出是7x7x30,中间结构可以进行调整

Q:但其实有个疑问这个confidence不是自己算出来的吗?感觉这里是直接得出来了
loss方面

额外加一个开根号的项是因为把尺度的问题考虑进去了
eg: 5、3差2,10,8差2,都差2,但开了根号以后就不一样了。
YOLO v2
这里主要介绍相对于v1版本的改进
1、Batch Normalization
按理说是应该加,我看现在网络基本一个卷积就接一个bn,bn的好处很多
2、High Resolution Classifier (重要)
先用224x224的输入从头开始训练网络,大概160个epoch(表示将所有训练数据循环跑160次),然后再将输入调整到448x448,再训练10个epoch。注意这两步都是在ImageNet数据集上操作。最后再在检测的数据集上fine-tuning
现在也是基本会加载训练过的网络
3、Convolutional With Anchor Boxes
最终每个grid cell选择5个anchor box
4、Dimension Clusters
采用k-means的方式对训练集的bounding boxes做聚类
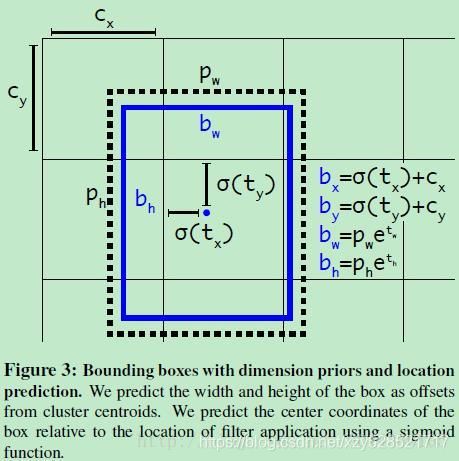
5、Direct Location prediction
在这里作者并没有采用直接预测offset的方法,还是沿用了YOLO算法中直接预测相对于grid cell的坐标位置的方式。 (YOLOv3延用了这个方式,这里是对offset进行了一个sigmoid的映射,防止不同尺度 或offset过大的问题。)
6、Fine-Grained Features
这里主要是添加了一个层:passthrough layer。这个层的作用就是将前面一层的26x26的feature map和本层的13x13的feature map进行连接,有点像ResNet
具体操作:对于26x26x512的特征图,经passthrough层处理之后就变成了13x13x2048的新特征图(特征图大小变为1/4,而通道数变为以前的4倍),然后与后面的13x13x1024特征图连接在一起形成13x13x3072的特征图,最后在该特征图上卷积做预测。
7、Multi-Scale Training
也就是说downsample的factor是32,因此作者采用32的倍数作为输入的size,具体来讲文中作者采用从{320,352,…,608}的输入尺寸。
这种网络训练方式使得相同网络可以对不同分辨率的图像做detection
8、网络
在YOLO v1中,作者采用的训练网络是基于GooleNet,而在YOLO v2中,作者采用了新的分类模型作为基础网络,那就是Darknet-19。
YOLO v3
1.计算loss方式
类别预测方面主要是将原来的单标签分类改进为多标签分类
将原来用于单标签多分类的softmax层换成用于多标签多分类的逻辑回归层
Class Prediction:
v3使用的是分类预测,使用了简单的logistic regression(逻辑回归)–-binary cross-entropy loss(二元交叉熵损失)来代替softmax进行预测类别,由于每个点所对应的bbox少并且差异大,所以每个bbox与ground truth的matching策略变成了1对1。当预测的目标类别很复杂的时候,采用logistic regression进行分类是更合理的。比如Open Images Dataset数据集有很多重叠的标签,如女人和人,softmax每个候选框只对应着一个类别,而logistic regression使用multi-label classification(多标签分类)对数据进行更合理的建模。
Bounding Box Prediction:
边界框预测。与之前YOLO版本一样,v3的anchor box也是通过聚类得到,每个bbox预测四个坐标值(tx,ty,tw,th),预测的cell图像左上角的偏移(cx,cy),及之前得到bbox的宽和高pw和ph可以对bbox按下图的方式进行预测,在训练这几个坐标值的时候采用了sum of squared error loss(平方和距离误差损失)
2.多scale
YOLOv3预测3种不同尺度的框(boxes)。我们的系统使用类似的概念来提取这些尺度的特征,以形成金字塔网络[6]。从我们的基本特征提取器中,我们添加了几个卷积层。其中最后一个预测了3-d张量编码边界框,对象和类别预测。在我们的COCO实验[8]中,我们预测每个尺度的3个框,所以对于4个边界框偏移量,1个目标性预测和80个类别预测,张量为N×N×[3 *(4 + 1 + 80)]。
特征图方面:
我们从之前的两层中取得特征图(feature map),并将其上采样2倍。我们还从网络中的较早版本获取特征图,并使用element-wise addition 将其与我们的上采样特征进行合并。这种方法使我们能够从早期特征映射中的上采样特征和更细粒度的信息中获得更有意义的语义信息。然后,我们再添加几个卷积层来处理这个组合的特征图,并最终预测出一个相似的张量,虽然现在是两倍的大小。
知乎译文是这么说的
然后我们从两层前那里拿feature map,upsample 2x,并与更前面输出的feature map通过element-wide的相加做merge
但代码是concat
x, y1 = make_last_layers(darknet.output, 512, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(256, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[152].output])
x, y2 = make_last_layers(x, 256, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[92].output])
x, y3 = make_last_layers(x, 128, num_anchors*(num_classes+5))
return Model(inputs, [y1,y2,y3])
然后又回头去看了下论文是merge it with our upsampled features
using concatenation
可以试下相加的效果,但原文就是concat

我们再次执行相同的设计来预测最终尺度的方框。因此,我们对第三种尺度的预测将从所有先前的计算中获益,并从早期的网络中获得细粒度的特征。
3.关于bounding box的初始尺寸
我们仍然使用k-means聚类来确定我们的边界框的先验。我们只是选择了9个聚类(clusters)和3个尺度(scales),然后在整个尺度上均匀分割聚类。在COCO数据集上,9个聚类是:(10×13);(16×30);(33×23);(30×61);(62×45); (59×119); (116×90); (156×198); (373×326)。
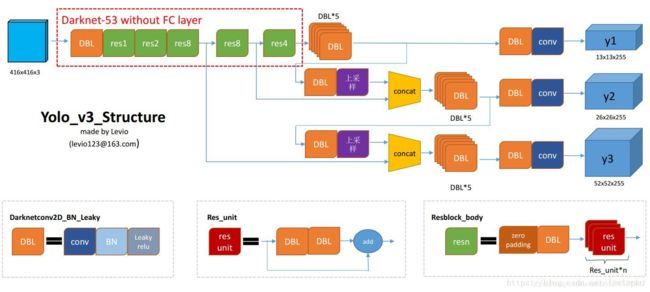
4.网络结构
(Darknet-53)一方面基本采用全卷积(YOLO v2中采用pooling层做feature map的sample,这里都换成卷积层来做了),另一方面引入了residual结构(YOLO v2中还是类似VGG那样直筒型的网络结构,层数太多训起来会有梯度问题,所以Darknet-19也就19层,因此得益于ResNet的residual结构,训深层网络难度大大减小,因此这里可以将网络做到53层,精度提升比较明显)
如果有什么问题请务必留言一起讨论,我自己感觉也有很多边边角角没考虑到,提出问题一起解决共同进步。
其它:YOLO v3、SSD、Faster-RCNN目标检测算法对比