python+selenium 爬取网易云音乐评论
写在前面
本文记录用python+selenium爬取网易云音乐评论,将其保存在文本文档中,每首歌评论用歌名命名。
爬取的网站:https://music.163.com/
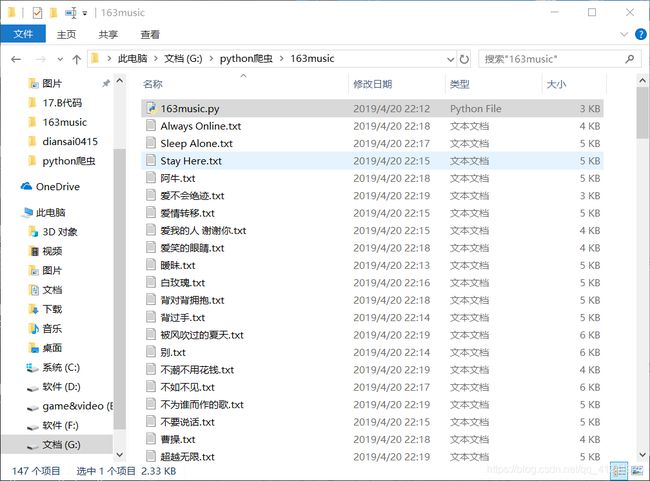
抓取效果如图:
使用的工具和编辑环境
- python 3.6;
- selenium库,chrome浏览器;
- 编辑器:sublime text3
selenium安装可以直接pip:
pip install selenium
使用chrome浏览器需要下载chromedriver,地址:https://sites.google.com/a/chromium.org/chromedriver/downloads
如果上面链接需要的话可以试试这个:
http://chromedriver.storage.googleapis.com/index.html
下载完成之后放在chrome浏览器的安装目录下就行了。
如下图: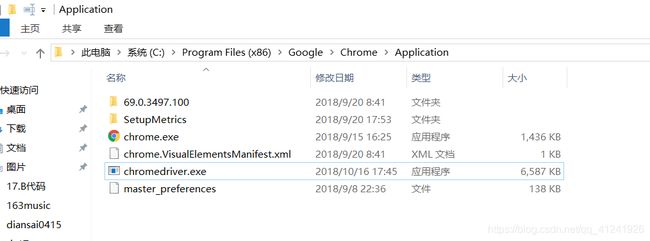
接下来就可以愉快的进行驱动浏览器了!
selenium库的基本使用
驱动浏览器:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
url = 'https://www.baidu.com/'
browser = webdriver.Chrome()
browser.get(url)
input = browser.find_element_by_xpath('//*[@id="kw"]')
input.send_keys('selenium')
input.send_keys(Keys.ENTER)
可以看到,自己的chrome打开了并百度搜索了selenium
无头浏览器模式
chrome较高版本有提供无头浏览器模式,这样我们再使用selenium爬虫的时候可以减少系统资源的消耗,而且利用selenium爬虫本身就是为了解决一些动态加载网站难以爬取的问题,不需要我们看到浏览器运行过程。(本人发现网易云首页就是动态加载的,直接用requests方法获取的html和在网站上查看的不一样,大家可以试一下)
好了,怎么使用无头模式呢,这样:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 启动浏览器,获取网页源代码
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.baidu.com/')
print(browser.page_source)
browser.quit()
可以看到浏览器图形界面没有打开但是打印出了网页源代码:
了解selenium更多用法,推荐这篇博客:Python 爬虫基础Selenium库的使用(二十二01)
那么我们现在就来爬取网易云吧!
爬取网易云音乐评论
1 网站分析
我们要爬取歌曲的评论,先看看歌手页长这样:
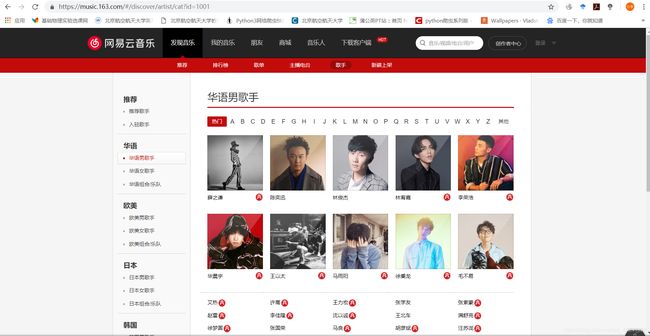
点进去各个歌手的主页,不难发现每个歌手主页的链接格式如下:
https://music.163.com/#/artist?id=5781
https://music.163.com/#/artist?id=2116
https://music.163.com/#/artist?id=3684
前半部分相同,只是不同的歌手id有所不同,那么我们就可以通过记录你想要爬取的歌手的id来构建目标网页链接了:
ids = ['5781', '2116', '3684']
self.singer_urls = []
for each in self.ids:
self.singer_urls.append('https://music.163.com/#/artist?id=' + each)
print('要爬取的歌手id有:'+ each)
把id改成你自己想要爬取的歌手的就好。
我们再分析歌手主页:
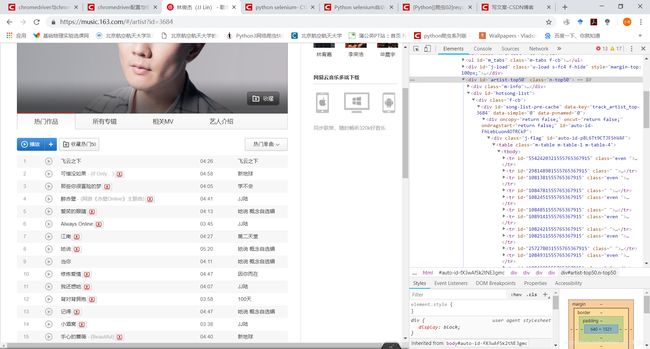
发现歌曲列表属性为m-table m-table-1 m-table-4的 table 标签下,这里我们使用selenium中的xpath查找方法。这有个博客总结的不错:网络爬虫基础-Xpath语法(一)
直接查找保存每首歌的链接:
items = self.browser.find_elements_by_xpath('//table[@class = "m-table m-table-1 m-table-4"]/tbody/tr//span[@class = "txt"]/a')
for item in items:
href = item.get_attribute('href')
song_urls.append(href)
print('要爬取的歌曲地址有'+ href)
然后再看每首歌的主页面:
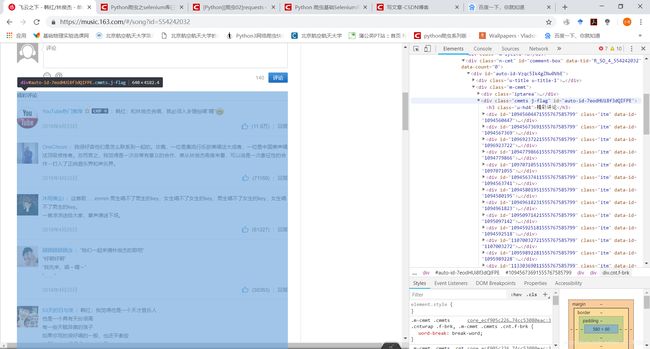
评论列表都在
count = 0
for url in self.song_urls:
comments = []
self.browser.get(url)
try:
self.browser.switch_to.frame('g_iframe') #记得切换到所要找的元素所在的frame,不然会找不到元素,这里有的网页不需要切换,所以使用try
except:
pass
song_name = self.browser.find_element_by_xpath('//div[@class = "tit"]/em')
items = self.browser.find_elements_by_xpath('//div[@class = "cmmts j-flag"]//div[@class = "cntwrap"]/div/div[@class = "cnt f-brk"]')
#写入文件
with open(song_name.text + '.txt', 'a+', encoding = 'utf-8') as f:
for item in items:
f.writelines(item.text + '\n')
#print(item.text)
print('当前正在抓取歌曲:“{}”的评论'.format(song_name.text))
print('已完成:%{}'.format(count/len(self.song_urls)*100))
count += 1
由于我是编写类代码的,上面代码直接是截取的,所以可能很多带了self,后面我把所有代码贴出来,不想用类的方式编写也是可以的,稍微改一下。
2 全部代码
from selenium import webdriver
import time
class music163(object):
"""docstring for 163music"""
def __init__(self):
self.song_urls = []
self.ids = ['5781', '2116', '3684']
self.singer_urls = []
for each in self.ids:
self.singer_urls.append('https://music.163.com/#/artist?id=' + each)
print('要爬取的歌手id有:'+ each)
chrome_options = webdriver.ChromeOptions()
# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 启动浏览器,获取网页源代码
self.browser = webdriver.Chrome(chrome_options=chrome_options)
def get_music_url(self):
for url in self.singer_urls:
self.browser.get(url)
self.browser.switch_to.frame('g_iframe')
items = self.browser.find_elements_by_xpath('//table[@class = "m-table m-table-1 m-table-4"]/tbody/tr//span[@class = "txt"]/a')
for item in items:
href = item.get_attribute('href')
self.song_urls.append(href)
print('要爬取的歌曲地址有'+ href)
def get_comment(self):
count = 0
for url in self.song_urls:
comments = []
self.browser.get(url)
time.sleep(1)
try:
self.browser.switch_to.frame('g_iframe')
except:
pass
song_name = self.browser.find_element_by_xpath('//div[@class = "tit"]/em')
items = self.browser.find_elements_by_xpath('//div[@class = "cmmts j-flag"]//div[@class = "cntwrap"]/div/div[@class = "cnt f-brk"]')
#写入文件
with open(song_name.text + '.txt', 'a+', encoding = 'utf-8') as f:
for item in items:
f.writelines(item.text + '\n')
#print(item.text)
print('当前正在抓取歌曲:“{}”的评论'.format(song_name.text))
print('已完成:%{}'.format(count/len(self.song_urls)*100))
count += 1
def main(self):
self.get_music_url()
self.get_comment()
print('下载完成')
self.browser.quit()
if __name__ == '__main__':
spider = music163()
spider.main()
单进程爬取而且使用驱动浏览器的方式,速度可能比较慢,休息会儿,马上就好。
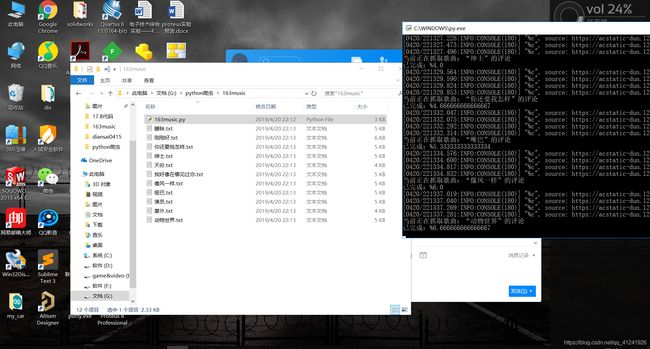
结语
练习使用selenium爬取动态加载网页,记录一下。程序需要改善的地方主要在运行速度上,可以考虑多开浏览器爬取和减少等待时间等。