Python爬虫 | 爬取贝壳找房8万+二手房源,看看普通人在北京买房是有多难!
文章目录
-
- 1.概述
- 2.数据采集
- 3.数据清洗
-
- 3.1.读取数据
- 3.2.去掉车位(地下室)数据
- 3.3.房源信息解析
- 4.数据处理及可视化
-
- 4.1.各地区二手房源数
- 4.2.各地区二手房均价
- 4.3.各地区二手房总价
- 4.4.各地区二手房面积
- 4.5.各地区二手房年限
- 4.6.各地区二手房【价格-地区】数量分布
- 4.7.各地区二手房【户型-价格】数量分布
- 4.8.各地区二手房【户型-地区】数量分布
- 4.9.各地区二手房【户型-地区】均价分布
- 5.房源标题及小区词云
- 6.总结
1.概述
最近看到一句话,感觉很扎心,这句话是”任何一个男孩子小时候的梦想,绝对不是买套房“。
其实,刚从象牙塔步入社会的时候,不曾想过房的事情。记得2016年房价猛涨,方才对房有了一些认知而已。直到随着年龄的增长,房子的故事便不得不需要展开了。
北上广深如今的房价又到了什么样惊人的数值呢?从贝壳找房最新的贝壳指数来看:北京是6.13万,上海5.62万,广州2.86万,深圳7.05万。
今天,我们从贝壳找房 爬取了 8万+二手房源信息,看看在北京的二手房都是什么样的存在。
通过本篇,大家可以在了解北京二手房多维度信息的同时学习Python的re正则表达式、pandas数据处理以及绘图库(pyecharts、seaborn)柱状图+饼图+直方图+箱线图+map+热力图+堆叠图和高德api的使用等。
数据说明:
数据来源:贝壳找房-二手房
数据日期:2020年12月28日
数据量级:82,346(含车位,数据处理阶段清洗)
工具环境
Python 3.8.5
| 库 | 用途 |
|---|---|
| requests | 爬虫请求网站数据 |
| re | 正则解析网页数据及数据清洗 |
| pandas | 数据清洗及统分 |
| pyecharts | 绘图 |
| matplotlib | 绘图 |
| seaborn | 绘图 |
2.数据采集
贝壳找房的数据爬取比较简单,简单的翻页规律和HTML网页文本解析。我们编写for循环,用requests请求数据,再用re正则表达式进行房源数据解析即可。
鉴于整个爬虫过程并不复杂,这里亦不细说,后续专题介绍如何获取全部数据。
房源数据解析代码如下:
# 请求网页数据函数
def get_html(url, proxies):
try:
rep = requests.get(url, headers= header, proxies= proxies, timeout=6)
except Exception as e :
print(e)
proxies = get_proxies()
rep = requests.get(url, headers= header, proxies= proxies, timeout=6)
while rep.status_code != 200:
proxies = get_proxies()
rep = requests.get(url, headers= header, proxies= proxies, timeout=6)
html = rep.text
html = re.sub('\s', '', html) # 将html文本中非字符数据去掉
return html,proxies
# 循环请求每页数据
num = 0
for page in range(1,pages+1):
items = []
time.sleep(random.random())
info_url = f'{url}/pg{page}'
try:
info_html, proxies = get_html(info_url, proxies)
except Exception as e:
print(e)
continue
sellListContent = re.findall(r'(.*?)' , info_html)[0]
Lists = re.findall(r'(.*?)' , sellListContent)
for List in Lists:
try:
# 获取房屋信息
item = {
}
item['标题'] = re.findall(r'detail"title="(.*?)"data-hreftype=', List)[0]
item['房子ID'] = re.findall(r'housedel_id=(\d+)&', List)[0]
item['地址'] = re.findall(r'(.*)' , List)[0][1]
item['详情页'] = re.findall(r'(.*)' , List)[0][0]
item['详情'] = re.findall(r'说明:
由于翻页最多支持100页,每页约30个房源数据,如果我们想获取全部的数据,需要注意两点:
- 可以通过进行更细颗粒度的筛选后再进行url的组合,一般来说可以通过 区域 和 价格区间 和 户型 进行组合即可,我这边即是采用这种组合策略;
- 由于网站对同IP的访问频率和次数是有限制的,因此需要用到代理IP,购买付费的代理IP就可满足学习需求了,在requests.get()函数中加上proxies参数即可。
3.数据清洗
这部分我们用到pandas和re,主要是过滤非住宅房源的车位数据信息,解析房源更多有用信息。
3.1.读取数据
import pandas as pd
import re
df = pd.read_excel('贝壳在售二手房数据20201228.xlsx')
df.sort_values(by='总价')

我们可以看到,在原始数据中 详情包含的信息较多,比如楼层、户型、面积、建筑年份和朝向等等,对于地下室和底层的部分大多数都是车位,索性就不考虑这部分数据,这部分我们后续进行清洗。同时,在均价和关注人数中也都包含更多信息需要我们解析出来。
3.2.去掉车位(地下室)数据
# 车位条件,不一定严谨
mask = ((df['详情'].str.contains('地下室'))
# & (df['详情'].str.contains('1室'))
# &(~df['详情'].str.contains(r'地下室\(共[2-9]|[1-9]\d+层\)'))
)|((df['详情'].str.contains('底层')) & (df['详情'].str.contains('1室'))
&(~df['详情'].str.contains(r'底层\(共[2-9]|[1-9]\d+层\)'))
)
# 房子
house = df[~mask]
# 车位
carport = df[mask]
carport.sort_values(by='总价')

哈哈,有点尴尬,部分别墅被误处理了。不过没事,别墅咱们就先不考虑,毕竟更买不起!
3.3.房源信息解析
# 详情信息解析
s = '中楼层(共9层)|2007年建|1室1厅|24.78平米|北'
# s = '地下室|2014年建|1室0厅|39.52平米|东'
# s = '底层(共2层)5室3厅|326.56平米|东南西北'
# s = '地下室1室0厅|11.9平米|南'
# re.split(r'(.+?)(\(共(.*)层\))*(\|((.*)年建)*\|)*?(\d+室.*?)\|(.*)平米\|(.*)',s)
re.split(r'(.+?)(?:\(共(.*)层\))?(?:\|(.*)年建\|)*?(\d+室.*?)\|(.*)平米\|(.*)',s)
![]()
我在操作的时候用的是注释掉的正则表达式部分,后来在交流群里询问大佬明神后知道了**?*表达式,于是就出现了最终采用的这个更优的表达式。接下来,我们对data数据进行相关操作。
houseData = house.copy()
houseData.loc[:,'楼层'] = houseData['详情'].apply(lambda x : re.split(r'(.+?)(?:\(共(.*)层\))?(?:\|(.*)年建\|)*?(\d+室.*?)\|(.*)平米\|(.*)',x)[1])
houseData.loc[:,'楼高'] = houseData['详情'].apply(lambda x : re.split(r'(.+?)(?:\(共(.*)层\))?(?:\|(.*)年建\|)*?(\d+室.*?)\|(.*)平米\|(.*)',x)[2])
houseData.loc[:,'建筑年份'] = houseData['详情'].apply(lambda x : re.split(r'(.+?)(?:\(共(.*)层\))?(?:\|(.*)年建\|)*?(\d+室.*?)\|(.*)平米\|(.*)',x)[3])
houseData.loc[:,'户型'] = houseData['详情'].apply(lambda x : re.split(r'(.+?)(?:\(共(.*)层\))?(?:\|(.*)年建\|)*?(\d+室.*?)\|(.*)平米\|(.*)',x)[4])
houseData.loc[:,'面积'] = houseData['详情'].apply(lambda x : re.split(r'(.+?)(?:\(共(.*)层\))?(?:\|(.*)年建\|)*?(\d+室.*?)\|(.*)平米\|(.*)',x)[5])
houseData.loc[:,'朝向'] = houseData['详情'].apply(lambda x : re.split(r'(.+?)(?:\(共(.*)层\))?(?:\|(.*)年建\|)*?(\d+室.*?)\|(.*)平米\|(.*)',x)[6])
均价、发布时间和关注人数信息解析,这里采用的extract方法,大家可以简单了解下其作用!
# 均价信息解析
houseData['均价'] = houseData['均价'].str.extract(r'(\d+)')
# 发布时间信息解析
houseData['发布时间'] = houseData['关注人数'].str.extract(r'\/(\d+[年|月|日])')
# 关注人数信息解析
houseData['关注人数'] = houseData['关注人数'].str.extract(r'(\d+)人关注')

最后,我们只选取自己想用到的数据copy出来吧,一共80,825条房源数据。
ershoufang = houseData[[ '房子ID', '地址', '总价', '总价单位', '均价', '关注人数', '地区',
'价格区间', '户型', '楼层', '楼高', '建筑年份', '面积', '朝向', '发布时间']]
ershoufang

4.数据处理及可视化
在第3部分我们引入了pandas库,这里在进行可视化的时候需要先引入以下绘图库和做一些全局设置。
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['Microsoft YaHei'] #设置全局默认字体 为 幼圆
plt.rcParams['axes.unicode_minus'] = False # 解决中文字体下负号显示问题
plt.rcParams["axes.labelsize"] = 16 # 设置全局轴标签字典大小
import seaborn as sns
sns.set_style("darkgrid",{
"font.family":['Microsoft YaHei', 'SimHei']}) #seaborn绘图的字体设置
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
from pyecharts.charts import *
data = ershoufang.copy()
4.1.各地区二手房源数
# 各地区二手房源数
beijing = data.groupby('地区',as_index=False)['房子ID'].count().sort_values('房子ID',ascending=False).reset_index(drop=True)
beijing.loc[~beijing['地区'].str.endswith('区'),'地区']=beijing['地区']+'区'
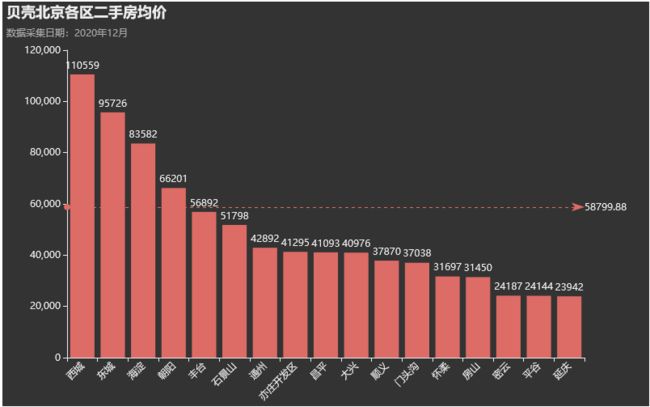
房源数最多的地区是 朝阳区,其次是丰台和海淀,基本上都集中在中心城区一带。像北京的北部郊区 延庆、怀柔、密云和平谷等房源较少。

绘图代码:
# 绘制地图(区)
c = (
Map(init_opts=opts.InitOpts(theme='dark', width='800px'))
.add("房源数", [list(z) for z in zip(beijing['地区'].to_list(), beijing['房子ID'].to_list())], "北京", label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="贝壳北京二手房源数分布",
subtitle='数据采集日期:2020年12月'),
visualmap_opts=opts.VisualMapOpts(max_=15000)
)
)
c.render_notebook()
贝壳北京二手房源数中,朝阳区以2.2万占比接近28%,房源数一半都在朝阳、丰台和海淀区。除以三个地区外,中心城区的东、西城虽然面积小,但是房源数其实并不少,反而是石景山区房源数较少。

绘图代码:
# 富文本
rich_text = {
"a": {
"color": "#999", "lineHeight": 22, "align": "center"},
"b": {
"fontSize": 12, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
}
location = beijing['地区'].to_list()
num = beijing['房子ID'].to_list()
pie = (Pie(init_opts=opts.InitOpts(theme='dark', width='800px',
height='560px',
))
.add('二手房源数', [list(z) for z in zip(location, num)],
radius=200, #设置饼图半径
label_opts=opts.LabelOpts(position='outsiede',
formatter="{b|{b}: }{c} {per|{d}%} ",
rich=rich_text))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(title="贝壳北京各区二手房源数量占比",
subtitle='数据采集日期:2020年12月'),)
)
pie.render_notebook()
4.2.各地区二手房均价
#房价均价平均值
data.均价.mean()
58799.88320445407
整个北京二手房均价为 5.88万元每平米!!
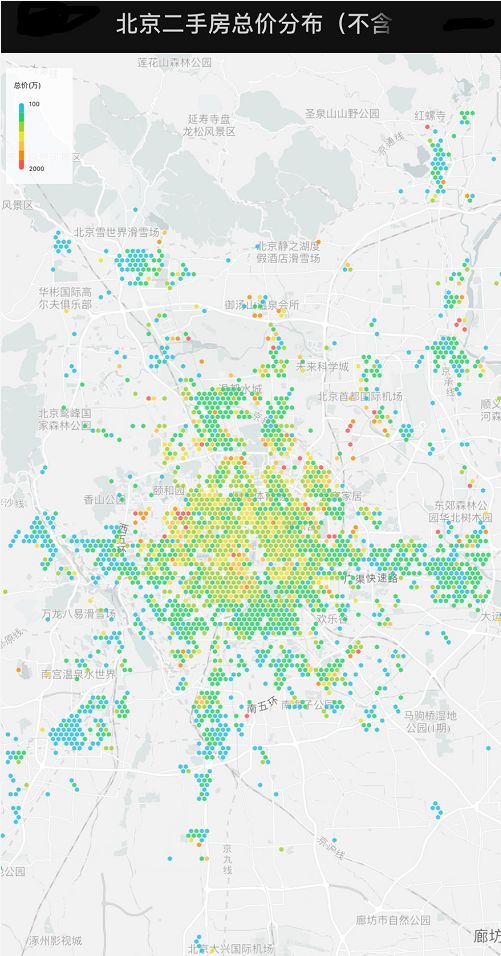
以下截图部分,公众号后台回复“北京二手房均价”可获取热力图地址,自由查看更详细信息。
均价直方图
从均价直方图我们可以发现,落在均价5万左右的房子比较多,而超过7万以上的房源数也不少,其中最低的可能仅1万出头,最高的则可以搞到17.5万!

绘图代码:
# 均价直方图
plt.figure(figsize=(15,8))
sns.set_context("talk")
sns.histplot(data.均价).set(ylabel='数量')
均价箱线图
在均价箱线图中我们可以看见,东、西城作为最核心的区域,其房子的均价真的是老高的,均价差不多都在10万+;其次是学校资源云集的海淀区,均价也高达8.3万+;朝阳貌似学校资源并没有那么丰富,均价6万+;其他区域价格虽然远没有以上几个区域贵,但是也基本都落在3-5万之间!!

绘图代码:
# 箱线图
x_data = list(data['地区'].unique())
y_data = [data[data['地区']==x]['均价'].to_list() for x in x_data]
Box = (Boxplot(init_opts=opts.InitOpts(theme='dark', width='800px'))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)),
title_opts=opts.TitleOpts(title="贝壳北京各区二手房均价箱型图",
subtitle='数据采集日期:2020年12月'),
)
)
Box.add_xaxis(x_data)
Box.add_yaxis("", Box.prepare_data(y_data))
Box.render_notebook()
那么,各地区均价排名具体如何呢,我们且看,北京高房价其实都是中心城区这几个各项资源都最丰厚的区域所共享的。
均价最贵小区
均价最贵小区前10名均价都超过了17.5万每平米,这些都是什么神仙小区啊!!

看看中信国安府是什么样的存在:位于西城宣武门附近,2018年建的房子,都是超大面积的房子,一套也就4千5百万!!

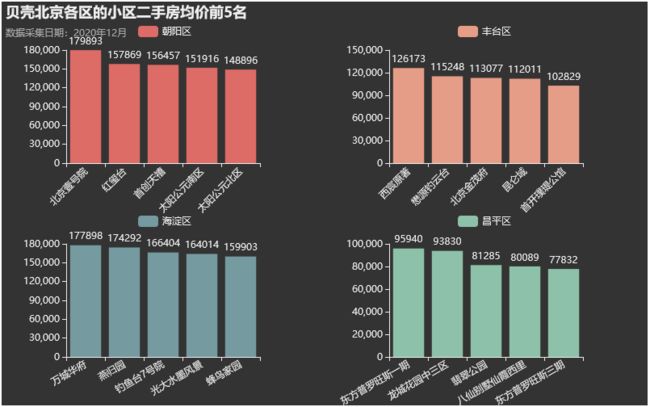
北京房源数最多的四个区域均价最高的小区分别都是谁呢?
朝阳区的 北京壹号院,丰台区的 西宸原著,海淀区的 万城华府,昌平区的 东方普罗旺斯。
4.3.各地区二手房总价
#房价均价分布(1000万以内)
data[data['总价']<1000].总价.mean()
458.2997917446772
**整个北京二手房总价均值为 458万!!**这还不算4000套价值超过1000万的房产。。
以下截图部分,公众号后台回复“**北京二手房总价热力图地址,自由查看更详细信息。
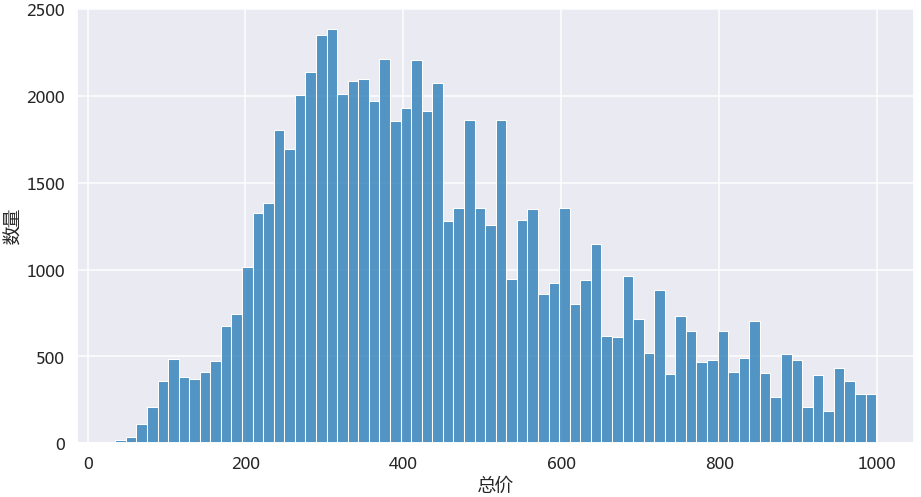
总价直方图(不含1000万以上房产)
总价大部分落在300-500万之间,全市范围内,其实200多万的房子也是比较多的。而100万上下的房子大部分都是所谓的学区房,单间带卫生间的大小在20平米左右,具体大家可以查看原始数据了解哈!!!
总价箱线图(不含1000万以上房产)
从单套的总价上看,依然是东、西城和海淀价格较高,几乎全是500万以上甚至更高。如果要在海淀比较自由的看房,700万预算基本可以覆盖绝大部分房产了,嗯,700万!!

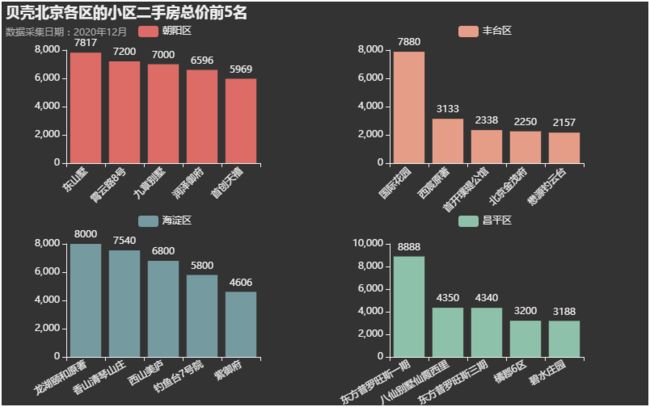
北京房源数最多的四个区域总价均值最高的小区分别都是谁呢?
朝阳区东山墅、霄云路8号,丰台区的国际花园,海淀区的龙湖颐和原著、香山清琴山庄,昌平区的东方普罗米修斯一期都有着7000万以上一套的房子。。
总价最贵在哪里
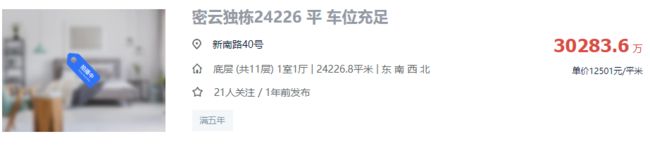
除了第一名位于密云的新南路40号独栋别墅外,就是二环附近的四合院或者奢华小区的高层超大面积户型。当然了,看这些其实没太大意义了!
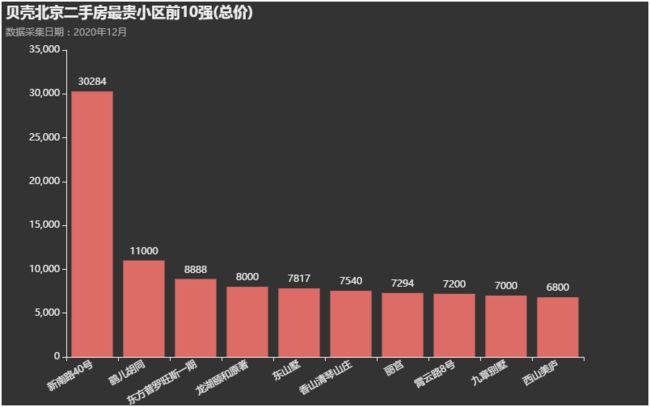
以下是密云的独栋别墅,2.4万平?一共11层的钢混结构!!!
4.4.各地区二手房面积
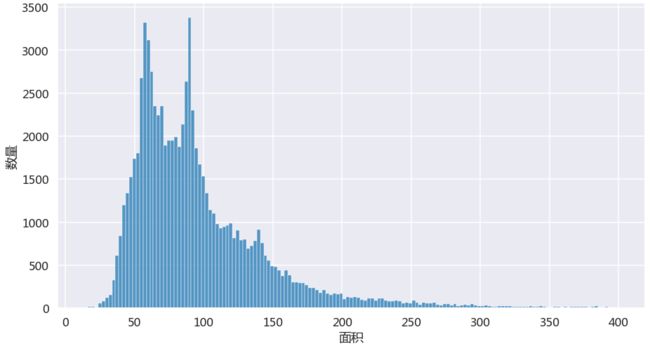
我们去掉房子面积大于400的372套房源,仅统计面积低于400的8万套房源。
面积直方图
在这些房源中,面积在50-70和80-90之间的房源最多,这些基本都是一室一厅、大2居或小3居的居多!
面积箱线图
和房价相反,大户型的房源基本都在非中心城区的区域,当然毕竟单价相对低一些嘛。昌平其实是个很不错的地方,二手房的均价没有海淀朝阳那么贵,但是大户型房源占比更多。

4.5.各地区二手房年限
在北京,大多数的二手房都建于2000-2010之间,几乎全是建于80年代改革开放之后。

4.6.各地区二手房【价格-地区】数量分布
从各地区不同总价区间的房源数来看,价值400-500万的房源最多,其次是价值在500-600万之间的房源。
当然,像东、西城,海淀和朝阳区价值200-250万的房源数也较多,通过更细的数据我们发现这类房子基本都是20多平的挂着学区房的基本不适合居住的小房间!教育资源衍生出来的奇怪房源产物,却又是那么重要且必须!!

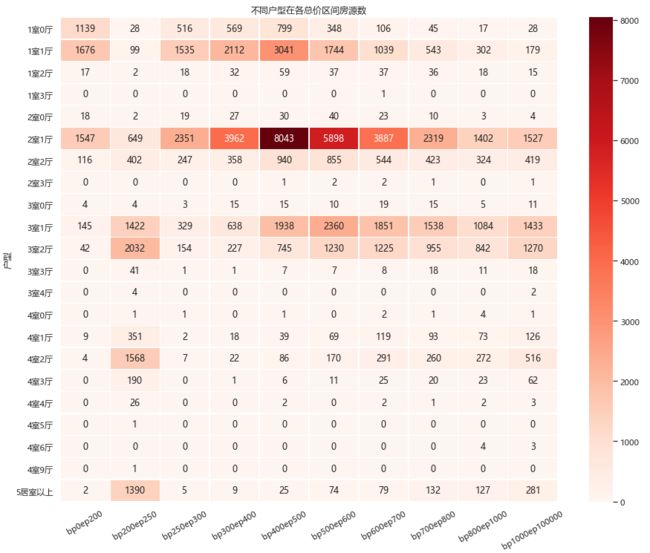
4.7.各地区二手房【户型-价格】数量分布
户型最多的是2居室、3居室和1居室这种适合家庭居住的小家生活房,大部分价格都落在400-500万之间!
4.8.各地区二手房【户型-地区】数量分布
2室1厅这种适合一家三口居住的户型是最多的,几乎不管在哪个区。
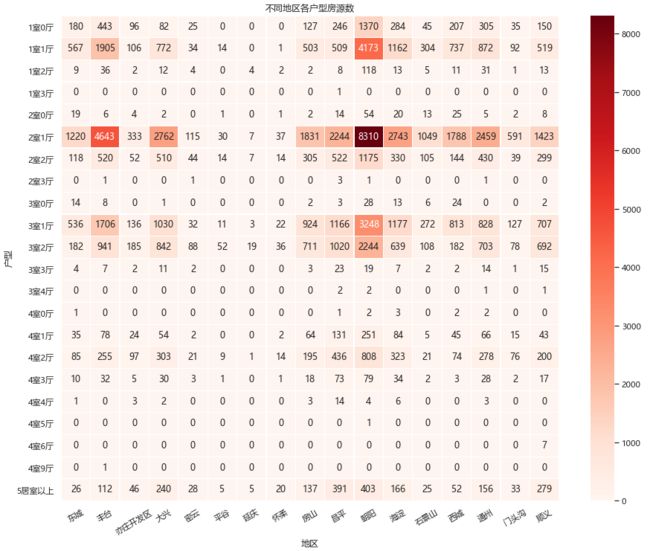
4.9.各地区二手房【户型-地区】均价分布
从不同户型的均价来看,基本上差距不大。我们单看主流的1室1厅、2室1厅和3室1厅对比,似乎1室1厅和3室1厅会比2室1厅均价高那么一点,但也并不明显。本质上还是和地域以及学区有关,中心区域学位多的价格更高!!
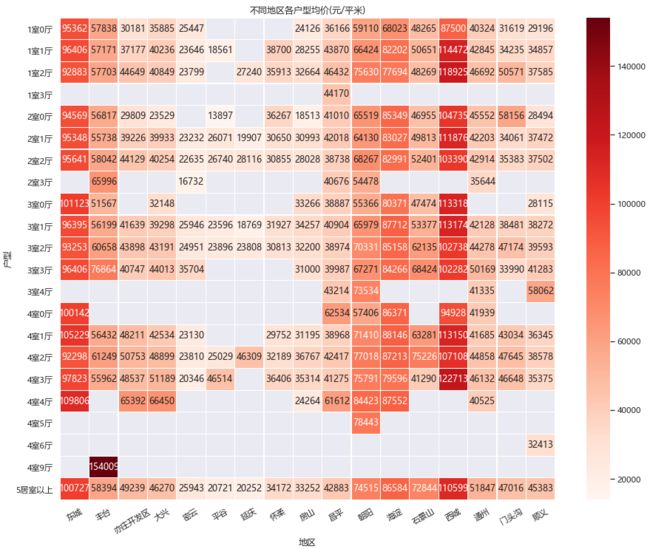
有朋友关注到丰台区有个4室9厅6卫的房子,均价高达15万,其实ta是个别墅!!

5.房源标题及小区词云
关于词云的制作,这里用到的是wordcloud库,本节中的词云作图代码大家可以参见此前文章《》有详细介绍。
贝壳的经纪人在上架房源的时候喜欢用什么样的字眼呢?
- 南北通透 说明采光好、通风透气
- 诚心、诚意出售 诚!
- 满五、五年唯一 可以省钱
其中“满五”是指房产证从出证开始计算,时间满五年或超过五年;
“唯一”则是指业主在该省份内,登记在国土局系统里得只有这一套房子。
通常情况下,房子满足“满五唯一”的条件即可减免房子的个税和营业税。

火火火的小区都有哪些?
这块词云其实就是小区名称房源数的多少决定的,天通苑、芍药居、兴隆家园的房子二手房源真的多啊!!

6.总结
根据2020年12月30日智联招聘发布《2020 年冬季中国雇主需求与白领人才供给报告》,北京平均薪酬为1.19万。
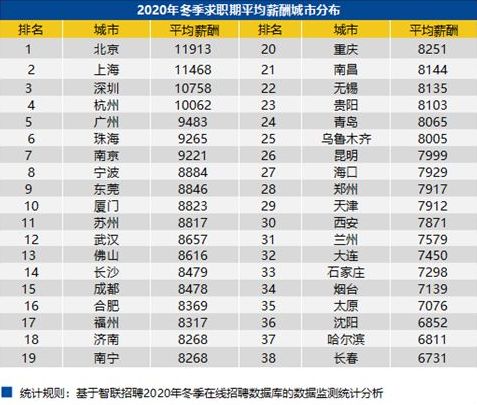
我们假定以总价均价450万为购房总价,按照首付35%,也就是157.5万来算,以年14薪折算,不吃不喝需要10年左右时间可以完成首付,但是在彼时房价数字却也不知道为几何了!!!
