tf2 DSSM双塔模型搭建和user、item侧训练向量获取
数据直接用的moivelens:
链接:https://pan.baidu.com/s/14sY0dKUsb4Pc18qPjVua3Q
提取码:on3v
参考:https://github.com/peiss/ant-learn-recsys
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
# 1. 读取和处理数据
df_user = pd.read_csv(r"C:\\RecommendSys\data\ml\users.dat",
sep="::", header=None, engine="python",
names = "UserID::Gender::Age::Occupation::Zip-code".split("::"))
df_movie = pd.read_csv(r"C:\Utop\ltr测试\RecommendSys\data\ml\movies.dat",
sep="::", header=None, engine="python",
names = "MovieID::Title::Genres".split("::"))
df_rating = pd.read_csv(r"CDesktop\ltr测试\RecommendSys\data\ml\ratings.dat",
sep="::", header=None, engine="python",
names = "UserID::MovieID::Rating::Timestamp".split("::"))
# 只取频率最高的电影分类
import collections
# 计算电影中每个题材的次数
genre_count = collections.defaultdict(int)
for genres in df_movie["Genres"].str.split("|"):
for genre in genres:
genre_count[genre] += 1
# 只保留最有代表性的题材
def get_highrate_genre(x):
sub_values = {}
for genre in x.split("|"):
sub_values[genre] = genre_count[genre]
return sorted(sub_values.items(), key=lambda x:x[1], reverse=True)[0][0]
df_movie["Genres"] = df_movie["Genres"].map(get_highrate_genre)
#给列新增数字索引列,目的是:防止embedding过大
def add_index_column(param_df, column_name):
values = list(param_df[column_name].unique())
value_index_dict = {value:idx for idx,value in enumerate(values)}
param_df[f"{column_name}_idx"] = param_df[column_name].map(value_index_dict)
add_index_column(df_user, "UserID")
add_index_column(df_user, "Gender")
add_index_column(df_user, "Age")
add_index_column(df_user, "Occupation")
add_index_column(df_movie, "MovieID")
add_index_column(df_movie, "Genres")
# 合并成一个df
df = pd.merge(pd.merge(df_rating, df_user), df_movie)
df.drop(columns=["Timestamp", "Zip-code", "Title"], inplace=True)
num_users = df["UserID_idx"].max() + 1
num_movies = df["MovieID_idx"].max() + 1
num_genders = df["Gender_idx"].max() + 1
num_ages = df["Age_idx"].max() + 1
num_occupations = df["Occupation_idx"].max() + 1
num_genres = df["Genres_idx"].max() + 1
#评分的归一化
min_rating = df["Rating"].min()
max_rating = df["Rating"].max()
df["Rating"] = df["Rating"].map(lambda x : (x-min_rating)/(max_rating-min_rating))
#构建训练数据集
df_sample = df.sample(frac=0.1)
X = df_sample[["UserID_idx","Gender_idx","Age_idx","Occupation_idx","MovieID_idx","Genres_idx"]]
y = df_sample.pop("Rating")
#2. 搭建双塔模型并训练
def get_model():
"""函数式API搭建双塔DNN模型"""
# 输入
user_id = keras.layers.Input(shape=(1,), name="user_id")
gender = keras.layers.Input(shape=(1,), name="gender")
age = keras.layers.Input(shape=(1,), name="age")
occupation = keras.layers.Input(shape=(1,), name="occupation")
movie_id = keras.layers.Input(shape=(1,), name="movie_id")
genre = keras.layers.Input(shape=(1,), name="genre")
# user 塔
user_vector = tf.keras.layers.concatenate([
layers.Embedding(num_users, 100)(user_id),
layers.Embedding(num_genders, 2)(gender),
layers.Embedding(num_ages, 2)(age),
layers.Embedding(num_occupations, 2)(occupation)
])
user_vector = layers.Dense(32, activation='relu')(user_vector)
user_vector = layers.Dense(8, activation='relu',
name="user_embedding", kernel_regularizer='l2')(user_vector)
# movie塔
movie_vector = tf.keras.layers.concatenate([
layers.Embedding(num_movies, 100)(movie_id),
layers.Embedding(num_genres, 2)(genre)
])
movie_vector = layers.Dense(32, activation='relu')(movie_vector)
movie_vector = layers.Dense(8, activation='relu',
name="movie_embedding", kernel_regularizer='l2')(movie_vector)
# 每个用户的embedding和item的embedding作点积
dot_user_movie = tf.reduce_sum(user_vector*movie_vector, axis = 1)
dot_user_movie = tf.expand_dims(dot_user_movie, 1)
output = layers.Dense(1, activation='sigmoid')(dot_user_movie)
return keras.models.Model(inputs=[user_id, gender, age, occupation, movie_id, genre], outputs=[output])
model = get_model()
model.compile(loss=tf.keras.losses.MeanSquaredError(),
optimizer=keras.optimizers.RMSprop())
fit_x_train = [
X["UserID_idx"],
X["Gender_idx"],
X["Age_idx"],
X["Occupation_idx"],
X["MovieID_idx"],
X["Genres_idx"]
]
history = model.fit(
x=fit_x_train,
y=y,
batch_size=32,
epochs=5,
verbose=1,
)
3. 模型的预估-predict
inputs = df.sample(frac=1.0)[
["UserID_idx","Gender_idx","Age_idx","Occupation_idx","MovieID_idx", "Genres_idx"]].head(10)
# 对于(用户ID,召回的电影ID列表),计算分数
model.predict([
inputs["UserID_idx"],
inputs["Gender_idx"],
inputs["Age_idx"],
inputs["Occupation_idx"],
inputs["MovieID_idx"],
inputs["Genres_idx"]
])
4、模型的保存与加载使用
model.save("./datas/ml-latest-small/tensorflow_two_tower.h5")
new_model = tf.keras.models.load_model("./datas/ml-latest-small/tensorflow_two_tower.h5")
new_model.predict([
inputs["UserID_idx"],
inputs["Gender_idx"],
inputs["Age_idx"],
inputs["Occupation_idx"],
inputs["MovieID_idx"],
inputs["Genres_idx"]
])
5、保存模型的embedding可用于召回
#user embedding
user_layer_model = keras.models.Model(
inputs=[model.input[0], model.input[1], model.input[2], model.input[3]],
outputs=model.get_layer("user_embedding").output
)
for index, row in df_user.iterrows():
user_id = row["UserID"]
user_input = [
np.reshape(row["UserID_idx"], [1,1]),
np.reshape(row["Gender_idx"], [1,1]),
np.reshape(row["Age_idx"], [1,1]),
np.reshape(row["Occupation_idx"], [1,1])
]
user_embedding = user_layer_model(user_input)
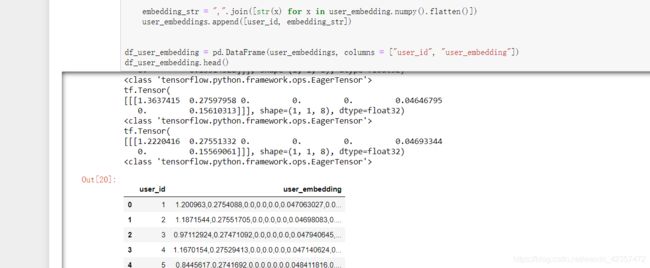
embedding_str = ",".join([str(x) for x in user_embedding.numpy().flatten()])
user_embeddings.append([user_id, embedding_str])
df_user_embedding = pd.DataFrame(user_embeddings, columns = ["user_id", "user_embedding"])
df_user_embedding.head()
#imoive embedding
movie_layer_model = keras.models.Model(
inputs=[model.input[4], model.input[5]],
outputs=model.get_layer("movie_embedding").output
)
for index, row in df_movie.iterrows():
movie_id = row["MovieID"]
movie_input = [
np.reshape(row["MovieID_idx"], [1,1]),
np.reshape(row["Genres_idx"], [1,1])
]
movie_embedding = movie_layer_model(movie_input)
embedding_str = ",".join([str(x) for x in movie_embedding.numpy().flatten()])
movie_embeddings.append([movie_id, embedding_str])
df_movie_embedding = pd.DataFrame(movie_embeddings, columns = ["movie_id", "movie_embedding"])
df_movie_embedding.head()
output = "./datas/ml-latest-small/tensorflow_movie_embedding.csv"
df_movie_embedding.to_csv(output, index=False)