【AI视野·今日CV 计算机视觉论文速览 第189期】Fri, 1 Jan 2021
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 1 Jan 2021
Totally 98 papers
上期速览✈更多精彩请移步主页

Interesting:
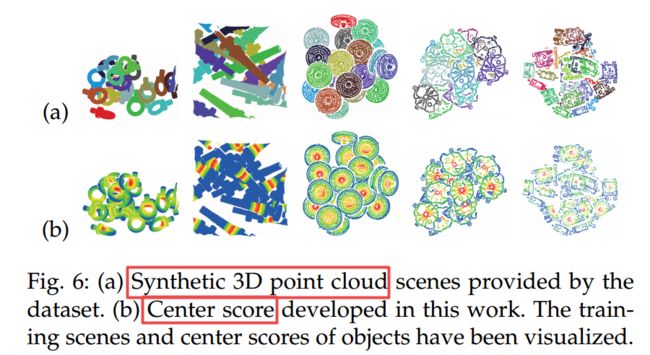
****FPCC-Net, 用于实例分割的高速点云聚类算法,主要用于机器人抓取问题,处理多个同种物体的实例分割。 bin-picking 场景的应用。(from 东北大学 日本Tohoku)
在机器人抓取的场景中,互相遮挡的同类物体区分十分复杂,所以需要高效的三维实例分割算法。其中主要包含两个模块,一个用于推理出特征中心,另一个用于描述每个点的特征。

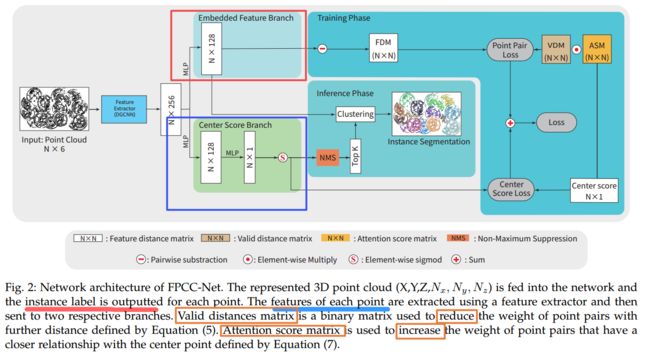


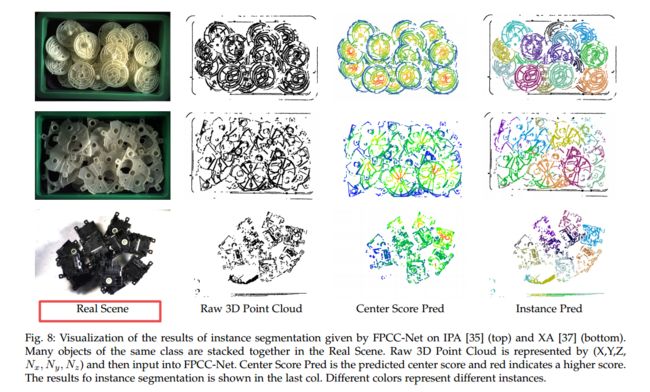
dataset:Fraunhofer IPA Bin-Picking dataset (IPA) [35] ,XA Bin-Picking dataset (XA) [37]
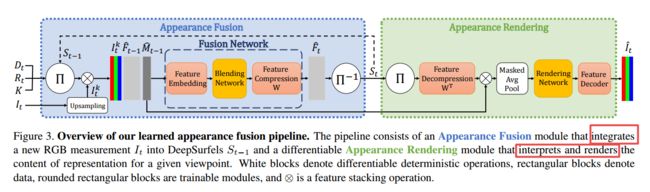
**DeepSurfels,一种用于几何与外观的混合场景表示方法,使用了显式和神经网络方式来对几何特征与外观信息进行联合编码,对高频特征表示较好,同时适用于在线更新与融合。Scene Representations (from ETH Zurich)

几何拟合过程:

两个模块的具体构成:

3D models from free3d.com and turbosquid.com
*DEEPSPHERE, 一种基于图的球卷积。(from 洛桑理工)
一些球空间的数据示例:

https://github.com/deepsphere
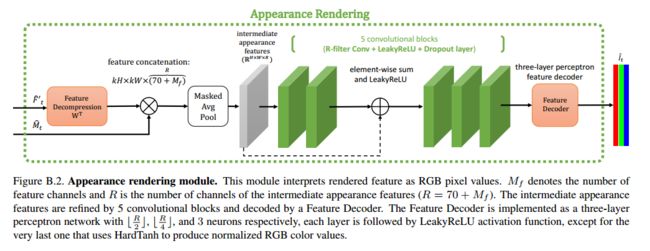
OSTeC, 单样本人脸纹理补全,将侧脸转为正脸(from 帝国理工)
https://github.com/barisgecer/OSTeC
DUT-LFSaliency多功能的光场数据集, 可实现RGB,RGBD和光场的显著性检测,并提出了聚焦流和RGB流两种光场表示的模型,分别用于台式机和移动端。(from 大连理工)
本文提出的双信息流检测算法:

现有的光场数据集比较



code:https://github.com/OIPLab-DUT/DUTLF-V2
**快速高光谱图像重建算法,编码孔径快照光谱成像技术,双目相机压缩的图像中快速重建/ (from RIKEN)
Coded aperture snapshot spectral imaging (CASSI)可利用2D测量来捕获高光谱图像。RGB用于估计稀疏,CASSI测量用于提供正交光谱信息。(ref:https://www.doc88.com/p-0711464143433.html)


高光谱数据集dataset:
https://www.usgs.gov/ http://icvl.cs.bgu.ac.il/hyperspectral/ http://www1.cs.columbia.edu/CAVE/databases/multispectral/
一种高光谱相机:https://www.specim.fi/spectral-cameras/
DeSCI:https://github.com/liuyang12/DeSCI
SCI将多帧压缩成一帧的方法 Snapshot compressive imaging:https://arxiv.org/pdf/1807.07837.pdf
*NeuralMagicEye, 魔眼算法autostereogram,看到隐藏在图像后的物体(from 密歇根大学安娜堡分校)


CorrNet3D, 一种非监督方法用于稠密点云间特征匹配。(from 香港城市大学)。
这一模型除了特征抽取模块外,还包括对应指示器和对称变形模块组成。它们可以生成对应矩阵并将输入的两个点云进行相互转换,用于无监督的方式驱动模型学习出两个点云间的特征。

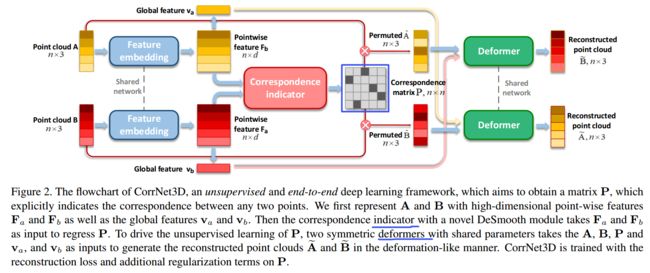
对应指示器用于生成两个点云特征间的对应矩阵,转换器用于点云间的互相转换:

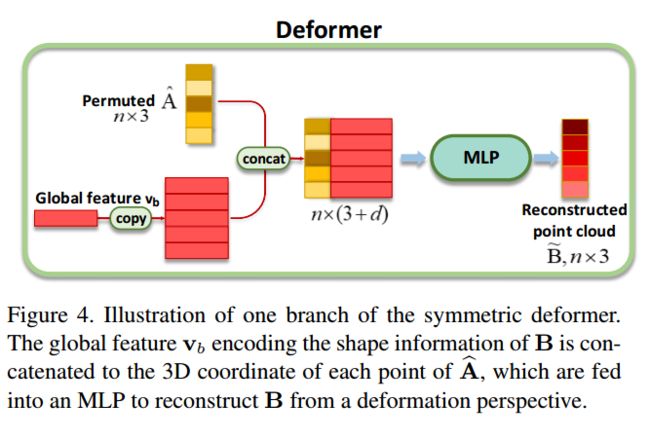
对应的颜色显示了点云每部分的对应程度:

non-rigid: Surreal [13] as the training dataset, test on the SHREC dataset [10]
rigid shape: Surreal dataset [13]
related methods:DeepGFM [10], DCP [47] and RPMNet [50]
SparsePipe用于点云的并行计算框架, 多GPU支持点云这类稀疏数据计算,构建了稀疏张量表示(from 弗罗里达大学)

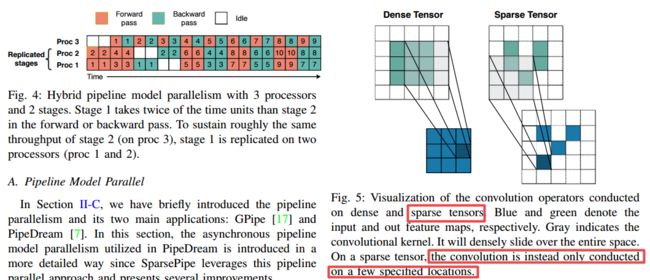
稀疏卷积库:https://github.com/traveller59/spconv
**视频处理教学系统,包括详实的教材和真实世界的样本,以及交互式的课程组织。 (from 德克萨斯大学奥斯丁分校)



课程:EE381V
光照估计相关工作总结与综述, (from Institute for Information Transmission Problems 俄罗斯)
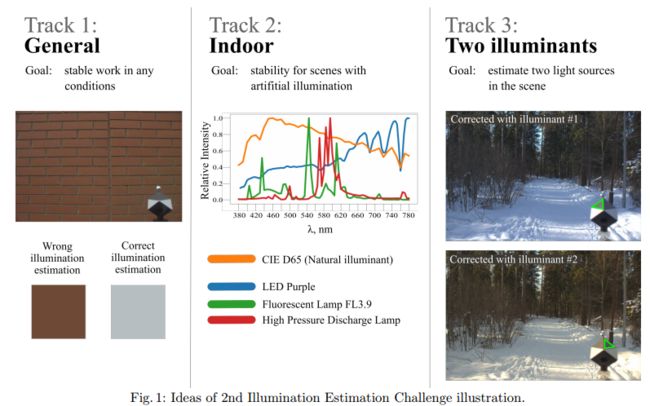
SpyderCube calibration object Cube+ dataset that was used in IEC#1
利用摄像头的心率检测, (from VicarVision)
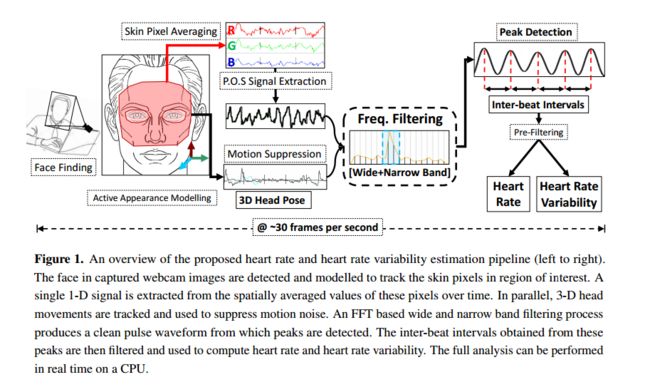
dataset:: www.vicarvision.nl/datasets/vicarppg2
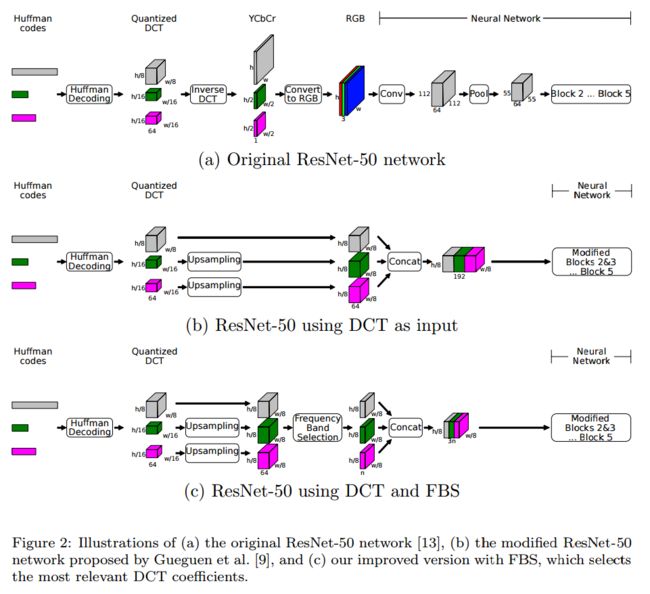
直接在边缘设备上利用视频压缩编码来进行深度学习, (from Universidade Federal de S˜ao Paulo巴西)

多媒体仇恨言论检测, (from Abhishek Das)


肠镜的息肉检测和分割, (from SimulaMet UiT The Arctic University of Norway)

MediaEval 2020 dataset:Kvasir-SEG
https://multimediaeval.github.io/editions/2020/tasks/medico/
什么样的视频令人印象深刻, (from University of Essex, UK)

MediaEval 2020
dataset:TRECVid 2019 Video-to-Text dataset
FLAME森林火警数据集, (from Northern Arizona University, US)

https://ieee-dataport.org/open-access/flame-dataset-aerial-imagery-pile-burn-detection-using-drones-uavs
Daily Computer Vision Papers
| Real-time Webcam Heart-Rate and Variability Estimation with Clean Ground Truth for Evaluation Authors Amogh Gudi, Marian Bittner, Jan van Gemert 远程体积容积描记法rPPG使用相机估计人的心率HR。类似于心率如何提供有关人的生命体征的有用信息,可以从心率变异性HRV获得有关潜在生理心理状况的见解。 HRV是心跳间隔中细微波动的量度。但是,该措施需要高精度地临时定位心跳。我们引入了一种经过改进的高效实时rPPG管道,该管道具有新颖的滤波和运动抑制功能,不仅可以估算心率,还可以提取脉搏波形以计时心跳并测量心率变异性。这种不受监督的方法不需要rPPG专门培训,并且能够实时运行。我们还将介绍一个新的多模态视频数据集VicarPPG 2,该数据集专门用于评估HR和HRV估计上的rPPG算法。我们在各种条件下,在广泛的公共和自记录数据集上验证和研究了我们的方法,显示了最新的结果并提供了对某些独特方面的有用见解。最后,我们提供CleanerPPG,它是现有rPPG数据集的经过人工验证的地面真实峰值心跳注释的集合。这些经过验证的注释应使rPPG算法的未来评估和基准测试更加准确,标准化和公平。 |
| Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers Authors Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip H.S. Torr, Li Zhang 最新的语义分段方法采用具有编码器解码器体系结构的全卷积网络FCN。编码器逐渐降低空间分辨率,并学习具有更大接收域的更多抽象语义视觉概念。由于上下文建模对于分割至关重要,因此,最新的工作集中在通过扩大的无声卷积或插入注意模块来增加接受域。但是,基于编码器解码器的FCN体系结构保持不变。在本文中,我们旨在通过将语义分割视为序列预测任务的序列来提供替代观点。具体来说,我们部署了一个纯变换器,即不进行卷积和分辨率降低,而是将图像编码为补丁序列。通过在变压器的每一层中建模全局上下文,该编码器可以与简单的解码器组合以提供功能强大的分段模型,称为SEgmentation TRANSformer SETR。广泛的实验表明,SETR在ADE20K 50.28 mIoU,Pascal Context 55.83 mIoU和Cityscapes的竞争结果方面达到了新的水平。特别是,我们在竞争激烈的ADE20K测试服务器排行榜中获得了第一个44.42 mIoU的位置。 |
| Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans Authors Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, Xiaowei Zhou 本文从非常稀疏的摄像机视图集中解决了人类表演者新颖的视图合成所面临的挑战。最近的一些工作表明,在密集的输入视图下,学习3D场景的隐式神经表示可实现非凡的视图合成质量。但是,如果视图非常稀疏,则表示学习将不适当。为了解决这个不适的问题,我们的关键思想是整合对视频帧的观察。为此,我们提出了一种新的人体表示形式“神经体”,它假设在不同框架上学习到的神经表示共享锚定在可变形网格上的同一组潜在代码,从而可以自然地整合跨框架的观察结果。可变形网格还为网络提供了几何指导,以更有效地学习3D表示。在新收集的多视图数据集上进行的实验表明,在视图合成质量方面,我们的方法大大优于以前的工作。我们还展示了我们的方法从People Snapshot数据集上的单目视频中重建移动的人的能力。代码和数据集将在以下位置提供 |
| A CNN Approach to Simultaneously Count Plants and Detect Plantation-Rows from UAV Imagery Authors Lucas Prado Osco, Mauro dos Santos de Arruda, Diogo Nunes Gon alves, Alexandre Dias, Juliana Batistoti, Mauricio de Souza, Felipe David Georges Gomes, Ana Paula Marques Ramos, L cio Andr de Castro Jorge, Veraldo Liesenberg, Jonathan Li, Lingfei Ma, Jos Marcato Junior, Wesley Nunes Gon alves 在本文中,我们提出了一种基于卷积神经网络CNN的新颖的深度学习方法,该方法可以同时检测并定位人工林行,同时考虑到高度密集的人工林配置对其植物进行计数。在具有不同生长阶段的玉米田和柑橘园中评估了实验设置。这两个数据集都表征了不同的植物密度情景,位置,农作物类型,传感器和日期。在我们的CNN方法中实现了两个分支的体系结构,其中,在种植行中获得的信息被更新为植物检测分支,并向行分支进行逆向输入,然后通过多阶段优化方法对其进行优化。在具有成年和成熟两个生长阶段的玉米种植数据集中,我们的方法返回的每个图像斑块的平均绝对误差MAE为6.224株,平均相对误差MRE为0.1038,精确度和召回率分别为0.856和0.905,并且F度量等于0.876。这些结果优于使用相同任务和数据集评估的其他深度网络HRNet,Faster R CNN和RetinaNet的结果。对于人工林行检测,我们的方法分别返回0.913、0.941和0.925的精度,召回率和F量度分数。为了测试模型在不同农业类型下的稳健性,我们在柑桔园数据集中执行了相同的任务。它返回的MAE等于每个补丁1.409棵柑橘树,MRE为0.0615,精度为0.922,召回率为0.911,F值为0.965。对于柑橘种植园行检测,我们的方法得出的精确度,召回率和F度量值分别等于0.965、0.970和0.964。所提出的方法实现了对来自不同类型农作物的无人机图像中的植物和植物行进行计数和地理定位的最新技术性能。 |
| iGOS++: Integrated Gradient Optimized Saliency by Bilateral Perturbations Authors Saeed Khorram, Tyler Lawson, Fuxin Li 深度网络的黑匣子性质解释了为什么他们做出某些预测极具挑战性。显着图是缓解此问题的最广泛使用的本地解释工具之一。生成显着性图的主要方法之一是通过在输入维度上优化掩码,以使网络的输出受到掩码的影响最大。但是,先前的工作仅通过从输入中删除证据来研究这种影响。在本文中,我们介绍了iGOS,它是生成显着图的框架,该显着图经过优化,可以通过删除或保留一小部分输入来更改黑盒系统的输出。此外,我们建议在优化中添加一个双边总变化项,以提高显着性图的连续性,尤其是在高分辨率和薄物体部分的情况下。通过将iGOS与最新的显着性图方法进行比较得出的评估结果显示,在定位人类可以直接解释的显着区域方面,有了显着的改进。我们将iGOS用于从X射线图像中对19例COVID病例进行分类的任务中,发现在进行分类时,有时CNN网络会过度适合打印在X射线图像上的字符。通过数据清理解决此问题,大大提高了分类器的准确性和召回率。 |
| Illumination Estimation Challenge: experience of past two years Authors Egor Ershov, Alex Savchik, Ilya Semenkov, Nikola Bani , Karlo Koscevi , Marko Suba i , Alexander Belokopytov, Zhihao Li, Arseniy Terekhin, Daria Senshina, Artem Nikonorov, Yanlin Qian, Marco Buzzelli, Riccardo Riva, Simone Bianco, Raimondo Schettini, Sven Lon ari , Dmitry Nikolaev 照明估计是计算色彩恒定性的必要步骤,它是现代数码相机各种图像处理管道的核心部分之一。具有准确而可靠的照度估算对于减少照度对图像颜色的影响很重要。为了激励这一领域的新思想的产生和新算法的发展,进行了第二次照明估计挑战IEC 2。与在某些已知数据集上进行测试相比,对挑战进行测试的主要优势在于,直到提交结果之前,挑战测试图像的地面真相照明都是未知的,这可以防止可能进行的任何超参数调整有偏见。 |
| SelectScale: Mining More Patterns from Images via Selective and Soft Dropout Authors Zhengsu Chen, Jianwei Niu, Xuefeng Liu, Shaojie Tang 卷积神经网络CNN在图像识别方面取得了显著成功。尽管CNN有效地学习了输入图像的内部模式,但是这些模式仅构成输入图像中包含的有用模式的一小部分。这可以归因于这样一个事实,即如果所学习的模式足以进行正确的分类,则CNN将停止学习。诸如dropout和SpatialDropout之类的网络正则化方法可以缓解此问题。在训练期间,他们会随机删除这些功能。从本质上讲,这些辍学方法会改变网络学习的模式,进而迫使网络学习其他模式以进行正确的分类。然而,上述方法具有重要的缺点。随机丢弃特征通常效率低下,并且会引入不必要的噪声。为了解决这个问题,我们建议使用SelectScale。 SelectScale可以随机选择网络中的重要功能,并在训练过程中对其进行调整,而不是随机丢弃它们。使用SelectScale,我们可以提高CIFAR和ImageNet上CNN的性能。 |
| Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection Authors Jiajun Deng, Shaoshuai Shi, Peiwei Li, Wengang Zhou, Yanyong Zhang, Houqiang Li 3D对象检测的最新进展在很大程度上取决于如何表示3D数据,即基于体素或基于点的表示。许多现有的高性能3D检测器都是基于点的,因为这种结构可以更好地保留精确的点位置。然而,由于无序存储,点级功能导致高计算开销。相反,基于体素的结构更适合于特征提取,但由于输入数据被划分为网格,因此通常产生较低的精度。在本文中,我们采取略有不同的观点,我们发现原始点的精确定位对于高性能3D对象检测不是必不可少的,并且粗体素粒度还可以提供足够的检测精度。牢记这一观点,我们设计了一个简单但有效的基于体素的框架,名为Voxel R CNN。通过在两阶段方法中充分利用体素功能,我们的方法可实现与基于点的最新模型可比的检测精度,但计算成本却很小。 Voxel R CNN由3D骨干网络,2D鸟瞰BEV区域提议网络和检测头组成。设计了体素RoI池以直接从体素特征中提取RoI特征,以进行进一步优化。在广泛使用的KITTI数据集和最新的Waymo Open数据集上进行了广泛的实验。我们的结果表明,与现有的基于体素的方法相比,Voxel R CNN可以提供更高的检测精度,同时在NVIDIA RTX 2080 Ti GPU上以25 FPS的速度保持实时帧处理速率(emph)。该代码将很快发布。 |
| NeuralMagicEye: Learning to See and Understand the Scene Behind an Autostereogram Authors Zhengxia Zou, Tianyang Shi, Yi Yuan, Zhenwei Shi 自动立体图,又称魔术眼图像,是可以从2D纹理创建3D场景的视觉幻觉的单个图像立体图。本文研究了一个有趣的问题,即能否训练深层的CNN来恢复自动立体图背后的深度并理解其内容。自动立体图魔术的关键在于解决这种问题的立体视觉,模型必须学会发现和估计准周期性纹理的差异。我们展示了嵌入视差卷积的深CNN,这是本文提出的一种新颖的卷积层,可以模拟立体视点并编码视差,在以自我监督的方式在大型3D对象数据集上经过充分训练后,可以很好地解决此类问题。我们将我们的方法称为NeuralMagicEye。实验表明,该方法可以准确地恢复自动立体图背后的深度,并具有丰富的细节和渐变平滑度。实验还显示了神经网络和人眼之间自动立体图感知的完全不同的工作机制。我们希望这项研究可以帮助有视觉障碍的人和查看自动立体图有困难的人。我们的代码可从url获得 |
| CNN-based Single Image Crowd Counting: Network Design, Loss Function and Supervisory Signal Authors Haoyue Bai, S. H. Gary Chan 单图像人群计数是一个具有挑战性的计算机视觉问题,在公共安全,城市规划,交通管理等方面具有广泛的应用。本次调查旨在通过密度图估计,对基于卷积神经网络CNN的最新高级人群计数技术进行全面总结。我们的目标是提供有关最新方法的最新评论,并教育该领域的新研究人员设计原则和权衡取舍。在介绍了公开可用的数据集和评估指标之后,我们将对三个主要设计模块进行详细比较,以对最新进展进行回顾,以对深度神经网络设计,损失函数和监督信号进行人群计数。我们以一些未来的方向来结束调查。 |
| Unsupervised Monocular Depth Reconstruction of Non-Rigid Scenes Authors Ay a Takmaz, Danda Pani Paudel, Thomas Probst, Ajad Chhatkuli, Martin R. Oswald, Luc Van Gool 复杂和动态场景的单眼深度重建是一个极具挑战性的问题。尽管对于刚性场景,基于学习的方法即使在无人监督的情况下也已提供了令人鼓舞的结果,但几乎没有文献针对动态和可变形场景解决同样的问题。在这项工作中,我们提出了一种用于动态场景密集深度估计的无监督单目框架,该框架可以联合重建刚性和非刚性零件,而无需显式建模摄像机运动。使用密集的对应关系,我们得出了一个训练目标,旨在机会性地保留重建的3D点之间的成对距离。在此过程中,使用尽可能严格的假设隐式地学习密集深度图。我们的方法提供了令人鼓舞的结果,证明了其从非刚性场景的具有挑战性的视频中重建3D的能力。此外,所提出的方法还提供了无监督的运动分割结果作为辅助输出。 |
| CorrNet3D: Unsupervised End-to-end Learning of Dense Correspondence for 3D Point Clouds Authors Yiming Zeng, Yue Qian, Zhiyu Zhu, Junhui Hou, Hui Yuan, Ying He 本文解决了以点云的形式计算3D形状之间的密集对应关系的问题,这是计算机视觉和数字几何处理中具有挑战性和根本的问题。常规方法通常以监督方式解决该问题,需要大量带注释的数据,这很难获得或昂贵。出于这样的直觉,即人们可以比未对齐的对更容易,更有意义地将两个对齐的点云彼此转换,因此我们提出了CorrNet3D,这是第一个无监督的,端到端的深度学习框架,通过像重建以克服对带注释数据的需求。具体来说,CorrNet3D包含一个深层特征嵌入模块和两个名为对应指示器和对称变形的新颖模块。馈入一对原始点云,我们的模型首先学习点状特征,并将其传递到指标中,以生成用于对输入对进行置换的可学习的对应矩阵。具有附加正则损失的对称变形器将两个置换的点云彼此转换,以驱动对对应关系的无监督学习。在刚性和非刚性3D形状的合成数据集和真实世界数据集上进行的广泛实验表明,我们的CorrNet3D在很大程度上优于最新方法,包括那些以网格为输入的方法。 CorrNet3D是一个灵活的框架,如果有注释的数据可用,它可以轻松地适应监督学习。 |
| A Deep Retinal Image Quality Assessment Network with Salient Structure Priors Authors Ziwen Xu, beiji Zou, Qing Liu 视网膜图像质量评估是诊断视网膜疾病的必要前提。它的目的是识别清晰清晰地显示出吸引眼科医生关注的解剖结构和病变的视网膜图像,同时剔除劣质眼底图像。因此,我们模仿了眼科医生评估视网膜图像质量的方法,并提出了一种称为SalStructuIQA的方法。首先,两个重要的结构用于自动视网膜质量评估。一种是大尺寸的突出结构,包括视盘区域和大尺寸的渗出液。另一个是微小的显着结构,主要包括血管。然后,我们将提出的两个显着结构先验与深度卷积神经网络CNN合并,以将CNN的重点转移到显着结构上。因此,我们开发了两种CNN架构:双分支SalStructIQA和单分支SalStructIQA。双分支SalStructIQA包含两个CNN分支,一个分支由大尺寸的突出结构引导,而另一个分支由小尺寸的突出结构引导。单个分支SalStructIQA包含一个CNN分支,该分支由大小和大小均显着的结构的串联引导。在Eye Quality数据集上的实验结果表明,我们提出的双分支SalStructIQA优于目前用于视网膜图像质量评估的方法,而Single Branch SalStructIQA与最先进的深度视网膜图像质量评估方法相比重量轻,并且仍具有竞争优势。 |
| Patch-wise++ Perturbation for Adversarial Targeted Attacks Authors Lianli Gao, Qilong Zhang, Jingkuan Song, Heng Tao Shen 尽管在针对深度神经网络DNN的对抗攻击方面已取得了巨大进展,但其可传递性仍然不尽人意,尤其是针对有针对性的攻击。有两个长期以来被忽视的问题:1传统的T迭代设置具有epsilon T的步长以符合epsilon约束。在这种情况下,大多数像素都可以添加非常小的噪声,这比epsilon和2通常要处理的像素噪声要少得多。然而,由DNN提取的像素的特征受其周围区域的影响,并且不同的DNN通常在识别中着重于不同的区分区域。为了解决这些问题,我们提出了一种补丁式迭代方法PIM,旨在制作具有高可移植性的对抗示例。具体来说,我们在每次迭代中为步长引入一个放大因子,并且溢出一个epsilon约束的一个像素s的整体坡度由项目内核适当地分配给其周围区域。但是有针对性的攻击旨在将对抗性示例推入特定类别的领域,并且放大系数可能会导致拟合不足。因此,我们介绍了温度,并提出了一种逐块迭代方法PIM,以在不显着牺牲白盒攻击性能的情况下进一步提高可传递性。我们的方法通常可以集成到任何基于梯度的攻击方法中。与当前最先进的攻击方法相比,我们将防御模型的成功率平均提高了35.9,对于经过常规训练的模型,则平均提高了32.7。 |
| Incremental Embedding Learning via Zero-Shot Translation Authors Kun Wei, Cheng Deng, Xu Yang, Maosen Li 通过学习一组预定义的数据集,现代深度学习方法在机器学习和计算机视觉领域取得了巨大的成功。但是,当将这些方法应用于现实世界时,它们的性能不能令人满意。这种现象的原因是,学习新任务导致训练有素的模型很快忘记了旧任务的知识,这被称为灾难性的忘记。当前最先进的增量学习方法可解决传统分类网络中的灾难性遗忘问题,而忽略了嵌入网络中存在的问题,后者是图像检索,人脸识别,零镜头学习等的基本网络。与传统的增量分类网络不同,在相邻学习环境下,嵌入网络是两个相邻任务的嵌入空间之间的语义鸿沟。因此,我们提出了一种新型的嵌入网络类增量方法,称为零镜头翻译类增量方法ZSTCI,它利用零镜头翻译来估计和补偿语义间隙而没有任何示例。然后,我们尝试在顺序学习过程中为两个相邻任务学习统一的表示形式,从而准确地捕获先前课程和当前课程的关系。此外,ZSTCI可以轻松地与现有的基于正则化的增量学习方法结合使用,以进一步提高嵌入网络的性能。我们对CUB 200 2011和CIFAR100进行了广泛的实验,实验结果证明了该方法的有效性。我们的方法代码已发布。 |
| Audio-Visual Floorplan Reconstruction Authors Senthil Purushwalkam, Sebastian Vicenc Amengual Gari, Vamsi Krishna Ithapu, Carl Schissler, Philip Robinson, Abhinav Gupta, Kristen Grauman 仅需看一眼环境,我们就可以推断出整个平面图的多少。现有方法只能映射从上下文可见或立即可见的内容,因此需要在空间中进行大量移动才能完全映射它。我们探讨了音频和视觉传感如何共同从有限的角度提供快速的平面图重建。音频不仅有助于感知相机视野之外的几何形状,而且还揭示了远方自由空间的存在,例如,狗在另一个房间里吠叫,并暗示了相机看不见的房间的存在,例如,洗碗机在嗡嗡声中嗡嗡作响是左边的厨房。我们介绍了AV Map,这是一种新颖的多模式编码器解码器框架,该框架共同针对音频和视觉进行推理,以从短输入视频序列中重建平面图。我们训练模型来预测环境的内部结构和相关房间的语义标签。我们在85个大型现实环境中获得的结果仅显示了一个区域26个区域的几处瞥见,因此,我们可以以66个精度估算整个区域,其效果明显优于现有的可视化地图推断方法。 |
| Learned Multi-Resolution Variable-Rate Image Compression with Octave-based Residual Blocks Authors Mohammad Akbari, Jie Liang, Jingning Han, Chengjie Tu 最近,基于深度学习的图像压缩已显示出超越传统编解码器的潜力。然而,大多数现有方法针对多个比特率训练多个网络,这增加了实现复杂性。在本文中,我们提出了一个新的可变速率图像压缩框架,该框架使用广义八度音阶卷积GoConv和广义八度音阶转置卷积GoTConv,并内置了广义除数归一化GDN和逆GDN IGDN层。在编码器和解码器网络中,还开发了基于GoConv和GoTConv的新型残差块。我们的方案还使用基于随机舍入的标量量化。为了进一步提高性能,我们将来自解码器网络的输入和重建图像之间的残差编码为增强层。为了使单个模型能够以不同的比特率运行并学习多速率图像特征,引入了新的目标函数。实验结果表明,所提出的采用可变速率目标函数训练的框架优于标准编解码器,例如基于H.265 HEVC的BPG和基于最新技术的可变速率方法。 |
| TransTrack: Multiple-Object Tracking with Transformer Authors Peize Sun, Yi Jiang, Rufeng Zhang, Enze Xie, Jinkun Cao, Xinting Hu, Tao Kong, Zehuan Yuan, Changhu Wang, Ping Luo 多目标跟踪MOT主要由检测算法进行的复杂和多步跟踪控制,该算法分别执行目标检测,特征提取和时间关联。单目标跟踪SOT中的查询关键机制通过前一帧的目标特征来跟踪当前帧的目标,具有建立简单的联合检测和跟踪MOT范式的巨大潜力。但是,由于查询键方法无法检测新出现的对象,因此很少进行研究。在这项工作中,我们提出了TransTrack,这是使用Transformer进行MOT的基准。它利用查询键机制,并将一组学习到的对象查询引入管道中,以检测新的即将到来的对象。 TransTrack具有三个主要优点:1是基于查询键机制的在线联合检测和跟踪管道。简化了先前方法中的复杂步骤和多步骤组件。 2这是基于Transformer的全新体系结构。学习的对象查询将检测当前帧中的对象。来自上一帧的对象特征查询将那些当前对象与先前的对象相关联。 3我们首次展示了一种基于查询键机制的简单有效的方法,而Transformer体系结构可以在MOT17挑战数据集上实现具有竞争力的65.8 MOTA。我们希望TransTrack可以为多对象跟踪提供新的视角。该代码位于url |
| SID: Incremental Learning for Anchor-Free Object Detection via Selective and Inter-Related Distillation Authors Can Peng, Kun Zhao, Sam Maksoud, Meng Li, Brian C. Lovell 增量学习需要一个模型来从流数据中不断学习新任务。但是,在新任务上对训练有素的深度神经网络进行传统的微调会极大地降低旧任务的性能,这是一个灾难性的遗忘问题。在本文中,我们在无锚对象检测的背景下解决了这个问题,这是计算机视觉的一种新趋势,因为它简单,快速且灵活。由于缺乏对特定模型结构的考虑,在这些无锚检测器上简单地采用当前的增量学习策略是失败的。为了应对无锚对象检测器上增量学习的挑战,我们提出了一种新型的增量学习范例,称为选择性和相互相关的蒸馏SID。此外,提出了一种新颖的评估指标,以更好地评估增量学习条件下检测器的性能。通过在适当的位置进行选择性蒸馏并进一步转移其他实例关系知识,我们的方法在基准数据集PASCAL VOC和COCO上显示出显着的优势。 |
| SharpGAN: Receptive Field Block Net for Dynamic Scene Deblurring Authors Hui Feng, Jundong Guo, Sam Shuzhi Ge 当在海上航行时,智能船不可避免地会由于风,浪和电流的作用而产生摇摆运动,这使得视觉传感器收集的图像显得运动模糊。这将对基于视觉传感器的物体检测算法产生不利影响,从而影响智能船的航行安全。为了消除智能船航行过程中图像的运动模糊,我们提出了一种基于生成对抗网络的新型图像去模糊方法SharpGAN。首先,将接收场块网络RFBNet引入去模糊网络,以增强网络提取模糊图像特征的能力。其次,我们提出了一种特征损失,该特征损失结合了不同级别的图像特征,以指导网络执行更高质量的去模糊,并改善还原图像和清晰图像之间的特征相似度。最后,我们建议使用轻量级的RFB模块来提高去模糊网络的实时性能。与大规模真实海图数据集和大规模去模糊数据集上的去模糊方法相比,该方法不仅在视觉感知和定量标准上具有更好的去模糊性能,而且具有更高的去模糊效率。 |
| Beating Attackers At Their Own Games: Adversarial Example Detection Using Adversarial Gradient Directions Authors Yuhang Wu, Sunpreet S. Arora, Yanhong Wu, Hao Yang 对抗示例是专门为欺骗机器学习分类器而设计的输入示例。现有技术的对抗示例检测方法通过量化多个扰动下特征变化的幅度或通过测量其与估计的良性示例分布的距离来将输入示例表征为对抗。代替使用这种度量,所提出的方法基于以下观察:在制作新的对抗示例时,对抗梯度的方向在表征对抗空间中起关键作用。与使用多个扰动的检测方法相比,该方法是有效的,因为它仅对输入示例应用单个随机扰动。在两个不同的数据库CIFAR 10和ImageNet上进行的实验表明,所提出的检测方法在五种不同的对抗攻击下平均分别达到97.9和98.6 AUC ROC,并且优于多种先进的检测方法。结果证明了使用对抗梯度方向进行对抗示例检测的有效性。 |
| 3D Human motion anticipation and classification Authors Emad Barsoum, John Kender, Zicheng Liu 人体运动的预测和理解是一个具有挑战性的问题。由于人类运动的复杂动态和未来预测的不确定性。我们提出了一种新的序列到序列模型,用于人类运动预测和特征学习,并使用生成的对抗网络的修改版进行了训练,并具有自定义损失函数,该函数从人类运动动画中汲取灵感,并可以控制来自同一运动的多个预测运动之间的差异输入姿势。 |
| Provident Vehicle Detection at Night: The PVDN Dataset Authors Lars Ohnemus, Lukas Ewecker, Ebubekir Asan, Stefan Roos, Simon Isele, Jakob Ketterer, Leopold M ller, Sascha Saralajew 对于高级驾驶员辅助系统,至关重要的是尽早获得有关迎面驶来的车辆的信息。在夜间,由于光线不足,此任务特别困难。为此,在夜间,每辆车都使用大灯来改善视线,从而确保安全行驶。作为人类,我们通过检测前照灯引起的光反射,直观地假设即将迎面驶来的车辆在实际物理上可见之前。在本文中,我们提出了一个新颖的数据集,其中包含夜晚农村环境中349个不同场景中的54659个带注释的灰度图像。在这些图像中,标记了所有迎面驶来的车辆,其相应的照明对象(例如前照灯)以及它们各自的光反射(例如护栏上的光反射)。这伴随着对数据集特征的深入分析。有了这些,我们将为第一个开源数据集提供全面的地面真实数据,从而使人们能够研究基于即将到来的车辆的光检测方法,这些方法将在车辆直接可见之前对其进行光反射。我们认为这是进一步缩小当前先进的驾驶员辅助系统与人类行为之间的性能差距所必不可少的步骤。 |
| OSTeC: One-Shot Texture Completion Authors Baris Gecer, Jiankang Deng, Stefanos Zafeiriou 最近几年见证了非线性生成模型在合成高质量逼真的面部图像方面的巨大成功。最近许多来自单一图像方法的3D面部纹理重建和姿势操纵仍然依赖于大型且干净的面部数据集,以将图像训练为图像生成对抗网络GAN。然而,如此大规模的高分辨率3D纹理数据集的收集仍然非常昂贵并且难以维持年龄种族平衡。此外,基于回归的方法在野外条件下普遍存在,无法微调至目标图像。在这项工作中,我们提出了一种无需监督的3D面部纹理补全方法,该方法不需要大规模的纹理数据集,而是可以利用存储在2D面部生成器中的知识。所提出的方法基于可见部分,通过在2D人脸生成器中重建旋转后的图像,以3D旋转输入图像并填充看不见的区域。最后,我们在UV图像平面中以不同角度缝合最可见的纹理。此外,我们通过将完成的纹理投影到生成器中来使目标图像正面化。定性和定量实验表明,完整的UV纹理和正面图像质量很高,类似于原始标识,可用于训练用于3DMM拟合的纹理GAN模型并改善姿势不变的面部识别。 |
| Knowledge Distillation with Adaptive Asymmetric Label Sharpening for Semi-supervised Fracture Detection in Chest X-rays Authors Yirui Wang, Kang Zheng, Chi Tung Chang, Xiao Yun Zhou, Zhilin Zheng, Lingyun Huang, Jing Xiao, Le Lu, Chien Hung Liao, Shun Miao 通过半监督学习SSL设置来利用可用的病历来训练高性能的计算机辅助诊断CAD模型正在兴起,以解决大规模医学图像注释所涉及的过高的人工成本。尽管SSL受到了广泛关注,但以前的方法未能1解释病历中疾病的低发生率,而2利用病历中指示的图像水平诊断。这两个问题都是SSL对于CAD模型所特有的。在这项工作中,我们提出了一种新的知识蒸馏方法,该方法可以有效地利用从病历中提取的大规模图像级标签,并添加有限的专家注释区域级标签,以训练胸部X射线CXR的肋骨和锁骨骨折CAD模型。我们的方法利用了师生模型范例,并采用了一种新颖的自适应不对称标签锐化AALS算法来解决医疗领域中特别存在的标签不平衡问题。我们的方法已在2008年至2016年的9年中,在匿名医院的创伤登记处对所有CXR N 65,845进行了最广泛的评估,涉及最常见的肋骨和锁骨骨折。实验结果表明,我们的方法达到了最先进的骨折检测性能,即在肋骨骨折上的接收器工作特性曲线AUROC下的面积为0.9318,自由响应接收器工作特性FROC得分为0.8914,大大优于以前的方法。 AUROC缺口为1.63,FROC改善为3.74。在锁骨骨折检测中也观察到一致的性能提升。 |
| Active Annotation of Informative Overlapping Frames in Video Mosaicking Applications Authors Loic Peter, Marcel Tella Amo, Dzhoshkun Ismail Shakir, Jan Deprest, Sebastien Ourselin, Juan Eugenio Iglesias, Tom Vercauteren 视频镶嵌需要注册序列中位于遥远时间点的重叠帧,以确保重建场景的全局一致性。然而,当图像本身的注册很困难时,这种长距离对的全自动配准是一个挑战,并且由于要注册的候选对数量众多,因此对于长序列而言在计算上是昂贵的。在本文中,我们为序列中的长距离成对对应关系的有效注释引入了一种有效的框架。我们的框架提出了一些图像对,这些图像对Oracle代理(例如人类用户)或在每个建议对上提供视觉对应关系的可靠匹配算法都具有参考价值。信息对是根据迭代策略检索的,该策略基于原则上的注释奖励以及两个互补且在线自适应的帧重叠模型。除了有效地构建镶嵌图之外,我们的框架还提供了可用于评估或学习目的的地面真实地标对应物作为副产品。我们通过在合成序列上进行的实验,在航空影像学上可公开获得的数据集以及在胎儿手术过程中用于胎盘镶嵌的临床数据集上的实验来评估我们在自动化和互动场景中的方法。 |
| Temporally-Transferable Perturbations: Efficient, One-Shot Adversarial Attacks for Online Visual Object Trackers Authors Krishna Kanth Nakka, Mathieu Salzmann 近年来,基于暹罗网络的跟踪器已经成为视觉对象跟踪VOT的高效工具。尽管这些方法很容易受到对抗攻击,但作为大多数用于视觉识别任务的深层网络,针对VOT跟踪器的现有攻击都需要扰动每个输入帧的搜索区域才能有效,考虑到这是不可忽略的代价VOT是一项实时任务。在本文中,我们提出了一个仅从对象模板图像生成单个可在时间上转移的对抗性扰动的框架。然后可以将此干扰添加到每个搜索图像中,这几乎是免费的,并且仍然成功地使跟踪器蒙骗。我们的实验证明,在无目标的情况下,我们的方法优于对标准VOT基准的最新攻击。此外,我们表明,形式主义自然可以扩展到针对性攻击,这些攻击通过预先计算各种方向性扰动来迫使跟踪器遵循任何给定的轨迹。 |
| Rethinking the Heatmap Regression for Bottom-up Human Pose Estimation Authors Zhengxiong Luo, Zhicheng Wang, Yan Huang, Tieniu Tan, Erjin Zhou 热图回归已成为当今人体姿势估计方法中最普遍的选择。地面真相热图通常是通过2D高斯核覆盖所有骨骼关键点来构造的。这些内核的标准偏差是固定的。但是,对于自下而上的方法,需要处理很大范围的人类比例和标签模糊性,当前的做法似乎是不合理的。为了更好地解决这些问题,我们提出了比例自适应热图回归SAHR方法,该方法可以自适应地调整每个关键点的标准差。这样,SAHR更能容忍各种人类规模和标签的歧义。但是,SAHR可能会加剧背景样本之间的不平衡,从而有可能损害SAHR的提高。因此,我们进一步介绍了权重自适应热图回归WAHR,以帮助平衡前面的背景样本。大量实验表明,SAHR和WAHR一起可以大大提高自下而上的人体姿势估计的准确性。结果,我们最终以1.5AP的性能跑赢了最先进的模型,并在COCO测试dev2017上达到了72.0 AP,这与大多数自顶向下方法的性能相当。 |
| MM-FSOD: Meta and metric integrated few-shot object detection Authors Yuewen Li, Wenquan Feng, Shuchang Lyu, Qi Zhao, Xuliang Li 在目标检测任务中,CNN卷积神经网络模型在训练过程中始终需要大量带注释的示例。为了减少昂贵注解的依赖性,几乎没有镜头物体检测已成为越来越多的研究焦点。在本文中,我们提出了一个有效的目标检测框架MM FSOD,该框架集成了度量学习和元学习,可以解决少数镜头目标检测任务。我们的模型是可与类别无关的检测模型,可以准确地识别训练样本中未出现的新类别。具体来说,为了快速学习新类别的特征而无需微调过程,我们提出了一种元表示模块MR模块来学习类内均值原型。 MR模块通过元学习方法进行训练,以获得重建高级特征的能力。为了进一步实现支持原型与查询RoIs特征之间的相似性,我们提出了一个用作分类器的Pearson度量模块PR模块。与以前常用的度量方法相比,余弦距离度量。 PR模块使模型能够将特征对齐到判别性嵌入空间中。我们对基准数据集FSOD,MS COCO和PASCAL VOC进行了广泛的实验,以证明该模型的可行性和效率。与先前的方法相比,MM FSOD获得了最新的SOTA结果。 |
| DUT-LFSaliency: Versatile Dataset and Light Field-to-RGB Saliency Detection Authors Yongri Piao, Zhengkun Rong, Shuang Xu, Miao Zhang, Huchuan Lu 光场数据表现出有利于显着性检测的有利特性。基于学习的光场显着性检测的成功在很大程度上取决于如何构建全面的数据集以提高模型的通用性,如何有效利用高维光场数据以及如何设计灵活的模型以实现台式机的多功能性电脑和移动设备。为了回答这些问题,我们首先引入一个大规模数据集,以支持RGB,RGB D和光场显着性检测的通用应用程序,其中包含102个类别和4204个样本。其次,我们提出了由Focal流和RGB流组成的非对称两流模型。 Focal流被设计为在台式计算机上实现更高的性能,并依靠两个定制模块将焦点知识转移到RGB流。 RGB流通过三种蒸馏方案保证了移动设备的灵活性和内存计算效率。实验表明,我们的Focal流可实现最先进的性能。 RGB流在DUTLF V2上达到了Top 2 F度量,与性能最佳的方法相比,该模型极大地减小了模型尺寸83%,将FPS提升了5倍。此外,我们提出的蒸馏方案适用于RGB显着性模型,在确保灵活性的同时实现了令人印象深刻的性能提升。 |
| RTS3D: Real-time Stereo 3D Detection from 4D Feature-Consistency Embedding Space for Autonomous Driving Authors Peixuan Li, Shun Su, Huaici Zhao 尽管最近使用伪LiDAR表示的基于图像的3D对象检测方法已显示出强大的功能,但与基于LiDAR的方法相比,效率和准确性仍然存在明显差距。此外,由于过度依赖独立的深度估计器,在训练阶段需要大量的像素级注释,并且在推理阶段需要更多的计算,因此限制了实际应用中的缩放比例。 |
| Bidirectional Mapping Coupled GAN for Generalized Zero-Shot Learning Authors Tasfia Shermin, Shyh Wei Teng, Ferdous Sohel, Manzur Murshed, Guojun Lu 基于双向映射的生成模型通过学习从类语义构造视觉特征并从生成的视觉特征重新构造类语义,从而在广义零镜头学习GZSL识别方面取得了卓越的性能。这些模型的性能取决于综合特征的质量。这取决于模型通过关联语义视觉空间,学习判别信息以及重新定位学习的分布以识别看不见的数据来捕获潜在的可见数据分布的能力。这意味着学习可见的看不见的域联合分布对于GZSL任务至关重要。但是,由于无法访问看不见的数据,因此现有模型仅学习可见域的基础分布。在这项工作中,我们建议利用可用的看不见的类语义以及所见的类语义,并通过强大的视觉语义耦合来学习双域联合分布。因此,通过将耦合生成对抗网络CoGAN扩展到双域学习双向映射模型,我们提出了双向映射耦合生成对抗网络BMCoGAN。我们进一步集成了Wasserstein生成对抗性优化,以监督联合分布学习。为了在合成的视觉空间中保留独特的信息并减少对可见类的偏见,我们设计了一种优化方法,将合成的可见特征推向真实的可见特征,并将合成的看不见的特征从真实可见的特征中拉出。我们根据当代方法在几个基准数据集上评估了BMCoGAN,并显示了其卓越的性能。此外,我们提供了烧蚀分析,以证明BMCoGAN中不同组件的重要性。 |
| SkiNet: A Deep Learning Solution for Skin Lesion Diagnosis with Uncertainty Estimation and Explainability Authors Rajeev Kumar Singh, Rohan Gorantla, Sai Giridhar Allada, Narra Pratap 皮肤癌被认为是人类最常见的恶性肿瘤。每年在美国记录约500万新的皮肤癌病例。皮肤病灶的早期识别和评估具有重要的临床意义,但是在大多数发展中国家,不成比例的皮肤科医生患者比例构成了重大问题。因此,提出了一种基于深度学习的架构,称为SkiNet,其目的是在临床诊断过程中为新近训练的医师提供更快的筛选解决方案并提供帮助。 Skinet的设计和开发背后的主要动机是提供白盒解决方案,以解决信任和可解释性这一关键问题,这对于医疗从业人员广泛采用计算机辅助诊断系统至关重要。 SkiNet是一个两阶段的管道,其中病变分割之后是病变分类。在我们的SkiNet方法中,蒙特卡洛辍学和测试时间增加技术已被用于估计认知和无意识不确定性,同时探索了基于显着性的方法来为深度学习模型提供事后解释。公开可用的数据集ISIC 2018用于执行实验和消融研究。结果建立了模型在传统基准上的鲁棒性,同时解决了此类模型的黑匣子性质,通过将透明性和置信度纳入模型的预测中,从而减轻了医生的怀疑态度。 |
| Damaged Fingerprint Recognition by Convolutional Long Short-Term Memory Networks for Forensic Purposes Authors Jaouhar Fattahi, Mohamed Mejri 指纹识别通常是改变犯罪分子证据的游戏规则。但是,我们越来越多地发现,犯罪分子故意以各种方式更改其指纹,从而使技术人员和自动传感器难以识别其指纹,这使调查人员在法医程序中针对他们建立强有力的证据变得乏味。从这个意义上讲,深度学习是帮助识别受损指纹的主要候选方法。特别是卷积算法。在本文中,我们重点研究卷积长短期记忆网络对受损指纹的识别。我们介绍了模型的架构,并演示了其性能超过95精度,99精度,并达到95召回率和99 AUC。 |
| NBNet: Noise Basis Learning for Image Denoising with Subspace Projection Authors Shen Cheng, Yuzhi Wang, Haibin Huang, Donghao Liu, Haoqiang Fan, Shuaicheng Liu 在本文中,我们介绍了NBNet,这是一种用于图像去噪的新颖框架。与以前的作品不同,我们建议从新的角度通过图像自适应投影降低噪声来解决这一难题。具体而言,我们建议通过学习特征空间中的一组重建基础来训练可以分离信号和噪声的网络。随后,可以通过选择信号子空间的相应基础并将输入投影到这种空间中来实现图像去噪。我们的主要见识在于,投影可以自然地保持输入信号的局部结构,尤其是在光线较弱或纹理较弱的区域。为此,我们提出了SSA,这是一个非本地子空间注意模块,专门设计用于学习基础生成以及子空间投影。我们进一步将SSA与NBNet结合在一起,NBNet是一种为端到端图像去噪设计的UNet结构化网络。我们对包括SIDD和DND在内的基准进行评估,并且NBNet在PSNR和SSIM上达到了最先进的性能,而计算成本却大大降低了。 |
| Towards Unsupervised Deep Image Enhancement with Generative Adversarial Network Authors Zhangkai Ni, Wenhan Yang, Shiqi Wang, Lin Ma, Sam Kwong 对于公众而言,提高图像的美学质量是充满挑战和渴望的。为了解决这个问题,大多数现有算法都是基于监督学习方法来学习用于配对数据的自动照片增强器,该照片增强器由低质量的照片和相应的专家修饰版本组成。但是,专家修饰的照片的样式和特征可能无法满足一般用户的需求或偏好。在本文中,我们提出了一种无监督的图像增强生成对抗网络UEGAN,该网络以无监督的方式从一组具有所需特征的图像中学习对应的图像到图像的映射,而不是学习大量的配对图像。所提出的模型基于单个深度GAN,它嵌入了调制和注意机制以捕获更丰富的全局和局部特征。基于提出的模型,我们引入了两种损失来处理无监督的图像增强1保真度损失,其定义为预训练VGG网络的特征域中的L2正则化,以确保增强图像和输入图像之间的内容相同,并且2质量损失被表示为相对论铰链对抗损失,以赋予输入图像所需的特性。定量和定性结果均表明,该模型有效地提高了图像的美学质量。我们的代码位于 |
| 2D or not 2D? Adaptive 3D Convolution Selection for Efficient Video Recognition Authors Hengduo Li, Zuxuan Wu, Abhinav Shrivastava, Larry S. Davis 3D卷积网络普遍用于视频识别。在标准基准上获得出色的识别性能的同时,它们在具有3D卷积的帧序列上运行,因此对计算的要求很高。利用不同视频之间的巨大差异,我们引入了Ada3D,这是一个条件计算框架,可学习实例特定的3D使用策略来确定要在3D网络中使用的帧和卷积层。这些策略是通过以每个输入视频剪辑为条件的两头轻型选择网络得出的。然后,在3D模型中仅使用由选择网络选择的帧和卷积来生成预测。选择网络使用策略梯度方法进行了优化,以最大化奖励,从而鼓励以有限的计算来做出正确的预测。我们在三个视频识别基准上进行了实验,并证明了我们的方法具有与最新3D模型相似的准确性,同时在不同数据集上所需的计算量减少了20 50。我们还显示,学习到的策略是可转让的,并且Ada3D与不同的主干和现代剪辑选择方法兼容。我们的定性分析表明,我们的方法为静态输入分配了较少的3D卷积和帧,但为运动密集型剪辑分配了更多的3D卷积和帧。 |
| SALA: Soft Assignment Local Aggregation for 3D Semantic Segmentation Authors Hani Itani, Silvio Giancola, Ali Thabet, Bernard Ghanem 我们介绍了在基于网格的聚合函数中使用可学习的邻居对网格进行软分配的想法,以实现3D语义分割的任务。文献中的先前方法在预定的几何网格上运行,例如局部体积分区或不规则的核点。这些方法使用几何函数将局部邻居分配给其相应的网格。对于语义分段的最终任务,这种几何启发式方法可能是次优的。此外,它们在网络的整个深度上均被均匀地应用。一个更通用的替代方法将允许网络学习最适合最终任务的自己的邻居到网格分配功能。由于它是可学习的,因此该映射具有灵活性,每层可以不同。本文利用学习到的邻居到网格的软分配来定义一个聚合函数,以平衡效率和性能。我们通过在S3DIS上达到最先进的SOTA性能(参数比当前的统治方法少近10倍)来证明我们方法的有效性。与更大的SOTA模型相比,我们还展示了ScanNet和PartNet上的竞争性能。 |
| Detecting Hate Speech in Multi-modal Memes Authors Abhishek Das, Japsimar Singh Wahi, Siyao Li 在过去的几年中,对多模式问题的兴趣激增,从图像字幕到视觉问题解答等等。在本文中,我们专注于多模态模因中的仇恨语音检测,其中模因构成了一个有趣的多模态融合问题。我们旨在解决Facebook Meme Challenge引用kiela2020hateful的问题,该目标旨在解决预测模因是否令人讨厌的二元分类问题。挑战的关键特征是它包括良性混杂因素,以应对利用单峰先验模型的可能性。挑战指出,与人类相比,现有模型的性能较差。在数据集的分析过程中,我们意识到,原来是可恨的大多数数据点只是在描述模因的图像时才变成良性的。而且,大多数多模式基线更偏爱仇恨语音语言模式。为了解决这些问题,我们使用对象检测和图像字幕模型来探索视觉模态以获取实际的字幕,然后将其与多模态表示相结合以执行二进制分类。这种方法解决了数据集中存在的良性文本混杂因素,以提高性能。我们尝试的另一种方法是通过情感分析来改善预测。不仅仅使用从训练有素的神经网络获得的多模式表示,我们还包括单峰情感以丰富功能。我们对以上两种方法进行了详细的分析,提供了令人信服的理由来支持所使用的方法。 |
| Learning a Dynamic Map of Visual Appearance Authors Tawfiq Salem, Scott Workman, Nathan Jacobs 世界的外观不仅在不同的地方有很大的不同,而且在每个小时,一个月和一个月中也是如此。每天都有数十亿张图像捕获这种复杂的关系,其中许多与精确的时间和位置元数据相关联。我们建议使用这些图像来构建全局的视觉外观属性动态地图。这样的地图使您可以在任何地理位置和时间都对预期的外观有细微的了解。我们的方法将密集的开销图像与位置和时间元数据集成到一个能够映射各种视觉属性的通用框架中。我们方法的主要特点是不需要手动数据注释。我们演示了这种方法如何支持各种应用程序,包括图像驱动的映射,图像地理定位和元数据验证。 |
| Object sorting using faster R-CNN Authors Pengchang Chen, Vinayak Elangovan 在工厂生产线中,需要对不同的行业零件进行快速区分和分类以进行进一步处理。零件可以具有不同的颜色和形状。对于人类来说,将这些物体区分并分类为适当的类别是一件很繁琐的事情。使该过程自动化将节省更多的时间和成本。在自动化过程中,根据特定功能选择合适的模型来检测和分类不同的对象更具挑战性。在本文中,将三种不同的神经网络模型与对象分类系统进行了比较。它们分别是CNN,Fast R CNN和Faster R CNN。测试了这些模型,并分析了它们的性能。此外,对于对象分类系统,对Arduino控制的5 DoF自由度机器人手臂进行了编程,可以将对称对象抓取并放到目标区域。根据颜色,有缺陷和无缺陷的对象将对象分为几类。 |
| Visual-Thermal Camera Dataset Release and Multi-Modal Alignment without Calibration Information Authors Frank Mascarich, Kostas Alexis 该报告随附了有关视觉和热像仪数据的数据集发布,并详细介绍了对齐此类多模式照像机框的过程,以便在不使用内部或外部校准信息的情况下提供两者之间的像素级对应。为了实现这一目标,我们受益于多模式图像对齐领域的进步,并特别采用了Mattes Mutual Information Metric来指导注册过程。在发布的数据集中,我们发布原始的视觉和热像仪数据以及对齐的帧以及校准参数,目的是更好地促进跨此类多模态图像流研究共同的局部全局特征。 |
| Graph-based non-linear least squares optimization for visual place recognition in changing environments Authors Stefan Schubert, Peer Neubert, Peter Protzel 视觉位置识别是移动机器人本地化的重要子问题。由于这是图像检索的特例,因此基本信息源是图像描述符的成对相似性。但是,将图像检索问题嵌入该机器人任务中提供了可以利用的附加结构,例如,时空一致性。存在几种利用该结构的算法,例如用于变化环境的序列处理方法或描述符标准化方法。在本文中,我们提出了一个基于图的框架来系统地利用不同类型的附加结构和信息。图形模型用于制定可以用标准工具优化的非线性最小二乘问题。除了序列和标准化之外,我们建议在数据库和/或查询图像集中使用内部集相似性作为其他信息源。如果可以的话,我们的方法还可以无缝集成有关数据库映像姿势的其他知识。我们在各种标准的位置识别数据集上评估该系统,并展示了针对大量不同配置(包括不同的信息源,不同类型的约束以及在线或离线位置识别设置)的性能改进。 |
| Deep Hashing for Secure Multimodal Biometrics Authors Veeru Talreja, Matthew Valenti, Nasser Nasrabadi 与单峰系统相比,多峰生物识别系统具有多个优势,包括更低的错误率,更高的准确性和更大的人口覆盖率。但是,由于多模式系统必须存储与每个用户相关的多个生物特征,因此对完整性和隐私性的需求增加。在本文中,我们提出了一种用于特征级融合的深度学习框架,该框架从每个用户的面部和虹膜生物特征生成安全的多峰模板。我们将深度哈希二值化技术集成到融合体系结构中,以生成健壮的二进制多峰共享潜在表示。此外,我们通过将可取消的生物特征与安全草图技术相结合并采用深度哈希框架来采用混合安全体系结构,这在计算上难以伪造通过身份验证的多个生物特征的组合。使用面部和虹膜的多峰数据库显示了该方法的有效性,并观察到由于多种生物识别技术的融合,匹配性能得到了改善。此外,所提出的方法还提供了模板的可取消性和不可链接性以及生物统计数据的改进的隐私性。此外,我们还使用基准数据集测试了针对图像检索应用程序提出的哈希函数。本文的主要目的是开发一种集成多模式融合,深度哈希和生物识别安全性的方法,重点是来自面部和虹膜等模式的结构数据。所提出的方法绝不是可应用于所有生物特征形式的通用生物特征安全框架,因为需要进一步的研究以将所提出的框架扩展到其他不受约束的生物特征形式。 |
| Chasing the Tail in Monocular 3D Human Reconstruction with Prototype Memory Authors Yu Rong, Ziwei Liu, Chen Change Loy 深度神经网络在单图像3D人体重建中取得了长足的进步。但是,现有方法仍不足以预测稀有姿势。原因是当前大多数模型都基于单个人体原型执行回归,这与常见姿势相似,而与稀有姿势相差甚远。在这项工作中,我们1识别并分析了这种学习障碍,2提出了原型记忆增强网络PM Net,该网络有效地提高了预测稀有姿势的性能。我们框架的核心是一个内存模块,用于学习和存储一组3D人体原型,以捕获常见姿势或稀有姿势的局部分布。使用这种公式,回归从更好的初始化开始,这相对容易收敛。与其他现有方法相比,在几个广泛使用的数据集上的大量实验证明了所提出框架的有效性。值得注意的是,我们的方法大大改善了模型在稀有姿势下的性能,同时在其他样本上产生了可比的结果。 |
| Advances in deep learning methods for pavement surface crack detection and identification with visible light visual images Authors Kailiang Lu 与无损检测和工程结构裂缝健康监测方法相比,基于可见光图像的表面裂缝检测或识别是非接触式的,具有速度快,成本低,精度高的优点。首先,收集了典型的路面混凝土和裂缝公共数据集,总结了样本图像的特征以及环境,噪声和干扰等随机变量因素。随后,比较了三种主要裂纹识别方法的优缺点,即手工特征工程,机器学习和深度学习。最后,从模型架构,测试性能和预测有效性的角度,回顾了可轻松部署在嵌入式平台上的典型深度学习模型(包括自建的CNN,传递学习TL和编码器解码器ED)的发展和进展。基准测试表明1使用ED方法(即FPCNet或TL方法),可以在嵌入式平台上实现实时的像素级裂纹识别,整个图像样本的裂纹检测平均时间成本小于100ms。在InceptionV3上。利用基于MobileNet的轻量级骨干基网络的TL方法,可以将其减少到10ms以下。 2就准确性而言,CCIC可以达到99.8以上,人眼可以轻松识别。在SDNET2018上,其中一些样本难以识别,FPCNet可以达到97.5,而TL方法接近96.1。 |
| Image-to-Image Retrieval by Learning Similarity between Scene Graphs Authors Sangwoong Yoon, Woo Young Kang, Sungwook Jeon, SeongEun Lee, Changjin Han, Jonghun Park, Eun Sol Kim 当场景图以结构化和象征性的方式紧凑地概括了图像的高级内容时,两个图像的场景图之间的相似性反映了它们内容的相关性。基于此思想,我们提出了一种新的方法,用于使用由图神经网络测量的场景图相似度来进行图像到图像的检索。在我们的方法中,训练图神经网络来预测代理图像相关性度量,该度量是使用预先训练的句子相似性模型从人注释字幕计算得出的。我们收集并发布人类注释者测量的图像相关性数据集,以评估检索算法。收集的数据集表明,与其他竞争基准相比,我们的方法与人类对图像相似性的感知非常吻合。 |
| COIN: Contrastive Identifier Network for Breast Mass Diagnosis in Mammography Authors Heyi Li, Dongdong Chen, William H. Nailon, Mike E. Davies, David Laurenson 乳腺摄影中计算机辅助乳腺癌的诊断是一个具有挑战性的问题,这源于乳腺摄影数据的稀缺性和数据纠缠。特别地,数据稀缺性归因于隐私和昂贵的注释。数据纠缠是由于良性和恶性肿块之间的高度相似性所致,其中歧管位于较低维空间中且边缘很小。为了解决这两个挑战,我们提出了一个名为Contrastive Identifier Network textsc COIN的深度学习框架,该框架集成了对抗增强和基于流形的对比学习。首先,我们采用对抗性学习来创建包含大量投资回报的在线和离线分布。在那之后,我们提出了一个带有建立的Signed图的新颖的对比损失。最后,以对比学习的方式对神经网络进行了优化,目的是提高扩展数据集上的深度模型的判别力。特别是,通过使用COIN,可以将来自同一类别的数据样本拉近,而将具有不同标签的数据样本推入更深的潜在空间。此外,COIN在解决乳腺癌诊断问题方面的表现优于现有的相关算法,可达到93.4的准确度和95.0的AUC评分。该代码将在上发布。 |
| Towards Reducing Severe Defocus Spread Effects for Multi-Focus Image Fusion via an Optimization Based Strategy Authors Shuang Xu, Lizhen Ji, Zhe Wang, Pengfei Li, Kai Sun, Chunxia Zhang, Jiangshe Zhang 多焦点图像融合MFF是一种流行的技术,可以生成场景中所有对象都清晰的全焦点图像。但是,现有方法很少关注现实世界多焦点图像的散焦散布效果。因此,大多数方法在聚焦图边界附近的区域中效果不佳。根据融合图像中每个局部区域都应与源图像中最清晰的区域相似的想法,本文提出了一种基于优化的方法来减少散焦散布效果。首先,结合结构相似性原理和检测到的焦点图,提出了一种新的MFF评估指标。然后,将MFF问题转化为最大化该指标。优化是通过梯度上升来解决的。在现实世界数据集上进行的实验证明了该模型的优越性。可以在以下位置找到代码 |
| Tips and Tricks for Webly-Supervised Fine-Grained Recognition: Learning from the WebFG 2020 Challenge Authors Xiu Shen Wei, Yu Yan Xu, Yazhou Yao, Jia Wei, Si Xi, Wenyuan Xu, Weidong Zhang, Xiaoxin Lv, Dengpan Fu, Qing Li, Baoying Chen, Haojie Guo, Taolue Xue, Haipeng Jing, Zhiheng Wang, Tianming Zhang, Mingwen Zhang WebFG 2020是由南京科技大学,爱丁堡大学,南京大学,阿德莱德大学,早稻田大学等主办的国际挑战。这一挑战主要关注网络监督的细粒度识别问题。在文献中,现有的深度学习方法高度依赖于大规模和高质量的带标签的训练数据,这限制了它们在实际应用中的实用性和可扩展性。特别是,对于细粒度的识别(一种视觉任务,需要专业知识进行标记),获取标记训练数据的成本非常高。要获得大量高质量的培训数据,将带来极大的困难。因此,利用免费的网络数据来训练细粒度识别模型已经引起了细粒度社区研究人员的越来越多的关注。这项挑战预计参与者将开发网络监督的细粒度识别方法,该方法可利用网络图像训练细粒度识别模型,以缓解深度学习方法对大规模手动标记的数据集的极端依赖,并增强其实用性和可扩展性。在此技术报告中,我们汇总了总共54个参赛团队中的顶级WebFG 2020解决方案,并讨论了哪些方法在整个获胜团队中效果最好,而哪些方法却无济于事。 |
| TrustMAE: A Noise-Resilient Defect Classification Framework using Memory-Augmented Auto-Encoders with Trust Regions Authors Daniel Stanley Tan, Yi Chun Chen, Trista Pei Chun Chen, Wei Chao Chen 在本文中,我们提出了一个称为TrustMAE的框架来解决产品缺陷分类的问题。我们的框架可以接受带有未标记图像的数据集,而不必依赖于难以收集且难以标记的缺陷图像。而且,与大多数异常检测方法不同,我们的方法对于训练数据集中的噪声或缺陷图像具有鲁棒性。我们的框架使用具有稀疏存储寻址方案的内存增强型自动编码器,以避免过度泛化自动编码器,并使用新颖的信任区域内存更新方案,以使噪声远离内存插槽。结果是可以使用感知距离网络重建无缺陷图像并识别缺陷区域的框架。当与各种最新基准进行比较时,我们的方法在无噪声的MVTec数据集下具有竞争优势。更重要的是,它在高达40的噪声水平下仍然有效,同时明显优于其他基准。 |
| The VIP Gallery for Video Processing Education Authors Todd Goodall, Alan C. Bovik 数字视频遍布日常生活。移动视频,数字电视和数字电影现在无处不在,因此,数字视频处理DVP领域经历了巨大的增长。数字视频系统也渗透到科学和工程学科中,包括但不限于天文学,通信,监视,娱乐,视频编码,计算机视觉和视觉研究。结果,DVP的教育工具必须迎合大量不同的学生群体。为了加强DVP教育,我们创建了精心构建的教育工具库,旨在通过提供有关真实世界内容的DVP实例以及可组织许多重要DVP主题(从模拟到模拟)的用户友好界面,来补充全面的在线讲座集视频,人类视觉处理,现代视频编解码器等。该演示库目前在德克萨斯大学奥斯汀分校的数字视频研究生班中得到有效使用。通过在视觉效果极强的讲座中学习理论,以及在画廊中观看具体实例,学生可以更深入地了解概念,从而捕捉到现代视频处理的基本原理之美。为了更好地了解这些工具的教育价值,我们进行了两次基于问卷的调查,以评估学生的背景,期望和结果。调查结果支持了这种新的教学视频工具集的教学效果。 |
| MS-GWNN:multi-scale graph wavelet neural network for breast cancer diagnosis Authors Mo Zhang, Quanzheng Li 乳腺癌是全世界女性中最常见的癌症之一,早期发现可以显着降低乳腺癌的死亡率。在检测乳腺癌时,必须考虑组织结构的多尺度信息。因此,设计精确的计算机辅助检测CAD系统以捕获癌组织中的多尺度上下文特征是关键。在这项工作中,我们提出了一种用于乳腺癌的组织病理学图像分类的新型图卷积神经网络。该新方法名为多尺度图小波神经网络MS GWNN,它利用频谱图小波的定位特性来进行多尺度分析。通过聚合不同尺度的特征,MS GWNN可以对整个病理幻灯片中的多尺度上下文交互进行编码。在两个公共数据集上的实验结果证明了该方法的优越性。此外,通过消融研究,我们发现多尺度分析对癌症诊断的准确性有重大影响。 |
| FPCC-Net: Fast Point Cloud Clustering for Instance Segmentation Authors Yajun Xu, Shogo Arai, Diyi Liu, Fangzhou Lin, Kazuhiro Kosuge 在许多现实世界的应用程序中,例如机器人技术,自动驾驶汽车和人机交互,实例分割是一项重要的预处理任务。但是,对于将相同类别的多个对象堆叠在一起的bin拾取场景的3D点云实例分割的研究很少。与二维2D图像任务深度学习的快速发展相比,基于深度学习的3D点云分割仍然有很大的发展空间。在这种情况下,区分大量相同类别的被遮挡物体是一个极富挑战性的问题。在通常的垃圾收集场景中,对象模型是已知的,并且对象类型的数量是一个。因此,可以代替地忽略语义信息,将重点放在实例的分割上。基于此任务要求,我们提出了一个网络FPCC网络,该网络可以推断每个实例的特征中心,然后将其余点聚类到特征嵌入空间中最近的特征中心。 FPCC网络包括两个子网,一个子网用于推断要素中心以进行聚类,另一个子网用于描述每个点的要素。将该方法与现有的3D点云和2D分割方法进行了比较。结果表明,FPCC Net的性能优于SGPN约40个平均精度AP,并且可以在约0.8 s的时间内处理约60,000个点 |
| Hierarchical Representation via Message Propagation for Robust Model Fitting Authors Shuyuan Lin, Xing Wang, Guobao Xiao, Yan Yan, Hanzi Wang 在本文中,我们提出了一种通过消息传播HRMP方法进行鲁棒模型拟合的新层次表示方法,该方法同时利用共识分析和偏好分析的优势从异常值破坏的数据中估计多个模型实例的参数,从而获得鲁棒模型配件。代替独立地分析每个数据点或每个模型假设的信息,我们将共识信息和偏好信息表述为分层表示形式,以减轻对总体异常值的敏感性。具体来说,我们首先构造一个层次表示,它由模型假设层和数据点层组成。模型假设层用于删除无关紧要的模型假设,数据点层用于删除总体异常值。然后,基于分层表示,我们提出了一种有效的分层消息传播HMP算法和改进的亲和力传播IAP算法,分别修剪无关紧要的顶点并聚类其余数据点。提出的HRMP不仅可以准确地估计多个模型实例的数量和参数,而且还可以处理受大量异常值污染的多结构数据。在合成数据和真实图像上的实验结果表明,在拟合精度和速度方面,提出的HRMP明显优于几种最新的模型拟合方法。 |
| AU-Expression Knowledge Constrained Representation Learning for Facial Expression Recognition Authors Tao Pu, Tianshui Chen, Yuan Xie, Hefeng Wu, Liang Lin 自动识别人的情绪表达是智能机器人技术的一项预期功能,因为它可以促进与人之间更好的沟通和合作。当前的基于深度学习的算法在某些实验室控制的环境中可能会实现令人印象深刻的性能,但是对于在野外情况下不受控制的表达式,它们始终无法准确识别这些表达式。幸运的是,面部动作单元AU可以描述微妙的面部行为,并且可以帮助区分不确定和模棱两可的表情。在这项工作中,我们探索了动作单元和面部表情之间的相关性,并设计了一个AU表达式知识约束表示学习AUE CRL框架来学习没有AU注释的AU表示,并自适应地使用表示来促进面部表情识别。具体来说,它利用AU表达式相关性来指导AU分类器的学习,因此它可以在不招致任何AU注释的情况下获得AU表示。然后,介绍了一种知识指导的注意力机制,该机制在AU表达相关性的约束下挖掘有用的AU表示。以这种方式,框架可以捕获局部判别和互补特征,以增强用于面部表情识别的面部表示。我们对具有挑战性的不受控制的数据集进行了实验,以证明所提出的框架相对于当前最新方法的优越性。 |
| MGML: Multi-Granularity Multi-Level Feature Ensemble Network for Remote Sensing Scene Classification Authors Qi Zhao, Shuchang Lyu, Yuewen Li, Yujing Ma, Lijiang Chen 遥感RS场景分类对于预测RS图像的场景类别是一项艰巨的任务。 RS图像具有两个主要特征,这是由于较大的分辨率差异和来自较大地理覆盖区域的混乱信息而导致的类内差异较大。为了减轻上述两个字符的负面影响。本文提出了一种多粒度多层次特征集合网络MGML FENet,以有效解决RS场景分类任务。具体而言,我们提出了多粒度多级特征融合分支MGML FFB,以通过通道分离特征生成器CS FG提取不同级别网络中的多粒度特征。为了避免混淆信息的干扰,我们提出了多粒度多层次特征集合模块MGML FEM,它可以通过全通道特征生成器FC FG提供各种预测。与以前的方法相比,我们提出的网络具有使用结构信息的能力和丰富的细粒度特征。此外,通过集成学习方法,我们提出的MGML FENets可以获得更令人信服的最终预测。在多个RS数据集AID,NWPU RESISC45,UC Merced和VGoogle上进行的广泛分类实验表明,我们提出的网络比以前最先进的SOTA网络具有更好的性能。可视化分析还显示了MGML FENet的良好解释性。 |
| Visual Probing and Correction of Object Recognition Models with Interactive user feedback Authors Viny Saajan Victor, Pramod Vadiraja, Jan Tobias Sohns, Heike Leitte 随着最先进的机器学习和深度学习技术的出现,一些行业正在向该领域发展。从自然语言处理到计算机视觉,此类技术的应用范围非常广泛。对象识别是计算机视觉领域中的此类领域之一。尽管已被证明具有很高的精度,但仍存在可以改进此类模型的领域。实际上,这在高度敏感的现实世界用例(如自动驾驶或癌症检测)中非常重要,并期望此类技术几乎没有不确定性。在本文中,我们尝试可视化对象识别模型中的不确定性,并通过用户反馈提出校正过程。我们将根据VAST 2020 Mini Challenge 2提供的数据进一步展示我们的方法。 |
| Enhancing Handwritten Text Recognition with N-gram sequence decomposition and Multitask Learning Authors Vasiliki Tassopoulou, George Retsinas, Petros Maragos 手写文本识别领域中的当前最先进的方法主要是具有unigram字符级目标单元的单个任务。在我们的工作中,我们使用多任务学习方案,训练模型以使用不同粒度(从精细到粗糙)的目标单位分解目标序列。我们认为此方法是在训练过程中隐式利用n gram信息的一种方法,而最终识别仅使用unigram输出进行。为了强调内部Unigram解码的差异,这种多任务方法强调了学习的内部表示的能力,这种能力是由训练步骤中不同的n克强加的。我们选择n克作为目标单位,然后从unigram到Fourgram进行实验,即子词级粒度。这些多重分解是从具有特定任务CTC损失的网络中获悉的。关于网络体系结构,我们提出了两种选择,即“分层”任务和“块多任务”。总体而言,我们提出的模型即使仅在unigram任务上进行了评估,但在贪婪解码中的绝对2.52 WER和1.02 CER优于其相对应的单个任务,在推理过程中没有任何计算开销,这暗示着成功实施了隐式语言模型。 |
| Color Channel Perturbation Attacks for Fooling Convolutional Neural Networks and A Defense Against Such Attacks Authors Jayendra Kantipudi, Shiv Ram Dubey, Soumendu Chakraborty 卷积神经网络CNN已经成为一种非常强大的数据相关分层特征提取方法。它被广泛用于一些计算机视觉问题。 CNN会从训练样本中自动学习重要的视觉功能。可以看出,网络非常容易拟合训练样本。已经提出了几种正则化方法来避免过度拟合。尽管如此,网络对图像内的颜色分布很敏感,而现有方法忽略了它。在本文中,我们通过提出“颜色通道扰动CCP”攻击来欺骗CNN,从而发现了CNN的颜色健壮性问题。在CCP攻击中,将通过将原始通道与随机权重结合在一起创建的新通道生成新图像。在图像分类框架中,对广泛使用的CIFAR10,Caltech256和TinyImageNet数据集进行了实验。 VGG,ResNet和DenseNet模型用于测试提议的攻击的影响。可以看出,在提出的CCP攻击下,CNN的性能急剧下降。结果显示了所提出的简单CCP攻击对CNN训练模型的鲁棒性的影响。还将结果与现有的CNN欺骗方法进行比较,以评估准确性下降。我们还通过使用建议的CCP攻击扩充训练数据集,提出了针对此问题的主要防御机制。在实验中观察到了使用提出的解决方案在CCP攻击下CNN鲁棒性方面的最新技术水平。该代码在url上公开可用 |
| Deep Learning Towards Edge Computing: Neural Networks Straight from Compressed Data Authors Samuel Felipe dos Santos, Jurandy Almeida 由于手机的计算能力的普及和增长以及人工智能的进步,已经开发了许多智能应用程序,从而有意义地丰富了人们的生活。因此,边缘智能领域的兴趣日益浓厚,其目的是将数据计算推向网络的边缘,以使这些应用程序更高效,更安全。许多智能应用程序都依赖于深度学习模型,例如卷积神经网络CNN。在过去的十年中,他们在许多计算机视觉任务中都取得了最先进的性能。为了提高这些方法的性能,趋势是使用越来越深的架构和更多的参数,从而导致较高的计算成本。实际上,这是深度架构所面临的主要问题之一,从而限制了它们在计算资源有限的领域(如边缘设备)中的适用性。为了减轻计算的复杂性,我们提出了一种深度神经网络,该网络能够直接从与视觉内容有关的相关信息中学习,这些视觉内容在用于图像和视频存储和传输的压缩表示中容易获得。我们的方法的新颖性在于它被设计为直接在频域数据上运行,使用DCT系数而不是RGB像素进行学习。这使得在对数据流进行完全解码时可以节省高计算量,从而大大加快了处理时间,这已成为深度学习的一大瓶颈。我们在两个具有挑战性的任务上评估了我们的网络:在ImageNet数据集上进行图像分类,在UCF 101和HMDB 51数据集上进行2视频分类。我们的结果在准确性方面证明了与现有技术方法可比的有效性,并且具有更高的计算效率。 |
| EC-GAN: Low-Sample Classification using Semi-Supervised Algorithms and GANs Authors Ayaan Haque 半监督学习已获得关注,因为它允许执行图像分析任务,例如使用有限的标记数据进行分类。一些使用生成对抗网络GAN进行半监督分类的流行算法共享一种用于分类和区分的架构。但是,这可能需要模型收敛到每个任务的单独数据分布,这可能会降低总体性能。虽然半监督学习取得了进展,但较少解决的是小型,完全监督的任务,即使没有标签的数据也无法获得。因此,我们提出了一种新颖的GAN模型,即外部分类器GAN EC GAN,该模型利用GAN和半监督算法来改进完全监督体制中的分类。我们的方法利用GAN生成用于补充监督分类的人工数据。更具体地说,我们将外部分类器(即名称EC GAN)附加到GAN的生成器,而不是与鉴别器共享体系结构。我们的实验表明,EC GAN的性能可与共享体系结构方法相媲美,远远优于基于标准数据扩充和正则化的方法,并且对小型,现实的数据集有效。 |
| Language-Mediated, Object-Centric Representation Learning Authors Ruocheng Wang, Jiayuan Mao, Samuel J. Gershman, Jiajun Wu 我们介绍语言介导的以对象为中心的表示学习LORL,这是一种从视觉和语言中学习解开,以对象为中心的场景表示的范例。 LORL建立在无监督对象分割的最新进展的基础上,尤其是MONet和Slot Attention。尽管这些算法仅通过重构输入图像来学习以对象为中心的表示,但LORL使他们能够进一步学习将学习到的表示与来自语言输入的概念(即用于对象类别,属性和空间关系的词)相关联。这些源自语言的以对象为中心的概念有助于学习以对象为中心的表示形式。 LORL可以与语言无关的各种无监督分割算法集成。实验表明,通过语言的帮助,LORL的集成不断提高了两个数据集上的MONet和Slot Attention对象分割性能。我们还表明,由LORL学习的概念与诸如MONet之类的分段算法相结合,有助于下游任务,例如引用表达式理解。 |
| Estimating Uncertainty in Neural Networks for Cardiac MRI Segmentation: A Benchmark Study Authors Matthew Ng, Fumin Guo, Labonny Biswas, Steffen E. Petersen, Stefan K. Piechnik, Stefan Neubauer, Graham Wright 卷积神经网络CNN在自动心脏磁共振成像分割中已显示出希望。但是,在大型现实数据集中使用CNN时,量化分段不确定性很重要,这样才能知道哪些分段可能会出现问题。在这项工作中,我们进行了贝叶斯和非贝叶斯方法的系统研究,以估计分段神经网络中的不确定性。我们使用Backprop BBB,Monte Carlo MC Dropout和Deep Ensembles评估了贝叶斯的分割精度,概率校准,分布图像不确定性以及分割质量控制。我们在具有各种畸变的数据集上测试了这些算法,并观察到Deep Ensembles的表现优于其他方法,除了具有严重噪声畸变的图像。对于分割质量控制,我们表明分割不确定性与分割精度相关。通过合并不确定性估计,我们可以通过标记31至48个最不确定的图像以进行手动检查,将分割不佳的比例降低到5,这比不使用神经网络不确定性的结果的随机检查要低得多。 |
| Overview of MediaEval 2020 Predicting Media Memorability Task: What Makes a Video Memorable? Authors Alba Garc a Seco De Herrera, Rukiye Savran Kiziltepe, Jon Chamberlain, Mihai Gabriel Constantin, Claire H l ne Demarty, Faiyaz Doctor, Bogdan Ionescu, Alan F. Smeaton 本文介绍MediaEval 2020 textit预测媒体可存储性任务。在MediaEval 2018上首次提出之后,预测媒体可存储性任务将在今年的第三版中发布,因为短期和长期视频可存储性VM的预测仍然是一项艰巨的任务。 2020年,格式与以前的版本相同。今年的视频是TRECVid 2019视频到文本数据集的子集,与2019任务相比,包含更多的动作丰富视频内容。在本文中,提供了此任务某些方面的描述,包括其主要特征,集合的描述,地面真相数据集,评估指标以及参与者运行提交的要求。 |
| Investigating Memorability of Dynamic Media Authors Phuc H. Le Khac, Ayush K. Rai, Graham Healy, Alan F. Smeaton, Noel E. O Connor 与往年相比,MediaEval 20中的“预测媒体可存储性”任务具有一些挑战性的方面。在本文中,我们将视频和有限大小的数据集中的高动态内容确定为该任务的核心挑战,我们提出了克服这些挑战的方向,并在这些方向上提出了初步结果。 |
| Leveraging Audio Gestalt to Predict Media Memorability Authors Lorin Sweeney, Graham Healy, Alan F. Smeaton 记忆力决定了什么是对空虚的回避,以及是什么蠕虫进入了我们最深的沟壑。当我们每天都在浏览数字洪流时,这是策划更有意义的媒体内容的关键。 MediaEval 2020中的“预测媒体可存储性”任务旨在通过设置自动预测视频可存储性的任务来解决媒体可存储性的问题。我们的方法是基于多模式深度学习的后期融合,结合了视觉,语义和听觉功能。我们使用了音频格式塔来估计音频模态对整体视频记忆力的影响,并据此告知哪些功能组合最能预测给定视频的记忆力得分。 |
| Searching a Raw Video Database using Natural Language Queries Authors Sriram Krishna, Siddarth Vinay, Srinivas K S 随着时间的流逝,正在生成并因此存储在视频流平台数据库中的视频数量呈指数级增长。这个庞大的数据库应该易于索引,以找到必要的剪辑或视频以匹配给定的搜索规范,最好以文本查询的形式。这项工作旨在提供端到端管道,以最终用户的语音查询来搜索视频数据库。该管道利用循环神经网络与卷积神经网络相结合来生成数据库中存在的视频剪辑的字幕。 |
| Exploiting Shared Knowledge from Non-COVID Lesions for Annotation-Efficient COVID-19 CT Lung Infection Segmentation Authors Yichi Zhang, Qingcheng Liao, Lin Yuan, He Zhu, Jiezhen Xing, Jicong Zhang 新型冠状病毒病COVID 19是一种高度传染性的病毒,已遍及世界各地,对所有国家构成了极为严重的威胁。来自计算机断层扫描CT的自动肺部感染分割在COVID 19的定量分析中起着重要作用。但是,主要挑战在于带注释的COVID 19数据集的不足。当前,有几个公开的非COVID肺部病变分割数据集,为将有用信息概括为相关的COVID 19分割任务提供了潜力。在本文中,我们提出了一种新的关系驱动协作学习模型,用于注释有效的COVID 19 CT肺部感染分割。该网络由具有相同架构的编码器和共享的解码器组成。采用通用编码器来捕获基于多个非COVID病变的一般肺部病变特征,而采用目标编码器来专注于COVID 19感染的任务特定特征。从两个并行编码器中提取的特征被串联起来用于后续的解码器部分。为了彻底利用COVID和非COVID病变之间的共享知识,我们开发了一种协作学习方案来规范化给定输入的提取特征之间的关系一致性。除了现有的基于一致性的方法可以简单地增强各个预测的一致性之外,我们的方法还可以增强样本之间特征关系的一致性,从而鼓励模型探索来自COVID 19和非COVID案例的语义信息。在一个公共COVID 19数据集和两个公共非COVID数据集上进行的大量实验表明,与现有方法相比,在没有足够高质量COVID 19注释的情况下,我们的方法具有更高的分割效果。 |
| Colonoscopy Polyp Detection: Domain Adaptation From Medical Report Images to Real-time Videos Authors Zhi Qin Zhan, Huazhu Fu, Yan Yao Yang, Jingjing Chen, Jie Liu, Yu Gang Jiang 结肠镜检查视频中结肠直肠息肉的自动检测是一项基本任务,受到了广泛的关注。在大型视频数据集中手动注释息肉区域既费时又昂贵,这限制了深度学习技术的发展。一种折衷方案是通过使用标记的图像来训练目标模型,并在结肠镜检查视频中进行推断。但是,基于图像的训练和基于视频的推理之间存在几个问题,包括域差异,缺少正样本和时间平滑度。为了解决这些问题,我们提出了图像视频联合息肉检测网络Ivy Net,以解决历史医学报告和实时视频中结肠镜检查图像之间的领域差距。在我们的常春藤网络中,通过在像素级别上组合正图像和负视频帧,利用改进的混合生成训练数据,从而可以学习域自适应表示并增加正样本。同时,提出了时间相干正则化TCR,以在相邻帧中引入对特征水平的平滑约束,并通过未标记的结肠镜检查视频改善息肉检测。为了进行评估,收集了一个新的大型结肠镜检查息肉数据集,其中包含889例阳性患者的历史医学报告中的3056张图像以及69例28例阳性患者的7.5小时视频。对收集到的数据集进行的实验表明,我们的Ivy Net在结肠镜检查视频上达到了最先进的结果。 |
| Text-Free Image-to-Speech Synthesis Using Learned Segmental Units Authors Wei Ning Hsu, David Harwath, Christopher Song, James Glass 在本文中,我们提出了第一个模型,该模型可以直接合成不需要自然语言文本作为中间表示或监督来源的图像的流利,自然听起来的语音字幕。取而代之的是,我们将图像字幕模块和语音合成模块与一组离散的子单词语音单元连接,这些单元是通过自我监督的视觉接地任务发现的。除了针对流行的MSCOCO数据集收集的新颖的语音字幕集之外,我们还对Flickr8k语音字幕集进行了实验,这表明我们生成的字幕还捕获了所描述图像的多种视觉语义。我们研究了几种不同的中间语音表示形式,并从经验上发现,该表示形式必须满足几个重要的属性才能用作替代文本。 |
| Survey of the Detection and Classification of Pulmonary Lesions via CT and X-Ray Authors Yixuan Sun, Chengyao Li, Qian Zhang, Aimin Zhou, Guixu Zhang 近年来,几种肺部疾病的流行,尤其是2019年冠状病毒病COVID 19大流行,引起了全世界的关注。这些疾病可以借助肺部成像得到有效诊断和治疗。随着深度学习技术的发展以及许多公共医学图像数据集的出现,通过医学成像对肺部疾病的诊断得到了进一步的改善。本文回顾了近十年来肺部CT和X射线图像的检测和分类。它还根据各种病变的影像学特征概述了肺结节,肺炎和其他常见肺病变的检测。此外,本综述介绍了26种常用的公共医学图像数据集,总结了最新技术,并讨论了当前的挑战和未来的研究方向。 |
| New Bag of Deep Visual Words based features to classify chest x-ray images for COVID-19 diagnosis Authors Chiranjibi Sitaula, Sunil Aryal 由于严重急性呼吸系统综合症冠状病毒2 COVID 19的感染会引起肺炎,如肺炎,因此胸部X线检查可以帮助诊断疾病。对于图像的自动分析,它们在机器中由一组语义特征表示。深度学习DL模型被广泛用于从图像中提取特征。一般的深部特征可能不适合表示胸部X射线,因为它们具有一些语义区域。尽管显示的基于词袋的BoVW功能更适合用于X射线类型的图像,但是现有的BoVW功能可能无法捕获足够的信息来区分COVID 19感染和其他与肺炎相关的感染。在本文中,我们通过删除特征图归一化步骤并在原始特征图上添加了深度特征归一化步骤,提出了一种针对深度特征的新BoVW方法,称为“深视觉词袋BoDVW”。这有助于保留每个特征图的语义,这些语义图可能具有区分COVID 19和肺炎的重要线索。我们使用支持向量机SVM评估建议的BoDVW功能在胸部X射线分类中诊断COVID 19的有效性。我们在公开可用的COVID 19 x射线数据集上的结果显示,我们的特征可产生稳定且突出的分类准确性,尤其是区分COVID 19与现有技术水平相比,可在更短的计算时间内从其他肺炎感染。因此,我们的方法对于大规模诊断COVID 19患者可能是非常有用的工具。 |
| FREA-Unet: Frequency-aware U-net for Modality Transfer Authors Hajar Emami, Qiong Liu, Ming Dong 正电子发射断层扫描PET成像已被广泛用于多种疾病的诊断,但它的获取过程成本很高,涉及对患者的辐射暴露。但是,磁共振成像MRI是一种更安全的成像方式,它不涉及患者的放射线暴露。因此,需要从MRI数据高效且自动化的PET图像生成。在本文中,我们提出了一种用于生成合成PET图像的新的频率感知注意力U net。具体来说,我们将注意力机制整合到不同的U网络层中,这些网络层负责估计图像的低高频比例。我们的频率感知注意力Unet计算低频层中特征图的注意力得分,并使用它来帮助模型将注意力更多地集中在最重要的区域上,从而获得更逼真的输出图像。来自阿尔茨海默氏病神经影像计划ADNI数据集的30位受试者的实验结果表明,所提出的模型在PET图像合成中表现良好,在定性和定量方面均优于当前技术水平。 |
| Model-Based Visual Planning with Self-Supervised Functional Distances Authors Stephen Tian, Suraj Nair, Frederik Ebert, Sudeep Dasari, Benjamin Eysenbach, Chelsea Finn, Sergey Levine 通才机器人必须能够在其环境中完成各种任务。指定每个任务的一种有吸引力的方法是观察目标。但是,通过强化学习达到学习目标的策略仍然是一个具有挑战性的问题,尤其是在没有手工设计的奖励功能时。学习的动力学模型是一种无偿学习环境的有前途的方法,但是没有奖励或任务导向的数据,但是要计划使用这种模型实现目标,则需要在观察值和目标状态之间保持功能相似的概念。我们提出了一种基于模型的视觉目标达成的自我监督方法,该方法同时使用了视觉动力学模型以及使用无模型强化学习而获得的动力学距离函数。我们的方法完全使用离线的,未标记的数据来学习,因此可以扩展到大型且多样化的数据集。在我们的实验中,我们发现我们的方法可以成功地学习在测试时执行各种任务的模型,使用模拟的机械臂在牵引器中移动对象,甚至使用真实世界的机器人学习如何打开和关闭抽屉。相比之下,我们发现这种方法大大优于无模型方法和基于模型的现有方法。视频和可视化效果在这里 |
| H2NF-Net for Brain Tumor Segmentation using Multimodal MR Imaging: 2nd Place Solution to BraTS Challenge 2020 Segmentation Task Authors Haozhe Jia, Weidong Cai, Heng Huang, Yong Xia 在本文中,我们提出了一种混合高分辨率和非局部特征网络H2NF网络来分割多模式MR图像中的脑肿瘤。我们的H2NF网络使用单个和级联的HNF网络来分割不同的脑肿瘤亚区域,并将预测结果组合在一起作为最终分割。我们在多模式脑肿瘤分割挑战BraTS 2020数据集上训练和评估了我们的模型。测试集上的结果表明,单个模型和级联模型的组合在增强肿瘤,整个肿瘤和肿瘤的平均Dice得分分别为0.78751、0.91290和0.85461,以及Hausdorff距离95为26.57525、4.18422和4.97162。分别为肿瘤核心。我们的方法在BraTS 2020挑战细分任务中赢得了近80名参与者的第二名。 |
| MRI brain tumor segmentation and uncertainty estimation using 3D-UNet architectures Authors Laura Mora Ballestar, Veronica Vilaplana 3D磁共振图像中脑肿瘤分割的自动化MRI是评估疾病诊断和治疗的关键。近年来,卷积神经网络的CNN在任务中显示出了改进的结果。但是,高内存消耗在3D CNN中仍然是一个问题。而且,大多数方法不包括不确定性信息,这在医学诊断中尤其重要。这项工作研究了采用基于补丁的技术训练的3D编码器解码器体系结构,以减少内存消耗并减少不平衡数据的影响。然后使用不同的训练模型来创建一个集合,该集合利用每个模型的属性,从而提高性能。我们还分别使用测试时间丢失TTD和数据增强TTA引入了体素和不确定的体素明智不确定性信息。此外,提出了一种混合方法,可帮助提高分割的准确性。在这项工作中提出的模型和不确定性估计测量已在BraTS 20挑战赛中用于任务1和3,涉及肿瘤分割和不确定性估计。 |
| Some Algorithms on Exact, Approximate and Error-Tolerant Graph Matching Authors Shri Prakash Dwivedi 由于它的表示能力和证明对象之间关系的固有能力,因此它是工程和科学中使用最广泛的数学结构之一。这项工作的目的是使用图的表示能力介绍新颖的图匹配技术,并将其应用于结构模式识别应用程序。我们对各种精确和不精确的图形匹配技术进行了广泛的调查。提出了使用同胚概念的图匹配。提出了一种图匹配算法,该算法通过使用某种相关性度量删除不太重要的节点来减小图的大小。我们提出一种使用节点收缩的容错图匹配方法,其中通过收缩较小度的节点将给定图转换为另一个图。我们使用这种方案来扩展图形编辑距离的概念,可以在执行时间和准确性之间进行权衡。我们描述了一种利用各种节点中心性信息进行图形匹配的方法,该方法通过基于给定的中心性度量从两个图形中删除一部分节点来减小图形大小。图匹配问题固有地与图的几何形状和拓扑有关。我们介绍了一种使用几何图来测量图相似度的新颖方法。我们使用两个几何图形的顶点位置定义它们之间的顶点距离,并将其表示为仅包含顶点的所有图形集的度量。我们基于边缘的角度方向,长度和位置定义两个图形之间的边缘距离。然后,我们结合顶点距离和边缘距离的概念来定义两个几何图形之间的图形距离,并将其显示为度量。最后,我们使用提出的图相似性框架执行精确和容错的图匹配。 |
| Automatic Polyp Segmentation using U-Net-ResNet50 Authors Saruar Alam, Nikhil Kumar Tomar, Aarati Thakur, Debesh Jha, Ashish Rauniyar 息肉是大肠癌的前身,大肠癌被认为是世界范围内与癌症相关的死亡的主要原因之一。结肠镜检查是识别,定位和去除结肠直肠息肉的标准程序。由于形状,大小和周围组织相似性的差异,临床医生在结肠镜检查时常常会错过大肠息肉。通过在结肠镜检查过程中使用自动,准确和快速的息肉分割方法,可以轻松地检测和去除许多结直肠息肉。 Medico自动息肉分割挑战提供了研究息肉分割并建立有效且准确的分割算法的机会。我们使用带有预先训练的ResNet50的U Net作为息肉分割的编码器。该模型在针对挑战提供的Kvasir SEG数据集上进行了训练,并在组织者的数据集上进行了测试,其骰子系数为0.8154,Jaccard为0.7396,召回率为0.8533,精度为0.8532,精度为0.9506,F2得分为0.8272,表明我们模型的泛化能力。 |
| DDANet: Dual Decoder Attention Network for Automatic Polyp Segmentation Authors Nikhil Kumar Tomar, Debesh Jha, Sharib Ali, H vard D. Johansen, Dag Johansen, Michael A. Riegler, P l Halvorsen 结肠镜检查是检查和检测大肠息肉的金标准。息肉的定位和轮廓在治疗例如外科手术计划和预后决策中起着至关重要的作用。息肉分割可为临床分析提供详细的边界信息。卷积神经网络提高了结肠镜检查的性能。但是,息肉通常面临各种挑战,例如类内和类间变异和噪音。人工标记息肉评估需要专家的时间并且容易发生人为错误,例如遗漏的病变,而自动,准确和快速的分割可以改善所描绘的病变边界的质量并降低遗漏率。 Endotect挑战通过在公开可用的Hyperkvasir上进行培训并在单独的看不见的数据集上进行测试,提供了基准计算机视觉方法的机会。在本文中,我们提出了一种基于双解码器注意网络的新颖架构DDANet。我们的实验表明,在Kvasir SEG数据集上训练并在看不见的数据集上进行测试的模型实现了0.7874的骰子系数,0.7010的mIoU,0.7987的召回率和0.8577的精度,证明了我们模型的泛化能力。 |
| Medico Multimedia Task at MediaEval 2020: Automatic Polyp Segmentation Authors Debesh Jha, Steven A. Hicks, Krister Emanuelsen, H vard Johansen, Dag Johansen, Thomas de Lange, Michael A. Riegler, P l Halvorsen 大肠癌是全球第三大常见癌症。根据《 2018年全球癌症统计》,无论是发展中国家还是发达国家,大肠癌的发病率都在增加。早期发现结肠息肉(例如息肉)对于预防癌症很重要,而自动息肉分割对此起关键作用。不管早期发现和治疗选择的最新进展如何,估计的息肉漏诊率仍为20左右。通过自动计算机辅助诊断系统的支持可能是被忽视的息肉的潜在解决方案之一。这种检测系统可以帮助提供低成本的设计解决方案,并节省医生的时间,例如,他们可以将其用于执行更多的患者检查。在本文中,我们介绍了2020 Medico挑战赛,提供了有关工作和数据集的一些信息,描述了任务和评估指标,并讨论了组织Medico挑战赛的必要性。 |
| Exploring Large Context for Cerebral Aneurysm Segmentation Authors Jun Ma, Ziwei Nie 从3D CT自动分割动脉瘤对于脑动脉瘤疾病的诊断,监测和治疗计划很重要。这篇简短的文章简要介绍了MICCAI 2020 CADA挑战中动脉瘤分割方法的主要技术细节。主要贡献在于,我们将3D U Net配置为具有较大的补丁程序大小,从而可以获得较大的上下文。我们的方法在MICCAI 2020 CADA测试数据集上排名第二,平均Jaccard为0.7593。我们的代码和训练有素的模型可在url上公开获得 |
| Fast Hyperspectral Image Recovery via Non-iterative Fusion of Dual-Camera Compressive Hyperspectral Imaging Authors Wei He, Naoto Yokoya, Xin Yuan 编码孔径快照光谱成像CASSI是一种有前途的技术,可使用单次编码二维2D测量来捕获三维高光谱图像HSI,其中使用算法来执行反问题。由于不适的性质,已利用各种调节器从2D测量中重建3D数据。不幸的是,准确性和计算复杂性不令人满意。一种可行的解决方案是利用附加信息,例如CASSI中的RGB测量。考虑到CASSI和RGB的组合测量,我们提出了一种用于HSI重建的新融合模型。我们研究了由频谱基础和空间系数组成的HSI的频谱低秩特性。具体地,利用RGB测量来估计系数,同时采用CASSI测量来提供正交光谱基础。我们进一步提出了一种补丁处理策略来增强HSI的频谱低秩特性。提出的模型既不需要非本地处理或迭代,也不需要RGB检测器的光谱感应矩阵。在模拟和真实HSI数据集上进行的大量实验表明,我们提出的方法不仅在质量上优于以前的技术水平,而且还加快了5000倍的重建速度。 |
| Accurate Word Representations with Universal Visual Guidance Authors Zhuosheng Zhang, Haojie Yu, Hai Zhao, Rui Wang, Masao Utiyama 单词表示是神经语言理解模型的基本组成部分。最近,预训练的语言模型PrLM通过利用序列级上下文进行建模,提供了一种新型的上下文化单词表示的高效方法。尽管PrLM通常比非上下文化模型提供更准确的上下文化单词表示,但是它们仍然受到一系列文本上下文的约束,而没有来自多模态的单词表示的不同提示。因此,本文提出了一种视觉表示方法,以从视觉指导中显着增强具有多个方面感的常规单词嵌入。详细地,我们从多峰种子数据集中构建一个小规模的单词图像字典,其中每个单词对应于各种相关图像。文本和成对的图像被并行编码,随后是注意层以集成多模式表示。我们表明该方法大大提高了消除歧义的准确性。对12种自然语言理解和机器翻译任务的实验进一步验证了该方法的有效性和泛化能力。 |
| Unpaired Image Enhancement with Quality-Attention Generative Adversarial Network Authors Zhangkai Ni, Wenhan Yang, Shiqi Wang, Lin Ma, Sam Kwong 在这项工作中,我们旨在学习一种不成对的图像增强模型,该模型可以利用用户提供的高质量图像的特征丰富低质量的图像。我们提出了一个基于未配对数据训练的质量注意生成对抗网络QAGAN,该网络基于嵌入了质量注意模块QAM的双向生成对抗网络GAN。提出的QAGAN的关键新颖之处在于为生成器注入的QAM,这样它就可以直接从两个域中学习与域相关的质量注意事项。更具体地,所提出的QAM允许生成器从空间方面有效地选择语义相关的特征,并分别从信道方面有效地合并样式相关的属性。因此,在我们提出的QAGAN中,不仅鉴别器而且生成器也可以直接访问两个域,这极大地促进了生成器学习映射功能。大量的实验结果表明,与基于不成对学习的最新方法相比,我们提出的方法在客观和主观评估方面均具有更好的性能。 |
| A Review of Machine Learning Techniques for Applied Eye Fundus and Tongue Digital Image Processing with Diabetes Management System Authors Wei Xiang Lim, Zhiyuan Chen, Amr Ahmed, Tissa Chandesa, Iman Liao 糖尿病是一种全球流行病,并且正在以惊人的速度增长。国际糖尿病联合会IDF预测,全球糖尿病患者总数可能会增加48,从2017年的4.25亿增加到2045年的6.29亿。此外,糖尿病已经导致数百万的死亡,并且这个数字还在急剧增加。因此,本文探讨了糖尿病及其并发症的背景。此外,本文通过应用眼底和舌头数字图像,研究了糖尿病管理系统领域的创新应用和过去的研究。市场上已有各种类型的现有糖尿病眼管理系统和已应用的眼底和舌头数字图像处理技术,以及来自先前文献的最新机器学习技术进行了综述。本文的含义是对糖尿病研究进行概述,以及可以提出什么新的机器学习技术来解决这一全球性流行病。 |
| DeepSphere: a graph-based spherical CNN Authors Micha l Defferrard, Martino Milani, Fr d rick Gusset, Nathana l Perraudin 为球面神经网络设计卷积需要在效率和旋转等方差之间进行微妙的权衡。 DeepSphere是一种基于采样球体图形表示的方法,它在这两个目标之间取得了可控的平衡。这一贡献是双重的。首先,我们在理论和经验上都研究了基础图相对于顶点和邻居数如何影响等方差。其次,我们在相关问题上评估DeepSphere。实验显示了最先进的性能,并证明了这种配方的效率和灵活性。也许令人惊讶的是,与以前的工作进行比较表明,各向异性滤波器可能是不必要的代价。我们的代码位于 |
| Semi-supervised Cardiac Image Segmentation via Label Propagation and Style Transfer Authors Yao Zhang, Jiawei Yang, Feng Hou, Yang Liu, Yixin Wang, Jiang Tian, Cheng Zhong, Yang Zhang, Zhiqiang He 正确分割心脏结构可以帮助医生诊断疾病,并改善治疗计划,这在临床实践中是非常需要的。但是,注释的不足以及不同供应商和医疗中心之间数据的差异限制了高级深度学习方法的性能。在这项工作中,我们提出了一种自动的方法,可以对包括左LV和右心室RV血池以及左心室心肌MYO在内的心脏结构进行MRI分割。具体来说,我们设计了一种半监督学习方法,通过标签传播来利用未标记的MRI序列时间范围。然后,我们利用样式转换来减少不同中心和供应商之间的差异,以实现更可靠的心脏图像分割。我们在M女士挑战赛7中评估了我们的方法,在14支竞争团队中排名第二。 |
| Parzen Window Approximation on Riemannian Manifold Authors Abhishek, Shekhar Verma 在图驱动学习中,标签传播很大程度上取决于表示为连接数据点之间的边缘的数据亲和力。相似性分配隐式假定数据在流形上均匀分布。由于向高密度区域的漂移,此假设可能不成立,并可能导致度量分配不正确。漂移影响的基于热核的亲和力与全局固定的Parzen窗口一起丢弃真正的邻居,或迫使遥远的数据点成为邻居的成员。这产生了偏倚的亲和度矩阵。在本文中,由于可变的Parzen窗口可解决因在黎曼流形上数据采样不均匀而引起的偏差,该变量被确定为邻域大小,环境尺寸,平坦度范围等的函数。此外,还使用了亲和力调整来抵消抽样不均是造成偏差的原因。提出了一种亲和力度量,该度量考虑了不规则采样效应以产生准确的标签传播。在合成和现实世界数据集上进行的大量实验证实,该方法显着提高了分类准确性,并且优于图拉普拉斯流形正则化方法中现有的Parzen窗口估计量。 |
| AILearn: An Adaptive Incremental Learning Model for Spoof Fingerprint Detection Authors Shivang Agarwal, Ajita Rattani, C. Ravindranath Chowdary 增量学习使学习者无需重新训练现有模型即可适应新知识。这是一项艰巨的任务,需要从新数据中学习以及保留从先前访问的数据中提取的知识。这一挑战被称为稳定性可塑性难题。我们提出AILearn,这是一种用于增量学习的通用模型,它通过将在新数据上训练的基础分类器的集合与当前集合进行仔细集成,从而克服了稳定性可塑性难题,而无需使用整个数据从头开始重新训练模型。我们演示了拟议的AILearn模型在欺骗指纹检测应用程序中的功效。与欺骗指纹检测相关的重大挑战之一是使用新的制造材料生成的欺骗的性能下降。 AILearn是一种自适应增量学习模型,可适应实时和欺骗指纹图像的特征,并在新数据可用时有效地识别新的欺骗指纹以及已知的欺骗指纹。据我们所知,AILearn是增量学习算法中的首次尝试,该算法适应于数据的属性以生成各种基础分类器。从对标准高维数据集LivDet 2011,LivDet 2013和LivDet 2015进行的实验中,我们表明,在新型假材料上的性能提升显着。平均而言,我们在连续学习阶段之间的准确性提高了49.57。 |
| Annotation-Efficient Learning for Medical Image Segmentation based on Noisy Pseudo Labels and Adversarial Learning Authors Lu Wang, Dong Guo, Guotai Wang, Shaoting Zhang 尽管深度学习已实现了医学图像分割的最先进性能,但其成功仍依赖于大量的手动注释图像进行训练,这些图像获取成本很高。在本文中,我们提出了一种用于分割任务的注释高效学习框架,该框架避免了训练图像的注释,在此我们使用改进的周期一致生成对抗网络GAN来从一组未配对的医学图像和从形状模型获得的辅助蒙版中学习或公共数据集。我们首先使用GAN在辅助掩模的帮助下,在基于变分自动编码器基于VAE的鉴别器所代表的隐含的高级形状约束下,为训练图像生成伪标签,然后构建采用鉴别器的发生器通道校准DGCC模块鉴别器的反馈,以校准发生器,以获得更好的伪标签。为了从嘈杂的伪标签中学习,我们进一步介绍了一种使用噪声加权Dice损失的鲁棒迭代学习方法。我们用两个情况对象验证了我们的框架,这些对象具有简单的形状模型,例如眼底图像中的视盘和超声图像中的胎儿头,以及复杂的结构,例如X射线图像中的肺和CT图像中的肝。实验结果表明1我们基于VAE的鉴别器和DGCC模块有助于获得高质量的伪标签。 2我们提出的噪声鲁棒学习方法可以有效地克服噪声伪标签的影响。 3我们的方法在不使用训练图像注释的情况下的分割性能与从人类注释中学习的方法相近甚至可比。 |
| Ensembled ResUnet for Anatomical Brain Barriers Segmentation Authors Munan Ning, Cheng Bian, Chenglang Yuan, Yefeng Zheng 脑结构的准确分割可能对神经胶质瘤和放射治疗计划有帮助。然而,由于不同模态之间在视觉和解剖上的差异,大脑结构的准确分割变得具有挑战性。为了解决这个问题,我们首先构造一个具有深度编码器和浅层解码器的基于残差块的U型网络,这可以权衡框架的性能和效率。然后,我们引入Tversky损失,以解决不同前景类和背景类之间的类不平衡问题。最后,模型集成策略用于消除异常值并进一步提高性能。 |
| Myocardial Segmentation of Cardiac MRI Sequences with Temporal Consistency for Coronary Artery Disease Diagnosis Authors Yutian Chen, Xiaowei Xu, Dewen Zeng, Yiyu Shi, Haiyun Yuan, Jian Zhuang, Yuhao Dong, Qianjun Jia, Meiping Huang 冠状动脉疾病CAD是全球最常见的死亡原因,其诊断通常基于磁共振成像MRI序列的手动心肌分割。由于手动分割繁琐,耗时且适用性低,因此最近广泛研究了使用机器学习技术进行的自动心肌分割。然而,几乎所有现有方法都独立地处理输入的MRI序列,这不能捕获序列之间的时间信息,例如,沿时间序列的心肌的形状和位置信息。在本文中,我们为左心室腔,右心室腔和心肌的心脏MRI CMR扫描序列提出了一种心肌分割框架。具体来说,我们建议将常规网络和递归网络相结合,以在序列之间合并时间信息,以确保时间上的一致性。我们在自动心脏诊断挑战ACDC数据集上评估了我们的框架。实验结果表明,我们的框架可以将Dice系数的分割精度提高2倍。 |
| Cascaded Framework for Automatic Evaluation of Myocardial Infarction from Delayed-Enhancement Cardiac MRI Authors Jun Ma 心肌和病理的自动评估在定量分析心肌梗死患者中起着重要作用。在本文中,我们提出了用于延迟增强心脏MRI的心肌梗塞分割和分类的级联卷积神经网络框架。具体来说,我们首先使用2D U Net分割整个心脏,包括左心室和心肌。然后,我们将整个心脏裁剪为感兴趣的ROI区域。最后,使用新的2D U Net分割整个心脏ROI中的梗阻区域和无回流区域。可以将分割方法应用于分类任务,在该分类任务中,将具有违规或无回流区域的分割结果分类为病理病例。我们的方法在MICCAI 2020 EMIDEC分割任务中排名第二,心肌,梗死和无回流区域的Dice得分分别为86.28、62.24和77.76,在分类任务中排名第一,准确度为92。 |
| Comparison of different CNNs for breast tumor classification from ultrasound images Authors Jorge F. Lazo, Sara Moccia, Emanuele Frontoni, Elena De Momi 乳腺癌是世界上最致命的癌症之一。及时发现可以降低死亡率。在临床常规中,根据超声US成像对良性和恶性肿瘤进行分类是一项至关重要但具有挑战性的任务。因此,需要一种能够处理数据可变性的自动化方法。 |
| SASSI -- Super-Pixelated Adaptive Spatio-Spectral Imaging Authors Vishwanath Saragadam, Michael DeZeeuw, Richard Baraniuk, Ashok Veeraraghavan, Aswin Sankaranarayanan 我们介绍一种具有高空间和时间分辨率的新型视频速率高光谱成像仪。我们的主要假设是,过度分割图像的超像素中像素的光谱轮廓往往非常相似。因此,在高光谱场景的超像素分割图像的引导下,场景自适应空间采样能够获得高质量的重建。为此,我们获取场景的RGB图像,计算其超像素,然后从中生成测量高分辨率光谱的位置的空间遮罩。随后通过使用可学习的引导滤波方法将RGB图像和光谱测量值融合来估计高光谱图像。由于超像素估计步骤的计算复杂度低,因此我们的设置可以捕获场景的高光谱图像,而传统快照高光谱相机的开销很小,但是空间和光谱分辨率却更高。我们通过广泛的仿真以及实验室原型验证了提出的技术,该实验室原型以600倍900像素的空间分辨率,在可见波段上的10 nm光谱分辨率测量高光谱视频,并实现18 fps的帧频。 |
| Classification of Pathological and Normal Gait: A Survey Authors Ryan C. Saxe, Samantha Kappagoda, David K.A. Mordecai 步态识别是计算机科学领域内通常被称为识别问题的术语。有多种方法和模型能够根据他们的步行运动模式来识别他们。通过调查有关步态识别的最新文献,本文力图确定适当的指标,设备和算法,以收集和分析有关跨人群走动模式和方式的数据。此外,该调查旨在激发对跨状态(即生理状态,情绪状态或认知状态)的步态扰动的更广泛的纵向分析的兴趣。更广泛地说,基于纵向和非纵向分类形式,可以归因于正常步态与病理步态的推断。这可能表明有希望的研究方向和实验设计,例如创建用于量化疲劳的算法指标或用于预测突发性疾病的模型。此外,结合生理和环境条件的其他测量结果,病理步态分类可能适用于对传染病状态或认知障碍进行综合监测的推断。 |
| Evaluation and Comparison of Edge-Preserving Filters Authors Sarah Gingichashvili, Dani Lischinski 边缘保留滤镜在计算摄影的一些最基本任务中起着至关重要的作用,例如抽象,色调映射,细节增强和纹理去除等。平滑运算符的丰富性和多样性,以及缺乏评估输出质量和/或在它们之间进行不偏不倚的比较的方法,可能会导致对此类方法的误解和潜在滥用。本文介绍了一种评估和比较此类算子的系统方法,并在一系列已发布的边缘保留滤波器上进行了演示。此外,我们提出了一个共同的基线,通过该基线可以实现对不同运算符的比较,并使用它来确定方法之间的等效参数映射。最后,我们提出一些客观比较和评估边缘保留滤波器的准则。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com