1 简介
Redis,REmote DIctionary Server,是一个由 Salvatore Sanfilippo 写的 Key-Value 存储系统。
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(Value)可以是字符串(String), 哈希(Map), 列表(list), 集合(sets)和有序集合(sorted sets)等类型。
2 安装
官网地址: https://redis.io
下载地址: https://github.com/antirez/redis/releases
2.1 Windows
安装完成后在安装目录下执行:
redis-server.exe redis.windows.conf
2.2 Linux
下载,解压缩并编译Redis最新稳定版本:
wget http://download.redis.io/releases/redis-5.0.3.tar.gz
tar xzf redis-5.0.3.tar.gz
cd redis-5.0.3
make启动Redis服务:
cd src
./redis-server ../redis.conf
3 配置
Redis 的配置文件,Windows 是安装目录的 redis.windows.conf 文件,Linux 是安装目录下的 redis.conf 文件。
在连接上 Redis 服务后,可以通过 config 命令查看或者编辑配置项。
3.1 查看
redis 127.0.0.1:6379> config get ${name}例:
127.0.0.1:6379> config get port
1) "port"
2) "6379"3.2 编辑
redis 127.0.0.1:6379> config set ${name} ${value}例:
127.0.0.1:6379> config set loglevel "notice"
OK注:部分配置不能通过 config 命令动态编辑,需要直接修改配置文件对应内容,例如端口 port。
3.3 部分参数说明
3.3.1 daemonize
是否以守护线程运行,默认为 no,使用 yes 启用守护线程;(后台启动)
3.3.2 port
Redis监听端口,默认为 6379;
注:作者曾解释过 6379 的来历。6379 在手机按键对应的英文是 MERZ,意大利歌女 Alessia Merz 的名字。参考链接: http://oldblog.antirez.com/po...
3.3.3 bind
指定客户端连接地址,默认为 127.0.0.1,也就是只能本地连接,屏蔽该参数启用远程连接;
3.3.4 timeout
客户端空闲多长时间(秒)关闭该连接,指定为 0 关闭该功能;
3.3.5 save
save
指定在多长时间内,至少有多少次更新操作,就将数据同步到数据文件,可以多个条件配合使用;
Redis默认提供了三个条件:
save 900 1
save 300 10
save 60 10000说明Redis在下列三种情况将会同步数据到文件中:
- 在 900 秒后至少 1 个 key 发生改变;
- 在 300 秒后至少 10 个key发生改变;
- 在 60 秒后至少 10000 个key发生改变;
3.3.6 dbfilename
本地数据库文件名,默认是dump.rdb;
3.3.7 dir
本地数据库文件存放路径,默认是./(当前目录);
3.3.8 replicaof
replicaof
当在主从复制中,自己作为 slave,设置 master 的 ip 和端口,在该 slave 启动时,会自动从 master 进行数据同步;
3.3.9 masterauth
当 master 设置了密码后,slave 连接 master 的密码;
3.3.10 requirepass
设置 Redis 连接密码,默认关闭;
3.3.11 appendonly
开启 Redis 数据持久化到日志中(AOF),默认为 no 未开启;
由于默认的数据持久化方案(RDB),存储到 dump.rdb 文件中,在断电或服务突然挂掉的情况下会丢失数据,开启日志持久化可以弥补该不足;
3.3.12 appendfilename
日志文件名,默认为 appendonly.aof;
3.3.13 appendfsync
日志更新频率,有3个可选值;
- no,让操作系统自己决定,速度最快;
- always,每次操作都会写更新日志,速度较慢但最安全;
- everysec,每秒更新一次日志,折中方案;(默认)
3.4 淘汰策略
# maxmemory
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
#
# volatile-lru -> Evict using approximated LRU among the keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key among the ones with an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
#
# Both LRU, LFU and volatile-ttl are implemented using approximated
# randomized algorithms.
#
# Note: with any of the above policies, Redis will return an error on write
# operations, when there are no suitable keys for eviction.
#
# At the date of writing these commands are: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# The default is:
#
# maxmemory-policy noeviction - LRU least recently used 最近使用;
- LFU least frequently used 最少使用;
- noeviction 默认淘汰策略,return an error;
4 数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及 zset(sorted set:有序集合)。
4.1 string
最基本类型,二进制安全,也可以包含jpg或序列化后的对象,最大支持512M;
例:
127.0.0.1:6379> SET name "caojiantao"
OK
127.0.0.1:6379> GET name
"caojiantao"4.2 hash
Key-Value键值对集合,适合用来存储简单对象;
例:
127.0.0.1:6379> hmset user name caojiantao age 18
OK
127.0.0.1:6379> hget user age
"18"4.3 list
简单的字符串列表,双向链表的数据结构;
例:
127.0.0.1:6379> lpush months 1
(integer) 1
127.0.0.1:6379> lpush months 2
(integer) 2
127.0.0.1:6379> rpush months 3
(integer) 3
127.0.0.1:6379> lrange months 0 10
1) "2"
2) "1"
3) "3"
127.0.0.1:6379> lpop months
"2"
127.0.0.1:6379> rpop months
"3"4.4 set
string 类型的无序集合(唯一性),hash 结构,操作复杂度为 O(1);
例:
127.0.0.1:6379> sadd team zhangsan lisi
(integer) 2
127.0.0.1:6379> smembers team
1) "zhangsan"
2) "lisi"
127.0.0.1:6379> sadd team lisi
(integer) 04.5 zset
同 set,不过每个子元素会关联一个 double 类型的分数 score,zset 根据 score 排序;
例:
127.0.0.1:6379> zadd days 1 one
(integer) 1
127.0.0.1:6379> zadd days 0 zero
(integer) 1
127.0.0.1:6379> zadd days 2 two
(integer) 1
127.0.0.1:6379> zrangebyscore days 0 10
1) "zero"
2) "one"
3) "two"4.6 geo
geo 为地理位置类型,3.2+ 版本才开始支持,其底层实现仍是 zset,所以删除成员命令同 zrem;
重要命令一览:
- geoadd 增加某个地理位置坐标
- geopos 获取某个地理位置坐标
- geodist 获取两个地理位置的距离
- georadius 根据给定的地理位置坐标获取指定范围内的地理位置集合
- geohash 获取某个地理位置的 geohash 值
例:
127.0.0.1:6379> geoadd positions 116.407258 39.991496 olympics 116.403909 39.915547 tiananmen 116.333374 40.009645 qinghua
(integer) 3
127.0.0.1:6379> geodist positions tiananmen qinghua
"12070.5091"
127.0.0.1:6379> georadiusbymember positions tiananmen 20 km
1) "qinghua"
2) "tiananmen"
3) "olympics"
127.0.0.1:6379> georadiusbymember positions tiananmen 10 km
1) "tiananmen"
2) "olympics"4.7 小结
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | --- |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 |
| geo | 经纬度坐标类型 | 附近的人 |
5 特性
5.1 事务
multi
...(命令)
exec一次执行多条命令,有以下特点:
- 发送exec指令前,所有的操作都会放入队列缓存;
- 执行事务时,任何命令执行失败,其他命令正常被执行,已操作的命令不会回滚(非原子性);
- 执行过程中,其他客户端的命令不会插入到该事务中;
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set a 1
QUEUED
127.0.0.1:6379> set b 2
QUEUED
127.0.0.1:6379> get a
QUEUED
127.0.0.1:6379> del a
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) "1"
4) (integer) 15.2 发布订阅
Redis 支持一个发布订阅的消息通信模式,发送者 pub 发送消息,订阅者 sub 接受消息,可订阅任意数量的频道 channel;
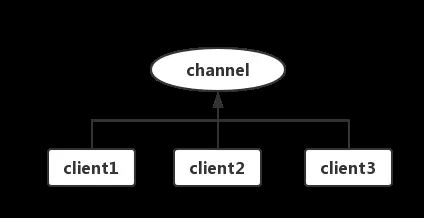
三个客户端都订阅了 channel 这个频道;
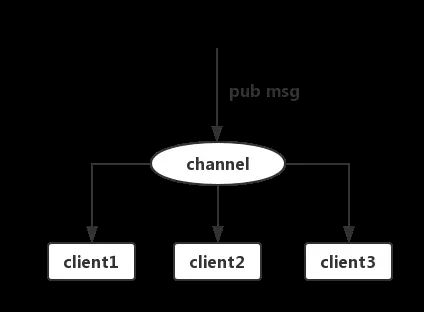
一旦有消息发布pub到channel中,之前订阅该channel的三个客户端都会收到这个message;
例:
客户端订阅talk频道;
127.0.0.1:6379> subscribe talk
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "talk"
3) (integer) 1另开客户端发布消息值talk频道;
127.0.0.1:6379> publish talk "hello world"
(integer) 1此时客户端收到消息;
1) "message"
2) "talk"
3) "hello world"5.3 脚本
Redis 使用 Lua 解释器执行,执行命令为eval;
eval script numkeys key [key ...] arg [arg ...]- script,lua脚本内容
- numkeys,key的个数
- key,Redis中key属性
- arg,自定义参数
注:key 和 arg 在 lua 脚本占位符分别为 KEYS[] 和 ARGV[],必须大写,数组下标从 1 开始。
例:获取脚本参数
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1]}" 2 "key1" "key2" "argv1"
1) "key1"
2) "key2"
3) "argv1"通常会将脚本存储到一个lua文件中,假如test.lua内容如下:
return {KEYS[1],KEYS[2],ARGV[1]}执行这个lua脚本命令;
redis-cli.exe --eval test.lua "key1" "key2" , "argv1"
1) "key1"
2) "key2"
3) "argv1"注意参数格式与之前有点出入,执行lua脚本文件不需要numkeys,key和arg参数用逗号相隔;
6 数据结构
6.1 sorted set
两种编码实现:ziplist 和 skiplist,当满足下列条件采用 ziplist 编码方式:
- 有序集合保存的元素数量小于128个 ;
- 有序集合保存的所有元素成员的长度小于64字节 ;
同时 zset 还维护了一个字典,保存元素 member 到 分值 score 的映射,便于等值查找。
6.1.1 ziplist
压缩列表, 2 个紧挨在一起的节点组成一个元素,代表元素的实际值和分值大小。
6.1.2 skiplist
跳跃表,有利于范围查找,相比红黑树实现难度较为简单得多。
参考: https://segmentfault.com/a/11...
7 为什么快
- 完全基于内存;
- 数据结构简单;
- 单线程避免上下文切换;
- 多路 I/0 复用模型,非阻塞;
8 使用(Java)
8.1 客户端
8.1.1 Jedis
github: https://github.com/xetorthio/jedis
阻塞 I/O 模型,调用方法都是同步的,不支持异步调用,并且 Jedis 客户端非线程安全,需要结合连接池使用;
maven依赖:
redis.clients
jedis
2.9.0
demo示例:
String host = "127.0.0.1";
int port = 6379;
// 连接本地的 Redis 服务
Jedis jedis = new Jedis(host, port);
// 查看服务是否运行
System.out.println("服务正在运行: " + jedis.ping());
// 基本操作
String key = "welcome";
jedis.set(key, "hello world");
System.out.println(jedis.get(key));
// 连接池配置
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxTotal(1);
// 连接池操作
JedisPool pool = new JedisPool(config, host, port);
Jedis a = pool.getResource();
// a.close();
System.out.println(a);
Jedis b = pool.getResource();
System.out.println(b);8.1.2 Lettuce
github: https://github.com/lettuce-io/lettuce-core
基于 Netty 框架,异步调用,线程安全;
maven依赖:
io.lettuce
lettuce-core
5.0.3.RELEASE
demo示例:
// 1. 构造uri
RedisURI uri = RedisURI.builder()
.withHost("127.0.0.1")
.withPort(6379)
.build();
// 2. 创建client
RedisClient client = RedisClient.create(uri);
// 3. 连接redis
StatefulRedisConnection connect = client.connect();
// 4. 获取操作命令(同步)
RedisCommands commands = connect.sync();
String key = "welcome";
System.out.println(commands.get(key));
connect.close(); 8.1.3 Redission
github: https://github.com/redisson/redisson
实现了分布式和可扩展的 Java 数据结构;
maven依赖:
org.redisson
redisson
3.11.5
demo示例:
public static void main(String[] args) {
// 1. 创建连接配置
Config config = new Config();
config.useSingleServer().setAddress("redis://10.242.24.246:6379");
// 2. 创建 redisson 实例
RedissonClient client = Redisson.create(config);
// 操作数据
RBucket8.2 springboot集成
8.2.1 maven 依赖
org.springframework.boot
spring-boot-starter-data-redis
注:springboot 2.x 之后使用了 Lettuce 替换掉了底层 Jedis 的依赖。
8.2.2 属性配置
在 application.yml 添加下面属性
spring:
redis:
host: 127.0.0.1
port: 6379
password: 123456
# 连接池配置(根据需要)
lettuce:
pool:
max-idle: 88.2.3 基本使用
springboot 默认注入了 RedisTemplate 和 StringRedisTemplate 两个实例用来操作 Redis,前者 key 和 value 都是采用 JDK 序列化,后者只能操作 String 数据类型;
可直接注入使用;
@Autowired
@Qualifier("redisTemplate")
private RedisTemplate redisTemplate;
@Autowired
@Qualifier("stringRedisTemplate")
private StringRedisTemplate stringRedisTemplate;
public void test() {
String key = "welcome";
Object o = redisTemplate.opsForValue().get(key);
// 此处为null,由于key序列化方式为JDK
System.out.println(o);
String s = stringRedisTemplate.opsForValue().get(key);
System.out.println(s);
}注:Redis 默认注入原理可参考 RedisAutoConfiguration 类。
8.2.4 自定义 Template
默认注入的两种 RedisTemplate 显然不适用所有的业务场景,自定义 Template 一般只需下列两个步骤;
- 自定义 RedisSerializer;
- 注入自定义 Template;
参考第三方序列化框架 protostuff,序列化后体积较小,速度快;
import io.protostuff.*;
import io.protostuff.runtime.RuntimeSchema;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.SerializationException;
/**
* @author caojiantao
*/
public class ProtoStuffSerializer implements RedisSerializer {
private Class clazz;
public ProtoStuffSerializer(Class clazz) {
this.clazz = clazz;
}
@Override
public byte[] serialize(T t) throws SerializationException {
if (t == null) {
return new byte[0];
}
Schema schema = RuntimeSchema.getSchema(clazz);
return ProtostuffIOUtil.toByteArray(t, schema, LinkedBuffer.allocate());
}
@Override
public T deserialize(byte[] bytes) throws SerializationException {
if (bytes == null) {
return null;
}
Schema schema = RuntimeSchema.getSchema(clazz);
T t = schema.newMessage();
ProtostuffIOUtil.mergeFrom(bytes, t, schema);
return t;
}
} 然后手动注入到spring容器中;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
@Configuration
public class RedisConfig {
@Bean("customTemplate")
public RedisTemplate customTemplate(RedisConnectionFactory factory) {
RedisTemplate template = new RedisTemplate<>();
// 注入redis连接工厂实例
template.setConnectionFactory(factory);
ProtoStuffSerializer serializer = new ProtoStuffSerializer<>(Student.class);
// 设置key、value序列化方式
template.setKeySerializer(RedisSerializer.string());
template.setValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
} 9 分布式解决方案
9.1 主从同步
将所有数据存储到单个 Redis 主要存在两个问题;
- 数据备份;
- 数据量过大降低性能;
主从模式很好的解决了以上问题。一个 Redis 实例作为主机 master,其他的作为从机 slave,主机主要用于数据的写入,从机则主要提供数据的读取。从机在启动时会同步全量主机数据,主机也会在写入数据的时候同步到所有的从机。
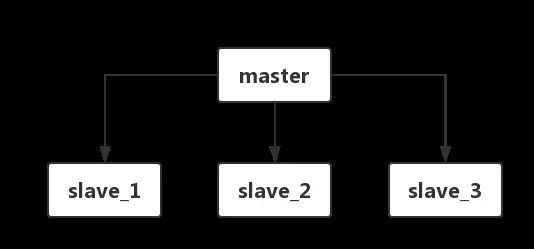
有两种方式可以设置主从关系;
- 在启动配置文件指定 replicaof 参数;
- 启动Redis实例后执行
replicaof ip port命令;
简单测试,复制 redis.conf 文件,主要配置如下:
master:
port 6379
logfile "6379.log"
dbfilename "dump-6379.rdb"slave_1:
port 6380
logfile "6380.log"
dbfilename "dump-6380.rdb"
replicaof 127.0.0.1 6379slave_2:
port 6381
logfile "6381.log"
dbfilename "dump-6381.rdb"
replicaof 127.0.0.1 6379slave_3:
port 6382
logfile "6382.log"
dbfilename "dump-6382.rdb"
replicaof 127.0.0.1 6379依次启动上述四个Redis实例;
./redis-server 6379.conf
./redis-server 6380.conf
./redis-server 6381.conf
./redis-server 6382.conf连接6379主机master,查看replication信息;
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:3
slave0:ip=127.0.0.1,port=6380,state=online,offset=322,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=322,lag=1
slave2:ip=127.0.0.1,port=6382,state=online,offset=322,lag=0
master_replid:417b1e3811a2d9b3465876d65c67a36949de8f9f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:322
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:322说明了当前 Redis 实例为主机,有三个从机;
在当前主机写入数据;
127.0.0.1:6379> set msg "hello world"
OK在其他任意从机执行获取操作;
127.0.0.1:6382> get msg
"hello world"已经成功设置主从同步。
9.2 哨兵模式
主从模式存在一定的弊端,master 一旦发生宕机,主从同步过程将会中断。
Sentinel(哨兵)作为一个单独的服务,用来监控 master 主机,间接监控所有 slave 从机,如下图所示;
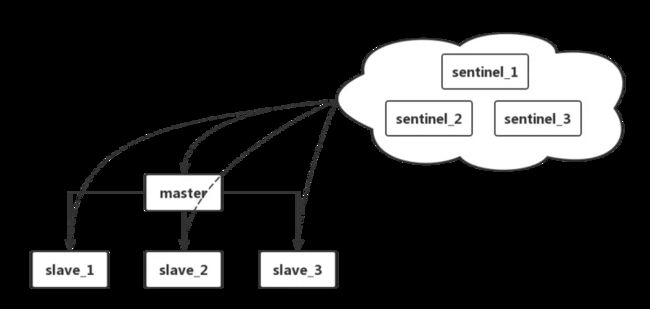
sentinel 主要有以下三个特点;
- 监控 Redis 实例是否正常运行;
- 节点发生故障,能够通知另外;
当master发生故障,sentinel 会采用在当前 sentinel 集群中投票方式,从当前所有 slave 中,推举一个作为新的master,从而保证了 Redis 的高可用性。
9.3 集群模式
在哨兵模式下,每个 Redis 实例都是存储的全量数据。为了最大化利用内存空间,采用集群模式,即分布式存储,每台 Redis 存储不同的内容。Redis 集群没有使用一致性hash,而是引入了哈希槽的概念 。
数据存储在 16384 个 slot(插槽)中,所有的数据都是根据一定算法映射到某个 slot 中;
为什么是 16384: https://github.com/antirez/re...
集群模式至少三个Redis节点,否则会提示:
./redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001
*** ERROR: Invalid configuration for cluster creation.
*** Redis Cluster requires at least 3 master nodes.
*** This is not possible with 2 nodes and 0 replicas per node.
*** At least 3 nodes are required.在src目录创建confs文件夹,复制redis.conf文件6分,三主三从;
主要配置如下;
port 7000
cluster-enabled yes
cluster-node-timeout 15000
cluster-config-file "nodes-7000.conf"
pidfile /var/run/redis-7000.pid
logfile "cluster-7000.log"
dbfilename dump-cluster-7000.rdb
appendfilename "appendonly-cluster-7000.aof"顺序启动相关Redis示例,最后创建集群;
./redis-server confs/7000.conf
./redis-server confs/7001.conf
./redis-server confs/7002.conf
./redis-server confs/7003.conf
./redis-server confs/7004.conf
./redis-server confs/7005.conf
./redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1控制台输出创建集群信息:
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 10.242.24.246:7003 to 10.242.24.246:7000
Adding replica 10.242.24.246:7004 to 10.242.24.246:7001
Adding replica 10.242.24.246:7005 to 10.242.24.246:7002
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: bbb45e488e5679b79dd077f97803304534793420 10.242.24.246:7000
slots:[0-5460] (5461 slots) master
M: b490121213e22451a9b788755b0be0d3bf158cda 10.242.24.246:7001
slots:[5461-10922] (5462 slots) master
M: 000f55716f8e9f2c635744999a49425bcc65595d 10.242.24.246:7002
slots:[10923-16383] (5461 slots) master
S: 17611ff6f3dffbfab60ce4ae7b7991a9ae280bcd 10.242.24.246:7003
replicates b490121213e22451a9b788755b0be0d3bf158cda
S: 950a5a467ccb6af3280b67a3f2ce2e3fa7510bd8 10.242.24.246:7004
replicates 000f55716f8e9f2c635744999a49425bcc65595d
S: c15ce5e96e69a1d93c5a71953ee044af6b2bd560 10.242.24.246:7005
replicates bbb45e488e5679b79dd077f97803304534793420
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
...........
>>> Performing Cluster Check (using node 10.242.24.246:7000)
M: bbb45e488e5679b79dd077f97803304534793420 10.242.24.246:7000
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: c15ce5e96e69a1d93c5a71953ee044af6b2bd560 10.242.24.246:7005
slots: (0 slots) slave
replicates bbb45e488e5679b79dd077f97803304534793420
M: b490121213e22451a9b788755b0be0d3bf158cda 10.242.24.246:7001
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 950a5a467ccb6af3280b67a3f2ce2e3fa7510bd8 10.242.24.246:7004
slots: (0 slots) slave
replicates 000f55716f8e9f2c635744999a49425bcc65595d
M: 000f55716f8e9f2c635744999a49425bcc65595d 10.242.24.246:7002
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 17611ff6f3dffbfab60ce4ae7b7991a9ae280bcd 10.242.24.246:7003
slots: (0 slots) slave
replicates b490121213e22451a9b788755b0be0d3bf158cda
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.集群部署成功后,连接7000这个节点,注意连接命令:
./redis-cli -c -p 7000
127.0.0.1:7000> get name
-> Redirected to slot [5798] located at 127.0.0.1:7001
(nil)9.3.1 添加节点
假如当前集群为 7000, 7001, 7002 三个节点,正确配置启动新节点 7003 后执行命令:
[root@localhost redis-conf]# redis-cli --cluster add-node 127.0.0.1:7003 127.0.0.1:7000
>>> Adding node 127.0.0.1:7003 to cluster 127.0.0.1:7000
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: 9de886a23be8bc92bbe51a4e73ad27d2fb96df8d 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: cba883e361f23f1415e4d94148c7c26900c28111 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
M: 3855e27b1ec68d6481d6d308101fb28dd6ed21df 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 127.0.0.1:7003 to make it join the cluster.
[OK] New node added correctly.添加的新节点没有分配 slots,需要手动分配:
[root@localhost redis-conf]# redis-cli --cluster reshard 127.0.0.1:7000
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: 9de886a23be8bc92bbe51a4e73ad27d2fb96df8d 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: cba883e361f23f1415e4d94148c7c26900c28111 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
M: 28eedd55e0fd8e35d36766055b720418c14fa04a 127.0.0.1:7003
slots: (0 slots) master
M: 3855e27b1ec68d6481d6d308101fb28dd6ed21df 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 100
What is the receiving node ID? 28eedd55e0fd8e35d36766055b720418c14fa04a
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 9de886a23be8bc92bbe51a4e73ad27d2fb96df8d
Source node #2: done
Ready to move 100 slots.
Source nodes:
M: 9de886a23be8bc92bbe51a4e73ad27d2fb96df8d 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
Destination node:
M: 28eedd55e0fd8e35d36766055b720418c14fa04a 127.0.0.1:7003
slots: (0 slots) master
Resharding plan:
...
...
Do you want to proceed with the proposed reshard plan (yes/no)? yes
...
...节点检查:
[root@localhost redis-conf]# redis-cli --cluster info 127.0.0.1:7000
127.0.0.1:7000 (9de886a2...) -> 0 keys | 5361 slots | 0 slaves.
127.0.0.1:7001 (cba883e3...) -> 0 keys | 5462 slots | 0 slaves.
127.0.0.1:7003 (28eedd55...) -> 0 keys | 100 slots | 0 slaves.
127.0.0.1:7002 (3855e27b...) -> 0 keys | 5461 slots | 0 slaves.9.3.2 删除节点
首先将该节点的 slots 转移(同新增),然后执行删除节点操作:
[root@localhost redis-conf]# redis-cli --cluster del-node 127.0.0.1:7003 28eedd55e0fd8e35d36766055b720418c14fa04a
>>> Removing node 28eedd55e0fd8e35d36766055b720418c14fa04a from cluster 127.0.0.1:7003
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.9.4 分布式锁
场景:定时任务集群部署,Job 需要加锁单次执行;
方案:基于 Redis 实现分布式锁,以 Job 唯一标识为 key,设置 expiration,在 Job 执行前获取锁判定;
优点:实现较为简单,过期策略防止死锁,效率较高;
基于 springboot 2.x 项目,参考代码如下;
加锁:
/**
* 尝试加锁
*
* @param lockKey 加锁的KEY
* @param requestId 加锁客户端唯一ID标识
* @param expireTime 过期时间
* @param timeUnit 时间单位
* @return 是否加锁成功
*/
public Boolean tryLock(String lockKey, String requestId, long expireTime, TimeUnit timeUnit) {
RedisConnection connection = connectionFactory.getConnection();
Boolean result = connection.set(lockKey.getBytes(StandardCharsets.UTF_8), requestId.getBytes(StandardCharsets.UTF_8), Expiration.from(expireTime, timeUnit), RedisStringCommands.SetOption.SET_IF_ABSENT);
connection.close();
return result;
}requestId 通常用作标识加锁请求的唯一性,只有对应的加锁请求,才能成功解锁。防止某个客户端操作阻塞很久,锁超时自动释放被另外客户端拿到,然后自己又执行释放锁释放掉其他客户端当前持有的锁。
解锁:
/**
* 释放锁
*
* @param lockKey 加锁的KEY
* @param requestId 加锁客户端唯一ID标识
* @return 是否释放成功
*/
public boolean releaseLock(String lockKey, String requestId) {
// Lua代码,一次性执行保证原子性,避免并发问题
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
RedisConnection connection = connectionFactory.getConnection();
byte[][] keysAndArgs = new byte[2][];
keysAndArgs[0] = lockKey.getBytes(StandardCharsets.UTF_8);
keysAndArgs[1] = requestId.getBytes(StandardCharsets.UTF_8);
Long result = connection.scriptingCommands().eval(script.getBytes(StandardCharsets.UTF_8), ReturnType.INTEGER, 1, keysAndArgs);
connection.close();
return result != null && result > 0;
}注意解锁姿势,保证操作原子性。
9.4.1 锁超时
当锁的持有时间无法估算,存在锁超时导致被自动释放掉的可能。可以在获取锁成功时,开启一个定时线程询问持有锁状况,若当前仍持有锁状态,则刷新过期时间。
参考 Redisson 实现:https://github.com/redisson/redisson/blob/master/redisson/src/main/java/org/redisson/RedissonLock.java (renewExpiration)
9.4.2 RedLock
主从复制时,获取锁成功还未同步 slave 时,master 宕机会出现数据不一致情况。
官方提供名为 RedLock 的算法思想:
- 获取当前时间;
- 尝试按顺序在 N 个节点获取锁;
- 在大多数节点获取锁成功,则认为成功;
- 如果锁获取成功了,锁有效时间就是最初的锁有效时间减去之前获取锁所消耗的时间;
- 如果锁获取失败了,将会尝试释放所有节点的锁;
Redlock 算法: https://redis.io/topics/distlock
10 缓存雪崩、缓存穿透和缓存击穿
10.1 缓存雪崩
描述:同一时间缓存大面积失效,数量级的请求直接打到数据库。
方案:给缓存失效时间加上一个随机数。
10.2 缓存穿透
描述:请求不符合缓存条件,直接打到数据库。
方案:参数做好校验,null 值也可缓存。
10.3 缓存击穿
描述:热点数据失效瞬间,大量对该热点数据的请求直接打到数据库。
方案:设置缓存永不过期,或者查询引入互斥锁。