本文首发于: 行者AI
绝大多数音频特征起源于语音识别任务,它们可以精简原始的波形采样信号,从而加速机器对音频中语义含义的理解。从20世纪90年代末开始,这些音频特征也被应用于乐器识别等音乐信息检索任务中,更多针对音频音乐设计的特征也应运而生。
1. 音频特征的类别
认识音频特征不同类别不在于对某一个特征精准分类而是加深理解特征的物理意义,一般对于音频特征我们可以从以下维度区分:
(1)特征是由模型从信号中直接提取还是基于模型的输出得到的统计,如均值、方差等;
(2)特征表示的是瞬态还是全局上的值,瞬态一般以帧为单位而全局则覆盖更长的时间维度;
(3)特征的抽象程度,底层特征抽象程度最低也是最易从原始音频信号中提取,它可以进一步被处理为高一级的中间特征代表乐谱中常见的音乐元素,如音高、音符的起始时间等;高层特征最为抽象大多用于音乐的曲风和情绪任务;
(4)根据特征提取过程的差异可以分为:从原始信号中直接提取的特征(如过零率)、将信号转换为频率得到的特征(如谱心质)、需经过特定的模型得到的特征(如旋律)、受人耳听觉认知启发改变量化特征尺度得到的特征(如MFCCs)。
我们以“特征提取过程的差异”为主要分类基准,列出各类下比较常见的特征:
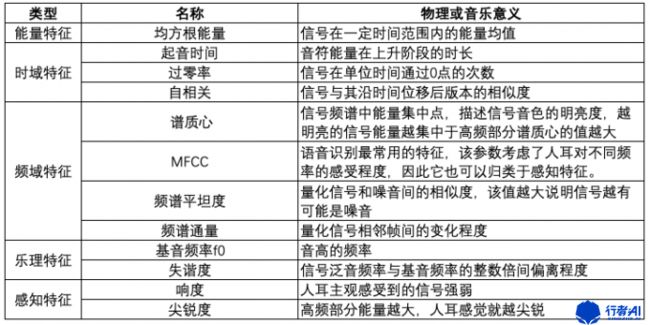
同时我们也发现部分特征并非完全属于其中一个类别例如MFCC,因为提取MFCC会将信号从时域转换至频域然后根据模仿人类听觉响应的MEL尺度过滤器得到的,因此它属于既属于频域特征又属于感知特征。
2. 常用提取工具
下面罗列出一些常用提取音频特征的工具和使用平台。
| 名称 | 地址 | 适配语言 |
|---|---|---|
| Aubio | https://aubio.org | c/python |
| Essentia | https://essentia.upf.edu | c++/python |
| Librosa | https://librosa.org | python |
| Madmom | http://madmom.readthedocs.org | python |
| pyAudioAnalysis | https://github.com/tyiannak/p... | python |
| Vamp-plugins | https://www.vamp-plugins.org | c++/python |
| Yaafe | http://yaafe.sourceforge.net | python/matlab |
3. 音频信号处理
音频数字信号是一系列数字代表时域中连续变化的样本,也就是常常说的“波形图”。要对数字信号进行分析操作需对信号进行采样和量化。
采样是指连续时间的离散化的过程,其中均匀采样是指每隔相等时间间隔采样一次,每秒需要采集的声音样本个数叫做采样频率,音频文件中常常见到的44.1kHz、11kHz就是指的采样(频)率。
量化将连续波形转变为离散化的数字,先将整个幅度划分为有限个量化阶距的集合,幅度的划分可以是等间距或不等间距的把落入某个阶距内的样本值赋予相同的量化值。音频文件中的位深代表的就是量化值,16bit位深代表的就是将幅值量化为2^16。
奈奎斯特定律指出如果采样频率大于等于信号中最高频率分量的2倍,一个信号可以从他的采样值精确地重构,实际上采样频率明显大于奈奎斯特频率。
4. 常用变换
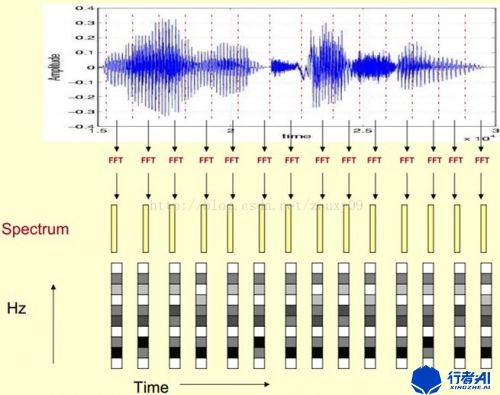
4.1 短时傅里叶变换
短时傅里叶变换(Short Time Fourier Transform, STFT)适用于分析缓慢时变信号的频谱分析,在音频和图像分析处理中已经得到广泛应用。其方法是先将信号分帧,再将各帧进行傅里叶变换。每一帧语音信号可以被认为是从各个不同的平稳信号波形中截取出来的,各帧语音的短时频谱就是各个平稳信号波形频谱的近似。
由于语音信号是短时平稳的,因此可以对信号进行分帧处理,计算某一帧的傅里叶变换,这样得到的就是短时傅里叶变换。
傅里叶变换(FFT)可以将信号从时域转变为频域,而逆傅里叶变换(IFFT)则可以将频域转换为时域信号;傅里叶变换将信号从时域转变为频域是音频信号处理最常用的方式。STFT得到的频谱图在音频信号中又叫做声谱图或语谱图。
4.2 离散余弦变换
离散余弦变换(DCT for Discrete Cosine Transform)是与傅里叶变换相关的一种变换,它类似于离散傅里叶变换(DFT for Discrete Fourier Transform),但是只使用实数。离散余弦变换相当于一个长度大概是它两倍的离散傅里叶变换,这个离散傅里叶变换是对一个实偶函数进行的(因为一个实偶函数的傅里叶变换仍然是一个实偶函数),在有些变形里面需要将输入或者输出的位置移动半个单位。
4.3 离散小波变换
离散小波变换(Discrete Wavelet Transform)在数值分析和时频分析中很有用,离散小波变换是对基本小波的尺度和平移进行离散化。
4.4 梅尔频谱和梅尔倒谱
声谱图往往是很大的一张图,为了得到合适大小的声音特征,往往把它通过梅尔标度滤波器组(mel-scale filter banks),变换为梅尔频谱。
人耳的音高感觉大致与声音的基频对数呈线性关系。在梅尔标度下,如果两段语音的梅尔频率相差两倍,则人耳可以感知到的音调大概也相差两倍。 当频率较小时,mel随Hz变化较快;当频率很大时,mel的上升很缓慢,曲线的斜率很小。这说明了人耳对低频音调的感知较灵敏,在高频时人耳是很迟钝的,梅尔标度滤波器组启发于此。
梅尔标度滤波器由多个三角滤波器组成滤波器组,低频处滤波器密集,门限值大,高频处滤波器稀疏,门限值低。恰好对应了频率越高人耳越迟钝这一客观规律。上图所示的滤波器形式叫做等面积梅尔滤波器(Mel-filter bank with same bank area),在人声领域(语音识别,说话人辨认)等领域应用广泛,但是如果用到非人声领域,就会丢掉很多高频信息。这时我们更喜欢的或许是等高梅尔滤波器(Mel-filter bank with same bank height)。

librosa中MEL频谱实现:
import numpy as np
def melspectrogram(y=None, sr=22050, S=None, n_fft=2048, hop_length=512,
power=2.0, **kwargs):
S, n_fft = _spectrogram(y=y, S=S, n_fft=n_fft, hop_length=hop_length, power=power)
# Build a Mel filter
mel_basis = filters.mel(sr, n_fft, **kwargs)
return np.dot(mel_basis, S)而梅尔倒谱在梅尔频谱上做倒谱分析(取对数,做DCT变换)就得到了梅尔倒谱。
# -- Mel spectrogram and MFCCs -- #
def mfcc(y=None, sr=22050, S=None, n_mfcc=20, **kwargs):
if S is None:
S = power_to_db(melspectrogram(y=y, sr=sr, **kwargs))
return scipy.fftpack.dct(S, axis=0, type=dct_type, norm=norm)[:n_mfcc]4.5 恒Q变换
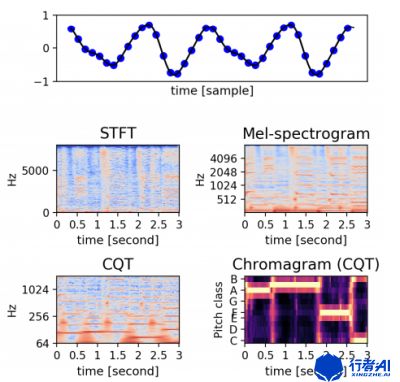
在音乐中,所有的音都是由若干八度的12平均律共同组成的,这十二平均律对应着钢琴中一个八度上的十二个半音。这些半音临近之间频率比为21/12。显然,同一音级的两个八度音,高八度音是低八度音频率的两倍。因此在音乐当中,声音都是以指数分布的,但我们的傅立叶变换得到的音频谱都是线性分布的,两者的频率点是不能一一对应的,这会指使某些音阶频率的估计值产生误差。所以现代对音乐声音的分析,一般都采用一种具有相同指数分布规律的时频变换算法:恒Q变换(Constant Q transform)。
CQT指中心频率按指数规律分布,滤波带宽不同、但中心频率与带宽比为常量Q的滤波器组。它与傅立叶变换不同的是,它频谱的横轴频率不是线性的,而是基于log2为底的,并且可以根据谱线频率的不同该改变滤波窗长度,以获得更好的性能。由于CQT与音阶频率的分布相同,所以通过计算音乐信号的CQT谱,可以直接得到音乐信号在各音符频率处的振幅值。
参考资料
《A Tutorial on Deep Learning for Music Information Retrieval》