面试官问基本数据类型不会回答,看这一篇足够了(建议收藏!!!)
本篇博客主要记录Java数据类型当中一些知识,这都属于基础的不能再基础的知识了,那么您是否真的掌握透彻呢?需要的朋友们下面随着小编来一起学习学习吧!
目录
-
- 数据类型的作用是什么?
- JAVA中数据类型分类
- 类型占用空间及取值范围
-
- 简单回顾
- 什么是二进制?
- 计算机只认识二进制,那么计算机怎么表示文字的呢?
- 计算单位换算
- 简单理解字节
- 八大类型使用详解
-
- int型
- byte型
- short型
- long型
- 浮点类型(float、double)
- char型
- boolean型
- 数据类型转换
-
- 隐式转换
- 显式转换
读完这一篇,我相信再次遇到面试有人问有关数据类型的,你不会再不知所措。
数据类型的作用是什么?
程序当中有很很多数据,每一个数据都是有相关类型的,不同的数据类型的占用的空间大小也是不一样的,数据类型的作用就是指导JVM在运行程序的时候给该数据分配多大的内存空间。
JAVA中数据类型分类
数据类型分为两种,基本数据类型和引用数据类型
基本数据类型分为四类:
整数型(byte,short,int,long)
浮点型(float,double)
布尔型(boolean)
字符型(char)
引用类型分为三类:
数组
类
接口
类型占用空间及取值范围
简单回顾
在了解占用空间前,先简单回顾一些计算机知识。
计算机在任何情况下都只能识别二进制,例如:只认识101010101010,
现代的计算机底层采用交流电的方式,接通和断开就两种状态,计算机只认识1或0;
什么是二进制?
数据的一种表示形式,十进制表示满十进一原则,二进制表示满二进一原则。
例如:十进制
0 1 2 3 4 5 6 7 8 9 10 11 12 …
例如:二进制
十进制:0 1 2 3 4 5 6 7 8 9
二进制:0 1 10 11 100 101 110 111 1000 1001
二进制就是遵循 1 2 4 8 16
计算机只认识二进制,那么计算机怎么表示文字的呢?
八种基本数据类型当中,byte,short,int,long,float,double,boolean这七种数据类型底层都是数字,计算机表示的时候非常容易,十进制数字和二进制之间存在一种固定转换规则。
但是八种基本数据类型当中char类型表示的是现实世界中的文字,文字和二进制之间是不存在任何转换关系的。
为了让计算机可以表示现实世界当中的文字,我们需要进一步人为干涉,需要人为的提前制定好文字和二进制之间的对照关系,这种对照关系转换称为:字符编码。
计算机最初只支持英文,最先出现的字符编码是:ASCII码
a用数字表示就是97,A用数字表示就是65
ASCII码我们可以理解为一本字典,也就是每个字母他都对应一个数字来表示,最终数字再转换成二进制,然后完成机器识别。
‘a’ --(按照ASCII解码) --> 01100001
01100001 --(按照ASCII编码) --> ‘a’
当编码和解码采用的不是同一套对照表,会出现乱码问题。
计算单位换算
1 Byte = 8 bit 【1个字节 = 8个比特位】 1个比特位表示一个二进制位 : 1/0
1 KB = 1024 Byte
1 MB = 1024 KB
1 GB = 1024 MB
1 TB = 1024 GB
1 TB = 1024 * 1024 * 1024 * 1024 * 8 bit
也就是我们常听到的1TB 他可以存储

这么多个1或者0。
简单理解字节
byte占用1个字节,所以byte类型的数据占用了8个比特位,8个比特位就相当于8个0或者1。
关于java数字类型,数字都是有正负之分的,所以在数字的二进制当中有一个二进制位被称为符号位。并且这个符号位在所有二进制位最左边,0表示正数,1表示负数。
由上得知:byte类型最大值二进制表示:01111111
2的7次方-1 结果是 127
所以他的取值范围是由字节数来决定的。
最小值 -128 (二进制表示涉及到原码,反码,补码了,了解即可本篇不过多细讲)

八大类型使用详解
int型
声明int型变量,代码如下:
这里需要注意的是,假如声明了变量但是没有赋值,输出是会报错的!!!

int变量在内存中占4字节,也就是32位bit,也就是32个0或者1,所以int类型的5在计算机是这样显示的:
00000000 00000000 00000000 00000000 00000101
byte型
byte型的声明方式和int型相同。唯一区别就是字节数
声明byte类型变量,代码如下:

short型
short型的声明方式和int型相同。唯一区别就是字节数
看到这里会发现,其实byte int short都可以用来表达数字的,用法没区别,而开发当中int用的最多,
byte short特别少见,原因只有一个,int表达的范围大。
声明short类型变量,代码如下:

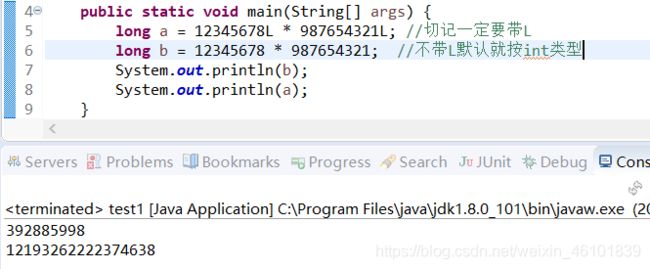
long型
由于long型的取值范围比int大,且属于高级的数据类型,所以在赋值的时候要和int型做出区分,需要在整数后加L或者l(小写的L)。
声明long类型变量,代码如下:
这里有一个常见错误,就是使用long类型,但是赋值没有带L,int型是JAVA默认的证书类型,不加L默认是int,在这里可以看出算出来的b输出出来是错误的。因为int类型的字节数就这么大。所以表示不全!
浮点类型(float、double)
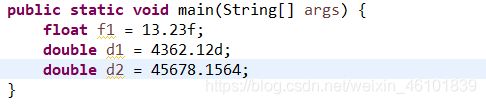
float和double被称为浮点类型,浮点类型表示有小数部分的数字,java中浮点类型分为单精度浮点类型(float)和双精度浮点类型(double),他们具有不同的取值范围。
在默认情况下小数都被看作double型,若想使用float型声明小数,则需要在小数后面添加F或f。另外可以使用后缀d或D来明确表明这是一个double类型数据,但加不加d或D并没有硬性规定。而声明float型变量时如果不加F或f,系统会认为是double类型而出错。
声明浮点类型变量,代码如下:
注意:浮点值属于近似值,在系统中运算后的结果可能与实际有偏差。
char型
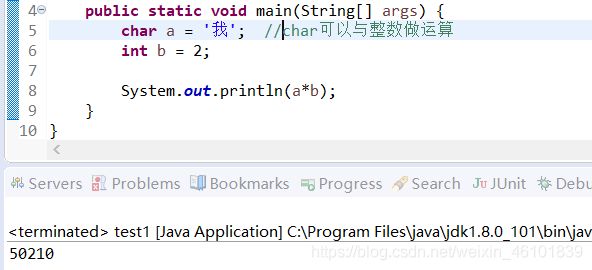
字符类恶性用于存储单个字符,占用16位bit的内存空间。声明字符型变量时候,要以单引号表示,如‘s’表示一个字符。
Java可以把字符作为整数对待,由于Unicode编码采用无符号编码,可以存储65535个字符,char可以和整数做运算。
代码示例:
boolean型
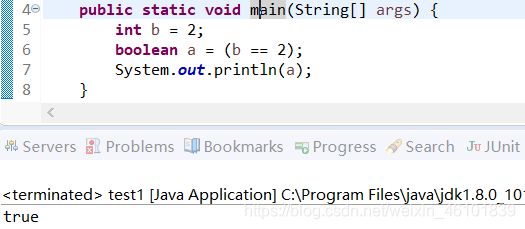
布尔类型又称逻辑类型,只有true和false两个值,分别代表布尔逻辑中的真和假。布尔类型不能与整数类型进行转换。
代码示例:
数据类型转换
类型转换是将一个值从一种数据类型更改为另一种数据类型的过程。数据类型转换有两种方式,即隐式转换和显示转换,如果低精度数据类型向高精度类型转换,那肯定成功的,高精度转低精度必然会有信息丢失,甚至可能失败。
这里所指的精度,可以理解为数据的准确度。
隐式转换
从低级类型向高级转换,系统将自动执行,无需进行任何操作,这种类型的转换称为隐式转换,也可以称为自动转换。
这些类型按精度从低到高排序为:byte->short->int->long->float->double
char类型比较特殊,他可以与部分int型数字兼容,不会发生精度变化。
代码示例:
像高精度转低精度类型,直接编译报错,在开发程序的时候经常会遇到高转低,这种情况就需要使用显示转换了。

显式转换
语法:(类型名)要转换的值
上面我们提到过了高转低,有时候会丢失精度,在这里我给大家写一个例子,相信通过这个例子应该思路就很清晰了。
代码示例:
造成这种情况的原因可以理解为,你拿个水壶想要往水杯里装水,水杯能 装的水是有限的,所以只能装满为止,这个时候肯定有一部分水是装不下去的。这就会产生丢失的情况!

当把整数赋值给一个byte、short、int、long型变量时,不可以超过变量的取值范围,否则必须强制类型转换。
例如:这种场景直接编译就报错了。强制转换之后虽然输出的数据不是129,但是直接避免了编译报错。

点个赞吧!
希望更多的人看得到!