Win10上darknet-yolov3-训练自己的数据集
文章目录
-
-
-
- 准备数据集
- 生成、修改文件
- 训练
- 测试
-
-
关于win10上darknet-yolov3的配置 https://blog.csdn.net/qq_41433316/article/details/98354269 上面有,这里主要记录一下训练的过程:
准备数据集
将数据集做成VOC格式的,使用labelimg工具对图片进行标注生成xml文件
生成、修改文件
1、进入build–>darknet–>x64,在该目录下进行操作
2、进入data–>VOCdevkit(如果没有VOCdevkit的话就从自行创建一个),创建文件夹VOCxxxx(建议日期),比如VOC0809,在VOCxxxx下建立Annotations,ImageSets,JPEGImages以及labels文件夹,在ImageSets下建立Main文件夹
将xml文件放入Annotations中,图片放入JPEGImages中
3、将makeTxt.py放入VOCxxxx中并执行python makeTxt.py,将会在Main下生成train、val、test三个txt
附上makeTxt.py的代码:
import os
import random
trainval_percent = 0.85 #可自行进行调节
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
#ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
#ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
trainval和test加起来就是图片的数量,train+val=trainval,比例可以自行调节
4、data下创建xxxx.data和xxxx.names(xxxx就是刚刚创建VOCxxxx的xxxx)两个文件,参照voc.data和voc.names
下面是.data文件的样式

5、修改data下的voc_label.py: sets=[将’0809’换成’xxxx"],classes 换成自己的,最后两行同样换成xxxx,运行该文件
放上voc_lable.py的代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('0809', 'train'), ('0809', 'test'), ('0809', 'val')]
classes = […………………………]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id),'rb')
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
if cls =='melon_seeds':
print(str(cls_id))
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 0809_train.txt 0809_val.txt > train.txt")
os.system("cat 0809_train.txt 0809_val.txt 0809_test.txt > train.all.txt")
6、修改x64–>cfg下的yolov3.cfg文件,主要将每个yolo层的classes改成自己的类别数量,
每个yolo层上面的convolutional层理的filters改成3*(5+len(classes)),一共修改六处即可
如果要修改迭代次数学习率之类的,修改net下的东西


训练
进入x86文件夹下,命令行输入:
.\darknet.exe detector train .\data\0809.data .\cfg\yolov3_0809.cfg .\darknet53.conv.74
darknet53.conv.74是预训练模型,下载地址: https://pjreddie.com/media/files/darknet53.conv.74
训练的时候会出现这一堆东西:

以及这样的图片:
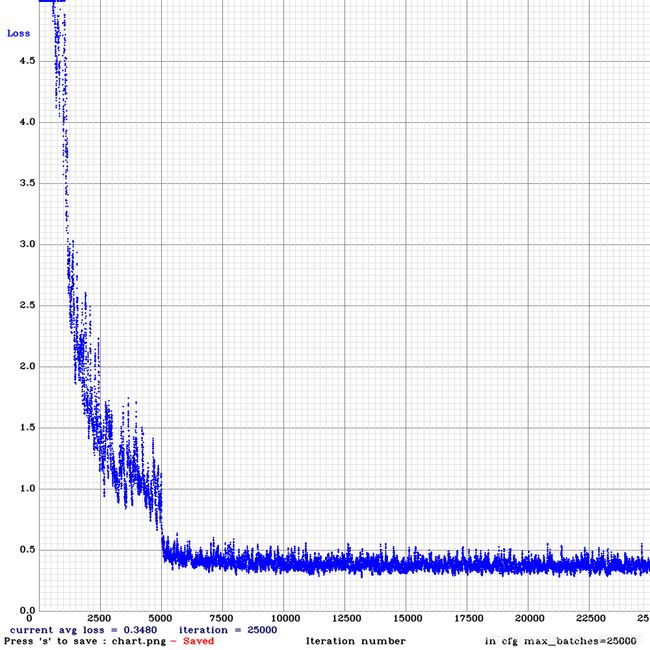
训练完后会在x64–>backup下生成权重文件(.weights)
测试
.\darknet.exe detect .\cfg\自己的.cfg .\训练生成的.weights .\data\dog.jpg