利用COCO API测试自己数据集训练的YOLOv3模型的mAP(VOC格式数据集)
目录
- 工具
- 前言
- 生成标注集的json文件
-
- 数据集准备
- 将voc注解格式数据集的注解转换成txt注解格式
- 自定义数据集的注解转换成coco的注解格式
- 生成结果集的json文件
-
- 安装darknet
- 获取自己模型的.weight文件(将.h5文件转换成.weight文件)
- 将图像以coco格式重命名
- 修改coco.data中的路径
- 修改yolov3.cfg文件
- 进行检测并生成json文件
- 测试mAP步骤
- 错误问题解决
- 参考博文及Github项目(十分感谢!)
工具
1.git:去git官网下载:https://git-scm.com/downloads/,下载自己需要的版本,下载完成后按照默认步骤安装即可
2.pycocotools:测试mAP时需要用到,参照https://blog.csdn.net/SyliaJason/article/details/103066638 进行安装(Win10系统)
3.Advanced Renamer:批量重命名工具——https://www.advancedrenamer.com/ ,批量更改数据集名称时可能会用到。
前言
对于不同数据集mAP值的计算方法不同,VOC2007提出了利用11个recall值来计算AP,而在2010之后使用了所有数据点来计算AP。COCO数据集采用的计算方式更加严格,它计算了不同IOU阈值和物体大小下的AP值,再取平均值。
本文参考了利用COCO API评估YOLOv3模型mAP的相关文章,这里总结了如何评估自己训练出的yolov3模型的mAP,其中自制数据集参考了VOC数据集的格式存放。
测试mAP需要两个json文件:cocoGt_file 和 cocoDt_file,一个是经过正确标注的标注集的json文件,一个是通过自己训练的YOLOv3模型进行检测而生成的结果集的json文件,这可以通过mAP的定义来理解。
下面我将分别介绍如何生成所需要的这两个json文件,进行mAP测试。
【文章默认已经准备好了带有xml标注的数据集,并且训练好了自己的yolo.h5模型】
生成标注集的json文件
数据集准备
我使用的是VOC格式的自制数据集,要生成COCO数据集需要的json文件,需要对数据集进行处理。

我这里需要使用的仅仅是测试集,所以只需要用到test.txt,该文件保存的是
测试集的图像名称。
将voc注解格式数据集的注解转换成txt注解格式
在自己的项目文件夹下新建1_voc2txt.py文件,输入如下代码。注意根据自己的实际情况更改数据集的路径,并且在VOCdevkit/VOC2007/Annotations文件夹下需要存放标注的.xml文件。
import os
import shutil
'''
将 dataset_dir 改为你的数据集的路径。
生成的txt注解文件格式为:
图片名 物体1左上角x坐标,物体1左上角y坐标,物体1右下角x坐标,物体1右下角y坐标,物体1类别id 物体2左上角x坐标,物体2左上角y坐标,物体2右下角x坐标,物体2右下角y坐标,物体2类别id ...
train_difficult控制是否训练难例。use_default_label控制是否使用默认的类别文件。
'''
# 是否训练难例。
train_difficult = True
# train_difficult = False
# 是否使用默认的类别文件。
use_default_label = True
# use_default_label = False
dataset_dir = 'VOCdevkit/VOC2007/'
train_path = dataset_dir + 'ImageSets/Main/train.txt'
val_path = dataset_dir + 'ImageSets/Main/val.txt'
test_path = dataset_dir + 'ImageSets/Main/test.txt'
#test_path = None
annos_dir = dataset_dir + 'Annotations/'
# 保存的txt注解文件的文件名
train_txt_name = 'voc2007_train.txt'
val_txt_name = 'voc2007_val.txt'
test_txt_name = 'voc2007_test.txt'
class_names = []
class_names_ids = {
}
cid_index = 0
if use_default_label:
# class_txt_name指向已有的类别文件,一行一个类别名。类别id根据这个类别文件中类别名在第几行确定。
# 如果只训练该数据集的部分类别,那么编辑该类别文件,只留下所需类别的类别名即可。
class_txt_name = 'model_data/voc_classes.txt'
if not os.path.exists(class_txt_name):
raise FileNotFoundError("%s does not exist!" % class_txt_name)
with open(class_txt_name, 'r', encoding='utf-8') as f:
for line in f:
cname = line.strip()
class_names.append(cname)
class_names_ids[cname] = cid_index
cid_index += 1
else: # 如果不使用默认的类别文件。则会分析出有几个类别,生成一个类别文件。
# 保存的类别文件名
class_txt_name = 'data/class_names.txt'
train_names = []
val_names = []
test_names = []
with open(train_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
train_names.append(line)
with open(val_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
val_names.append(line)
if test_path is not None:
with open(test_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
test_names.append(line)
# 创建txt注解目录
if os.path.exists('annotation/'): shutil.rmtree('annotation/')
os.mkdir('annotation/')
def write_txt(xml_names, annos_dir, txt_name, use_default_label, train_difficult, class_names, class_names_ids, cid_index):
content = ''
for xml_name in xml_names:
xml_file = '%s%s.xml'%(annos_dir, xml_name)
enter_gt = False
enter_part = False
x0, y0, x1, y1, cid = '', '', '', '', -10
difficult = 0
img_name = ''
bboxes = ''
with open(xml_file, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if '' in line:
if '' in line:
ss = line.split('name>')
sss = ss[1].split(')
img_name = sss[0]
else:
print('Error 1.')
if ' in line:
if '' in line:
print('Error 2.')
else:
enter_gt = True
if '' in line:
if cid > -5:
if train_difficult:
bboxes += ' %s,%s,%s,%s,%d'%(x0, y0, x1, y1, cid)
else:
if difficult == 0:
bboxes += ' %s,%s,%s,%s,%d'%(x0, y0, x1, y1, cid)
x0, y0, x1, y1, cid = '', '', '', '', -10
difficult = 0
enter_gt = False
enter_part = False
if enter_gt:
if '' in line: #
if '' in line:
print('Error part.')
else:
enter_part = True
if '' in line:
enter_part = False
if not enter_part:
if '' in line:
if '' in line:
ss = line.split('name>')
sss = ss[1].split(')
cname = sss[0]
if use_default_label:
if cname not in class_names:
cid = -10
else:
cid = class_names_ids[cname]
else:
if cname not in class_names:
class_names.append(cname)
class_names_ids[cname] = cid_index
cid_index += 1
cid = class_names_ids[cname]
else:
print('Error 3.')
if '' in line:
if '' in line:
ss = line.split('xmin>')
sss = ss[1].split(')
x0 = sss[0]
else:
print('Error 4.')
if '' in line:
if '' in line:
ss = line.split('ymin>')
sss = ss[1].split(')
y0 = sss[0]
else:
print('Error 5.')
if '' in line:
if '' in line:
ss = line.split('xmax>')
sss = ss[1].split(')
x1 = sss[0]
else:
print('Error 6.')
if '' in line:
if '' in line:
ss = line.split('ymax>')
sss = ss[1].split(')
y1 = sss[0]
else:
print('Error 7.')
if '' in line:
if '' in line:
ss = line.split('difficult>')
sss = ss[1].split(')
difficult = int(sss[0])
else:
print('Error 8.')
content += img_name + bboxes + '\n'
with open('annotation/%s' % txt_name, 'w', encoding='utf-8') as f:
f.write(content)
f.close()
return class_names, class_names_ids, cid_index
# train set
class_names, class_names_ids, cid_index = write_txt(train_names, annos_dir, train_txt_name,
use_default_label, train_difficult, class_names, class_names_ids, cid_index)
# val set
class_names, class_names_ids, cid_index = write_txt(val_names, annos_dir, val_txt_name,
use_default_label, train_difficult, class_names, class_names_ids, cid_index)
# test set
if test_path is not None:
class_names, class_names_ids, cid_index = write_txt(test_names, annos_dir, test_txt_name,
use_default_label, train_difficult, class_names, class_names_ids, cid_index)
if not use_default_label:
num_classes = len(class_names)
content = ''
for cid in range(num_classes):
for cname in class_names_ids.keys():
if cid == class_names_ids[cname]:
content += cname + '\n'
break
if not os.path.exists('data/'): os.mkdir('data/')
with open(class_txt_name, 'w', encoding='utf-8') as f:
f.write(content)
f.close()
print('Done.')
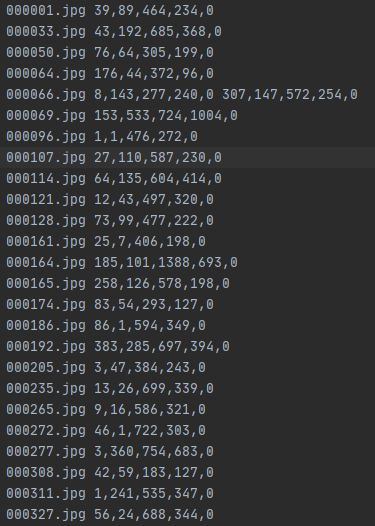
运行后生成一个annotation文件夹,保存txt注解格式,如下图。
自定义数据集的注解转换成coco的注解格式
同样新建一个1_txt2json.py文件,输入如下代码,这段代码参考了Github上的项目:https://github.com/miemie2013/Keras-YOLOv4,我在im_id处做了修改,以便于匹配训练生成的image_id的格式。
#! /usr/bin/env python
# coding=utf-8
# ================================================================
#
# Author : miemie2013
# Created date: 2020-05-20 15:35:27
# Description : Convert annotation files (txt format) into coco json format.
# 自定义数据集的注解转换成coco的注解格式。生成的json注解文件在annotation_json目录下。
#
# ================================================================
import os
import cv2
import json
import copy
import shutil
def get_classes(classes_path):
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def write_json(txt_path, img_path, base_json, anno_name, im_id, anno_id):
target_json = copy.deepcopy(base_json)
with open(txt_path) as f:
txt_lines = f.readlines()
images = []
annos = []
for line in txt_lines:
anno_list = line.split()
ndarr = cv2.imread(img_path + anno_list[0])
img_h, img_w, _ = ndarr.shape
im_id=int((((line.split())[0]).split("."))[0])
image = {
'license': 1,
'file_name': anno_list[0],
'coco_url': 'a',
'height': img_h,
'width': img_w,
'date_captured': 'a',
'flickr_url': 'a',
'id': im_id,
}
images.append(image)
for p in range(1, len(anno_list), 1):
bbox = anno_list[p].split(',')
x1 = float(bbox[0])
y1 = float(bbox[1])
x2 = float(bbox[2])
y2 = float(bbox[3])
cid = int(bbox[4])
w = x2 - x1
h = y2 - y1
anno = {
'segmentation': [[x2, y2, x2, y1, x1, y1, x1, y2, x2, y2]],
'area': w*h,
'iscrowd': 0,
'image_id': im_id,
'bbox': [x1, y1, w, h],
'category_id': cid,
'id': anno_id,
}
annos.append(anno)
anno_id += 1
#im_id += 1
target_json['annotations'] = annos
target_json['images'] = images
filename = anno_name[0] #这里我根据自己存放测试集的txt格式做了修改
if '/' in anno_name[0]:
filename = anno_name[0].split('/')[-1]
with open('annotation_json/%s.json' % filename, 'w') as f2:
json.dump(target_json, f2)
return im_id, anno_id
if __name__ == '__main__':
# 自定义数据集的注解转换成coco的注解格式。只需改下面7个即可。文件夹下的子目录(子文件)用/隔开,而不能用\或\\。
train_path = 'annotation/voc2007_train.txt'
val_path = 'annotation/voc2007_val.txt'
test_path = 'annotation/voc2007_test.txt' # 如果没有测试集,填None;如果有测试集,填txt注解文件的路径。
classes_path = 'model_data/voc_classes.txt'
train_pre_path = 'VOCdevkit/VOC2007/JPEGImages/' # 训练集图片相对路径
val_pre_path = 'VOCdevkit/VOC2007/JPEGImages/' # 验证集图片相对路径
test_pre_path = 'VOCdevkit/VOC2007/JPEGImages/' # 测试集图片相对路径
# 创建json注解目录
if os.path.exists('annotation_json/'): shutil.rmtree('annotation_json/')
os.mkdir('annotation_json/')
train_anno_name = train_path.split('.')
val_anno_name = val_path.split('.')
print('Convert annotation files (txt format) into coco json format...')
info = {
'description': 'My dataset',
'url': 'https://github.com/miemie2013',
'version': '1.0',
'year': '2020',
'contributor': 'miemie2013',
'date_created': '2020/06/01',
}
licenses_0 = {
'url': 'https://github.com/miemie2013',
'id': 1,
'name': 'miemie2013 license',
}
licenses = [licenses_0]
categories = []
class_names = get_classes(classes_path)
num_classes = len(class_names)
for cid in range(num_classes):
cate = {
'supercategory': 'object',
'id': cid,
'name': class_names[cid],
}
categories.append(cate)
base_json = {
'info': info,
'licenses': licenses,
'categories': categories,
}
im_id = 0
anno_id = 0
# train set
im_id, anno_id = write_json(train_path, train_pre_path, base_json, train_anno_name, im_id, anno_id)
# val set
im_id, anno_id = write_json(val_path, val_pre_path, base_json, val_anno_name, im_id, anno_id)
# test set
if test_path is not None:
test_anno_name = test_path.split('.')
im_id, anno_id = write_json(test_path, test_pre_path, base_json, test_anno_name, im_id, anno_id)
print('Done.')
运行后生成的json注解文件在项目文件夹的annotation_json目录下,格式如下。该文件就是标注集的json文件,记住它的路径。
![]()
生成结果集的json文件
安装darknet
在终端输入命令从github上clone源码,或者从该链接直接下载.zip文件。
git clone https://github.com/pjreddie/darknet.git
darknet文件格式如下:
想要用GPU进行检测的可以将darknet-master/Makefile文件中第一行的GPU=0改为GPU=1,我这里没有进行修改,进入到darknet文件中
cd darknet
编译(windows系统需要自行下载Cygwin,参考https://blog.csdn.net/chunleixiahe/article/details/55666792来安装,使得darknet可以编译)
make
编译结束后,会产生darknet.exe、libdarknet.a、libdarknet.so文件。将darknet.exe所在文件夹添加到环境变量当中去,即可使用darknet命令。
获取自己模型的.weight文件(将.h5文件转换成.weight文件)
通常情况下,我们训练好的YOLOv3模型都是.h5文件,而后续生成COCO数据集需要的json文件则需要用到.weight文件,所以需要进行转换。
这里参考文章https://blog.csdn.net/qinchang1/article/details/105776132,将自己训练好的.h5文件转换成.weight文件。(注意修改model_path为自己的.h5文件名称)
转换完会生成自己的.weight文件,复制到darknet-master/backup当中去。

![]()
将图像以coco格式重命名
作者在检测时发现按照原来的000001.jpg格式命名,在识别image_id时会出错,所以要更改命名方式,将自己需要测试的数据集批量重命名为COCO_VOC2007_000001.jpg这种格式。
创建一个convert.py将上面的VOC2007/ImageSets/Main/test.txt转换成保存图像路径的txt,注意根据自己的实际情况修改路径,运行该脚本会生成ntest.txt文件。
ftest = open('VOC2007/test.txt', 'r')
lines = ftest.readlines()
ftest.close()
ftest = open('VOC2007/test.txt', 'w')
for line in lines:
line_new="VOC2007/JPEGImages/COCO_VOC2007_"+line
ftest.write(line_new)
ff = open('VOC2007/ntest.txt','w') #打开一个文件,可写模式
with open('VOC2007/test.txt','r') as f: #打开一个文件只读模式
line = f.readlines()
for line_list in line:
line_new =line_list.replace('\n','')
line_new=line_new+r'.jpg'+'\n'
ff.write(line_new)
ntest.txt文件格式如下:
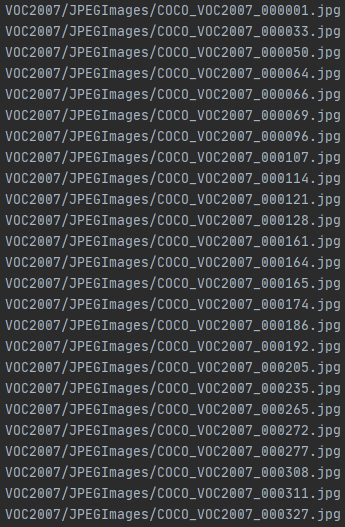
修改coco.data中的路径
打开darknet/cfg/coco.data,这里只需要用到valid,所以把valid的值改为保存图像路径的txt的路径。把classes改为你的数据集包含的物体类别数。

打开data/coco.names文件,将内容修改为自己模型的物体类别名称。
修改yolov3.cfg文件
打开darknet/cfg/yolov3.cfg文件,搜索yolo,一共搜索到三处,每一处都做如下修改:
1.filters =3*(5+classes) (注意这里要写计算出来的具体数字,例如classes是2,这里就改为21,否则后面会报错)
2.classes=2(你训练的模型的类别个数)
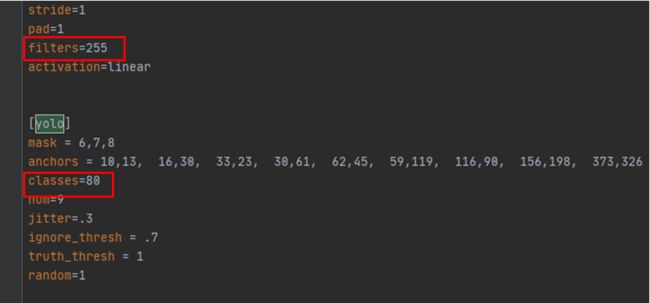
进行检测并生成json文件
在终端运行(作者尝试了在Win10系统运行,但内存始终报错,于是转到Linux系统):
./darknet detector valid cfg/coco.data cfg/yolov3.cfg backup/yolov3.weights
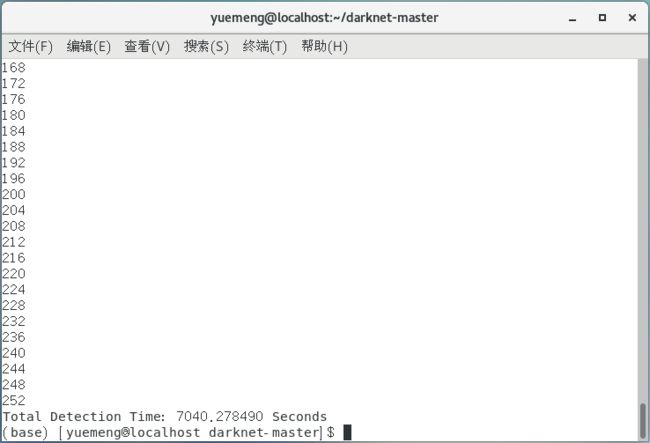
运行完成后结果保存在results/coco_results.json文件中,即结果集的json文件,将该文件复制到自己的项目文件夹下,并记住该路径。
测试mAP步骤
得到两个json文件后,在自己的项目文件夹下创建一个coco_compute_mAP.py文件,根据自己存放的路径对cocoGt_file和cocoDt_file进行修改。
#-*- coding:utf-8 -*-
import matplotlib.pyplot as plt
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
import numpy as np
import skimage.io as io
import pylab,json
pylab.rcParams['figure.figsize'] = (10.0, 8.0)
def get_img_id(file_name):
ls = []
myset = []
annos = json.load(open(file_name, 'r'))
for anno in annos:
ls.append(anno['image_id'])
myset = {
}.fromkeys(ls).keys()
return myset
if __name__ == '__main__':
annType = ['segm', 'bbox', 'keypoints']#set iouType to 'segm', 'bbox' or 'keypoints'
annType = annType[1] # specify type here
cocoGt_file = 'annotation_json/voc2007_test.json' #需要根据自己的实际情况配置该路径
cocoGt = COCO(cocoGt_file)#取得标注集中coco json对象
cocoDt_file = 'results/coco_results.json' #需要根据自己的实际情况配置该路径
imgIds = get_img_id(cocoDt_file)
print(len(imgIds))
cocoDt = cocoGt.loadRes(cocoDt_file)#取得结果集中image json对象
imgIds = sorted(imgIds)#按顺序排列coco标注集image_id
imgIds = imgIds[0:5000]#标注集中的image数据
cocoEval = COCOeval(cocoGt, cocoDt, annType)
cocoEval.params.imgIds = imgIds#参数设置
cocoEval.evaluate()#评价
cocoEval.accumulate()#积累
cocoEval.summarize()#总结
运行该脚本得到mAP的计算结果:
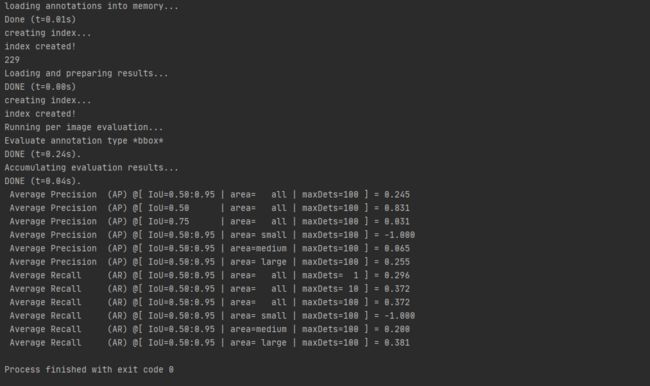
错误问题解决
1.【pycocotools报TypeError: object of type class numpy.float64 cannot be safely interpreted as an int】
https://blog.csdn.net/sinat_29957455/article/details/106481297
将507行和508行都做上述修改
2.【检测时报"cannot load image "./JPEGImages/000001.jpg
STB Reason: unknown image type images】
https://blog.csdn.net/weixin_30840573/article/details/94896855
图片打开出现错误,视情况将后缀改为.png / 将webp格式转换为.jpg格式
3.【检测时报:STB Reason: can‘t fopen】
https://blog.csdn.net/pursuit_zhangyu/article/details/107604731
【如有其他错误欢迎留言讨论,但是我也不一定会…◐▽◑】
参考博文及Github项目(十分感谢!)
1.COCOAPI评估Yolov3,计算mAP
https://blog.csdn.net/SongJ12345666/article/details/108452730
2.计算YOLOv3在COCO数据集上的mAP值
https://blog.csdn.net/huangxiang360729/article/details/105853200/
3.利用COCOAPI计算Yolov3训练出的模型的MAP值,复现ap
https://blog.csdn.net/xidaoliang/article/details/88397280
4.【YOLO】如何将Keras训练的模型用于OpenCV中(.h5文件转换成.weights文件)
https://blog.csdn.net/qinchang1/article/details/105776132
5.Github:Keras-YOLOv4
https://github.com/miemie2013/Keras-YOLOv4
6.目标检测模型的评估指标mAP详解(附代码)
https://zhuanlan.zhihu.com/p/37910324
作者第一次发布文章,在这个方面还属于小白,以上内容难免会有错误,欢迎在评论区指正(๑•̀ㅂ•́)و✧