Pandas学习-Task10
基础知识就结束啦!!!
习题完成的还不错,对于宽表长表转换现在使用比之前灵活了不少,这一次学习还是补充了很多很多知识的!再次夸夸课程和教程的设计者以及助教们~
综合题加油!
练习题1: 太阳辐射数据集
读取数据:
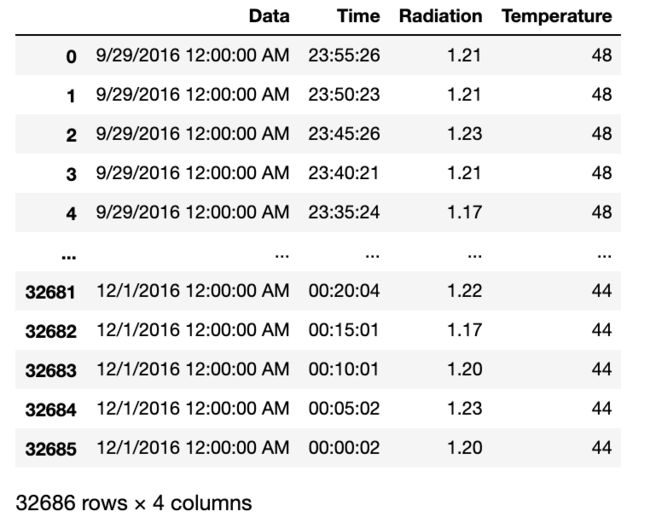
df = pd.read_csv('joyful-pandas-master/data/solar.csv', usecols=['Data','Time','Radiation','Temperature'])
df
1、将 Datetime, Time 合并为一个时间列 Datetime ,同时把它作为索引后排序。
- 使用
to_datetime方法来将多列合并转为时间序列:
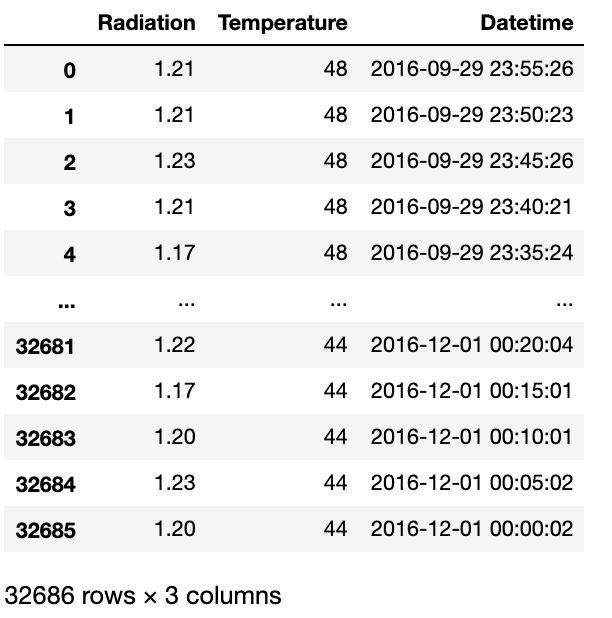
df['Datetime'] = pd.to_datetime(df.Data + df.Time)
df.drop(df[['Data','Time']],1,inplace=True)
df
- 使用
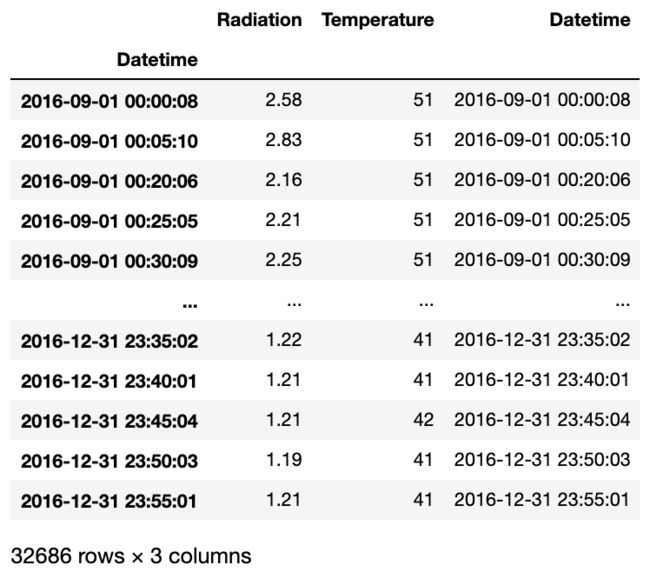
set_index()方法将Datetime这一列作为索引,再使用sort_index()对其进行排序。
df.set_index(df.Datetime).sort_index()
2、每条记录时间的间隔显然并不一致,请解决如下问题:
a. 找出间隔时间的前三个最大值所对应的三组时间戳。
【我的解答】:
- 将Datetime这列转为序列,然后对其使用
diff进行求差。 - 使用
abs()对差求绝对值之后,使用sort_values对其排序,降序排列。
time_diff = pd.Series(df.Datetime)
time_diff = time_diff.diff(1)
abs(time_diff).sort_values(ascending=False)

【参考答案】:
s = df.index.to_series().reset_index(drop=True).diff().dt.total_seconds()
max_3 = s.nlargest(3).index
df.index[max_3.union(max_3-1)]
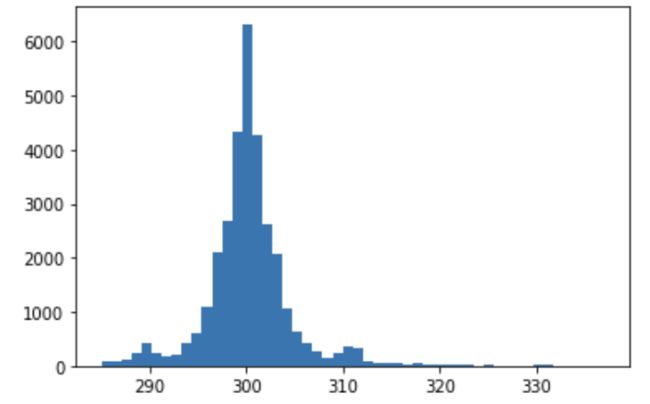
b. 是否存在一个大致的范围,使得绝大多数的间隔时间都落在这个区间中?如果存在,请对此范围内的样本间隔秒数画出柱状图,设置 bins=50 。
【参考答案】:
res = s.mask((s>s.quantile(0.99))|(s<s.quantile(0.01)))
_ = plt.hist(res, bins=50)
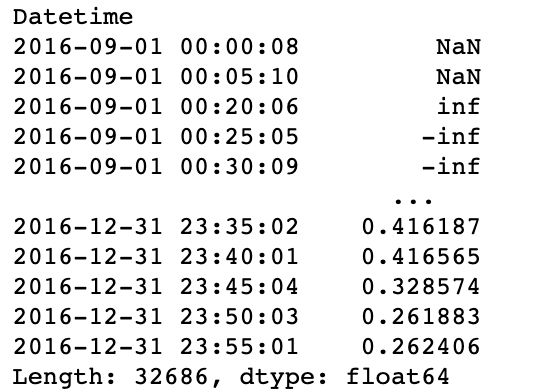
3、求如下指标对应的 Series :
a. 温度与辐射量的6小时滑动相关系数
res = df.Radiation.rolling('6H').corr(df.Temperature)
res
b. 以三点、九点、十五点、二十一点为分割,该观测所在时间区间的温度均值序列
slide = df.Temperature.resample('6H', origin='03:00:00').mean()
slide

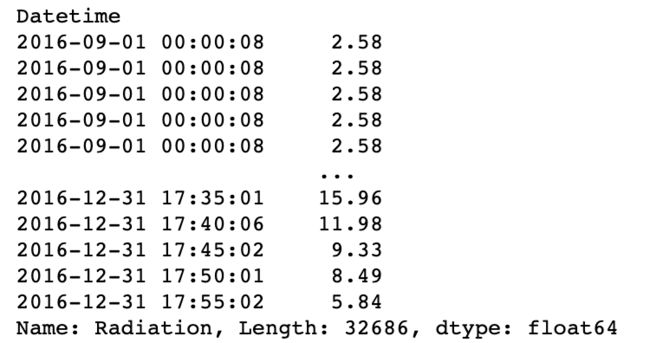
c. 每个观测6小时前的辐射量(一般而言不会恰好取到,此时取最近时间戳对应的辐射量)
【参考答案】:
my_dt = df.index.shift(freq='-6H')
my_dt
int_loc = [df.index.get_loc(i, method='nearest') for i in my_dt]
res = df.Radiation.iloc[int_loc]
res
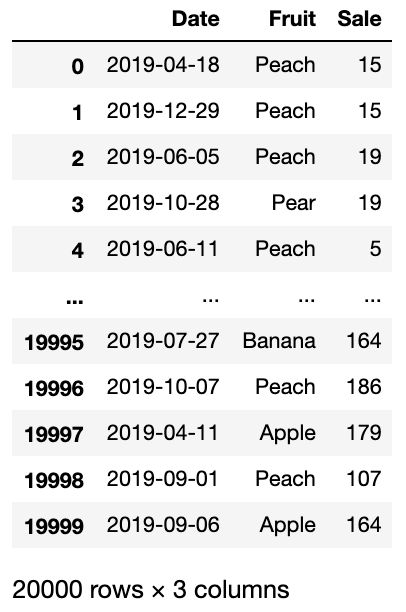
练习题2: 水果销量数据集
查看数据:
df = pd.read_csv('joyful-pandas-master/data/fruit.csv')
1、统计如下指标:
(a)每月上半月(15号及之前)与下半月葡萄销量的比值
- 将Date这一列转化为时间序列
df.Date = pd.to_datetime(df.Date)
df.Date

- 查看水果的种类
df.Fruit.unique()
输出:array(['Peach', 'Pear', 'Grape', 'Banana', 'Apple'], dtype=object)
- 查询葡萄这一种类
df_grape = df.query("Fruit == 'Grape'")
- 以日期、月份来作为分组的标准,求销售的均值。
- 将结果存为DateFrame表,然后使用
unstack将数据的行“旋转”为列 - 再将外层的索引
sale删除 - 求上半个月与下半个月的比值
res = df_grape.groupby([np.where(df_grape.Date.dt.day<=15, 'First', 'Second'), df_grape.Date.dt.month]
)['Sale'].mean().to_frame().unstack(0).droplevel(0,axis=1)
res
res = (res.First/res.Second).rename_axis('Month')
res
(b)每月最后一天的生梨销量总和
- 查询出梨子的行
- 选出梨子中每个月最后一天的行
- 根据月份进行分组,再对销量求和
df_pear = df.query("Fruit == 'Pear'")
df_pear = df_pear[df_pear.Date.dt.is_month_end]
df_pear
df_pear.groupby(df_pear.Date.dt.month)['Sale'].sum()
(c)每月最后一天工作日的生梨销量总和
pd.date_range('20190101', '20191231',freq='BM')取出每个月最后一天工作日
df_pear = df.query("Fruit == 'Pear'")
df_pear_work = df_pear[df_pear.Date.isin(pd.date_range('20190101', '20191231',freq='BM'))]
df_pear_work.groupby(df_pear_work.Date.dt.month)['Sale'].sum()
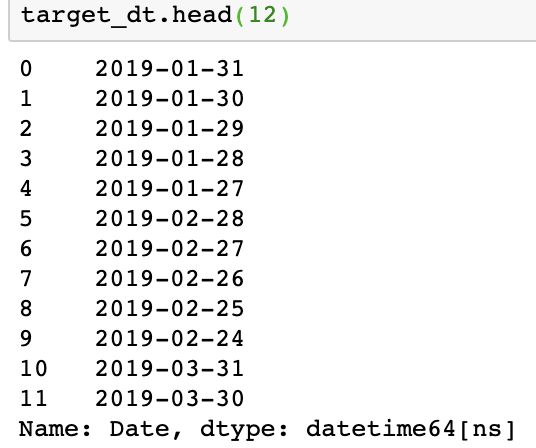
(d)每月最后五天的苹果销量均值。
【参考答案】:
target_dt = df.drop_duplicates().groupby(df.Date.drop_duplicates().dt.month)['Date'].nlargest(5).reset_index(drop=True)
target_dt
res = df.set_index('Date').loc[target_dt].reset_index().query("Fruit == 'Apple'")
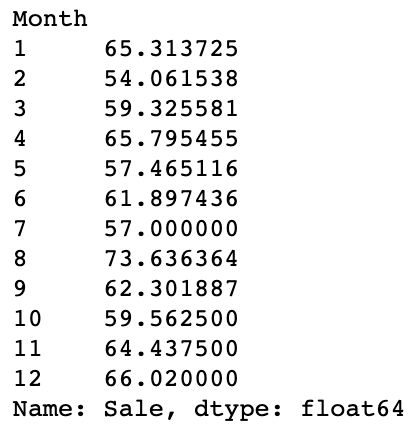
res = res.groupby(res.Date.dt.month)['Sale'].mean().rename_axis('Month')
res
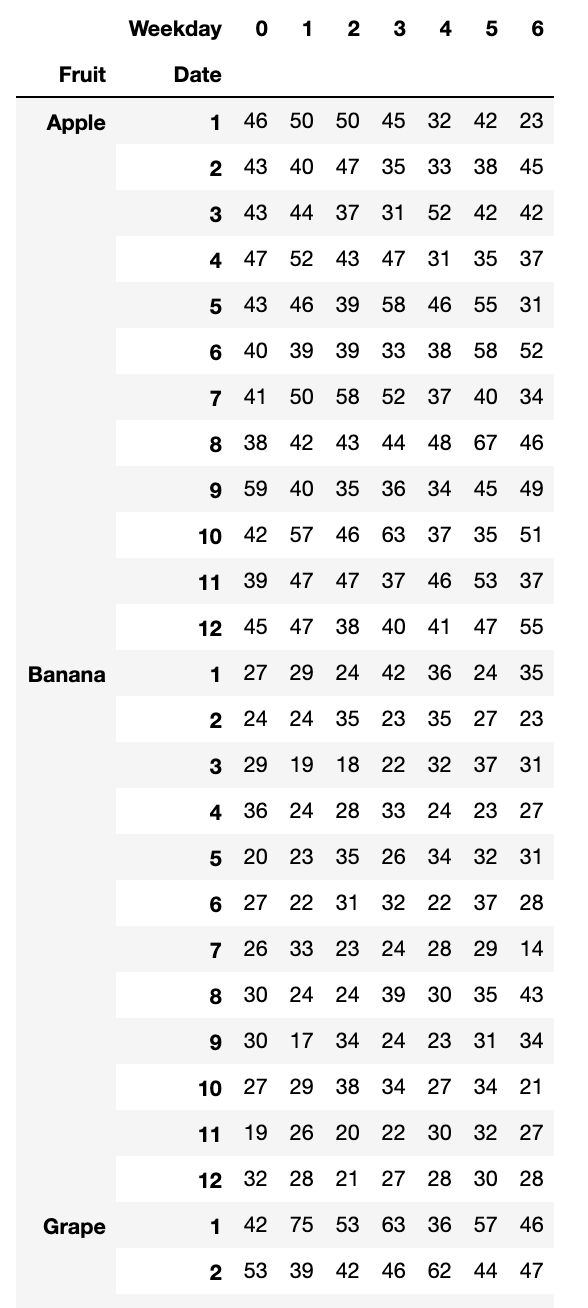
2、按月计算周一至周日各品种水果的平均记录条数,行索引外层为水果名称,内层为月份,列索引为星期。
【我的思考】:
使用df['Weekday'] = df.Date.dt.dayofweek在列表中添加一列,代表星期几,然后再使用长表变宽表,将其作为列索引。嘻嘻嘻与参考答案方法不一致,但做出来啦,感觉这样也很简单~
- 将每一天的星期几对应上,并作为单独一列。
- 按照水果名称、月份、星期几分组,求出每一种水果每月的星期几的总记录数,并转为DataFrame表,重置索引。
- 长表变宽表,将星期几作为列索引。
df['Weekday'] = df.Date.dt.dayofweek
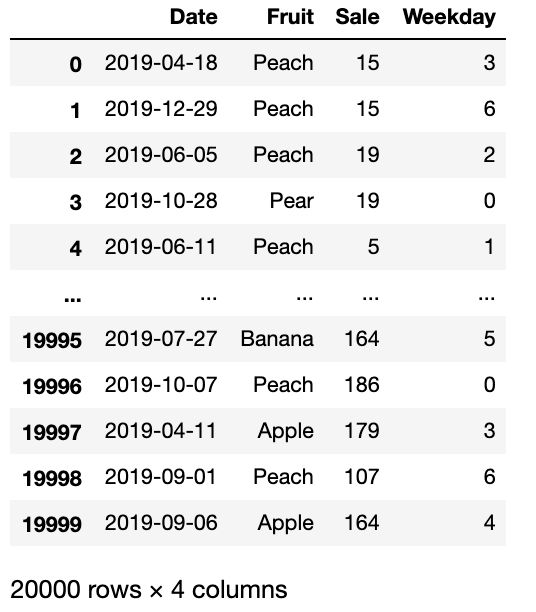
a = df.groupby(['Fruit', df.Date.dt.month, 'Weekday'])['Sale'].count().to_frame().reset_index()
a

a.pivot(index=['Fruit','Date'],columns='Weekday',values='Sale')
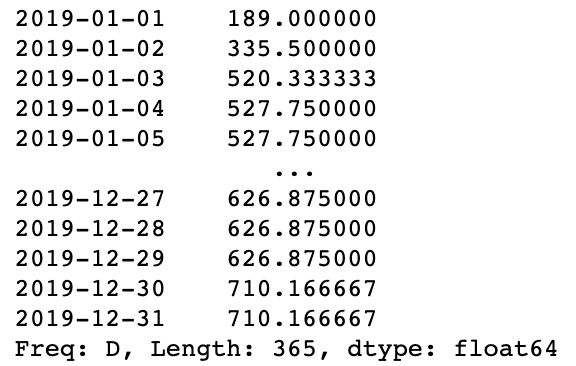
3、按天计算向前10个工作日窗口的苹果销量均值序列,非工作日的值用上一个工作日的结果填充。
这题题目暂时没太读懂。。。
【参考答案】:
df_apple = df[(df.Fruit=='Apple')&(~df.Date.dt.dayofweek.isin([5,6]))]
s = pd.Series(df_apple.Sale.values, index=df_apple.Date).groupby('Date').sum()
res = s.rolling('10D').mean().reindex(pd.date_range('20190101','20191231')).fillna(method='ffill')
res