基于机器学习的2022卡塔尔世界杯冠军预测-个人期末项目总结
声明:文中内容基于山东某高校数据挖掘课程的学习成果,本系列文章为课程期末项目的个人总结。
该项目所属数据挖掘类型:分类预测问题。
通过对2018年之前世界杯各个国家球队的表现以及比分结果进行数据分析,并结合以往各个球队在历届世界杯中的表现,通过机器学习算法建立模型,并对其进行评价以及模型优化之后,进行模拟2022年卡塔尔世界杯的冠军球队的归属。
开发工具:Pycharm
Python版本:3.7.0
(一)数据采集
首先从Kaggle网站上找到合适的历年世界杯的比赛结果数据集。
网址:https://www.kaggle.com/abecklas/fifa-world-cup
该数据存在诸多多余的属性:如比赛年份,比赛场地等。我们首先去掉无关的属性,只留下:主队、客队、主队进球数、客队进球数,比赛结果。其中结果集分为1为主队获胜,2为客队获胜,-1为平局。

(注:以上为部分数据此处为了方便展示,加上了日期,并且将CSV文档中国家名翻译成了中文。该文件名:fifa_ch.csv)
此时,我们发现仅有主场客场比分并不能很好地分析每个队的实力,所以我们要进行数据统计,找出新的特征值来扩充数据集。
数据扩充
首先我们计算每个国家的参赛次数
# 导入相关的库
import pandas as pd
import csv
# fifa_ch.csv为最初的把多余属性去掉,然后把国家名翻译成了中文的kaggle下载的文件
df = pd.read_csv('fifa_ch.csv',encoding="utf_8_sig")
date = df["date"]
home_team = df["home_team"]
away_team = df["away_team"]
home_score = df["home_score"]
away_score = df["away_score"]
result_n = df["result_n"]
#创建个数据字典
# 各个国家
country = home_team.append(away_team)
allcountry = {
}
for i in country:
if i not in allcountry:
allcountry[i]=0
# 各个国家参加比赛的次数
times = allcountry.copy()
for i in range(900):
times[home_team[i]] +=1
times[away_team[i]] +=1
# 各个国家胜利的次数
win=allcountry.copy()
for i in range(900):
if result_n[i] == 0:
win[away_team[i]] += 1
if result_n[i] == 1:
win[home_team[i]] += 1
# 总进球数
goals = allcountry.copy()
for i in range(900):
goals[home_team[i]] += home_score[i]
goals[away_team[i]] += away_score[i]
# 各个球队胜率,并新建文档data.csv存放数据
# 新建属性为 国家名称、世界杯参赛次数、胜利次数、进球数、胜率、场均进球数
csvFile = open('data.csv','w', newline='')
writer = csv.writer(csvFile)
writer.writerow(["country","times","win","goals","rate of winning","Average goal"])
for key in allcountry:
writer.writerow([key,times[key],win[key],goals[key],win[key]/times[key],goals[key]/times[key]])
csvFile.close()
# 上述代码执行完毕后,执行如下代码。将数据合并至新的csv中(tr_data_after.csv)
df = pd.read_csv('data.csv',encoding="utf_8_sig")
country = df["country"]
data_times = df["times"]
data_win = df["win"]
data_goals = df["goals"]
r_of_winning = df["rate of winning"]
Average_goal = df["Average goal"]
csvFile2 = open('tr_data_after.csv','w', newline='',encoding="utf_8_sig")
writer2 = csv.writer(csvFile2)
writer2.writerow(["home_team","away_team","home_times","away_times","home_win","away_win","home_goals","away_goals","home_r_win","away_r_win","home_Ave_goal","away_Ave_goal","result"])
for i in range(900):
for j in range(82):
if(home_team[i]==country[j]):
for k in range(82):
if (away_team[i] == country[k]):
writer2.writerow([home_team[i],away_team[i],data_times[j],data_times[k],data_win[j],data_win[k],data_goals[j],data_goals[k],r_of_winning[j],r_of_winning[k],Average_goal[j],Average_goal[k],result_n[i]])
csvFile2.close()
合并后生成的tr_data_after.csv中内容为:主队、客队、主队参赛次数、客队参赛次数、主队胜利次数、客队胜利次数、主队进球数、客队进球数、主队胜率、客队胜率、主队场均进球、客队场均进球、比赛结果。

此处统计数据共有900行,即纾解杯中所有比赛场次,特种扩充到了15列
方便展示可以使用Echart将统计到的各个国家的信息进行简单的数据可视化

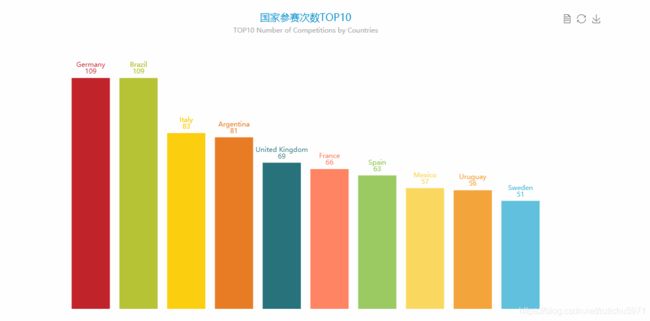
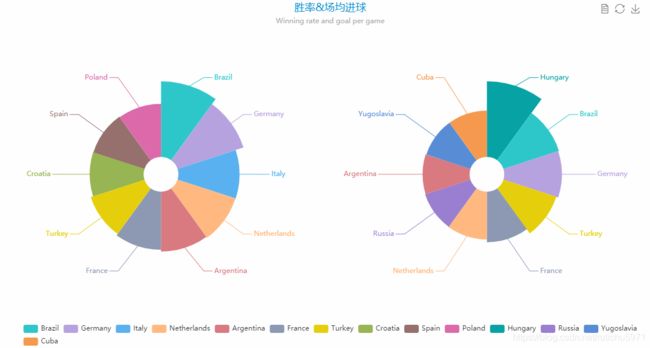
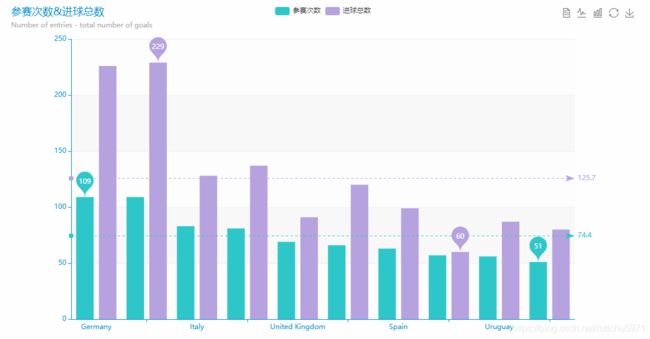
(二)数据预处理。
# 此处所引入的包大部分为下文机器学习算法
import pandas as pd
from numpy import *
import numpy as np
from sklearn.neural_network import MLPClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import learning_curve
from sklearn.metrics import accuracy_score,recall_score,f1_score
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
from sklearn import svm
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.utils.np_utils import to_categorical
from random import sample
from sklearn.model_selection import ShuffleSplit
# import warnings
# warnings.filterwarnings("ignore")
# 把tr_data_after.csv读入
df = pd.read_csv('tr_data_after.csv',encoding="utf_8_sig")
home_team = df["home_team"]
away_team = df["away_team"]
home_times = df["home_times"]
away_times = df["away_times"]
home_win = df["home_win"]
away_win = df["away_win"]
home_goals = df["home_goals"]
away_goals = df["away_goals"]
home_r_win = df["home_r_win"]
away_r_win = df["away_r_win"]
home_Ave_goal = df["home_Ave_goal"]
away_Ave_goal = df["away_Ave_goal"]
result = df["result"]
team_merge = pd.concat([home_team,away_team,home_times,away_times,home_win,away_win,home_goals,away_goals,home_r_win,away_r_win,home_Ave_goal,away_Ave_goal,result], axis=1).drop(['home_team','away_team'],axis=1)
#以下使用了两种预处理方式,任选其一即可
# Min-Max处理(除了主客队名称和结果集以外数据)
play_score_temp = team_merge.iloc[:, :-1]
# play_score_normal = (play_score_temp - play_score_temp.min()) / (play_score_temp.max() - play_score_temp.min())
# 标准分数处理(除了主客队名称和结果集以外数据)
play_score_normal = (play_score_temp - play_score_temp.mean()) / (play_score_temp.std())
play_score_normal = pd.concat([play_score_normal, team_merge.iloc[:, -1]], axis=1)
# print(play_score_normal)
其中标准分数(z-score)是一个分数与平均数的差再除以标准差的过程。
用公式表示为:z=(x-μ)/σ。
其中x为某一具体分数,μ为平均数,σ为标准差。
# 获取csv数据的长度(条数)
with open('tr_data_after.csv', 'r',encoding="utf_8_sig") as f:
line=len(f.readlines())
# 70%的数据作为训练集
tr_index=sample(range(0,line-1),int(line*0.7))
te_index=[i for i in range(0,line-1) if i not in tr_index]
tr_x = play_score_normal.iloc[tr_index, :-1] # 训练特征
tr_y = play_score_normal.iloc[tr_index, -1] # 训练目标
te_x = play_score_normal.iloc[te_index, :-1] # 测试特征
te_y = play_score_normal.iloc[te_index, -1] # 测试目标
df2 = pd.read_csv('data.csv',encoding="utf_8_sig")
country = df2["country"]
times = df2["times"]
win = df2["win"]
goals = df2["goals"]
rate = df2["rate of winning"]
Average = df2["Average goal"]
frames=[country,times,win,goals,rate,Average]
country_all = pd.concat(frames, axis=1).dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
num_data = country_all.iloc[:,[1,2,3,4,5]]
# 测试集Min-Max处理
# country_all_MM = (num_data - num_data.min()) / (num_data.max() - num_data.min())
# 测试集标准分数标准化
country_all_MM = (num_data - num_data.mean()) / (num_data.std())
country_all_MM = pd.concat([country, country_all_MM], axis=1)
# country_all_MM.to_csv("tr_data_z.csv",encoding="utf_8_sig")
play_score_normal.reset_index(drop = True)
play_score_normal.to_csv("play_score_normal.csv",encoding="utf_8_sig")
预处理后的数据存放至play_score_normal.csv中:

(三)机器学习
model=MLPClassifier(hidden_layer_sizes=10,max_iter=1000).fit(tr_x,tr_y)
print("神经网络:")
print("训练集准确度:{:.3f}".format(model.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(model.score(te_x,te_y)))
y_pred = model.predict(te_x)
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
# 准确率,召回率,F-score评价
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
print("逻辑回归:")
logreg = LogisticRegression(C=1,solver='liblinear',multi_class ='auto')
logreg.fit(tr_x, tr_y)
score = logreg.score(tr_x, tr_y)
score2 = logreg.score(te_x, te_y)
print("训练集准确度:{:.3f}".format(logreg.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(logreg.score(te_x,te_y)))
y_pred = logreg.predict(te_x)
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
print("决策树:")
tree=DecisionTreeClassifier(max_depth=50,random_state=0)
tree.fit(tr_x,tr_y)
y_pred = tree.predict(te_x)
print("训练集准确度:{:.3f}".format(tree.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(tree.score(te_x,te_y)))
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
print("随机森林:")
rf=RandomForestClassifier(max_depth=20,n_estimators=1000,random_state=0)
rf.fit(tr_x,tr_y)
print("训练集准确度:{:.3f}".format(rf.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(rf.score(te_x,te_y)))
y_pred = rf.predict(te_x)
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
print("SVM支持向量机:")
clf = svm.SVC(C=0.1, kernel='linear', decision_function_shape='ovr')
clf.fit(tr_x, tr_y.ravel())
y_pred = clf.predict(te_x)
print("训练集准确度:{:.3f}".format(clf.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(clf.score(te_x,te_y)))
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
此处使用了神经网络、逻辑回归、支持向量机、决策树、随机森林算法分别进行训练。
并输出其在训练集上的准确度、在测试集上的准确度以及平均绝对误差。
此时发现结果并不理想。准确度仅为六成左右
(四)误差原因分析:
(尝试方法一)分别输出以上机器学习算法的学习曲线:
# 学习曲线函数
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("game num")
plt.ylabel("score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
cv = ShuffleSplit(n_splits=line, test_size=0.2, random_state=0)
plot_learning_curve(logreg, "logreg", tr_x, tr_y, ylim=None, cv=cv, n_jobs=1)
plot_learning_curve(tree, "tree", tr_x, tr_y, ylim=None, cv=None, n_jobs=1)
plot_learning_curve(rf, "rf", tr_x, tr_y, ylim=None, cv=None, n_jobs=1)
plot_learning_curve(model, "model", tr_x, tr_y, ylim=None, cv=None, n_jobs=1)
plot_learning_curve(clf, "clf", tr_x, tr_y, ylim=None, cv=None, n_jobs=1)
结果如下:
逻辑回归学习曲线:

神经网络学习曲线:

支持向量机学习曲线:

结果图上可以看出,随着数据量的增加,三组模型虽然趋近于收敛,但是在训练集和检验集上准确度表现都很差,仅有0.58左右。这预示着存在着很高的偏差,是欠拟合的表现。
决策树学习曲线:

随机森林学习曲线:
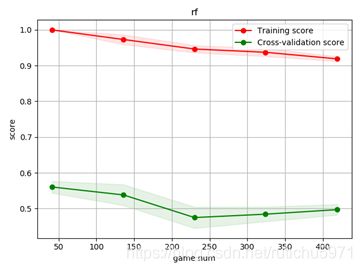
决策树和随机森林出现了高方差情形,也就是过拟合的情况。这都预示着我们要找到正确率低原因,并且优化我们的模型。
(尝试方法二)输出灰色关联矩阵:
def GRA_ONE(DataFrame,m=-1):
gray= DataFrame
# 读取为df格式
gray=(gray - gray.min()) / (gray.max() - gray.min())
# 标准化
std = gray.iloc[:, m] # 为标准要素
ce = gray.iloc[:, 0:] # 为比较要素
n=ce.shape[0]
m=ce.shape[1]# 计算行列
# 与标准要素比较,相减
a=zeros([m,n])
for i in range(m):
for j in range(n):
a[i,j]=abs(ce.iloc[j,i]-std[j])
# 取出矩阵中最大值与最小值
c=amax(a)
d=amin(a)
# 计算值
result=zeros([m,n])
for i in range(m):
for j in range(n):
result[i,j]=(d+0.5*c)/(a[i,j]+0.5*c)
# 求均值,得到灰色关联值
result2=zeros(m)
for i in range(m):
result2[i]=mean(result[i,:])
RT=pd.DataFrame(result2)
return RT
def GRA(DataFrame):
list_columns = [str(s) for s in range(len(DataFrame.columns)) if s not in [None]]
df_local = pd.DataFrame(columns=['home_times','away_times','home_win','away_win','home_goals','away_goals','home_r_win','away_r_win','home_Ave_goal','away_Ave_goal'])
for i in range(len(DataFrame.columns)):
df_local.iloc[:,i] = GRA_ONE(DataFrame,m=i)[0]
return df_local
play_score = GRA(team_merge.drop(columns=['result']))
输出结果如下:
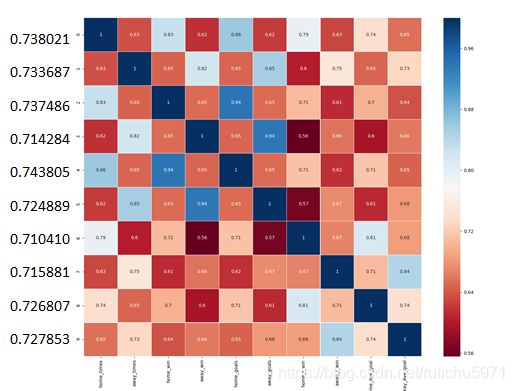
统计出每个特征关联度的均值后,我们发现大部分的特征关联度都在0.738021~0.710410之间,也就是说大部分特征都与结果呈现出了相对较高的关联性。
这也意味着已有的数据源的特征关联度对之前模型的影响是有限的。
(尝试方法三)以上两种方法进一步缩小了误差原因,于是重新分析测试集与预测结果如图:
测试集:蓝色的*
预测结果:红色的o
发现在预测平局方面,算法预测结果有着较大的误差。于是我们推测由于结果集中的平局拉低了模型的准确度。

进一步查询有关资料发现,我们所使用的决策树算法,随机森林算法,还有逻辑回归,都典型二分类的算法。而此时我们的结果集有三类。
我们重新检查数据源,发现平局的情况仅有199条,而仅凭借着这些较少数据量去很好的训练数据是不合适的。 于是我们开始探讨简化结果集即去掉平局结果的可行性。
在充分了解世界杯的规则后,从16强开始,就意味着告别了小组赛,开始了淘汰赛。如遇到平局,就开始加时赛以及点球大战。即比赛结果只有胜负两种结果。而数据集中的比赛结果是将点球大战排除在外的90分钟内的比赛结果。 所以含有平局的情况。
(五)模型改良
将play_score_normal.csv中所有的结果集为-1(即平局的数据去掉)
重新采用上述机器学习算法进行训练学习。
训练结果如下:
神经网络:
训练集准确度:0.570
测试集准确度:0.570
平均绝对误差: 0.5740740740740741
逻辑回归:
训练集准确度:0.554
测试集准确度:0.622
平均绝对误差: 0.5296296296296297
决策树:
训练集准确度:0.894
测试集准确度:0.407
平均绝对误差: 0.8074074074074075
随机森林:
训练集准确度:0.894
测试集准确度:0.485
平均绝对误差: 0.7111111111111111
SVM支持向量机:
训练集准确度:0.592
测试集准确度:0.530
平均绝对误差: 0.6222222222222222
由上可见,准确度有了略微的提升,但这还不是我们想要达到的准确度。 于是我们继续研究,并尝试使用深度学习算法继续提升模型的准确度。
深度神经网络
于是我们使用了Sequential模型,它是多个网络层的线性堆叠,通过堆叠许多层,构建出深度神经网络。
model_k = Sequential()
model_k.add(Dense(output_dim=500, input_dim=10, activation='relu'))
model_k.add(Dense(output_dim=500, input_dim=200, activation='relu'))
model_k.add(Dense(units=2, activation='softmax'))
# 为了保证数据一致性,将目标类转化为独热编码,同时我们想要计算交叉熵损失函数,Adam算法作为优化算法,然后把准确率当做衡量这个算法的指标
y = to_categorical(tr_y, 2)
model_k.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
# 以200个样本为一批进行迭代
model_k.fit(np.asarray(tr_x), y, epochs=200, batch_size=200)
result = model_k.evaluate(np.asarray(tr_x), y)
y_pred = model_k.predict_classes(np.asarray(te_x))
print(result[1])
运行结果如图:
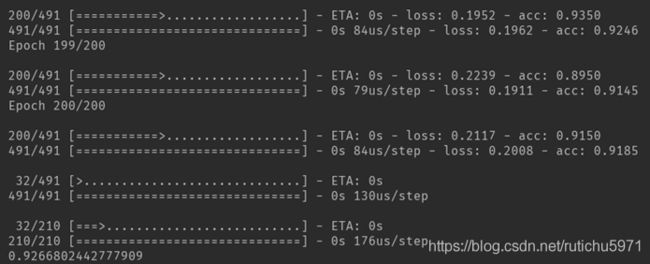
正确率已经能够到达92%。但需要进一步的调参,找到更合适的参数,防止过拟合。
接下来我们暂时用此模型,对世界杯的结果进行模拟预测。
(六)冠军预测:
对于2022年的16强队的选择,考虑到近几年球队的数据更能反映出该球队的状态,于是我们统计了近几年(2002-2018)年共5次世界杯进入16强次数最多的队伍。
从16支队伍里面随机选中8支队伍,分为两队:
# 16强
#
df = pd.read_csv('NO16.csv',encoding="utf_8_sig")
country = df['country']
g1_index=sample(range(0,16),8)
group1=pd.Series(country[g1_index]).reset_index(drop = True)
g2_index=[i for i in range(0,16) if i not in g1_index]
group2=pd.Series(country[g2_index])
从数据集里面找到这16支队伍相对应的数据:
csvFile = open('16res.csv', 'w', newline='',encoding="utf_8_sig")
writer = csv.writer(csvFile)
writer.writerow(["times","team1","team2","win"])
print("\n16进8")
for i in range(0,8):
print("组1:第",i+1,"队")
team1 = country_all_MM.loc[
country_all['country'] == group1.iloc[i]]
print(group1.iloc[i])
print("组2:第",i+1,"队")
team2 = country_all_MM.loc[
country_all['country'] == group2.iloc[i]]
print(group2.iloc[i])
比赛的两支队伍的数据进行合并用作待预测数据,并使用深度学习算法进行预测:
vs = pd.concat([team1.reset_index(),
team2.reset_index()],
axis=1).drop(['index', 'country'], axis=1)
result=model_k.predict_classes(np.asarray(vs))
将每次的比赛结果输出到Excel表中:
if(result==1):
temp = group1.iloc[i]
if(result==0):
temp = group2.iloc[i]
print("获胜方:", temp)
writer.writerow([i,group1.iloc[i],group2.iloc[i],temp])
csvFile.close()
以此类推,8强、4强到最后的决赛
# 8强
df = pd.read_csv('16res.csv',encoding="utf_8_sig")
win = df['win']
g1_index=[i for i in range(0,4)]
group1=pd.Series(win[g1_index]).reset_index(drop = True)
g2_index=[j for j in range(4,8)]
group2=pd.Series(win[g2_index]).reset_index(drop = True)
csvFile = open('8res.csv', 'w', newline='',encoding="utf_8_sig")
writer = csv.writer(csvFile)
writer.writerow(["times","team1","team2","win"])
print("\n8进4")
for i in range(0,4):
print("组1:第",i+1,"队")
team1 = country_all_MM.loc[country_all['country'] == group1.iloc[i]]
print(group1.iloc[i])
print("组2:第",i+1,"队")
team2 = country_all_MM.loc[country_all['country'] == group2.iloc[i]]
print(group2.iloc[i])
print("比赛结果")
vs = pd.concat([team1.reset_index(), team2.reset_index()], axis=1).drop(['index', 'country'], axis=1)
result=model_k.predict_classes(np.asarray(vs))
if (result == 1):
temp = group1.iloc[i]
if (result == 0):
temp = group2.iloc[i]
print("获胜方:", temp)
writer.writerow([i, group1.iloc[i], group2.iloc[i], temp])
csvFile.close()
# 4强
df = pd.read_csv('8res.csv',encoding="utf_8_sig")
win = df['win']
g1_index=[i for i in range(0,2)]
group1=pd.Series(win[g1_index]).reset_index(drop = True)
g2_index=[j for j in range(2,4)]
group2=pd.Series(win[g2_index]).reset_index(drop = True)
csvFile = open('4res.csv', 'w', newline='',encoding="utf_8_sig")
writer = csv.writer(csvFile)
writer.writerow(["times","team1","team2","win"])
print("\n4进2")
for i in range(0,2):
print("组1:第",i+1,"队")
team1 = country_all_MM.loc[country_all['country'] == group1.iloc[i]]
print(group1.iloc[i])
print("组2:第",i+1,"队")
team2 = country_all_MM.loc[country_all['country'] == group2.iloc[i]]
print(group2.iloc[i])
print("比赛结果")
vs = pd.concat([team1.reset_index(), team2.reset_index()], axis=1).drop(['index', 'country'], axis=1)
result=model_k.predict_classes(np.asarray(vs))
if (result == 1):
temp = group1.iloc[i]
if (result == 0):
temp = group2.iloc[i]
print("获胜方:", temp)
writer.writerow([i, group1.iloc[i], group2.iloc[i], temp])
csvFile.close()
#决赛
df = pd.read_csv('4res.csv',encoding="utf_8_sig")
win = df['win']
g1_index=[i for i in range(0,1)]
group1=pd.Series(win[g1_index]).reset_index(drop = True)
g2_index=[j for j in range(1,2)]
group2=pd.Series(win[g2_index]).reset_index(drop = True)
csvFile = open('2res.csv', 'w', newline='',encoding="utf_8_sig")
writer = csv.writer(csvFile)
writer.writerow(["times","team1","team2","win"])
print("\n决赛")
for i in range(0,1):
print("组1:第",i+1,"队")
team1 = country_all_MM.loc[country_all['country'] == group1.iloc[i]]
print(group1.iloc[i])
print("组2:第",i+1,"队")
team2 = country_all_MM.loc[country_all['country'] == group2.iloc[i]]
print(group2.iloc[i])
print("比赛结果")
vs = pd.concat([team1.reset_index(), team2.reset_index()], axis=1).drop(['index', 'country'], axis=1)
result=model_k.predict_classes(np.asarray(vs))
if (result == 1):
temp = group1.iloc[i]
if (result == 0):
temp = group2.iloc[i]
print("获胜方:", temp)
writer.writerow([i, group1.iloc[i], group2.iloc[i], temp])
csvFile.close()
运行结果:

以上预测结果仅为参考,原因如下:
1、数据量较少。
2、小组赛是由抽签结果确定的,而且分为了各个地区(如亚洲区、欧州区),抽签的结果无法预测,即每个队伍有特定地区的对手,且是由抽签决定的。
3、本预测结果16强队均为历史上进入16强次数最多的队伍,且比赛时为两两随机比赛,而真正进入世界杯16强队伍中会有很多“黑马”杀入,并且有很多洲际规则需要考虑。
若要真正预测结果,则需等待小组分组结果后,决出16强或32强。这样会比较然后将其球队数据代入,最终决出冠军。
以下为整合代码
数据扩充代码
import pandas as pd
import csv
df = pd.read_csv('fifa_ch.csv',encoding="utf_8_sig")
date = df["date"]
home_team = df["home_team"]
away_team = df["away_team"]
home_score = df["home_score"]
away_score = df["away_score"]
result_n = df["result_n"]
# 各个国家
country = home_team.append(away_team)
allcountry = {
}
for i in country:
if i not in allcountry:
allcountry[i]=0
# 各个国家参加比赛的次数
times = allcountry.copy()
for i in range(900):
times[home_team[i]] +=1
times[away_team[i]] +=1
# print(times)
# 各个国家胜利的次数
win=allcountry.copy()
for i in range(900):
if result_n[i] == 0:
win[away_team[i]] += 1
if result_n[i] == 1:
win[home_team[i]] += 1
# print(win)
# 总进球数
goals = allcountry.copy()
for i in range(900):
goals[home_team[i]] += home_score[i]
goals[away_team[i]] += away_score[i]
# print(goals)
# 各个球队胜率
# csvFile = open('data.csv','w', newline='')
# writer = csv.writer(csvFile)
# writer.writerow(["country","times","win","goals","rate of winning","Average goal"])
# for key in allcountry:
# writer.writerow([key,times[key],win[key],goals[key],win[key]/times[key],goals[key]/times[key]])
# csvFile.close()
df = pd.read_csv('data.csv',encoding="utf_8_sig")
country = df["country"]
data_times = df["times"]
data_win = df["win"]
data_goals = df["goals"]
r_of_winning = df["rate of winning"]
Average_goal = df["Average goal"]
csvFile2 = open('tr_data_after.csv','w', newline='',encoding="utf_8_sig")
writer2 = csv.writer(csvFile2)
writer2.writerow(["home_team","away_team","home_times","away_times","home_win","away_win","home_goals","away_goals","home_r_win","away_r_win","home_Ave_goal","away_Ave_goal","result"])
for i in range(900):
for j in range(82):
if(home_team[i]==country[j]):
for k in range(82):
if (away_team[i] == country[k]):
writer2.writerow([home_team[i],away_team[i],data_times[j],data_times[k],data_win[j],data_win[k],data_goals[j],data_goals[k],r_of_winning[j],r_of_winning[k],Average_goal[j],Average_goal[k],result_n[i]])
csvFile2.close()
确定十六强代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import csv
df = pd.read_csv('fifa_ch.csv',encoding="utf_8_sig")
date = df["date"]
home_team = df["home_team"]
away_team = df["away_team"]
home_score = df["home_score"]
away_score = df["away_score"]
result_n = df["result_n"]
# 2002-2020年16强
country = home_team.append(away_team)
allcountry = {
}
for i in country:
if i not in allcountry:
allcountry[i]=0
# for k in range(2002,2020,4):
# times = allcountry.copy()
# for i in range(900):
# if date[i]==k:
# times[home_team[i]] +=1
# times[away_team[i]] +=1
#
# csvFile = open('country.csv','a', newline='',encoding='utf_8')
# writer = csv.writer(csvFile)
# # writer.writerow(["year","country","times"])
#
# list_2002 = sorted(times.items(), key=lambda x: x[1], reverse=True)
# b=pd.DataFrame(list_2002)
# c= b[0].head(16)
# d= b[1].head(16)
#
#
# for i in range(16):
# writer.writerow([k,c[i],d[i]])
# csvFile.close()
df = pd.read_csv('country.csv',encoding="utf_8")
year = df["year"]
country = df["country"]
times = df["times"]
dic={
}
for cy in country:
if cy not in dic:
dic[cy] = 1
else:
dic[cy] += 1
NO16=sorted(dic.items(), key=lambda x:x[1],reverse=True)
NO16=pd.DataFrame(NO16).reset_index(drop = True)
print(NO16.head(16))
# NO16[0].head(16).to_csv("NO16.csv",encoding="utf_8_sig")
主要机器学习以及分析代码:
import pandas as pd
from numpy import *
import numpy as np
from sklearn.neural_network import MLPClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import learning_curve
from sklearn.metrics import accuracy_score,recall_score,f1_score
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
from sklearn import svm
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.utils.np_utils import to_categorical
from random import sample
import csv
from sklearn.metrics import mean_squared_error
from sklearn.metrics import median_absolute_error
from tensorflow import keras
from sklearn.metrics import classification_report
from sklearn.metrics import precision_recall_curve, average_precision_score
from sklearn.model_selection import ShuffleSplit
from sklearn.linear_model import Lasso
from sklearn.metrics import confusion_matrix
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
from keras.layers import Embedding
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv('tr_data_after2.csv',encoding="utf_8_sig")
home_team = df["home_team"]
away_team = df["away_team"]
home_times = df["home_times"]
away_times = df["away_times"]
home_win = df["home_win"]
away_win = df["away_win"]
home_goals = df["home_goals"]
away_goals = df["away_goals"]
home_r_win = df["home_r_win"]
away_r_win = df["away_r_win"]
home_Ave_goal = df["home_Ave_goal"]
away_Ave_goal = df["away_Ave_goal"]
result = df["result"]
team_merge = pd.concat([home_team,away_team,home_times,away_times,home_win,away_win,home_goals,away_goals,home_r_win,away_r_win,home_Ave_goal,away_Ave_goal,result], axis=1).drop(['home_team','away_team'],axis=1)
# Min-Max处理
play_score_temp = team_merge.iloc[:, :-1]
# play_score_normal = (play_score_temp - play_score_temp.min()) / (play_score_temp.max() - play_score_temp.min())
# 标准分数处理
play_score_normal = (play_score_temp - play_score_temp.mean()) / (play_score_temp.std())
play_score_normal = pd.concat([play_score_normal, team_merge.iloc[:, -1]], axis=1)
print(play_score_normal)
# 获取csv数据的长度(条数)
with open('tr_data_after2.csv', 'r',encoding="utf_8_sig") as f:
line=len(f.readlines())
tr_index=sample(range(0,line-1),int(line*0.7))
te_index=[i for i in range(0,line-1) if i not in tr_index]
tr_x = play_score_normal.iloc[tr_index, :-1] # 训练特征
tr_y = play_score_normal.iloc[tr_index, -1] # 训练目标
te_x = play_score_normal.iloc[te_index, :-1] # 测试特征
te_y = play_score_normal.iloc[te_index, -1] # 测试目标
df2 = pd.read_csv('data.csv',encoding="utf_8_sig")
country = df2["country"]
times = df2["times"]
win = df2["win"]
goals = df2["goals"]
rate = df2["rate of winning"]
Average = df2["Average goal"]
frames=[country,times,win,goals,rate,Average]
country_all = pd.concat(frames, axis=1).dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
num_data = country_all.iloc[:,[1,2,3,4,5]]
# 测试对象Min-Max处理
# country_all_MM = (num_data - num_data.min()) / (num_data.max() - num_data.min())
# 标准分数标准化
country_all_MM = (num_data - num_data.mean()) / (num_data.std())
country_all_MM = pd.concat([country, country_all_MM], axis=1)
# country_all_MM.to_csv("tr_data_z.csv",encoding="utf_8_sig")
play_score_normal.reset_index(drop = True)
play_score_normal.to_csv("play_score_normal.csv",encoding="utf_8_sig")
model=MLPClassifier(hidden_layer_sizes=10,max_iter=1000).fit(tr_x,tr_y)
print("神经网络:")
print("训练集准确度:{:.3f}".format(model.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(model.score(te_x,te_y)))
y_pred = model.predict(te_x)
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
# 准确率,召回率,F-score评价
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
print("逻辑回归:")
logreg = LogisticRegression(C=1,solver='liblinear',multi_class ='auto')
logreg.fit(tr_x, tr_y)
score = logreg.score(tr_x, tr_y)
score2 = logreg.score(te_x, te_y)
print("训练集准确度:{:.3f}".format(logreg.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(logreg.score(te_x,te_y)))
y_pred = logreg.predict(te_x)
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
print("决策树:")
tree=DecisionTreeClassifier(max_depth=50,random_state=0)
tree.fit(tr_x,tr_y)
y_pred = tree.predict(te_x)
print("训练集准确度:{:.3f}".format(tree.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(tree.score(te_x,te_y)))
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
print("随机森林:")
rf=RandomForestClassifier(max_depth=20,n_estimators=1000,random_state=0)
rf.fit(tr_x,tr_y)
print("训练集准确度:{:.3f}".format(rf.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(rf.score(te_x,te_y)))
y_pred = rf.predict(te_x)
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
print("SVM支持向量机:")
clf = svm.SVC(C=0.1, kernel='linear', decision_function_shape='ovr')
clf.fit(tr_x, tr_y.ravel())
y_pred = clf.predict(te_x)
print("训练集准确度:{:.3f}".format(clf.score(tr_x,tr_y)))
print("测试集准确度:{:.3f}".format(clf.score(te_x,te_y)))
print("平均绝对误差:",mean_absolute_error(te_y, y_pred))
print("ACC",accuracy_score(te_y,y_pred))
print("REC",recall_score(te_y,y_pred,average="micro"))
print("F-score",f1_score(te_y,y_pred,average="micro"))
# 学习曲线函数
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("game num")
plt.ylabel("score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
cv = ShuffleSplit(n_splits=line, test_size=0.2, random_state=0)
plot_learning_curve(logreg, "logreg", tr_x, tr_y, ylim=None, cv=cv, n_jobs=1)
plot_learning_curve(tree, "tree", tr_x, tr_y, ylim=None, cv=None, n_jobs=1)
plot_learning_curve(rf, "rf", tr_x, tr_y, ylim=None, cv=None, n_jobs=1)
plot_learning_curve(model, "model", tr_x, tr_y, ylim=None, cv=None, n_jobs=1)
plot_learning_curve(clf, "clf", tr_x, tr_y, ylim=None, cv=None, n_jobs=1)
#
#
def GRA_ONE(DataFrame,m=-1):
gray= DataFrame
# 读取为df格式
gray=(gray - gray.min()) / (gray.max() - gray.min())
# 标准化
std = gray.iloc[:, m] # 为标准要素
ce = gray.iloc[:, 0:] # 为比较要素
n=ce.shape[0]
m=ce.shape[1]# 计算行列
# 与标准要素比较,相减
a=zeros([m,n])
for i in range(m):
for j in range(n):
a[i,j]=abs(ce.iloc[j,i]-std[j])
# 取出矩阵中最大值与最小值
c=amax(a)
d=amin(a)
# 计算值
result=zeros([m,n])
for i in range(m):
for j in range(n):
result[i,j]=(d+0.5*c)/(a[i,j]+0.5*c)
# 求均值,得到灰色关联值
result2=zeros(m)
for i in range(m):
result2[i]=mean(result[i,:])
RT=pd.DataFrame(result2)
return RT
def GRA(DataFrame):
list_columns = [str(s) for s in range(len(DataFrame.columns)) if s not in [None]]
df_local = pd.DataFrame(columns=['home_times','away_times','home_win','away_win','home_goals','away_goals','home_r_win','away_r_win','home_Ave_goal','away_Ave_goal'])
for i in range(len(DataFrame.columns)):
df_local.iloc[:,i] = GRA_ONE(DataFrame,m=i)[0]
return df_local
play_score = GRA(team_merge.drop(columns=['result']))
#
#
#
# def ShowGRAHeatMap(DataFrame):
# import matplotlib.pyplot as plt
# import seaborn as sns
# colormap = plt.cm.RdBu
# plt.figure(figsize=(14,12))
# plt.title('FIFA Correlation of Features', y=1.05, size=15)
# sns.heatmap(DataFrame.astype(float),linewidths=0.1,vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True)
# plt.show()
# ShowGRAHeatMap(play_score)
#
#
#
#
# keras深度学习库
# 我们是用Sequential模型,它是多个网络层的线性堆叠,通过堆叠许多层,构建出深度神经网络。通过 .add() 函数添加新的层
# 这里我们定义了3个全连接层,第一层input_dim表示我们有10个输入,也就是各个特征,然后剩余的几层全连接,最后输出维度为2的结果
#
model_k = Sequential()
model_k.add(Dense(output_dim=500, input_dim=10, activation='relu'))
model_k.add(Dense(output_dim=500, input_dim=200, activation='relu'))
model_k.add(Dense(units=2, activation='softmax'))
# 为了保证数据一致性,将目标类转化为独热编码,同时我们想要计算交叉熵损失函数,Adam算法作为优化算法,然后把准确率当做衡量这个算法的指标
y = to_categorical(tr_y, 2)
model_k.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
# 以200个样本为一批进行迭代
model_k.fit(np.asarray(tr_x), y, epochs=200, batch_size=200)
result = model_k.evaluate(np.asarray(tr_x), y)
y_pred = model_k.predict_classes(np.asarray(te_x))
print(result[1])
#
# plt.show()
# 16强
#
# df = pd.read_csv('NO16.csv',encoding="utf_8_sig")
# country = df['country']
#
# g1_index=sample(range(0,16),8)
# group1=pd.Series(country[g1_index]).reset_index(drop = True)
#
# g2_index=[i for i in range(0,16) if i not in g1_index]
# group2=pd.Series(country[g2_index])
#
#
# csvFile = open('16res.csv', 'w', newline='',encoding="utf_8_sig")
# writer = csv.writer(csvFile)
# writer.writerow(["times","team1","team2","win"])
# print("\n16进8")
# for i in range(0,8):
# print("组1:第",i+1,"队")
# team1 = country_all_MM.loc[
# country_all['country'] == group1.iloc[i]]
#
# print(group1.iloc[i])
# print("组2:第",i+1,"队")
# team2 = country_all_MM.loc[
# country_all['country'] == group2.iloc[i]]
#
# print(group2.iloc[i])
#
# print("比赛结果")
# vs = pd.concat([team1.reset_index(),
# team2.reset_index()],
# axis=1).drop(['index', 'country'], axis=1)
#
# result=model_k.predict_classes(np.asarray(vs))
#
# if(result==1):
# temp = group1.iloc[i]
# if(result==0):
# temp = group2.iloc[i]
# print("获胜方:", temp)
# writer.writerow([i,group1.iloc[i],group2.iloc[i],temp])
# csvFile.close()
#
# # 8强
# df = pd.read_csv('16res.csv',encoding="utf_8_sig")
# win = df['win']
# g1_index=[i for i in range(0,4)]
# group1=pd.Series(win[g1_index]).reset_index(drop = True)
# g2_index=[j for j in range(4,8)]
# group2=pd.Series(win[g2_index]).reset_index(drop = True)
#
#
#
# csvFile = open('8res.csv', 'w', newline='',encoding="utf_8_sig")
# writer = csv.writer(csvFile)
# writer.writerow(["times","team1","team2","win"])
# print("\n8进4")
# for i in range(0,4):
# print("组1:第",i+1,"队")
# team1 = country_all_MM.loc[country_all['country'] == group1.iloc[i]]
# print(group1.iloc[i])
# print("组2:第",i+1,"队")
# team2 = country_all_MM.loc[country_all['country'] == group2.iloc[i]]
# print(group2.iloc[i])
# print("比赛结果")
# vs = pd.concat([team1.reset_index(), team2.reset_index()], axis=1).drop(['index', 'country'], axis=1)
# result=model_k.predict_classes(np.asarray(vs))
# if (result == 1):
# temp = group1.iloc[i]
# if (result == 0):
# temp = group2.iloc[i]
# print("获胜方:", temp)
# writer.writerow([i, group1.iloc[i], group2.iloc[i], temp])
# csvFile.close()
#
#
#
#
# # 4强
# df = pd.read_csv('8res.csv',encoding="utf_8_sig")
# win = df['win']
#
# g1_index=[i for i in range(0,2)]
# group1=pd.Series(win[g1_index]).reset_index(drop = True)
# g2_index=[j for j in range(2,4)]
# group2=pd.Series(win[g2_index]).reset_index(drop = True)
#
#
#
# csvFile = open('4res.csv', 'w', newline='',encoding="utf_8_sig")
# writer = csv.writer(csvFile)
# writer.writerow(["times","team1","team2","win"])
# print("\n4进2")
# for i in range(0,2):
# print("组1:第",i+1,"队")
# team1 = country_all_MM.loc[country_all['country'] == group1.iloc[i]]
# print(group1.iloc[i])
# print("组2:第",i+1,"队")
# team2 = country_all_MM.loc[country_all['country'] == group2.iloc[i]]
# print(group2.iloc[i])
# print("比赛结果")
# vs = pd.concat([team1.reset_index(), team2.reset_index()], axis=1).drop(['index', 'country'], axis=1)
# result=model_k.predict_classes(np.asarray(vs))
# if (result == 1):
# temp = group1.iloc[i]
# if (result == 0):
# temp = group2.iloc[i]
# print("获胜方:", temp)
# writer.writerow([i, group1.iloc[i], group2.iloc[i], temp])
# csvFile.close()
#
# #决赛
# df = pd.read_csv('4res.csv',encoding="utf_8_sig")
# win = df['win']
#
# g1_index=[i for i in range(0,1)]
# group1=pd.Series(win[g1_index]).reset_index(drop = True)
# g2_index=[j for j in range(1,2)]
# group2=pd.Series(win[g2_index]).reset_index(drop = True)
#
#
#
# csvFile = open('2res.csv', 'w', newline='',encoding="utf_8_sig")
# writer = csv.writer(csvFile)
# writer.writerow(["times","team1","team2","win"])
# print("\n决赛")
# for i in range(0,1):
# print("组1:第",i+1,"队")
# team1 = country_all_MM.loc[country_all['country'] == group1.iloc[i]]
# print(group1.iloc[i])
# print("组2:第",i+1,"队")
# team2 = country_all_MM.loc[country_all['country'] == group2.iloc[i]]
# print(group2.iloc[i])
# print("比赛结果")
# vs = pd.concat([team1.reset_index(), team2.reset_index()], axis=1).drop(['index', 'country'], axis=1)
# result=model_k.predict_classes(np.asarray(vs))
# if (result == 1):
# temp = group1.iloc[i]
# if (result == 0):
# temp = group2.iloc[i]
# print("获胜方:", temp)
# writer.writerow([i, group1.iloc[i], group2.iloc[i], temp])
# csvFile.close()
以上内容为个人学习总结用,预测世界杯冠军并非笔者目的。未经许可不得转载。