16000亿!谷歌发布人类历史首个万亿级模型 Switch Transformer,中国还有机会赶超吗?...
新年伊始,大规模预训练模型军备竞赛进入万亿参数时代。
文:梦佳、周寅张皓、贾伟
近日,Google Brain的研究人员William Fedus、Barret Zoph、Noam Shazeer等在arxiv上提交了一篇新论文,“Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”,提出了稀疏激活专家模型Switch Transformer。

链接:arxiv.org/abs/2101.03961
研究人员表示,这个1.6万亿参数模型似乎是迄今为止最大的模型,其速度是Google之前开发的最大语言模型(T5-XXL)的4倍,参数规模几乎是1750亿参数的GPT-3的十倍!
这应该是人类历史上发布的第一个万亿级人工智能模型。
研究人员在论文中指出,大规模训练是通向强大模型的有效途径,具有大量数据集和参数计数的简单架构可以远远超越复杂的算法,但目前有效的大规模训练主要使用稠密模型。
作为对比,William等人提出的 Switch Transformer 采用了“稀疏激活”技术。所谓稀疏,指的是对于不同的输入,只激活神经网络权重的子集。
根据作者介绍,Switch Transformer是在MoE的基础上发展而来的,而MoE则是90年代初首次提出的AI模型。MoE 将多个“专家”或专门从事不同任务的模型放在一个较大的模型中,并有一个“门控网络”来选择对于任何给定数据要咨询哪些/个“专家”。
尽管MoE取得了一些显著成功,但复杂性、通信成本和训练不稳定阻碍了其广泛采用。
Switch Transformer的新颖之处在于,它有效地利用了为稠密矩阵乘法(广泛用于语言模型的数学运算)而设计的硬件——例如GPU和Google TPU。研究人员为不同设备上的模型分配了唯一的权重,因此权重会随着设备的增多而增加,但每个设备上仅有一份内存管理和计算脚本。
Switch Transformer 在许多下游任务上有所提升。研究人员表示,它可以在使用相同计算资源的情况下使预训练速度提高7倍以上。他们证明,大型稀疏模型同样可以用于创建较小的、稠密的模型,通过微调,这些模型相对大型模型会有30%的质量提升。
论文一作William Fedus 也在twitter上表示,「我们的模型采样更加高效,相比于流行的模型,T5-Base,T5-Large、T5-XXL等能实现4到7倍的增速。」
在一项测试中,Switch Transformer模型以在100多种不同语言之间的翻译测试中,研究人员观察到“普遍改进”,与基准模型相比,91%的语言翻译有4倍以上的提速。
研究人员认为,在未来的工作中,Switch Transformer可以应用到其他模态或者跨模态的研究当中。模型稀疏性可以多模态模型中发挥出更大的优势。
01
模型框架
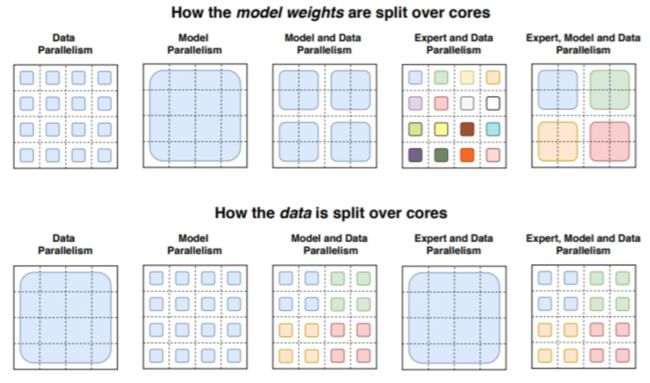
模型的设计原则是,在保持计算开销与效率的同时,尽可能的提升模型的参数量。该工作通过固定每个数据样本所进行的浮点数操作,对比不同参数量可能带来的影响。实际运行中,该方法通过split层将不同的参数分配到不同的设备上,在增加新的设备时,更多的参数会被引入,因此能够根据设备的属性分配参数数量,同时维持在各个设备上的存储开销和计算足迹。
1)简化稀疏通道
Mixture of Expert Routing:
Shazeer et al.(2017) 提出了一种混合专家轨迹的语言模型,能给输入匹配到最适合的k个“专家”模型。分配的参数W生成每个“专家”的结果所占的比重,进行线性加和,得到样本的输出结果。
Switch Routing: Rethinking Mixture-of-Experts:
作者在本文中提出的Switch Layer对上述MoE模型做出改进,MoE模型对每个输出需要参考至少2个以上的专家意见,而本文提出的Switch Routing方法,针对不同的输入,匹配最适合的一个专家。有如下优势:
1、通道计算量大大降低,因为每个样本仅仅需要一个“专家”通道参与计算;
2、每个“专家”通道所计算样本的batchsize被大大缩小(至少减半);
3、每个专家通道的实现复杂度减小了,“专家”间的通信开销降低。
2)高效稀疏通道
模型采用了Mesh-Tensorflow(MTF)库实现,能够高效支持分布式的数据与模型结构,下面的部分将会重点介绍Switch-Transformer的实现。
Distributed Switch Implementation
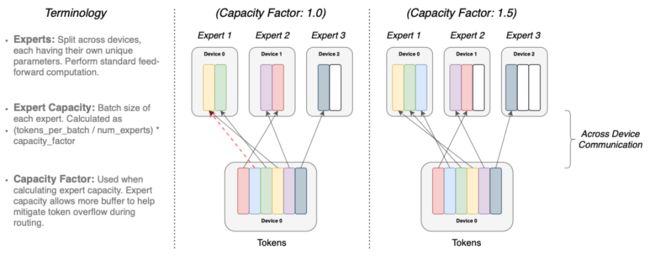
虽然输入数据的张量大小是实现决定的,但因为分配通道的不同,以及训练和预测阶段的不同,计算过程是动态变化的,因此作者采用了expert capacity的设定,通过调整每个expert计算的token数量,来控制整体的计算。表达式如下:
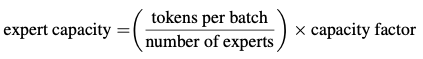
当capacity factor大于1时,代表需要创建额外的缓存器来容纳没能在expert中得到较好分配的数据。当过多数据被交付给同一个expert时,计算过程则会被跳过,数据将直接通过残差连接交付给下一层。增大capacity也会带来缺点,比如内存和计算资源的浪费。
3)Putting all together
第一个测试时在Raffel et al. 2019年引入的“Colossal Clean Crawled Corpus”(C4)上进行。采用了masked language model task,令模型预测消失的tokens。测试中随机drop out百分之15的token并使用一个前缀token来替换mask序列。我们记录困惑度(Negative Log Perplexity)进行对比。
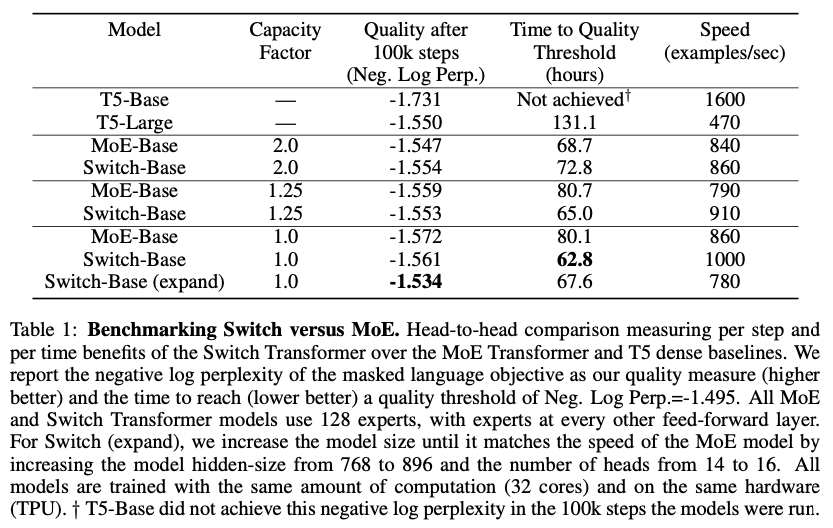
上表显示:
1、在速度-质量的指标上,Switch-Transformer超过了精密微调的稠密模型,与MoE Transformer。在有限的计算量与工作时间下,Switch Transformer都得到了最优的结果;
2、Switch Transformer有更小的计算足迹(computational footprint);
3、在更小的capactiy factor下,Switch Transformer工作的效果更佳。
4)提升训练与微调的技术
稀疏专家模型相比普通Transformer更难训练,这是由于切换通道带来的不稳定引起的,同时,低精度计算会导致恶化softmax计算中的问题,下面列举训练中遇到的问题,以及本文解决的方法。
Selective Precision with Large Sparse Model:
在MoE的工作中,作者发现低精度训练存在的问题,并通过float32精度数据训练解决,但是此举会引入更高的通信开销,本文工作发现,在局部引入高精度的训练,而非全局采用,就可以达到理想的稳定性,测试效果如表2所示。

small Parameter Initialization for Stability:
参数初始化对模型训练十分关键,本文中采用了Transformer的初始化方案,但将其均值缩放了10倍,提升了模型的稳定性能,测试比较结果如下:
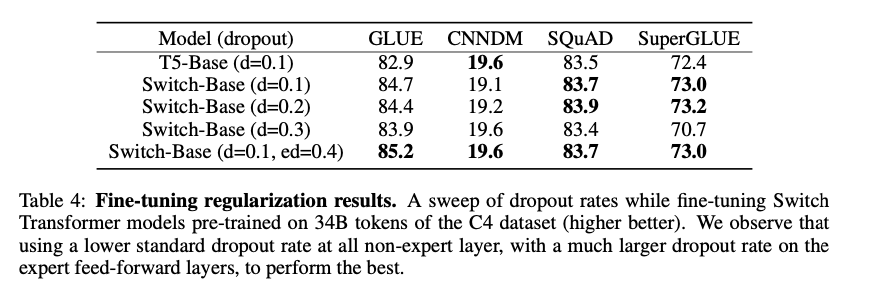
Regularizing Large Sparse Model:
本文中采用的方法是常规的预训练+微调方法,常见的问题是,由于下游任务的数据较少,在微调过程中容易发生过拟合现象,在以往的模型中已经非常常见,但是本文中的模型有着更大量的参数,因此会导致更加严重的过拟合现象。本文通过在微调过程中,增加在每个expert中的dropout比例来缓解过拟合。
02
性能对比:稀疏 vs 稠密
作者分别在预训练阶段和下游任务阶段分别对 Switch Transformer的特性进行了研究。
在预训练阶段,为避免数据瓶颈问题,他们选用了具有超过180B个目标token的大型C4语料库。
下图展示了专家数量(模型参数)带来的一致性规模优势,其中所有模型的训练步数是固定的。
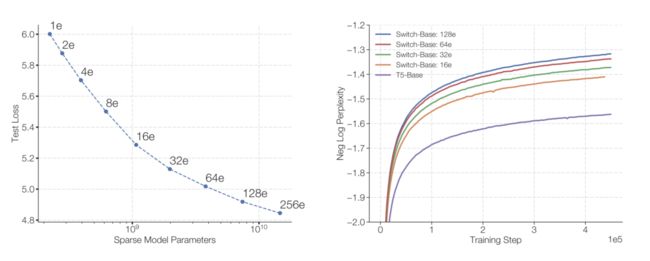
左图:随着模型参数增加(专家数量增加),性能的提升。从左上角到右下角,专家数量分别为2、4、8……、256(14.7B个参数)。
右图:专家数量的每步负对数复杂度。紫色基线为稠密基线(T5-Base),Switch-Base模型的采样效率会比较高。
如果训练时间确定,计算资源也确定,那么到底是训练一个稠密模型(Dense Model)好,还是训练一个稀疏模型(sparse model)好?下面两张图回答了这个问题:
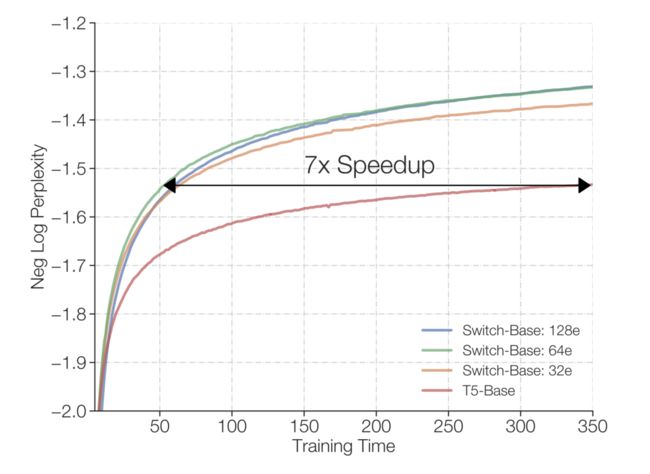 由图可见,在相同负对数复杂度的情况下,Switch-Base的模型(稀疏模型)相比T5-Base模型(稠密模型)要有近七倍的提速。
由图可见,在相同负对数复杂度的情况下,Switch-Base的模型(稀疏模型)相比T5-Base模型(稠密模型)要有近七倍的提速。
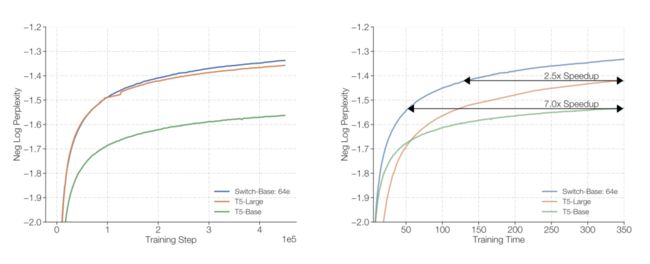
使用Switch层或标准稠密模型的Scaling Transformer模型。左图:Switch-Base与T5-Base和T5-Large变体相比,具有更高的采样效率。右图:在相同负对数复杂度情况下,Switch-Base相比T5-Large的速度提高了2.5倍。
在下游任务上,作者认为预训练的收益可以转化为下游任务上语言学习能力的提高。
作者选用了四种模型,分别为T5-Base、T5-Large、Switch-Base、Switch-Large,其参数和FLOPS分别如下:

在各种知识密集型语言任务上,我们可以观察到Switch Transformer都有显著地提升:

当然,部署一个具有数十亿或数万亿参数的大规模神经网络是极为不便的。为了缓解这种情况,作者也研究了如何将大型稀疏模型蒸馏为小型稠密模型的方法。
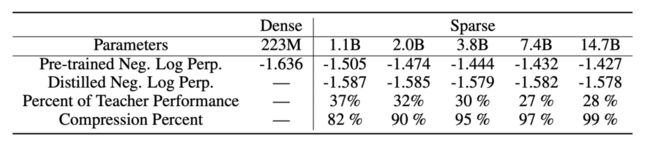
在上表中可以看到,通过蒸馏,在仅保留1.1B参数的情况下(压缩了82%),依然可以获得37%的性能增益;极端情况下,将模型压缩99%,也能够获得28%的性能改善。
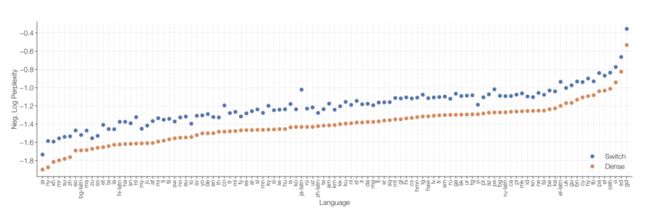
作者尝试在101种语言上进行多语言预训练,从下图可以看出,Switch Transformer在所有语言上全面超越T5-Base模型。
03
未来研究可能性
作者在论文中,提出六大问题以及六个未来可能的研究方向。
1)六大问题
问:纯粹的大参数是否会让 Switch Transformer更好?
答:是的!大型模型已被证明具有更好的性能。在这种情况下,Switch Transformer模型可以在使用相同计算资源的同时,采样效率更高,速度更快。
问:没有大算力,这么大的模型对我有用吗?
答:这种技术在小规模环境中同样有用,仅有两个专家的模型就可以提高性能。
问:如果在速度-精度曲线上,稀疏模型会优于稠密模型吗?
答:是的。在各种不同大小的模型尺度下,稀疏模型的速度和精度均优于稠密模型。
问:我无法部署一个万亿参数级别的模型,可以缩小一下吗?
答:正如前面提到了蒸馏一样,可以。但无法完全保证模型的质量,但是通过将稀疏模型蒸馏为稠密模型,可以达到10倍,甚至100倍的压缩率,而同时专家模型依然可以获得将近30%的性能增益。
问:使用Switch Transformer替代model-parallel的稠密模型,真的有必要吗?
答:从时间角度看,Switch Transformer要比具有同样级别参数的稠密模型要更高效。当然两者并非互斥,在Switch Transformer 中使用模型并行,有时候会导致传统模型并行性变慢。
问:既然稀疏模型这么好,为什么到现在稀疏模型还没有被广泛使用呢?
答:尝试使用稀疏模型的动机,被可扩展稠密模型的成功给掩盖了;而且稀疏模型也受到模型复杂性、训练困难、通信成本等问题的困扰。Switch Transformer在缓解这些问题方面取得了比较大的进步。
2)六大可能方向
面对未来更大规模的模型,训练的稳定性是一个重大挑战。作者提到目前的技术对于Switch-Base、Switch-Large和Switch-C模型还没有观察到不稳定现象,但对于更大的模型或许会不够,所以他们提出了使用正则化函数、适度的梯度裁剪等方法作为预备。
训练中存在一些异常现象。一般来说预训练越好,下游任务的效果也就越好,但在一些任务上发现,1.6T参数的Switch-C会比较小模型的结果更低。
Switch-Transformer可以用来研究规模关系,从而来指导融合数据、模型、专家并行的体系结构设计。
这一工作属于自适应计算算法系列,目前使用的是相同的同类专家,但未来可以设计支持异构专家。
调查FFN层之外的专家层,初步的证据表明,这同样可以改善模型质量。
在目前的工作中,主要考虑了语言任务,未来或许可以将模型稀疏性类似地应用到其他模态(例如图像)或多模态中。
04
作者是谁?
这篇论文的作者都来自谷歌大脑,分别为:William Fedus,Barret Zoph,Noam Shazeer。

其中一作Fedus是蒙特利尔大学博士生,师从 Hugo Larochelle和Yoshua Bengio, Google Brain学生研究员。
目前研究领域主要为监督、无监督机器学习和强化学习。本科在MIT攻读物理学,参与暗物质方向的研究,硕士毕业于加州大学圣地亚哥分校。曾经在ICLR 2018、NeurIPS 2019、ICML 2020等顶会发表一作论文。

作为共同一作的 Barret Zoph 是 Google Brain团队的高级研究员。
此前在南加州大学的资讯科学研究院( ISI )与 Kevin Knight 和 Daniel Marcu 教授合作研究神经网络机器翻译的相关课题。曾在CVPR 2018、NeurIPS 2020、ECCV 2020等发表顶会一作文章。

值得注意的是,作者之一Noam Shazeer正是「Attention is all your need」的作者之一。

推荐阅读:

113亿参数,中国最大 AI 模型!不仅能作诗,还能告诉你男朋友该不该分手!

点击左下角“阅读原文”,了解更多!