Day9-Python文本数据(DataWhale)
文本数据
import pandas as pd
import numpy as np
print(pd.__version__)
1.2.0
一、str对象
1. str对象的设计意图
(1) str 对象是定义在 Index 或 Series 上的属性,专门用于逐元素处理文本内容
(2) 对一个序列进行文本处理,首先需要获取其 str 对象
(3) 有 str 模块, 许多函数的用法与pandas一致
var = 'abcd'
str.upper(var) # Python内置str模块
'ABCD'
s = pd.Series(['abcd','efg','hj'])
s.str
s.str.upper()# pandas中str对象上的upper方法
0 ABCD
1 EFG
2 HJ
dtype: object
2. []索引器
对于 str 对象而言,可理解为其对字符串进行了序列化的操作,例如在一般的字符串中,通过 [] 可以取出某个位置的元素
var[0]
'a'
var[0:2:1] #切片start:end:step---不包含end
'ab'
通过对 str 对象使用 [] 索引器,可以完成完全一致的功能,并且如果超出范围则返回缺失值
s.str[0]
0 a
1 e
2 h
dtype: object
s.str[0:2:1]
0 ab
1 ef
2 hj
dtype: object
s.str[2]
0 c
1 g
2 NaN
dtype: object
3. string类型
(1) 字符串需要具有自己的数据存放类型,object类型只应当存储混合类型
(2) 绝大多数对于object和string类型的序列使用 str 对象方法产生的结果是一致
(3) 尽量保证每一个序列中的值都是字符串的情况下才使用str属性
(4) 对于可迭代对象(包括但不限于字符串、字典、列表),string类型的str对象和object类型的str对象返回结果可能是不同的
s = pd.Series([{
1:'temp_1',2:'temp_2'},['a','b'],0.5,'my_string'])
s.str[1]
0 temp_1
1 b
2 NaN
3 y
dtype: object
s[1]
['a', 'b']
思考:比较上面的两个,带有str和不带str产生的结果完全不一样,带有str会作用到每一个元素,而不是作为一个整体
s.astype('string').str[1]
0 1
1 '
2 .
3 y
dtype: string
解释:
(1) 序列类型为 object 时,是对于每一个元素进行 [] 索引。对于字典而言,返回temp_1字符串,对于列表则返回第二个值,而第三个为不可迭代对象,返回缺失值,第四个是对字符串进行 [] 索引
(2) string 类型的 str 对象先把整个元素转为字面意义的字符串。对于字典而言,第一个元素即 “{“,对于字符串元素,转化前后的表示方法一致
s = pd.Series(['a'])
s.str.len()
0 1
dtype: int64
s.astype('string').str.len()
0 1
dtype: Int64
s == 'a'
0 True
dtype: bool
s.astype('string') == 'a'
0 True
dtype: boolean
s = pd.Series(['a', np.nan])
s.str.len()
0 1.0
1 NaN
dtype: float64
s.astype('string').str.len()
0 1
1
dtype: Int64
s == 'a'
0 True
1 False
dtype: bool
s.astype('string') == 'a'
0 True
1
dtype: boolean
解释:
(1) string 类型是 Nullable 类型, 如果调用的 str 方法返回值为整数 Series 和布尔 Series 时,其分别对应的 dtype 是 Int 和 boolean 的 Nullable 类型
(2) object 类型则会分别返回 int/float 和 bool/object ,取决于缺失值的存在与否
s = pd.Series([12, 345, 6789])
s.astype('string').str[1]
0 2
1 4
2 7
dtype: string
解释: 对于全体元素为数值类型的序列,即使其类型为 object 或者 category 也不允许直接使用 str 属性。如果需要把数字当成 string 类型处理,可以使用 astype 强制转换为 string 类型的 Series
二、正则表达式基础
1. 一般字符的匹配
(1) 正则表达式是一种按照某种正则模式,从左到右匹配字符串中内容的一种工具
(2) 对于一般的字符而言,它可以找到其所在的位置
使用re 模块的 findall 函数来匹配所有出现过但不重叠的模式, 第一个参数是正则表达式,第二个参数是待匹配的字符串
import re
re.findall(r'Apple', 'Apple! This Is an Apple! ')
['Apple', 'Apple']
2. 元字符基础

re.findall(r'a.','abc')
['ab']
re.findall(r'[ac]','abc')
['a', 'c']
re.findall(r'[^ac]','abc')
['b']
re.findall(r'[ab]{2}','aaabbc') # {n}指匹配n次
['aa', 'ab']
re.findall(r'aaa|bbb','aaaabbbb')
['aaa', 'bbb']
re.findall(r'a\?|aa\*','aa?a*a')#匹配a?或者aa*
['a?']
re.findall(r'a?','abaacadaae') # 0次或一次
['a', '', 'a', 'a', '', 'a', '', 'a', 'a', '', '']
re.findall(r'a+','abaacadaae') #1次或多次
['a', 'aa', 'a', 'aa']
re.findall(r'a*','abaacadaae') #0次或多次
['a', '', 'aa', '', 'a', '', 'aa', '', '']
3. 简写字符集
正则表达式中还有一类简写字符集,其等价于一组字符的集合
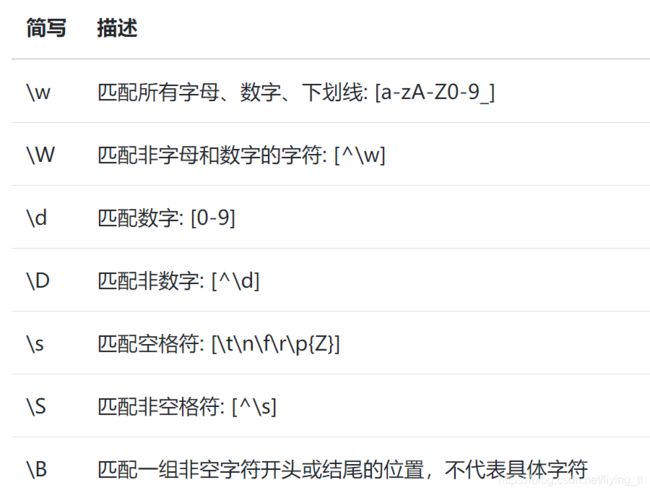
re.findall(r'.s', 'Apple! This Is an Apple!')#匹配s结束的两个字符
['is', 'Is']
re.findall(r'\w{2}', '09 8? 7w c_ 9q p@') #连续两次出现字母、数字、下划线
['09', '7w', 'c_', '9q']
re.findall(r'\w\W\B', '09 8? 7w c_ 9q p@')
['8?', 'p@']
re.findall(r'.\s.', 'Constant dropping wears the stone.') #匹配空格前后的两个字符
['t d', 'g w', 's t', 'e s']
三、文本处理的五类操作
1. 拆分
1. str.split
能够把字符串的列进行拆分,第一个参数为正则表达式【会将分隔符去除】
可选参数:
n: 从左到右的最大拆分次数
expand: 是否展开为多个列
s = pd.Series(['上海市黄浦区方浜中路249号','上海市宝山区密山路5号'])
s.str.split('[市区路]')
0 [上海, 黄浦, 方浜中, 249号]
1 [上海, 宝山, 密山, 5号]
dtype: object
s.str.split('[市区路]', n=2, expand=True)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 上海 | 黄浦 | 方浜中路249号 |
| 1 | 上海 | 宝山 | 密山路5号 |
2. str.rsplit
其区别在于使用 n 参数的时候是从右到左限制最大拆分次数。但是当前版本下 rsplit 因为 bug 而无法使用正则表达式进行分割
s.str.rsplit('[市区路]', n=2, expand=True)
| 0 | |
|---|---|
| 0 | 上海市黄浦区方浜中路249号 |
| 1 | 上海市宝山区密山路5号 |
2. 合并
1. str.join
用某个连接符把 Series 中的字符串列表连接起来,如果列表中出现了非字符串元素则返回缺失值
s = pd.Series([['a','b'], [1, 'a'], [['a', 'b'], 'c']])
s.str.join('-')
0 a-b
1 NaN
2 NaN
dtype: object
2. str.cat
用于合并两个序列。
参数:
sep: 连接符
join: 连接形式,默认为以索引为键的左连接
na_rep: 缺失值替代符号
s1 = pd.Series(['a','b'])
s2 = pd.Series(['cat','dog'])
s1.str.cat(s2,sep='-')
0 a-cat
1 b-dog
dtype: object
s2.index = [1, 2]
s2
1 cat
2 dog
dtype: object
s1.str.cat(s2, sep='-', na_rep='?', join='outer')
0 a-?
1 b-cat
2 ?-dog
dtype: object
3. 匹配
1. str.contains
回了每个字符串是否包含正则模式的布尔序列
s = pd.Series(['my cat', 'he is fat', 'railway station'])
s.str.contains('\s\wat')
# 是否存在空格符+字母、数字、下划线+at的组合
0 True
1 True
2 False
dtype: bool
2. str.startswith
返回了每个字符串以给定模式为开始的布尔序列,不支持正则表达式
s.str.startswith('my')
0 True
1 False
2 False
dtype: bool
3. str.endswith
返回了每个字符串以给定模式为结束的布尔序列,不支持正则表达式
s.str.endswith('t')
0 True
1 True
2 False
dtype: bool
4. str.match
返回了每个字符串起始处是否符合给定正则模式的布尔序列,支持正则表达式
s.str.match('m|h') #存在m或者h
0 True
1 True
2 False
dtype: bool
s.str[::-1].str.match('ta[f|g]|n')
# 反转后匹配ta+f或者g,n
0 False
1 True
2 True
dtype: bool
5. str.contains 的正则中使用^和$来实现起始处的判断
s.str.contains('^[m|h]')
0 True
1 True
2 False
dtype: bool
s.str.contains('[f|g]at|n$')
0 False
1 True
2 True
dtype: bool
6. str.find
返回从左到右第一次匹配的位置的索引,未找到则返回-1,不支持正则匹配,只能用于字符子串的匹配
s = pd.Series(['This is an apple. That is not an apple.'])
s.str.find('apple')
0 11
dtype: int64
7. str.find
返回从右到左第一次匹配的位置的索引,未找到则返回-1,不支持正则匹配,只能用于字符子串的匹配
s.str.rfind('apple')
0 33
dtype: int64
4. 替换
1. str.replace
使用字符串替换时使用str.replace,而不是replace
s = pd.Series(['a_1_b','c_?'])
s.str.replace('\d|\?', 'new', regex=True)
#替换数字或者?为'new'
0 a_new_b
1 c_new
dtype: object
2. 使用子组
对不同部分进行有差别的替换,可以通过传入自定义的替换函数来分别进行处理,group(k) 代表匹配到的第 k 个子组
s = pd.Series(['上海市黄浦区方浜中路249号','上海市宝山区密山路5号','北京市昌平区北农路2号'])
pat = '(\w+市)(\w+区)(\w+路)(\d+号)'
city = {
'上海市': 'Shanghai', '北京市': 'Beijing'}
district = {
'昌平区': 'CP District','黄浦区': 'HP District','宝山区': 'BS District'}
road = {
'方浜中路': 'Mid Fangbin Road','密山路': 'Mishan Road','北农路': 'Beinong Road'}
def my_func(m):
str_city = city[m.group(1)]
str_district = district[m.group(2)]
str_road = road[m.group(3)]
str_no = 'No. ' + m.group(4)[:-1]
return ' '.join([str_city,str_district,str_road,str_no])
s.str.replace(pat, my_func, regex=True)
0 Shanghai HP District Mid Fangbin Road No. 249
1 Shanghai BS District Mishan Road No. 5
2 Beijing CP District Beinong Road No. 2
dtype: object
这里的数字标识并不直观,可以使用 命名子组 更加清晰地写出子组代表的含义:
pat = '(?P<市名>\w+市)(?P<区名>\w+区)(?P<路名>\w+路)(?P<编号>\d+号)'
def my_func(m):
str_city = city[m.group('市名')]
str_district = district[m.group('区名')]
str_road = road[m.group('路名')]
str_no = 'No. ' + m.group('编号')[:-1]
return ' '.join([str_city,str_district,str_road,str_no])
s.str.replace(pat, my_func, regex=True)
0 Shanghai HP District Mid Fangbin Road No. 249
1 Shanghai BS District Mishan Road No. 5
2 Beijing CP District Beinong Road No. 2
dtype: object
实际数据处理中对应的替换,一般都会通过代码来获取数据从而构造字典映射
5. 提取
提取既可以认为是一种返回具体元素(而不是布尔值或元素对应的索引位置)的匹配操作,也可以认为是一种特殊的拆分操作【不去除分隔符】
1. str.extract
只匹配一次
pat = '(\w+市)(\w+区)(\w+路)(\d+号)'
s.str.extract(pat)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 上海市 | 黄浦区 | 方浜中路 | 249号 |
| 1 | 上海市 | 宝山区 | 密山路 | 5号 |
| 2 | 北京市 | 昌平区 | 北农路 | 2号 |
2. 通过子组的命名,直接对新列命名
pat = '(?P<市名>\w+市)(?P<区名>\w+区)(?P<路名>\w+路)(?P<编号>\d+号)'
s.str.extract(pat)
| 市名 | 区名 | 路名 | 编号 | |
|---|---|---|---|---|
| 0 | 上海市 | 黄浦区 | 方浜中路 | 249号 |
| 1 | 上海市 | 宝山区 | 密山路 | 5号 |
| 2 | 北京市 | 昌平区 | 北农路 | 2号 |
3. str.extractall
将所有符合条件的模式全部匹配出来,如果存在多个结果,则以多级索引的方式存储
s = pd.Series(['A135T15,A26S5','B674S2,B25T6'], index = ['my_A','my_B'])
pat = '[A|B](\d+)[T|S](\d+)'
s.str.extractall(pat)
| 0 | 1 | ||
|---|---|---|---|
| match | |||
| my_A | 0 | 135 | 15 |
| 1 | 26 | 5 | |
| my_B | 0 | 674 | 2 |
| 1 | 25 | 6 |
s.str.extract(pat)
| 0 | 1 | |
|---|---|---|
| my_A | 135 | 15 |
| my_B | 674 | 2 |
pat_with_name = '[A|B](?P\d+)[T|S](?P\d+)'
s.str.extractall(pat_with_name)
| name1 | name2 | ||
|---|---|---|---|
| match | |||
| my_A | 0 | 135 | 15 |
| 1 | 26 | 5 | |
| my_B | 0 | 674 | 2 |
| 1 | 25 | 6 |
4. str.findall
类似于 str.extractall,区别是:str.findall所有匹配组合构成列表,并把结果存入列表中,而str.extractall每个行只对应一组匹配,并将结果处理为多级索引
s.str.findall(pat)
my_A [(135, 15), (26, 5)]
my_B [(674, 2), (25, 6)]
dtype: object
四、常用字符串函数
1. 字母型函数
upper, lower, title, capitalize, swapcase 这五个函数主要用于字母的大小写转化
s = pd.Series(['lower', 'CAPITALS', 'this is a sentence', 'SwApCaSe'])
s.str.upper()#大写转换
0 LOWER
1 CAPITALS
2 THIS IS A SENTENCE
3 SWAPCASE
dtype: object
s.str.lower()#小写转换
0 lower
1 capitals
2 this is a sentence
3 swapcase
dtype: object
s.str.title() #首字母大写
0 Lower
1 Capitals
2 This Is A Sentence
3 Swapcase
dtype: object
s.str.capitalize() #句子的首字母大写
0 Lower
1 Capitals
2 This is a sentence
3 Swapcase
dtype: object
s.str.swapcase() #大小写字母转换,大写变小写,小写变大写
0 LOWER
1 capitals
2 THIS IS A SENTENCE
3 sWaPcAsE
dtype: object
2. 数值型函数
pd.to_numeric
对字符格式的数值进行快速转换和筛选。
参数:
errors: 非数值的处理模式。raise:直接报错、coerce:设为缺失、ignore:保持原来的字符串
downcast: 非数值的转换类型
s = pd.Series(['1', '2.2', '2e', '??', '-2.1', '0'])
pd.to_numeric(s, errors='ignore')
0 1
1 2.2
2 2e
3 ??
4 -2.1
5 0
dtype: object
pd.to_numeric(s, errors='coerce')
0 1.0
1 2.2
2 NaN
3 NaN
4 -2.1
5 0.0
dtype: float64
利用 coerce 的设定,快速查看非数值型的行
s[pd.to_numeric(s, errors='coerce').isna()]
2 2e
3 ??
dtype: object
3. 统计型函数
1. count
返回出现正则模式的次数
s = pd.Series(['cat rat fat at', 'get feed sheet heat'])
s.str.count('[r|f]at|ee') #出现r或者f+at或者ee的次数
0 2
1 2
dtype: int64
2. len
字符串的长度
s.str.len()
0 14
1 19
dtype: int64
4. 格式型函数
除空型
1. strip
去除两侧空格
my_index = pd.Index([' col1', 'col2 ', ' col3 '])
my_index.str.strip().str.len()
Int64Index([4, 4, 4], dtype='int64')
2. rstrip
去除右侧空格
my_index.str.rstrip().str.len()
Int64Index([5, 4, 5], dtype='int64')
3. lstrip
去除左侧空格
my_index.str.lstrip().str.len()
Int64Index([4, 5, 5], dtype='int64')
填充型
1. pad
可以选定字符串长度、填充的方向和填充内容
s = pd.Series(['ac','b','c'])
s.str.pad(5,'left','*') #总位数为5,空位向左填充*
0 ***ac
1 ****b
2 ****c
dtype: object
s.str.pad(5,'right','*')
0 ac***
1 b****
2 c****
dtype: object
s.str.pad(5,'both','*')#两边填充
0 **ac*
1 **b**
2 **c**
dtype: object
上述的三种情况可以分别用 rjust, ljust, center 来等效完成
s.str.rjust(5, '*') #向左填充,数字在右 等价于left
0 ***ac
1 ****b
2 ****c
dtype: object
s.str.ljust(5, '*') #向右填充,数字在左 等价于right
0 ac***
1 b****
2 c****
dtype: object
s.str.center(5, '*') #等价于both
0 **ac*
1 **b**
2 **c**
dtype: object
2. zfill
返回指定长度的字符串,原字符串右对齐,前面填充0
s = pd.Series([7, 155, 303000]).astype('string')
s.str.pad(6,'left','0')
0 000007
1 000155
2 303000
dtype: string
s.str.rjust(6,'0')
0 000007
1 000155
2 303000
dtype: string
s.str.zfill(6)
0 000007
1 000155
2 303000
dtype: string
五、练习
1. 房屋信息数据集
df1 = pd.read_excel('data/house_info.xls',usecols=['floor','year','area','price'])
df1.head(2)
| floor | year | area | price | |
|---|---|---|---|---|
| 0 | 高层(共6层) | 1986年建 | 58.23㎡ | 155万 |
| 1 | 中层(共20层) | 2020年建 | 88㎡ | 155万 |
1. 将 year 列改为整数年份存储
思路: 截取year元素的前四位并赋值到year;另一种思路是将year根据年去拆分。但是这两种方式个人更偏向于第一种,这份数据的年一定是四位的,如果读取出来的前四位出现了异常,那么该条数据是异常值
df = df1.copy()
year_a = df['year'].str[:4]
year_a.head(2)
0 1986
1 2020
Name: year, dtype: object
df['year'] = year_a
df.head(2)
| floor | year | area | price | |
|---|---|---|---|---|
| 0 | 高层(共6层) | 1986 | 58.23㎡ | 155万 |
| 1 | 中层(共20层) | 2020 | 88㎡ | 155万 |
year_b = df['year'].str.split('年建',expand=True)
#此处注意使用expand进行分列
df['year'] = year_b
df.head(2)
| floor | year | area | price | |
|---|---|---|---|---|
| 0 | 高层(共6层) | 1986 | 58.23㎡ | 155万 |
| 1 | 中层(共20层) | 2020 | 88㎡ | 155万 |
2. 将 floor 列替换为 Level, Highest 两列,其中的元素分别为 string 类型的层类别(高层、中层、低层)与整数类型的最高层数
Level = df['floor'].astype('string').str[0:2]
#可以用来获取Level,但是获取Height有点困难
ext = df['floor'].str.extract('(\w层)(共(\d+)层)')
#通过括号去控制想要获取的值,一定要注意提取时要兼顾所有的字符
Level = ext[0]
Height = ext[1]
df['Level'] = Level
df['Height'] = Height
df = df[['Level','Height','year','area','price']]
df.head(2)
| Level | Height | year | area | price | |
|---|---|---|---|---|---|
| 0 | 高层 | 6 | 1986 | 58.23㎡ | 155万 |
| 1 | 中层 | 20 | 2020 | 88㎡ | 155万 |
3. 计算房屋每平米的均价 avg_price ,以 * * 元 / 平米的格式存储到表中,其中 * * 为整数**
思路:先将area和price处理成float和int型,方便之后的计算,在这里将截取后的数字转变为float型时出现了报错,后来发现应该是存在空格,使用replace替换掉空格即可
#截取出数值
area_sum = df['area'].str.split('[㎡]',expand = True)
price_sum = df['price'].str.split('万',expand = True)
#将空格替换掉,方便转换为float型
area_sum2 = area_sum[0].str.replace(' ','')
price_sum2 = price_sum[0].str.replace(' ','')
#将数值转换为float型
area_sum2 = area_sum2.astype('float')
price_sum2 = price_sum2.astype('float')
#将价格转换为元
price_sum2 = [ i*10000 for i in price_sum2]
price_sum2 = pd.Series(price_sum2)
#将面积和价格插入df表
df['price_sum'] = price_sum2
df['area_sum'] = area_sum2
df.head(2)
| Level | Height | year | area | price | price_sum | area_sum | |
|---|---|---|---|---|---|---|---|
| 0 | 高层 | 6 | 1986 | 58.23㎡ | 155万 | 1550000.0 | 58.23 |
| 1 | 中层 | 20 | 2020 | 88㎡ | 155万 | 1550000.0 | 88.00 |
#求出avg_price
df['avg_price'] = df['price_sum']/df['area_sum']
#将avg_price转换为整数型
df['avg_price'] = df['avg_price'].astype(int)
#给avg_price添加单位
df['avg_price'] = [str(i)+'元/平米' for i in df['avg_price']]
df[['Level','Height','year','avg_price']].head(5)
| Level | Height | year | avg_price | |
|---|---|---|---|---|
| 0 | 高层 | 6 | 1986 | 26618元/平米 |
| 1 | 中层 | 20 | 2020 | 17613元/平米 |
| 2 | 低层 | 28 | 2010 | 40859元/平米 |
| 3 | 低层 | 20 | 2014 | 37560元/平米 |
| 4 | 高层 | 1 | 2015 | 11938元/平米 |
2.《权力的游戏》剧本数据集
df2 = pd.read_csv('data/script.csv')
df2.head(2)
| Release Date | Season | Episode | Episode Title | Name | Sentence | |
|---|---|---|---|---|---|---|
| 0 | 2011-04-17 | Season 1 | Episode 1 | Winter is Coming | waymar royce | What do you expect? They're savages. One lot s... |
| 1 | 2011-04-17 | Season 1 | Episode 1 | Winter is Coming | will | I've never seen wildlings do a thing like this... |
1. 计算每一个 Episode 的台词条数
思考:此处的Episode尾部带有一个空格,先将列名的空格去除,之后再根据Episode进行分组求和
df = df2.copy()
#去除列名的空格
df.columns = df.columns.str.strip()
#进行分组求和,求出每一个Episode的台词条数
gb = df.groupby('Episode')['Sentence'].count()
gb.head(2)
Episode
Episode 1 2637
Episode 10 1846
Name: Sentence, dtype: int64
2. 以空格为单词的分割符号,请求出单句台词平均单词量最多的前五个人
思考:split在拆分之后会存为列表,刚好可以用来计算len(),求出单词量之后根据Name,求出平均单词,再选取前5即可
#求出每行单词量
df['Vocabulary'] = df['Sentence'].str.split(' ').str.len()
#分组求出平均单词量
gb = df.groupby('Name')['Vocabulary'].mean()
#根据values进行排序
gb = gb.sort_values(ascending = False)
#选取前5
gb.head(5)
Name
male singer 109.000000
slave owner 77.000000
manderly 62.000000
lollys stokeworth 62.000000
dothraki matron 56.666667
Name: Vocabulary, dtype: float64
3. 若某人的台词中含有问号,那么下一个说台词的人即为回答者。若上一人台词中含有 n 个问号,则认为回答者回答了 n 个问题,请求出回答最多问题的前五个人
思考:求出每一句的?数量即可
#求出回答问题的数量
df['count'] = df['Sentence'].str.count('\?')
#分组求出总回答问题数
gb = df.groupby('Name')['count'].sum()
#根据values进行排序
gb = gb.sort_values(ascending = False)
#选取前5
gb.head(5)
Name
tyrion lannister 579
daenerys targaryen 395
cersei lannister 351
jaime lannister 303
jon snow 269
Name: count, dtype: int64