【leetcode】23. 合并K个排序链表(优先队列,有序列表合并)
知识点:优先队列(priority_queue),有序列表合并
注意点:
- priority_queue底层是heap。默认情况下底层是以Vector实现的heap。优先级队列是一个拥有权值概念的单向队列queue,在这个队列中,所有元素是按优先级排列的
- cmp的结构体写法
- 重载运算符是operate() [注意这里不是>]
- priority_queue
题目:
合并K个排序链表
方法 1:逐一比较
算法
比较 k 个节点(每个链表的首节点),获得最小值的节点。
将选中的节点接在最终有序链表的后面。
复杂度分析
时间复杂度: O(kN)O(kN) ,其中 \text{k}k 是链表的数目。
几乎最终有序链表中每个节点的时间开销都为 O(k)(k-1 次比较)。
总共有 NN 个节点在最后的链表中。
空间复杂度:
O(n)。创建一个新的链表空间开销为 O(n)。
O(1)。重复利用原来的链表节点,每次选择节点时将它直接接在最后返回的链表后面,而不是创建一个新的节点。
方法 2:用优先队列优化方法
算法
几乎与上述方法一样,除了将 比较环节 用 优先队列 进行了优化。你可以参考 这里 获取更多信息。
作者:LeetCode
链接:https://leetcode-cn.com/problems/merge-k-sorted-lists/solution/he-bing-kge-pai-xu-lian-biao-by-leetcode/
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
struct cmp{
bool operator () (ListNode* l1, ListNode* l2){
return l1->val > l2->val;
}
};
ListNode* mergeKLists(vector<ListNode*>& lists) {
ListNode* res = new ListNode(0); // dummy head point
ListNode* tmpRes = res;
priority_queue<ListNode*, vector<ListNode*>, cmp> pq; // 第三个参数自定义时需每个参数显示调用
for(int i = 0; i < lists.size(); i++){
if(lists[i] != NULL){
pq.push(lists[i]);
}
}
while(!pq.empty()){
ListNode* tmpNode = new ListNode(pq.top()->val);
tmpRes->next = tmpNode;
tmpRes = tmpRes->next; // res上面移动,res指示头结点
ListNode* topNext = pq.top()->next;
pq.pop();
if(topNext != NULL){
pq.push(topNext);
}
}
return res->next;
}
};
拓展:优先队列+堆
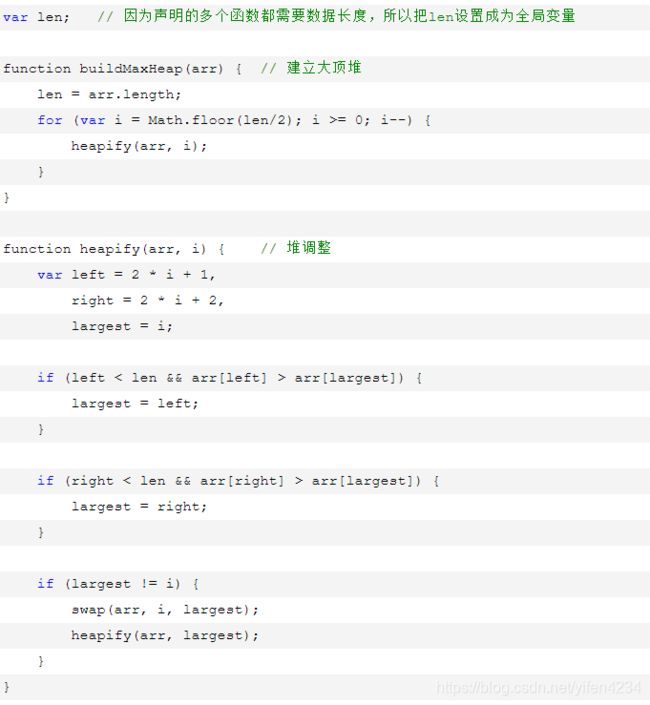
单纯堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
**堆的定义:**具有n个元素的序列 (h1,h2,…,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1) (i=1,2,…,n/2)时称之为堆。在这里只讨论满足前者条件的堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项(大顶堆)。完全二叉树可以很直观地表示堆的结构。堆顶为根,其它为左子树、右子树。
思想:初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的存储序,使之成为一个堆,这时堆的根节点的数最大。然后将根节点与堆的最后一个节点交换。然后对前面(n-1)个数重新调整使之成为堆。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。
所以堆排序有两个函数组成。
一是建堆的建堆函数,
二是反复调用建堆函数实现排序的函数。
————————————————
版权声明:本文为CSDN博主「kuanzi0001」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yifen4234/article/details/88643712#22__207
// 一次只调整k这个元素
void AdjustDown(ElemType a[], int k, int len){
a[0] = a[k];
// 注意,堆是完全二叉树,所以坐标有规律,
// 节点i的父亲是i/2, 左右孩子是2*i, 2*i+1
for(i = 2*k; i<=len; i*=2){
if(i<len && a[i]<a[i+1])
i++; // 找到更大的孩子节点
if(a[0] >= a[i])
break; // 它比儿子们都大,所以说明已经有序的了,因为其他部分本来有序
else{
// 如果没有儿子大,则交换下去
// 但是这边只是上移了孩子,因为可能会一直移动,所以就不重复赋值了,直接找到最终点,一次性写值上去
a[k] = a[i]; // 这里覆盖了没事,a[0]还存着初始值
k = i; // 将指针下移
}
}
a[k] = a[0];
}
void BuildHeap(Elemtype a[]){
for ( int i=len/2; i>0; i-- ){
// 从底部往上建
AdjustDown(a, i, len);
}
}
void HeapSort(int a[], int len){
BuildMaxHeap(a, len); // 首先建堆
for(int i = len; i>1; i--){
swap[a[1], a[i]];
AdjustDown(a, 1, i-1); // 注意!此时是从上往下调整堆,从堆顶开始调整,目前堆里面只剩下i-1个元素
}
}
// 插入元素:原来的堆是有序的,所以插入的目标是只需要调整插入的元素,找到他的位置
// 其他元素只是被迫被影响了
void AdjustUp(int a[], int k, int len){
a[0] = a[k];
for(int i = k/2; i > 1; i = i/2){
if(a[i] < a[0]){
a[k] = a[i]; // 双亲节点下调
k = i;
}
else break; // 如果双亲不小于当前元素,说明已经找到位置了
}
a[k] = a[0];
}
————————————————
版权声明:本文为CSDN博主「kuanzi0001」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yifen4234/article/details/88643712

【排序】堆排序,C++实现
https://www.cnblogs.com/wanglei5205/p/8733524.html
这个有图说明,还挺清晰的
#includeHeap
在探讨priority_queue之前,我们必须先分析heap。heap并不归属于STL容器,他是个幕后英雄,扮演priorityqueue的助手。顾名思义,priority queue允许用户以任何次序将任何元素推入容器,但取出时一定是从优先权最高的元素开始取。Binary max heap证据有这样的特性,适合作为priority_queue的底层机制。由于关于heap有关的算法可参见相关数据结构书籍,这里只是用图简单的介绍。
————————————————
版权声明:本文为CSDN博主「walkerkalr」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/walkerkalr/article/details/22823237
priority_queue底层是vector,使用了heap算法
首先,**堆是完全二叉树,**这意味着堆可以很方便用数组这种数据结构来表示,看下图:
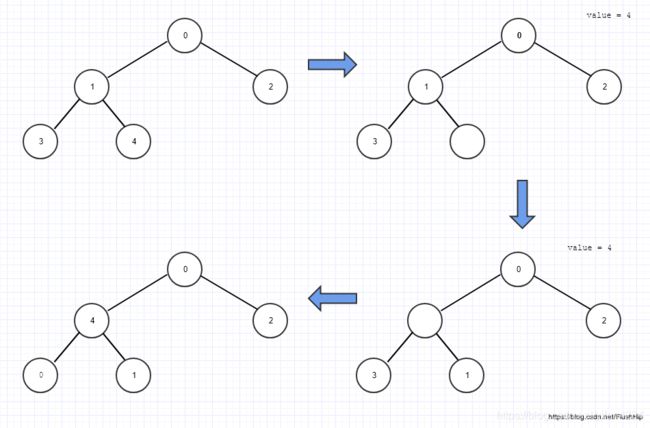
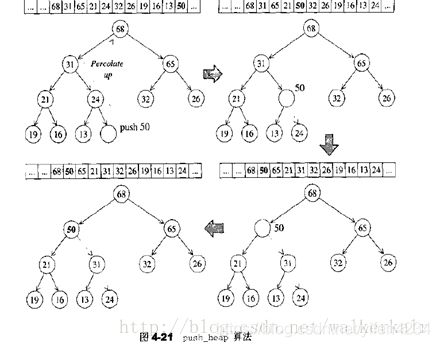
push_heap算法:
push的方法是将新的元素放到vector末尾。
这里把最后一个元素,也就是新加入堆的元素(最后一个叶子结点)打了个洞,利用std::move,这样,最后一个位置是没有值的,这相当于是一个空洞;
由于出现了空洞,因此需要元素来填上空洞,而且,新加入进来的元素只会影响一条路径(叶子结点到根节点的路径),因此只要在这条路径上做插入排序就好了,把父亲结点移动到孩子结点直到这条路径上满足堆的性质,这样可以填洞,但是又会把父亲结点弄成洞,所以最后用新加入的元素填住最后的洞,其实就是个向上的插入排序。这样,就把新加入的元素融入了堆。
————————————————
版权声明:本文为CSDN博主「FlushHip」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/FlushHip/article/details/85266258
template <typename _RandomAccessIterator, typename _Distance, typename _Tp, typename _Compare>
void
__push_heap(_RandomAccessIterator __first,
_Distance __holeIndex, _Distance __topIndex, _Tp __value,
_Compare __comp)
{
_Distance __parent = (__holeIndex - 1) / 2;
while (__holeIndex > __topIndex && __comp(__first + __parent, __value))
{
*(__first + __holeIndex) = std::move(*(__first + __parent));
__holeIndex = __parent;
__parent = (__holeIndex - 1) / 2;
}
*(__first + __holeIndex) = std::move(__value);
}
/**
* @brief Push an element onto a heap.
* @param __first Start of heap.
* @param __last End of heap + element.
* @ingroup heap_algorithms
*
* This operation pushes the element at last-1 onto the valid heap
* over the range [__first,__last-1). After completion,
* [__first,__last) is a valid heap.
*/
template <typename _RandomAccessIterator>
inline void
push_heap(_RandomAccessIterator __first, _RandomAccessIterator __last)
/*
template
inline void
push_heap(_RandomAccessIterator __first, _RandomAccessIterator __last, _Compare __comp)
*/
{
typedef typename iterator_traits<_RandomAccessIterator>::value_type _ValueType;
typedef typename iterator_traits<_RandomAccessIterator>::difference_type _DistanceType;
_ValueType __value = std::move(*(__last - 1));
std::__push_heap(__first, _DistanceType((__last - __first) - 1),
_DistanceType(0), std::move(__value),
__gnu_cxx::__ops::__iter_less_val());
// __gnu_cxx::__ops::__iter_comp_val(__comp));
}
————————————————
版权声明:本文为CSDN博主「FlushHip」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/FlushHip/article/details/85266258
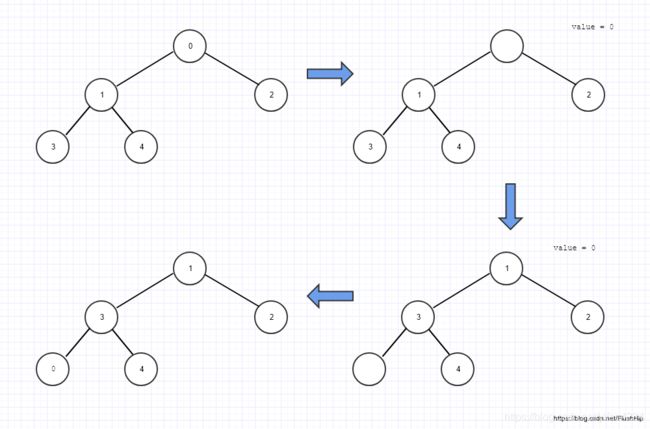
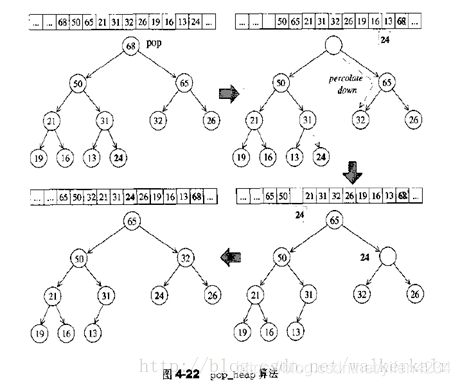
pop_heap算法:
把堆顶元素和序列尾元素交换一下,调整堆就行了。
是讲最前面的元素提出来放到最后,注意原来第一个位置则是空出来的
向下调整这个空位
以大顶堆为例,把最大的元素弹出堆,其实就是把根节点也就是数组的第一个元素弄走就行了。
也就是把第一个元素和最后一个元素互换一下,然后把第一个元素的位置打一个洞,之后就调用__adjust_heap来填洞,其实就是个向下的插入排序。
template <typename _RandomAccessIterator, typename _Distance, typename _Tp, typename _Compare>
void __adjust_heap(_RandomAccessIterator __first, _Distance __holeIndex,
_Distance __len, _Tp __value, _Compare __comp)
{
const _Distance __topIndex = __holeIndex;
_Distance __secondChild = __holeIndex;
// 1
while (__secondChild < (__len - 1) / 2)
{
__secondChild = 2 * (__secondChild + 1);
if (__comp(__first + __secondChild, __first + (__secondChild - 1)))
__secondChild--;
*(__first + __holeIndex) = std::move(*(__first + __secondChild));
__holeIndex = __secondChild;
}
// 2
if ((__len & 1) == 0 && __secondChild == (__len - 2) / 2)
{
__secondChild = 2 * (__secondChild + 1);
*(__first + __holeIndex) = std::move(*(__first + (__secondChild - 1)));
__holeIndex = __secondChild - 1;
}
// 3
std::__push_heap(__first, __holeIndex, __topIndex, std::move(__value), __gnu_cxx::__ops::__iter_comp_val(__comp));
}
template <typename _RandomAccessIterator, typename _Compare>
inline void
__pop_heap(_RandomAccessIterator __first, _RandomAccessIterator __last,
_RandomAccessIterator __result, _Compare __comp)
{
typedef typename iterator_traits<_RandomAccessIterator>::value_type _ValueType;
typedef typename iterator_traits<_RandomAccessIterator>::difference_type _DistanceType;
_ValueType __value = std::move(*__result);
*__result = std::move(*__first);
std::__adjust_heap(__first, _DistanceType(0),
_DistanceType(__last - __first),
std::move(__value), __comp);
}
/**
* @brief Pop an element off a heap.
* @param __first Start of heap.
* @param __last End of heap.
* @pre [__first, __last) is a valid, non-empty range.
* @ingroup heap_algorithms
*
* This operation pops the top of the heap. The elements __first
* and __last-1 are swapped and [__first,__last-1) is made into a
* heap.
*/
template <typename _RandomAccessIterator>
inline void
pop_heap(_RandomAccessIterator __first, _RandomAccessIterator __last)
/*
template
inline void
pop_heap(_RandomAccessIterator __first, _RandomAccessIterator __last, _Compare __comp)
*/
{
typedef typename iterator_traits<_RandomAccessIterator>::value_type _ValueType;
if (__last - __first > 1)
{
--__last;
std::__pop_heap(__first, __last, __last,
__gnu_cxx::__ops::__iter_less_iter());
// __gnu_cxx::__ops::__iter_comp_iter(__comp));
}
}
————————————————
版权声明:本文为CSDN博主「FlushHip」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/FlushHip/article/details/85266258
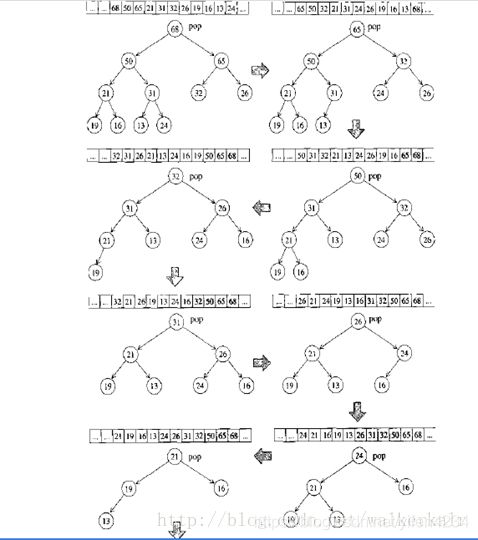
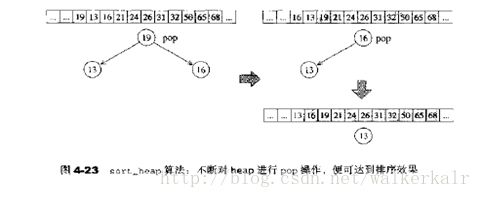
sort_heap算法
根据堆的性质,堆顶一定是最大或者最小的元素,那么,我们**逐渐把堆顶元素和尾部元素互换,然后马上调整堆。**这样子,有序的元素会从数组尾部一直扩展到头部,至此,整个数组都是有序的了。
template <typename _RandomAccessIterator, typename _Compare>
void __sort_heap(_RandomAccessIterator __first, _RandomAccessIterator __last,
_Compare __comp)
{
while (__last - __first > 1)
{
--__last;
std::__pop_heap(__first, __last, __last, __comp);
}
}
/**
* @brief Sort a heap.
* @param __first Start of heap.
* @param __last End of heap.
* @ingroup heap_algorithms
*
* This operation sorts the valid heap in the range [__first,__last).
*/
template <typename _RandomAccessIterator>
inline void
sort_heap(_RandomAccessIterator __first, _RandomAccessIterator __last)
/*
template
inline void
sort_heap(_RandomAccessIterator __first, _RandomAccessIterator __last, _Compare __comp)
*/
{
std::__sort_heap(__first, __last,
__gnu_cxx::__ops::__iter_less_iter());
// __gnu_cxx::__ops::__iter_comp_iter(__comp));
}
————————————————
版权声明:本文为CSDN博主「FlushHip」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/FlushHip/article/details/85266258
由于的所有元素都是遵循特殊的排列规则,所有heap不过遍历,也不提供迭代器。
#includepriority_queue
priority_queue缺省情况下是以vector为底部容器,再加上heap处理规则实现 ,它没有迭代器。它只允许在低端加入元,并从顶端取出元素【单向】,其内部元素自动按照元素的权值排列。权值最高者排在最前面。
C++11的标准库是怎么构造出优先队列的呢?优先队列是用堆来构造的。所以,优先队列其实并不能叫队列,它的完整定义应该是这样的:优先队列是用堆来构造,包装成队列的适配器。
class priority_queue{
public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequencec; // 底层容器
Compare comp; // 元素大小比较标准
public:
priority_queue(): c() {
}
explicit priority_queue(constCompare& x) : c(), comp(x) {
}
// 以下用到的make_heap(), push_heap(),pop_heap()都是泛型算法
// 注意,任何一个构造函数都立刻于底层容器内产生一个implicitrepresentation heap。
#ifdef __STL_MEMBER_TEMPLATES
template <class InputIterator>
priority_queue(InputIteratorfirst, InputIterator last, const Compare& x)
: c(first, last), comp(x) {
make_heap(c.begin(),c.end(), comp); }
template <class InputIterator>
priority_queue(InputIteratorfirst, InputIterator last)
: c(first, last) {
make_heap(c.begin(),c.end(), comp); }
#else /* __STL_MEMBER_TEMPLATES */
priority_queue(constvalue_type* first, const value_type* last,
const Compare& x) :c(first, last), comp(x) {
make_heap(c.begin(), c.end(), comp);
}
priority_queue(constvalue_type* first, const value_type* last)
: c(first, last) {
make_heap(c.begin(),c.end(), comp); }
#endif /* __STL_MEMBER_TEMPLATES */
bool empty()const {
return c.empty(); }
size_type size()const {
return c.size(); }
const_reference top()const {
return c.front(); }
void push(constvalue_type& x) {
__STL_TRY {
// push_heap 是泛型算法,先利用底层容器的push_back()将新元素
// 推入末端,再重排heap
c.push_back(x);
push_heap(c.begin(), c.end(), comp);// push_heap 是泛型演算法
}
__STL_UNWIND(c.clear());
}
void pop(){
__STL_TRY {
// pop_heap 是泛型演算法,從 heap 內取出一個元素。它並不是真正將元素
// 彈出,而是重排heap,然後再以底層容器的pop_back() 取得被彈出
// 的元素。見C++ Primerp.1195。
pop_heap(c.begin(), c.end(), comp);
c.pop_back();
}
__STL_UNWIND(c.clear());
}
};
————————————————
版权声明:本文为CSDN博主「walkerkalr」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/walkerkalr/article/details/22823237