【学术前沿趋势分析 Task 01】
任务1:论文数据统计
任务说明:统计2019年全年计算机各个方向的论文数量;
- 数据集准备
数据集来源数据集下载地址 - 数据集说明
格式说明:
id:arXiv ID,可用于访问论文;
submitter:论文提交者;
authors:论文作者;
title:论文标题;
comments:论文页数和图表等其他信息;
journal-ref:论文发表的期刊的信息;
doi:数字对象标识符,https://www.doi.org;
report-no:报告编号;
categories:论文在 arXiv 系统的所属类别或标签;
license:文章的许可证;
abstract:论文摘要;
versions:论文版本;
authors_parsed:作者的信息。
- arxiv论文类别
类别信息地址
以下为部分类别展示
'astro-ph': 'Astrophysics',
'astro-ph.CO': 'Cosmology and Nongalactic Astrophysics',
'astro-ph.EP': 'Earth and Planetary Astrophysics',
'astro-ph.GA': 'Astrophysics of Galaxies',
'cs.AI': 'Artificial Intelligence',
'cs.AR': 'Hardware Architecture',
'cs.CC': 'Computational Complexity',
'cs.CE': 'Computational Engineering, Finance, and Science',
'cs.CV': 'Computer Vision and Pattern Recognition',
'cs.CY': 'Computers and Society',
'cs.DB': 'Databases',
'cs.DC': 'Distributed, Parallel, and Cluster Computing',
'cs.DL': 'Digital Libraries',
'cs.NA': 'Numerical Analysis',
'cs.NE': 'Neural and Evolutionary Computing',
'cs.NI': 'Networking and Internet Architecture',
'cs.OH': 'Other Computer Science',
'cs.OS': 'Operating Systems',
- 代码实现及分析
requirements
seaborn:0.9.0
BeautifulSoup:4.8.0
requests:2.22.0
json:0.8.5
pandas:0.25.1
matplotlib:3.1.1
导包
#导入所需的package
import seaborn as sns
from bs4 import BeautifulSoup
import re
import requests
import json
import pandas as pd
import matplotlib.pyplot as plt
读数据并打印大小和部分样例
# 读入数据
filepath = r'D:\Datasets\archive\arxiv-metadata-oai-snapshot.json'
data = [] # 初始化
# 使用with语句优势:1.自动关闭文件句柄;2.自动显示(处理)文件读取数据异常
with open(filepath, 'r') as f:
for line in f:
data.append(json.loads(line))
data = pd.DataFrame(data) # 将list变为dataframe格式,方便使用pandas进行分析
print(data.shape) # 显示数据大小
print(data.head()) #显示数据的前五行
print(data["categories"].describe())
此处输出为
(1796911, 14)
id ... authors_parsed
0 0704.0001 ... [[Balázs, C., ], [Berger, E. L., ], [Nadolsky,...
1 0704.0002 ... [[Streinu, Ileana, ], [Theran, Louis, ]]
2 0704.0003 ... [[Pan, Hongjun, ]]
3 0704.0004 ... [[Callan, David, ]]
4 0704.0005 ... [[Abu-Shammala, Wael, ], [Torchinsky, Alberto, ]]
[5 rows x 14 columns]
count 1796911
unique 62055
top astro-ph
freq 86914
Name: categories, dtype: object
筛选独立种类
unique_categories = set([i for l in [x.split(' ') for x in data["categories"]] for i in l])
len(unique_categories)
unique_categories = set([i for l in [x.split(' ') for x in data["categories"]] for i in l])
print(len(unique_categories))
print(unique_categories)
输出
176
{'q-fin.EC', 'math.SG', 'hep-ph', 'q-bio.QM', 'nucl-th', 'q-bio.MN', 'q-fin.GN', 'cs.RO', 'math.RA', 'gr-qc', 'cs.DM', 'cs.NI', 'astro-ph.SR', 'physics.flu-dyn', 'math.DS', 'math.GT', 'stat.AP', 'hep-lat', 'solv-int', 'econ.TH', 'astro-ph', 'math.GR', 'math.CA', 'q-fin.RM', 'math.MP', 'cs.GT', 'math.OC', 'math.AG', 'math.LO', 'math.NT', 'physics.ao-ph', 'acc-phys', 'cs.CL', 'eess.AS', 'math.AT', 'alg-geom', 'hep-th', 'cs.DC', 'cs.MM', 'cs.IR', 'cs.GL', 'cs.NA', 'q-fin.CP', 'cs.PL', 'physics.med-ph', 'math.KT', 'stat.ML', 'physics.optics', 'astro-ph.HE', 'physics.bio-ph', 'cs.GR', 'stat.ME', 'physics.acc-ph', 'physics.space-ph', 'physics.data-an', 'cs.OS', 'cs.MA', 'physics.ins-det', 'physics.gen-ph', 'astro-ph.GA', 'math.AC', 'q-fin.MF', 'cs.CE', 'physics.plasm-ph', 'cs.ET', 'cs.HC', 'eess.SY', 'mtrl-th', 'quant-ph', 'funct-an', 'econ.GN', 'stat.TH', 'cs.MS', 'physics.class-ph', 'cs.CR', 'q-bio.NC', 'cond-mat.supr-con', 'cs.CY', 'cond-mat.mes-hall', 'stat.CO', 'plasm-ph', 'q-bio.CB', 'nucl-ex', 'q-bio.BM', 'cond-mat.quant-gas', 'cs.SE', 'q-bio', 'comp-gas', 'cs.AI', 'physics.chem-ph', 'physics.atm-clus', 'math.HO', 'patt-sol', 'cond-mat', 'supr-con', 'q-bio.SC', 'cs.CG', 'cond-mat.mtrl-sci', 'math.SP', 'math.NA', 'physics.hist-ph', 'math.GN', 'nlin.CD', 'cs.NE', 'astro-ph.CO', 'adap-org', 'math.FA', 'physics.ed-ph', 'math-ph', 'cs.CV', 'stat.OT', 'physics.soc-ph', 'math.ST', 'eess.IV', 'math.DG', 'math.PR', 'math.QA', 'cs.LO', 'chao-dyn', 'cs.DS', 'nlin.CG', 'math.MG', 'cs.DB', 'cs.SD', 'astro-ph.IM', 'physics.app-ph', 'cond-mat.stat-mech', 'q-fin.ST', 'cs.LG', 'dg-ga', 'cond-mat.other', 'cs.IT', 'hep-ex', 'cond-mat.dis-nn', 'math.OA', 'q-fin.TR', 'cond-mat.soft', 'math.GM', 'cmp-lg', 'math.IT', 'eess.SP', 'math.AP', 'math.CO', 'cs.CC', 'chem-ph', 'math.CV', 'math.RT', 'q-alg', 'cond-mat.str-el', 'q-fin.PM', 'cs.SC', 'q-bio.TO', 'bayes-an', 'q-bio.GN', 'physics.pop-ph', 'cs.AR', 'nlin.SI', 'physics.atom-ph', 'cs.FL', 'cs.SI', 'q-bio.PE', 'cs.SY', 'physics.comp-ph', 'ao-sci', 'q-fin.PR', 'q-bio.OT', 'cs.PF', 'cs.OH', 'cs.DL', 'atom-ph', 'astro-ph.EP', 'nlin.PS', 'math.CT', 'physics.geo-ph', 'econ.EM', 'nlin.AO'}
筛选2019年后的论文
data["year"] = pd.to_datetime(data["update_date"]).dt.year #将update_date从例如2019-02-20的str变为datetime格式,并提取处year
del data["update_date"] #删除 update_date特征,其使命已完成
data = data[data["year"] >= 2019] #找出 year 中2019年以后的数据,并将其他数据删除
#data.groupby(['categories','year']) #以 categories 进行排序,如果同一个categories 相同则使用 year 特征进行排序
data.reset_index(drop=True, inplace=True) #重新编号
print(data) #查看结果
此处参考的文档还采用了 网络爬虫的方式爬取了网上的数据集来与本地的数据集做交集,交叉验证,保证数据完整性
# 爬取所有的类别
website_url = requests.get('https://arxiv.org/category_taxonomy').text # 获取网页的文本数据
soup = BeautifulSoup(website_url, 'lxml') # 爬取数据,这里使用lxml的解析器,加速
root = soup.find('div', {
'id': 'category_taxonomy_list'}) # 找出 BeautifulSoup 对应的标签入口
tags = root.find_all(["h2", "h3", "h4", "p"], recursive=True) # 读取 tags
# 初始化 str 和 list 变量
level_1_name = ""
level_2_name = ""
level_2_code = ""
level_1_names = []
level_2_codes = []
level_2_names = []
level_3_codes = []
level_3_names = []
level_3_notes = []
# 进行
for t in tags:
if t.name == "h2":
level_1_name = t.text
level_2_code = t.text
level_2_name = t.text
elif t.name == "h3":
raw = t.text
level_2_code = re.sub(r"(.*)\((.*)\)", r"\2", raw) # 正则表达式:模式字符串:(.*)\((.*)\);被替换字符串"\2";被处理字符串:raw
level_2_name = re.sub(r"(.*)\((.*)\)", r"\1", raw)
elif t.name == "h4":
raw = t.text
level_3_code = re.sub(r"(.*) \((.*)\)", r"\1", raw)
level_3_name = re.sub(r"(.*) \((.*)\)", r"\2", raw)
elif t.name == "p":
notes = t.text
level_1_names.append(level_1_name)
level_2_names.append(level_2_name)
level_2_codes.append(level_2_code)
level_3_names.append(level_3_name)
level_3_codes.append(level_3_code)
level_3_notes.append(notes)
# 根据以上信息生成dataframe格式的数据
df_taxonomy = pd.DataFrame({
'group_name': level_1_names,
'archive_name': level_2_names,
'archive_id': level_2_codes,
'category_name': level_3_names,
'categories': level_3_codes,
'category_description': level_3_notes
})
# 按照 "group_name" 进行分组,在组内使用 "archive_name" 进行排序
df_taxonomy.groupby(["group_name", "archive_name"])
print(df_taxonomy)
re.sub(r"(.*)\((.*)\)",r"\2",raw)
#raw = Astrophysics(astro-ph)
#output = astro-ph
_df = data.merge(df_taxonomy, on="categories", how="left").drop_duplicates(["id","group_name"]).groupby("group_name").agg({
"id":"count"}).sort_values(by="id",ascending=False).reset_index()
print(_df)
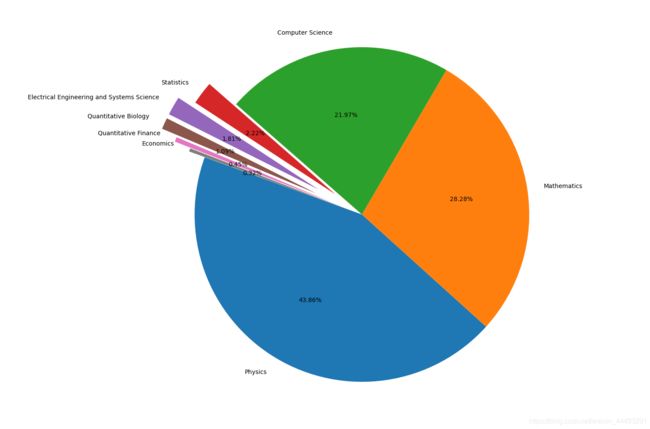
最后对数据绘图分析
fig = plt.figure(figsize=(15,12))
explode = (0, 0, 0, 0.2, 0.3, 0.3, 0.2, 0.1)
plt.pie(_df["id"], labels=_df["group_name"], autopct='%1.2f%%', startangle=160, explode=explode)
plt.tight_layout()
plt.show()
group_name="Computer Science"
cats = data.merge(df_taxonomy, on="categories").query("group_name == @group_name")
cats.groupby(["year","category_name"]).count().reset_index().pivot(index="category_name", columns="year",values="id")
print(cats)