scrapy爬虫框架实现url跟进爬取页面详情
本篇博文将介绍如何搭建爬虫项目实现目录页的数据爬取,并对每个目录标题下的url进行跟进,进入该url爬取该页面的详情内容。最后把结果保存为本地json文件或者csv文件。详细的项目搭建操作已经在前面博文中提及了,可以参考:
https://blog.csdn.net/fallwind_of_july/article/details/97246577
文章非常适合有入门基础的小伙伴们一起学习和研究,我的其他博文也有从零开始学习使用scrapy框架的过程。该项目经过实测验证,代码可以成功运行。文章最后给出github免费的源码下载地址,小伙伴下载下来看着源码分析一下就会很清楚了。
本篇博文是在上一篇的基础上搭建的,上一篇已经成功爬取公到了链接:
https://blog.csdn.net/fallwind_of_july/article/details/97391822
.
一、爬取目标网站:
http://www.gz.gov.cn/gzgov/snzc/common_list.shtml
.
二、爬取目标信息:
我们将要爬取公告的标题,时间以及链接,以及每个标题下的详情内容,如下图所示:
公告标题:

标题详情页:

三、网页分析:
用谷歌浏览器和xpath Helper插件,F12键来分析源代码
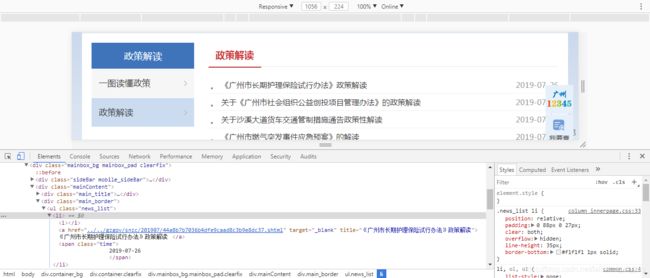
公告标题:
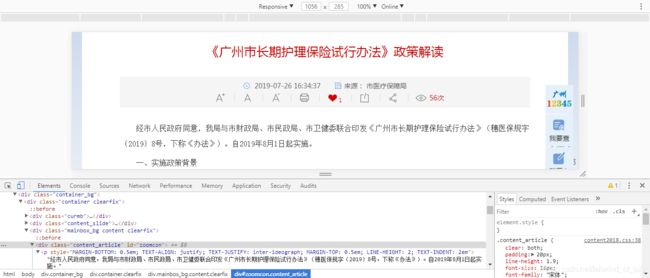
标题详情页:
对于目录页面:可以看出我们需要的名字、时间、链接对应的xpath分别是:
//ul[@class='news_list']/li/a
//ul[@class='news_list']/li/span
//ul[@class='news_list']/li/a/@href
对于详情页面:可以看出我们需要的详情内容的xpath是:
//div[@class=‘content_article’]/p
四、爬取文件代码
我们只需要修改四个文件即可,分别是items.py;pipelines.py;settings.py;爬虫文件govmenu.py
1.items.py文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class GzgovItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#pass
name = scrapy.Field()
time = scrapy.Field()
link = scrapy.Field()
class DetailsItem(scrapy.Item):
detail = scrapy.Field()
以上文件定义我们获取信息的字段;将详情页提取到的数据另外保存到一个文件中,因此另写一个类。
.
2.pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from Gzgov.items import GzgovItem,DetailsItem
import json
class GzgovPipeline(object):
def __init__(self):
#self.f = open("gzgovment.json","w")
self.f = open("title.json","w")
self.file_detail = open("detail.json","w")
def process_item(self, item, spider):
content = json.dumps(dict(item),ensure_ascii=False)
if isinstance(item,GzgovItem):
self.f.write(content + ',\n')
if isinstance(item,DetailsItem):
self.file_detail.write(content + ',\n')
return item
def close_spider(self,spider):
self.f.close()
self.file_detail.close()
以上文件定义我们保持数据的格式,写到本地文件中。可以看到我们打开了两个文件来保存数据,并通过if isinstance来判断数据来源于哪里(是哪个类的实例),然后写入对应的文件。
.
3.settings.py
1.文件中下面的True改为False
ROBOTSTXT_OBEY = False
2.取消67行左右的注释,得到
ITEM_PIPELINES = {
'Gzgov.pipelines.GzgovPipeline': 300,
}
以上文件为配置文件
.
4.我们的爬虫文件govmenu.py
爬虫文件名字自定义,在spiders目录下
# -*- coding: utf-8 -*-
import scrapy
from Gzgov.items import GzgovItem,DetailsItem
#from scrapy.http import Request
class GovmenuSpider(scrapy.Spider):
name = 'govmenu'
allowed_domains = ['gz.gov.cn']
#start_urls = ['http://www.gz.gov.cn/gzgov/snzc/common_list.shtml']
baseURL = "http://www.gz.gov.cn/gzgov/snzc/common_list_"
offset = 1
end = ".shtml"
start_urls = ["http://www.gz.gov.cn/gzgov/snzc/common_list.shtml"]
def parse(self, response):
node_list = response.xpath("//ul[@class='news_list']/li")
for node in node_list:
item = GzgovItem()
item['name'] = node.xpath("./a/text()").extract()
item['time'] = node.xpath("./span/text()").extract()
if node.xpath("./a/@href").extract()[0].startswith("../../gzgov/snzc/") :
item['link'] = str("http://www.gz.gov.cn/gzgov/snzc"+"/"+
node.xpath("./a/@href").extract()[0].split('/', 5)[4]+"/"+
node.xpath("./a/@href").extract()[0].split('/', 5)[5])
else:
item['link'] = ""
# node.xpath("./a/@href").extract()
yield item
yield scrapy.Request(url=item['link'],callback=self.details)
if self.offset < 67:
self.offset +=1
url = self.baseURL + str(self.offset) + self.end
yield scrapy.Request(url,callback=self.parse)
def details(self,response):
item = DetailsItem()
ps = response.xpath("//div[@class='content_article']/p")
item['detail'] = ps.xpath("./text()").extract()
yield item
以上文件的解释:
1.我们采用url拼接的方式进行数据的翻页爬取,
比如第二页的url就是:
http://www.gz.gov.cn/gzgov/snzc/common_list_2.shtml
以此类推,每次只需要修改数字部分即可。总共67个条目,因此我们判断<67。
2.scrapy中有个Request专门处理跟进的url
yield scrapy.Request(url=item['link'],callback=self.details)
.callback是我们的回调函数,说明接下来将要执行的提取内容和方法,指向了我们新写的关于详情页面的函数def details(self,response):
五、运行结果
json格式
1.目录页
2.详情页

到这里,我们就成功地实现了scrapy爬虫之url跟进。
.
六、附录
本文的源码下载(Url文件夹):
https://github.com/AndyofJuly/scrapyDemo
如果有帮助到你,请点个赞或关注对博主进行鼓励,后续还会继续更新进阶的爬虫案例,有任何疑问请下方评论留言,感谢!