大数据技术与应用-D1
大数据技术与应用-D1
- 考核点
- 平台搭建(Hadoop+spark)
- 数据采集(爬虫-request库)
- 数据清洗与分析
- 数据展示
- 写报告
平台搭建
Hadoop生态圈
核心设计HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
-
伪分布:一台单机上运行,但用不同的进程模仿分布式运行中的各类结点。没有所谓的在多台机器上进行真正的分布式计算,故称为"伪分布式"。
-
全分布:由3个及以上的实体机或者虚拟机组件的机群。
-
HA架构(High Available双机集群系统)指高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。
组件安装与配置(hive hbase spark)
-
Hive:基于Hadoop的一个数据仓库工具,可以将结构化的数据文件(或者非结构化的数据)映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
-
HBase:nosql数据库,和mongodb类似。高可靠性、高性能、面向列、可伸缩的分布式存储系统。
-
Spark:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。与 Hadoop 相似的开源集群计算环境,不同:Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
三大组件
-
hdfs(Hadoop Distributed File System)分布式文件系统
底部-存储 Hadoop 集群中所有存储节点上的文件
适合运行在通用硬件(commodity hardware)上的分布式文件系统。
-
MapReduce
上一层-该引擎由 JobTrackers 和 TaskTrackers 组成
概念"Map(映射)“和"Reduce(归约)”,和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
-
yarn(Yet Another Resource Negotiator)
另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
数据采集
[完型填空]
网络爬虫:Request,lxml,scrapy
-
requests:requests 是用Python语言编写,基于自带库urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便
-
lxml:XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。对应插件名为lxml
-
scrapy:Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
数据清洗与分析
MapReduce(大规模数据集的并行运算)
语言:Java
spark(基于MapReduce算法实现的分布式计算)
语言scala(面向对象 函数式编程语言 下一代Java)
hive(HQL)数据库仓库工具
数据展示
[完型填空]
可视化
MySQL
Flask(python轻量级Web框架)
Jinja(基于python的模板引擎,沙箱执行模式,模板的每个部分)
ECharts(使用JavaScript实现的开源可视化库)
前端:JavaScript
平台搭建
环境:VMware
大数据集群操作系统:CentOS 7 64位
创建虚拟机
【创建新的虚拟机】-【典型】
【安装客户机操作】:选择.iso镜像文件(下载镜像文件)[https://msdn.itellyou.cn/]
【命名虚拟机】:设置虚拟机名称及位置
【磁盘大小】:20GB-拆分成多个文件(方便,省内存)
【自定义硬件】:2GB=2048MB
(计算:Master主人1台1-2G;slave2台1-2G;Windows-2G=8G)
安装CentOS 7.
【选择语言】:中文-简体中文中国(爱啥啥)-[继续C]
【安装信息摘要】:有!的地方,点击进入后,左上角【完成】。软件选择:最小安装-命令行。【GNOME桌面】图形桌面
shutdown -h now#关机
shutdown -r now#重启
useradd 用户名#创建用户
passwd 用户名#设置密码
userdel -r 用户名#删除用户
GNOME桌面配置
- 接受安装许可:点击进入
- 我同意许可协议(A)-完成(D)-完成配置(F)
- 欢迎/输入/隐私-(选你所爱)-前进(N)
- 时区:上海,上海,中国
- 连接您的在线账号-跳过(S)
- 关于您:设置全名和用户名
- 设置密码:混合使用字母,数字和标点
一切就绪,开始使用吧!
配置IP-连接网络
-
VMware操作:
-
【编辑(E)】-【虚拟网络编辑器(N)】
-
【更改设置©】
-
VMnet8|NAT模式
子网IP:192.168.66.0|子网掩码:255.255.255.0
[NAT设置(S)]网管IP:192.168.66.2
这里的66爱啥啥,后面统一就行
-
-
虚拟机操作:
-
右上角
 ,再点击设置工具图标(扳手和一字批交叉)
,再点击设置工具图标(扳手和一字批交叉) -
【网络】-【有线】
 设置-IPv4-手动[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
设置-IPv4-手动[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传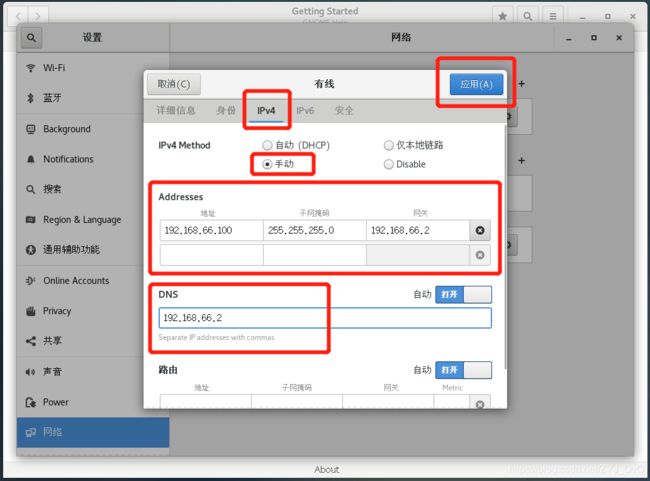
-
有线设为打开状态

-
这时候用物理机ping 192.168.66.100是可以ping通的
-
可以ping通了也就可以用xshell等等的原程桌面了
-
操作小练习
用户创建
进入管理员root,创建用户hadoop,设置hadoop用户密码
su -用户和Shell环境一起切换成root身份,符号从$变为#
useradd 用户名创建用户
passwd 用户名设置密码
userdel -r 用户名删除用户
[zyj@localhost ~]$ su -
密码:GNOME桌面设置时的密码
[root@localhost ~]# passwd hadoop
passwd:未知的用户名 hadoop。
[root@localhost ~]# useradd hadoop
[root@localhost ~]# passwd hadoop
更改用户 hadoop 的密码 。
新的 密码:123456
无效的密码: 密码少于 8 个字符
重新输入新的 密码:123456
passwd:所有的身份验证令牌已经成功更新。
修改sudo配置文件
vim /etc/sudoers打开sudo的配置文件
插入一下内容,给hadoop配置免密sudo
root ALL=(ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL
- 文本操作
| 命令 | 解析 |
|---|---|
| i | 进入编辑文本模式 |
| Esc | 退出编辑文本模式 |
| :w | 保存当前修改 |
| :q | 不保存退出vi |
| :wq | 保存当前修改名退出vi |
若出现:已设定选项 ‘readonly’ (请加 ! 强制执行)
在后面加入
!即可,例如:wq!
- 编辑时行间跳转
跳转到文件的首行:普通模式下 gg
跳转到文件的尾行:普通模式下 G
跳转到指定行:普通模式100gg或者100G|命令模式下跳转到指定行::100
跳转到文件的50%:普通模式50%
查找关键字:命令模式/查找内容,输入n向后查找,输入N向前查找
创建文件夹,修改属主
mkdir -p /tmp/dir1/dir2创建一个目录树|mkdir dir1创建dir1目录|mkdir dir1 dir2同时创建两个目录
ls查看目录|ls -l显示详细信息|ls -a显示隐藏文件|ls -lrt按时间显示文件,l详细列表,r反向排序,t时间排序
chown修改属主change owner|chown -R 用户名:组名 ./|chown -R hadoop:hadoop /opt/apps|chown :mail
[root@localhost ~]# mkdir -p /opt/apps
[root@localhost ~]# ls
anaconda-ks.cfg initial-setup-ks.cfg
[root@localhost ~]# ls -l /opt/apps
总用量 0
[root@localhost ~]# chown -R hadoop:hadoop /opt/apps
[root@localhost ~]# ll
总用量 8
-rw-------. 1 root root 1587 1月 15 02:50 anaconda-ks.cfg
-rw-r--r--. 1 root root 1635 1月 15 02:55 initial-setup-ks.cfg
安装JDK
root目录下导入jdk-8u171-linux-x64.tar.gz文件,此文件适用于UNIX系统
题外话
压缩命令:tar -zcvf 压缩文件名 .tar.gz 被压缩文件名
解压命令:tar -zxvf 压缩文件名.tar.gz
- 安装lrzsz:
sudo yum -y install lrzsz。rz上传或直接拖动,sz 要下的文件回车。lrzsz是一个unix通信套件提供的X,Y,和ZModem文件传输协议,可以用在windows与linux 系统之间的文件传输,体积小速度快,可替代ftp。 - 移动
mv jdk-8u171-linux-x64.tar.gz /opt/apps
[root@localhost ~]# sudo yum install lrzsz
已加载插件:fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* base: mirrors.163.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
base | 3.6 kB 00:00
extras | 2.9 kB 00:00
updates | 2.9 kB 00:00
(1/4): extras/7/x86_64/primary_db | 222 kB 00:00
(2/4): base/7/x86_64/group_gz | 153 kB 00:00
(3/4): base/7/x86_64/primary_db | 6.1 MB 00:01
(4/4): updates/7/x86_64/primary_db | 4.7 MB 00:01
软件包 lrzsz-0.12.20-36.el7.x86_64 已安装并且是最新版本
无须任何处理
[root@localhost ~]# mv jdk-8u171-linux-x64.tar.gz /opt/apps
xshell远程主机
xshell下载地址
连接虚拟机

连接后输入命令即可使用
【Ctrl+Alt+F】文件传输【XFTP】