大数据开发环境搭建番外及总结:Redis和Anaconda环境的安装搭建
1. 写在前面
最近学习推荐系统, 想做一个类似于企业上的那种推荐系统(采用的阿里天池赛的一个电商数据集, 然后基于大数据的Lambda架构, 实现离线和在线相结合的实时推荐系统), 这样可以熟悉一下真实环境中的推荐系统流程, 但是这里面需要大数据的开发环境, 所以这里的这个系列是记录自己搭建大数据开发环境的整个过程, 这里面会涉及到Hadoop集群,Spark, zookeeper, HBase, Hive, Kafka等的相关安装和配置,当然后面也会整理目前学习到的关于前面这些东西的相关理论知识和最终的那个推荐系统, 经过这一段时间的摸索学习, 希望能对大数据开发和工业上的推荐系统流程有个宏观的初识,这一块涉及到技术上的细节偏多, 所以想记录一下, 方便以后查看和回练, 开始
上一篇安装完了两个有关日志采集的两个工具flume和kafka, 基本上已经把这一整套环境搭建完毕,今天这篇文章算是番外了, 进行Redis和Anaconda环境的安装, 如果想实现上面的推荐系统, 仅仅有大数据环境还不行, 还需要Python的环境,所以需要安装一个anaconda统一管理Python的一些运行环境, 然后还想配置一个远程jupyter来使用服务器的的Python环境, 还有就是希望这个远程的jupyter再能使用服务器的大数据环境,也就是通过pyspark来完成分布式的计算, 之前已经用pycharm实现了这个过程,这里再基于jupyter搞一下。 由于上面的实时推荐部分还需要用到Redis,这是一个高性能的key-value数据库,非常适合海量数据库的读写,常用类配合关系型数据库做高速缓存的工作,所以这个这次也要安装一下子。
开启三台, 开启Hadoop集群,然后开始。
2. Redis的环境安装与搭建
安装Redis,和我们之前安装大数据的其他框架基本一致,一开始还是三步走:
tar -zxvf redis-3.0.4.tar.gz
sudo mkdir /opt/bigdata/redis
sudo mv redis-3.0.4 /opt/bigdata/redis/redis3.0
这个东西注意不用配置环境变量, 我们进入到redis3.0目录下,然后执行make命令:
cd /opt/bigdata/redis/redis3.0
make
由于我机器里面已经装了gcc编译器, 所以运行命令,直接一路成功了, 如果没有gcc的话,会报错,这时候需要装一下:
#能联网
yum install gcc
yum install gcc-c++
# 然后清空之前的安装结果
make distclearn
# 再重新安装
make
他们说默认的安装路径: /usr/local/bin目录,但是我的find了一下,我的不是, 在redis3.0/src下面,所以后面执行命令的之后,我得切换到这个目录。然后输入命令:
cd /opt/bigdata/redis/redis3.0/src
# 启动Redis的服务器端
redis-server
# 最好设置成后台启动服务端, 这时候需要先改一下Redis的配置文件 redis.conf
sudo gedit redis.conf
# 把里面的daemonize的选项改成yes,保存退出
# 启动Redis的服务器端
cd .. # 切换到redis3.0下面
src/redis-server redis.conf # 后面指定配置文件即可, 如果不是redis3.0目录,需要写全路径
# 这时候可以ps看一下是否启动了
ps -ef | grep redis
可以看到我这里Redis服务器端启动:

下面开启客户端:
src/redis-cli -h master -p 6379 # 后面是主机名和端口号, 不加的话会使用默认的
测试一下:

关闭的时候,是在客户端里面shutdown或者在命令行: src/redis-cli shutdown, 这样就通过客户端关闭了服务器端。
这个东西具体还没有学,不大会玩,后期如果用到的时候再详细记录一下, 这里就安装成功了, 接下来再介绍一款工具叫做Redis Desktop Manager(RDM), 这个软件可以到这里下载,这是一个简单快速,跨平台的Redis桌面管理工具, 这个在Windows上安装,然后管理master上的Redis数据库,我下载了一下,然后连接到了我的master的Redis,但是不太会用,先放个图,后面做推荐的时候会用到这个东西:

好了,关于Redis就整理到这里了。下面是Anaconda环境的安装搭建及配置远程jupyter,然后用jupyter连接pyspark。
这里多说一点,就是如果想给Redis加密码的话也可以, 这样如果想访问Redis,就需要输入密码,但这个不针对用户,也就是只要输入这个密码就能用,而不管是谁。 这个密码添加的方式是redis.conf文件里面,在里面搜索requirepass foobared, 在这后面加入密码即可:

这时候, 如果是用Windows上的这个软件连接的话,得事先配置好密码,看一下:
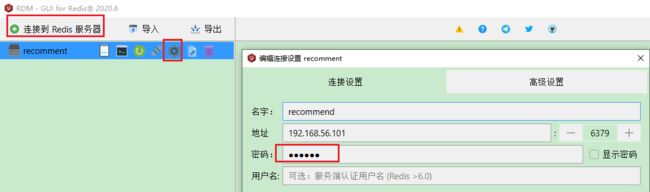
这里我只是为了玩玩, 这时候如果是从命令行里面连接的话,进去之后得需要先输入 auth 密码,然后才能正常使用,否则报错NOAUTH Authentication required.
3. Anaconda环境搭建
3.1 Anaconda安装
这个相对来说就简单很多了,可以去Anaconda官网下载相应的Linux安装包,我们这里也是提前下载好了,这个直接是可执行的文件,我们找到这个安装包的位置,输入命令, 这个得切换成root,否则在根目录下安装的话icss用户权限不够:
bash Anaconda3-2020.07-Linux-x86_64.sh
由于这一整套是基于大数据的,所以我这里的安装路径依然选择了/opt/bigdata/, 这样,有关于整套大数据的东西就都放在一块了
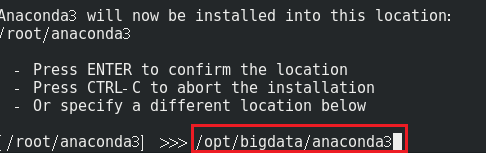
这时候等待安装完毕即可。
接下来配置环境变量,三步走:
gedit /etc/profile
# 加入anaconda的安装目录下面的命令
export PATH=$PATH:/opt/bigdata/anaconda3/bin
source /etc/profile
这样, 我们就能进入anaconda了。输入Python,结果发现,自带的Python2.7.5, 这不行啊,于是乎,一言不合就整, 把默认的改成anaconda中的Python版本, 这个也很简单,就是把/usr/bin/python的软连接改成anaconda/bin下的Python即可。输入下面命令:
ln -s /opt/bigdata/anaconda3/bin/python /usr/bin/python
# 如果报错说已经有了,删除掉之前的
这时候,就是Python3.8了, 下面我们进入anaconda,输入命令, source activate , 然后新建立一个虚拟环境叫做bigdata_env,然后装上jupyter notebook即可。Python版本用的3.7
source activate
conda env list
conda create -n bigdata_env python=3.7
conda activate bigdata_env
这样就齐活了。

后面就是具体的anaconda的使用了,这里不说。
3.2 远程jupyter notbook的连接
下面安装jupyter notebook,pip install jupyter notebook, 装上之后,就可以使用jupyter notebook命令来进行启动,但是如果是用xshell远程连接服务器的话,使用这个命令会不好使,因为网页是在本地打开的, 所以我们需要配置远程jupyter的使用。
这时候,首先生成jupyter的配置文件:
jupyter notebook --generate-config(在虚拟环境里运行)
# 生成密文
python
# 进入编程环境
from notebook.auth imoprt passwd
passwd()
# 然后输入铭文 即密码即可
生成密文如下:

把这串密文复制,然后修改jupyter notebook的配置文件: gedit /root/.jupyter/jupyter_notebook_config.py, 修改下面这几项:
c.NotebookApp.ip='*' #表示同一网络的主机都可访问
c.NotebookApp.password = 'argon2:$argon2id$v=19$m=10240,t=10,p=8$6m/iOXxUHX2qNlP0c928vg$rR7yP5czsw5U/n6Qy0q2dg' # 上面的密文
c.NotebookApp.password_required = True
c.NotebookApp.open_browser = False # 本地不用打开,远程访问即可
c.NotebookApp.port =8890 #随便指定一个端口(这个需要看是不是冲突)
这时候再输入:

这时候,从本地Windows上输入网址:http://192.168.56.101:8890, 输入密码就可以远程登录了。
Linux里面如果想改变jupyter打开的根目录,不像Windows那么麻烦,在哪个目录下面运行jupyter,打开的默认就会是哪个目录,这么说应该懂了,在有代码的地方运行jupyter就可以了。 当然也可以多用户连接,这个具体参考这篇文章
3.3 远程jupyter用远程的pyspark环境
这个事情之前我也记录过一次,只不过是用pycharm搞的,具体干的事情可以参考这篇文章,这里我们用jupyter再玩一遍,因为这个后面推荐系统会用到, 关于本地服务器运行pyspark程序的这个,这里不再详细介绍了,看上面的连接。
我这里了依然尝试运行了一下命令行的wordcount程序,在master上直接输入pyspark,我这里竟然能直接进入pyspark, 和上面博客里面不一样的是我这里的spark版本,python版本和Hadoop版本都变了。
输入
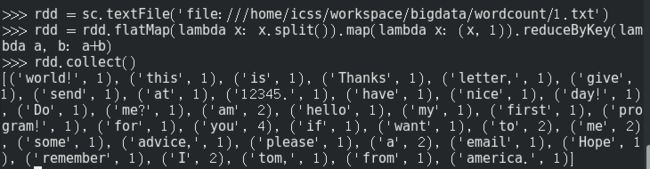
sc = SparkContext('local[2]', 'wordcount')
rdd = sc.textFile('file:///home/icss/workspace/bigdata/wordcount/1.txt').flatMap(lambda x: x.split()).map(lambda x: (x, 1)).reduceByKey(lambda a, b: a+b)
rdd.collect()
迎来了第一个报错:TypeError: an integer is required (got type bytes), 这个错误的原因是因为spark和Python的版本对应不上, spark是2.2的,而Python是3.8多,spark不支持这么高的版本,于是需要把Python降到3.7或者以下, 于是我这里修改了默认的Python版本,用了我上面建立的虚拟环境bigdata_env里面的Python环境,结果这个错误搞定。关于Linux上修改默认的Python版本, 就是修改/usr/bin/python的链接位置,之前链接的是anaconda3/bin/python, 这里面的Python是3.8的,这时候,需要把这个软连接改成/anaconda3/envs/bigdata_env/bin/python, 这个是3.7的。
# 删除原来的链接 /usr/bin目录
rm python
# 把anaconda3/envs/bigdata_env/bin/加入到环境变量,否则找不到这个python的
# 配置环境变量
# 新建立软连接
ln -s /opt/bigdata/anaconda3/envs/bigdata_env/bin/python python
# 搞定
这时候迎来了第二个报错:ValueError: Cannot run multiple SparkContexts at once; existing SparkContext,这是因为之前已经开了一个sparkContext了,需要先停掉前面那个,输入sc.stop,然后再运行即可。
如果想在anaconda里面的bigdata_env里面运行pyspark的话,就需要把pyspark配置到环境变量里面,修改环境变量,加上这句:
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/pyspark:$SPARK_HOME/python/lib/pyspark.zip:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
生效即可。这样,在本地的服务器anaconda可以使用pyspark了。
下面在/home/icss/workspace/bigdata/wordcount目录下,开启,然后Windows下输入网址进行访问:
source activate # 进入anaconda环境
conda activate bigdata_env # 激活bigdata_env环境
cd ~/workspace/bigdata/wordcount # 进入目录
# 切换root身份,因为之前设置jupyter notebook配置的时候,是用root设置的,如果用普通用户打开的话,配置不管用了
su
jupyter notebook --allow-root # 打开远程notebook
新建立一个Python3文件,然后尝试导入pyspark。会报错ModuleNotFoundError: No module named 'pyspark', 上面在命令行的时候明明导入了呀。所以在前面需要指定一下spark的路径, spark里面的python路径, py4j这个。
import os
import sys # sys.path是python的搜索模块的路径集,是一个list
os.environ['SPARK_HOME'] = '/opt/bigdata/spark/spark2.2'
sys.path.append('/opt/bigdata/spark/spark2.2/python')
sys.path.append('/opt/bigdata/spark/spark2.2/python/lib/py4j-0.10.4-src.zip')
这样就搞定了。这时候大功告成, 这个要比pycharm那个简单一些的。
4. 总结一下
到这里,基本上大数据开发环境搭建就结束了, 下面来简单的梳理总结一下。
搭建这一整套环境花费了我整整4天时间, 除去中间开组会用了一上午,做了两次核酸的时间,其他时间基本上全在搭这套环境,这次完全从0开始,安装虚拟机,操作系统, 做准备工作,然后开始搭建Hadoop集群, 玩了一下单机版和集群版, 接下来是Spark集群,尝试了三种运行spark的模式。 然后是Zookeeper和HBase的环境搭建, 搞定了一个协调应用程序工作的和一个面向列的数据库, 然后是MySQL, Hive和Sqoop, 安了数据库和数据仓库, 然后是两个日志采集相关的Flume和kafka, 最后是这篇番外,安装了Redis和anaconda, 这两个是完成后面的推荐系统附加的两个环境,也正好放到一块了。有了这些基础准备, 后面才可以基于一个真实的数据集玩一个电商广告的推荐,这个我是看的B站上的一个视频(但没有他的课件和环境,于是只能自己先摸索一套才能玩),通过这个实时的推荐项目就可以把前面的所有东西给串起来。
Lambda架构是一个为离线计算和实时计算提供服务的一个架构。
离线计算的框架:
- Hadoop, hdfs, MapReduce
- spark core, spark SQL
- hive
实时的计算框架:
- spark streaming
- storm
- flink
消息中间件:
- flume
- kafka
整个推荐系统的流程可以简单概括成下面这样:
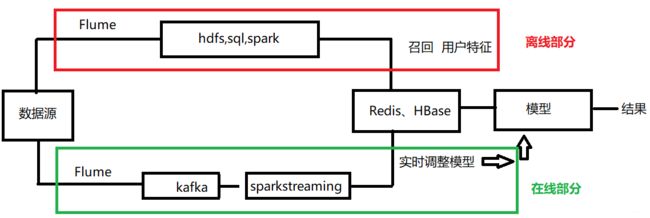
通过这个就可以看到我们之前搭建的环境在整个流程中所起的作用了。
这4天的时间,感觉过的太快了实在是, 除了这套环境,啥也没做,其他任务都停滞了,但也有收获,就是通过这一整套环境的搭建,第一个是熟悉了Linux系统,之前对Linux系统是比较反感的,但是这几天下来给我的感受是Linux确实是好用且简洁,这可能是对于通过练习对命令的熟练和对目录系统的理解了。 第二个是知道了这些组件之间的配合原理(宏观层面), 通过修改各种环境变量啥的,大致上对于各个组件的运行和配合有了一个理解, 程度是大致上知道如果某个地方运行出错是哪里的原因,应该调什么设置了。 第三个就是心里承受能力加强,这可多亏了这四天遇到的坑, 各种坑,有时候也挺崩溃,但是解决了问题之后的快感是真的爽,现在导致遇到错误反而有一种小激动,这样能够多学一些东西了,虽然可能换了版本,换了系统等这些错误的解决没有用,但我觉得应该不是没有用, 我回想了一下我遇到的这些坑, 包括网卡,ip配置的问题(Mac与配置里面的要匹配), SSH免密连接问题, Hive使用前元数据的初始化, mysql安装遇到的相干问题(这个会揭示Centos系统的一些默认特点,mysql的保存等),Hive启动卡住的问题(如何查看日志)等,版本不兼容等。 这些坑我觉得即使在真实环境下也都用得到,至少很多东西背后的逻辑都是不变的,毕竟设计这些东西,写代码的都是人,思想虽然不一致,但肯定有相同的地方哈哈。
这4天接触了各种环境变量配置, 各种连接,各个组件的配置,编写shell脚本,各种Linux命令,软件安装,建立软连接等,发现其实安装这些组件背后都有着差不多的逻辑,首先就是三步走(为了安装),然后修改环境变量(方便找), 然后就是修改自身配置(为了和别的组件通信,这里面会配置自己的一些东西,方便别的组件找到,然后就是配置一些找到别人的东西)。 目前反正我遇到这些组件都是这样的逻辑。 无非就是每一步里面的操作不同罢了。 然后就是一些常用的Linux命令要熟记于心:
- 目录文件操作:
cd, cp, mv, mkdir, mkdir -p, rm -r, rm, rm -rs, 建目录,复制,粘贴,重命名等 - 文件操作:
touch(建立文件),vi, gedit(编辑文件),cat(查看文件) - 查找文件位置:
find, locate - 解压和压缩:
tar -zxvf, tar -zcvf,unzip - 查看进程:
ps -ef | grep相应的进程, top - 服务相关:
service 服务 start , stop - 权限相关:
chmod, chown - 还有一些附加:
ssh,scp, df -h, pwd, ls, ll, su, yum, ln, ping, ip addr, ifconfig, shutdown, reboot, wget
这些挺常用的, 这4天的时间借机会摸了一下, shell脚本同时搞3台机器也体验了一下, 逐渐的感觉到了Linux的魅力所在, 更加有意思的事情是这4天的业余时间看完了红楼梦的解说,也感受到了红楼梦的魅力,并喜欢上了Linux和红楼梦, 这两个都是来源于好奇心, 但真的接触之后发现确实好,Linux好,红楼梦也好,都好都好, 哈哈。
这4天在学习和生活上都体验了一波完全不一样的事情,接下来的一段时间,会做一个实时推荐系统的项目, 会尝试整理关于上面各个组件的理论知识和细节, 会回到推荐系统算法层面, 会回到之前的轨道上, 这四天算是小插曲了, 撤