TensorFlow初步-张量的基本运算
TensorFlow简介:https://tensorflow.google.cn/
一. TensorFlow内的基本概念
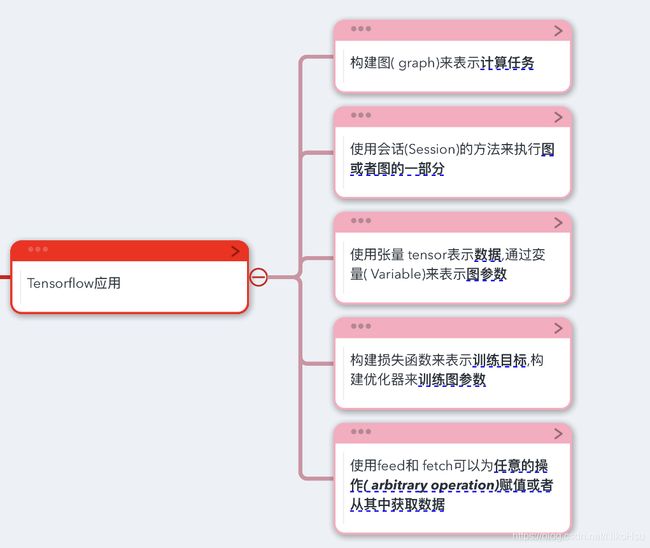
图的构建
1.初始化图
tf.reset_default_graph()
用于清除默认图形堆栈并重置全局默认图形.
2.构建新的图
g1 = tf.Graph()
g2 = tf.Graph()
3.在图中定义张量
with g1.as_default():
a = tf.constant([1.0, 1.0])
b = tf.constant([1.0, 1.0])
result1 = a + b
会话
一个Session对象封装了Operation执行对象的环境
1.构建会话
tf.Session() #使用系统默认的图
tf.Session(graph=g1) #指定图
2.初始化
__init__(target='', graph=None, config=None)
•target:(可选)要连接到的执行引擎.默认使用进程内引擎. 如:’/cpu:0’,’/gpu:0’
•graph:(可选)将被启动的Graph(如上所述).
•config:(可选)具有session配置选项的ConfigProto协议缓冲区
3.会话运行
运行
run(fetches, feed_dict=None, options=None,
run_metadata=None)
• fetches: 需要运行的图形元素,可以是一个单一的图形元素,或任意嵌套
张量列表、 元组、namedtuple、字典、或含有它的叶子图表元素OrderedDict.
• feed_dict: 是一个字典,运行前从外部赋给图中张量的值。
• options: 一个[ RunOptions]协议缓冲区. • run_metadata:一个[ RunMetadata]协议缓冲区.
4.会话类的其他方法
关闭.
close()
关闭这个session.释放与session关联的所有资源. • tf.Session().as_default()创建一个默认会话,当上下文管理器退出时会
话没有关闭,还可以通过调用会话进行run()和eval()操作
• 列出设备
list_devices()
• 部分执行
partial_run ( handle, fetches, feed_dict=None)
tf.Session()创建一个会话,当上下文管理器退出时会话关闭和资源释放自动完成。
二. 张量的声明

常量声明
tf.constant(value, dtype=None, shape=None, name='Const',verify_shape=False)
t1=tf.constant(1.0) #一个零维的常数张量
t1=tf.constant([1, 2]) #一个一维的常整数张量
t2=tf.constant([1, 2], dtype=tf.float32) #一个一维的常浮点数张量
t3=tf.constant(-1, shape=[2, 3]) #一个2维张量
t4=tf.constant([1, 2, 3, 4, 5, 6, 7], shape=[2, 3]) #一个2维张量
其他常量申明函数
tf.zeros(shape, dtype=tf.float32, name=None)
tf.zeros_like(tensor, dtype=None, name=None)
tf.ones(shape, dtype=tf.float32, name=None)
tf.ones_like(tensor, dtype=None, name=None)
tf.fill(dims, value, name=None)
a = tf.zeros([2, 3], dtype=tf.int32)
b =tf.ones_like(a, dtype=tf.float32)
a = tf.ones([2, 3], dtype=tf.float32)
b = tf.fill([2, 3, 4], 5)
随机量申明
random_uniform(shape, minval=0, maxval=None,
dtype=tf.float32, seed=None, name=None)
生成的值在该 [minval, maxval) 范围内遵循均匀分布.下限 minval 包含在范围
内,而上限 maxval 被排除在外.
如
t1=tf.random_uniform( (6,6), minval=-0.5, maxval=0.5,dtype=tf.float32)
random_normal( shape, mean=0.0, stddev=1.0,
dtype=tf.float32, seed=None, name=None)
shape:一维整数张量或 Python 数组.输出张量的形状.
mean:dtype 类型的0-D张量或 Python 值.正态分布的均值.
stddev:dtype 类型的0-D张量或 Python 值.正态分布的标准差.
dtype:输出的类型.
seed:一个 Python 整数.用于为分发创建一个随机种子.
name:操作的名称(可选).
如
tf.random_normal([2, 3], stddev=1, seed=1)
变量声明
tensorflow中的变量是通过Variable类来实现的,类初始化函数为
tf.Variable() __init__(self, initial_value=None, trainable=True,
collections=None, validate_shape=True, caching_device=None,
name=None, variable_def=None, dtype=None,
expected_shape=None, import_scope=None)
v1 = Variable(tf.zeros([100]))
v2= Variable(tf.random_uniform((6,6), minval=-0.5, maxval=0.5,
dtype=tf.float32))
变量申明参数.
initial_value: 变量的初始值
trainable: 如果为True,会把它加入到GraphKeys. TRAINABLE_VARIABLES,才能对它使用Optimizer
collections: 指定该图变量的类型、默认为[GraphKeys.GLOBAL_VARIABLES]
validate_shape: 如果为False,则不进行类型和维度检查
name: 名字
创建变量的其他方法
get_variable(name, shape=None, dtype=None, initializer=None,
regularizer=None, trainable=True, collections=None,
caching_device=None, partitioner=None, validate_shape=True,
use_resource=None, custom_getter=None)
共享变量的方法
with tf.variable_scope("scope1"): # scopename is scope1
w1 = tf.get_variable("w1", shape=[])
w2 = tf.Variable(0.0, name="w2")
with tf.variable_scope("scope1", reuse=True):
w1_p = tf.get_variable("w1", shape=[])
w2_p = tf.Variable(1.0, name="w2")
print(w1 is w1_p, w2 is w2_p) # True False.
指定变量的前缀
tf.variable_scope
• __init__( name_or_scope, default_name=None, values=None,
initializer=None, regularizer=None, caching_device=None,
partitioner=None, custom_getter=None, reuse=None, dtype=None,
use_resource=None, constraint=None, auxiliary_name_scope=True)
其中reuse 参数规定tf.get_variable的功能, 可以是True、None或tf.AUTO_REUSE
如果是True, tf.get_variable只能重用,不能创建;
如果是tf.AUTO_REUSE,则tf.get_variable创建变量(如果它们不存在),否则返回它们;如果是None,则继承父范围
的重用标志.
推荐使用tf.AUTO_REUSE
三. 张量的四则运算
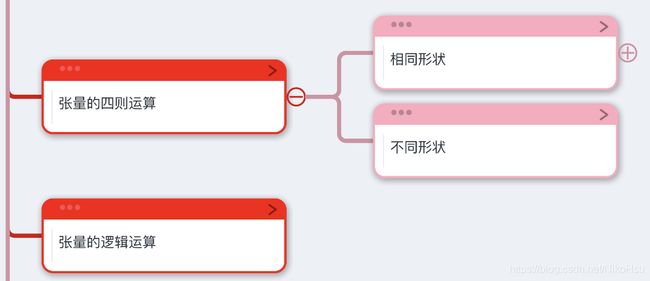
四则运算
1.相同形状的张量
a = tf.constant([1, 2, 3])
b = tf.constant([4, 5, 6])
c=a+b
c=a-b
c=a*b
c=a/b #结果为浮点数
c=a//b #整数除法
c=a**2
最基本的加减乘除,没有什么好说的
2.不同形状的张量
张量维度不同时,要注意python有一个广播机制(broadcaing)
如,一维张量与二维向量相加时,一维向量中每个元素会与二维向量中最小的那个维度中的每个元素逐个相加,前提条件就是两个张量最后一个维度的长度必须相等。多维也同理。
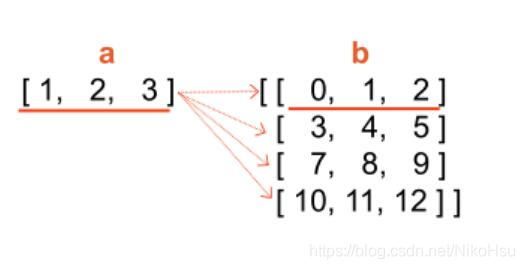
a = tf.constant([1, 2, 3])
b = tf.constant([1])
c=a+b
print(c) #tf.Tensor([2 3 4], shape=(3,), dtype=int32)
逻辑运算
tf.bitwise.bitwise_and( x , y , name = None )#与运算
tf.bitwise.bitwise_or( x , y , name = None )#或运算
tf.bitwise.bitwise_xor( x , y , name = None )#异或运算
tf.bitwise.invert ( x , name = None )#取反
tf.bitwise.left_shift( x, y, name=None)#左移,y为左移位数。
四. 张量的拼接,拆分
拼接
tf.concat( values, axis, name='concat')
t1 = [[1, 2, 3], [4, 5, 6]]
t2 = [[7, 8, 9], [10, 11, 12]]
t3=tf.concat([t1, t2], 0) #4x3
t4=tf.concat([t1, t2], axis=1) #2x6
axis表示拼接的维度,例如等于0,就表示按行拼接,2个2行的张量变成了4行。
拆分
tf.split(value, num_or_size_splits, axis=0, num=None, name='split')
# 'value' is a tensor with shape [5, 30]
# Split 'value' into 3 tensors with sizes [4, 15, 11] along dimension 1
split0, split1, split2 = tf.split(value, [4, 15, 11], 1)
tf.shape(split0) # [5, 4]
tf.shape(split1) # [5, 15]
tf.shape(split2) # [5, 11]
张量的数学函数
tf.abs, tf.acos, tf.asin, tf.atan,tf.atan2,tf.ceil, tf.cos,
tf.exp, tf.log, tf.pow,tf.round,tf.rsqrt,
tf.square, tf.sqrt ,tf.sin,tf.sign,
tf.sigmoid, tf.tan, tf.tanh
四. 张量的统计函数,优化器
张量的统计函数
reduce_mean(
input_tensor, axis=None, keep_dims=False, name=None,
reduction_indices=None)
'''
input_tensor: 被统计的张量
axis: 需要统计的指定维,如果没有,统计所有维。
keep_dims: 是否保持原来的形状。
'''
# 'x' is [[1., 1.]
# [2., 2.]]
tf.reduce_mean(x) ==> 1.5
tf.reduce_mean(x, 0) ==> [1.5, 1.5]
tf.reduce_mean(x, 1)
'''
其他统计函数
'''
reduce_max,
reduce_min,
reduce_sum,
reduce_sum,
reduce_prod
张量的亚当优化器
1.初始化
__init__( learning_rate=0.001, beta1=0.9, beta2=0.999,
epsilon=1e-08, use_locking=False, name='Adam')
learning_rate: 学习速率
beta1: . 冲量的幂衰减系数
beta2: 二阶冲量的幂衰减系数
2.最小化方法
minimize(loss, global_step=None, var_list=None,
gate_gradients=GATE_OP, aggregation_method=None,
colocate_gradients_with_ops=False, name=None, grad_loss=None)
'''
loss: 损失函数
global_step: 更新次数
var_list: 需要训练的参数
gate_gradients:梯度的计算方法
aggregation_method: Specifies the method used to combine gradient terms..
colocate_gradients_with_ops: If True, try colocating gradients with the corresponding op.
'''
熟悉了张量的基本计算就可以去读生成对抗网络的源码啦
源码阅读笔记-DCGAN 生成对抗网络model.py main.py
https://zhuanlan.zhihu.com/p/335801090