video object segmentation(VOS)论文目录 2020
video object segmentation
- 2020 AAAI
-
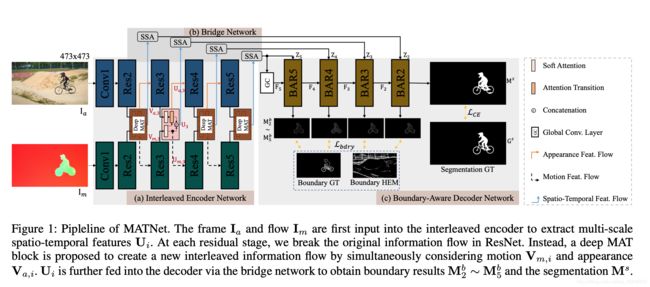
- 1. Motion-Attentive Transition for Zero-Shot Video Object Segmentation(Z-VOS)
- 2020 CVPR
-
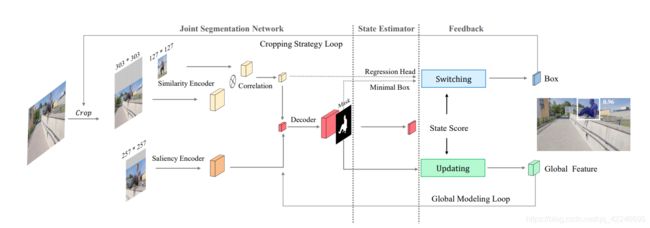
- 1. State-Aware Tracker for Real-Time Video Object Segmentation
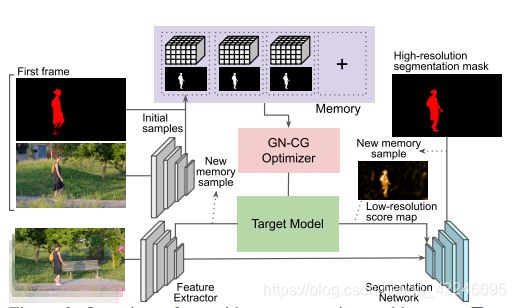
- 2. Learning Fast and Robust Target Models for Video Object Segmentation
- 3. A Transductive Approach for Video Object Segmentation
- 4. Fast Video Object Segmentation With Temporal Aggregation Network and Dynamic Template Matching
- 5. Learning Video Object Segmentation From Unlabeled Videos
- 6. Classifying, Segmenting, and Tracking Object Instances in Video with Mask Propagation
- 7. Fast Template Matching and Update for Video Object Tracking and Segmentation
- 8. Memory Aggregation Networks for Efficient Interactive Video Object Segmentation
- 相关
- 2020 ECCV
-
- 1. Video Object Segmentation with Episodic Graph Memory Networks(spotlight Z-VOS and O-VOS)
- 2. Learning What to Learn for Video Object Segmentation(oral O-VOS)
- 3. TENet: Triple Excitation Network for Video Salient Object Detection(spotlight)
- 4. Collaborative Video Object Segmentation by Foreground-Background Integration(spotlight O-VOS)
- 5. Learning Object Depth from Camera Motion and Video Object Segmentation
- 6. Learning Discriminative Feature with CRF for Unsupervised Video Object Segmentation
- 7. Kernelized Memory Network for Video Object Segmentation(O-VOS)
- 8. Interactive Video Object Segmentation Using Global and Local Transfer Modules
- 9. URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark
- 10. Unsupervised Video Object Segmentation with Joint Hotspot Tracking
- 11. ScribbleBox: Interactive Annotation Framework for Video Object Segmentation
- 12. Fast Video Object Segmentation using the Global Context Module(O-VOS)
- 相关
- 2020 BMVC
-
- 1.Making a Case for 3D Convolutions for Object Segmentation in Videos
- 2020 NIPS
-
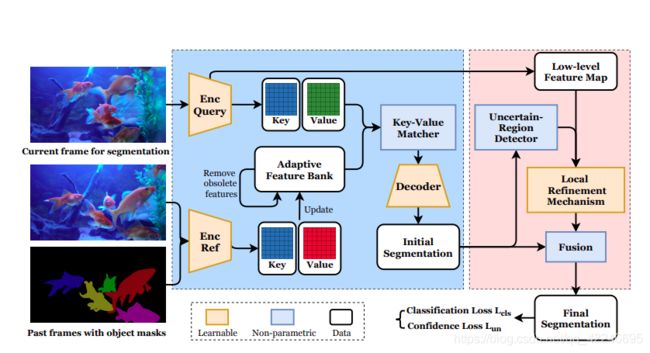
- 1. Video Object Segmentation with Adaptive Feature Bank and Uncertain-Region Refinement
之前的2017-2019年论文会逐渐陆续添加上,自己的一些论文翻译和总结也会陆续整理上来。
(linux下的指标对齐,但是windows下的指标对不齐。。)
2020.08.24 为ECCV 7 和 12加入了整理的阅读笔记。
2020.08.30 加入BMVC 2020以及阅读笔记
近些年里,跟视频相关的任务逐渐增多,从之前的 Video Classification到后来的 Video Object Segmentation,相关任务还有很多:
Video Captioning/ Video Object Detection
Video Super-Resolution/ Video Instance Segmentation
Video Denoising/ Video Action Recognition
Video Frame Interpolation/ Video Inpainting
2020 AAAI
1. Motion-Attentive Transition for Zero-Shot Video Object Segmentation(Z-VOS)
链接: arxiv.
2020 CVPR
1. State-Aware Tracker for Real-Time Video Object Segmentation
Xi Chen, Zuoxin Li, Ye Yuan, Gang Yu, Jianxin Shen, Donglian Qi
链接: arxiv.
指标:
J&F Jmean Fmean
DAVIS 16 83.1 82.6 83.6 39FPS
DAVIS 17 72.3 68.6 76.0 39FPS
J&F Js Juns Fs Funs
YTB-VOS 63.6 67.1 55.3 70.2 61.7
2. Learning Fast and Robust Target Models for Video Object Segmentation
Andreas Robinson, Felix Jaremo Lawin, Martin Danelljan, Fahad Shahbaz Khan, Michael Felsberg
链接: arxiv.
指标:
J&F Jmean Fmean
DAVIS 16 81.7 - - 21.9FPS use DAVIS 17
(with YTB) 83.5
DAVIS 17 68.8 - -
(with YTB) 76.7
J&F Js Juns Fs Fsean
YTB-VOS 72.1 72.3 65.9 76.2 74.1
3. A Transductive Approach for Video Object Segmentation
Yizhuo Zhang, Zhirong Wu, Houwen Peng, Stephen Lin
链接: arxiv.
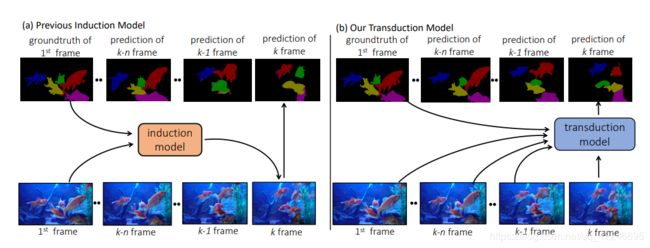
指标:
J&F Jmean Fmean
DAVIS 17 72.3 69.9 74.7 37FPS
J&F Js Juns Fs Fsean
YTB-VOS 67.8 67.1 63.0 69.4 71.6
(with DAVIS) 67.4 66.7 62.5 69.8 70.6
4. Fast Video Object Segmentation With Temporal Aggregation Network and Dynamic Template Matching
Xuhua Huang, Jiarui Xu, Yu-Wing Tai, Chi-Keung Tang
链接: arxiv.
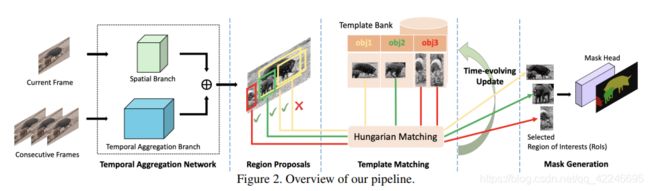
指标:
J&F Jmean Fmean
DAVIS 17 75.9 72.3 79.4 0.14t/s no YTB
STM no YTB :71.6 with YTB:81.7
5. Learning Video Object Segmentation From Unlabeled Videos
Xiankai Lu, Wenguan Wang, Jianbing Shen, Yu-Wing Tai, David J. Crandall, Steven C. H. Hoi
链接: arxiv.
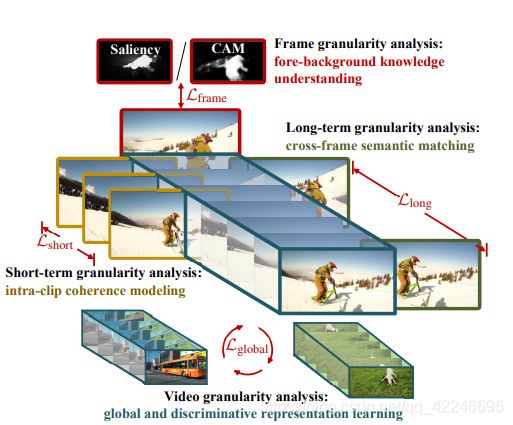
指标:
Z-VOS:
J&F Jmean Fmean
DAVIS 16 - 58.0 51.5
DAVIS 17 37.3 35.0 39.6
Jmean
YTB-Obj 57.7
O-VOS
J&F Jmean Fmean
DAVIS 16 - 63.1 61.8
DAVIS 17 56.1 54.0 58.2
6. Classifying, Segmenting, and Tracking Object Instances in Video with Mask Propagation
Gedas Bertasius, Lorenzo Torresani
链接: arxiv.
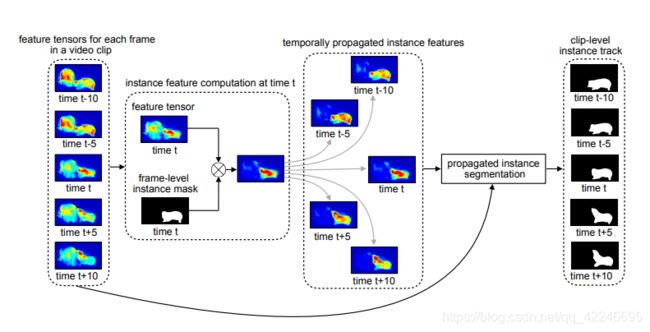
7. Fast Template Matching and Update for Video Object Tracking and Segmentation
Mingjie Sun, Jimin Xiao, Eng Gee Lim, Bingfeng Zhang, Yao Zhao
链接: arxiv.
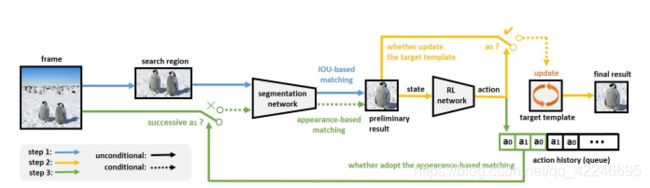
指标:
use first frame box-level ground-truth; no fine-tune
J&F Jmean Fmean
DAVIS 16 78.9 77.5 - 0.09t/s
DAVIS 17 70.6 69.1 -
Jmean
YTB-Obj 79.3
8. Memory Aggregation Networks for Efficient Interactive Video Object Segmentation
Jiaxu Miao, Yunchao Wei, Yi Yang
链接: arxiv.
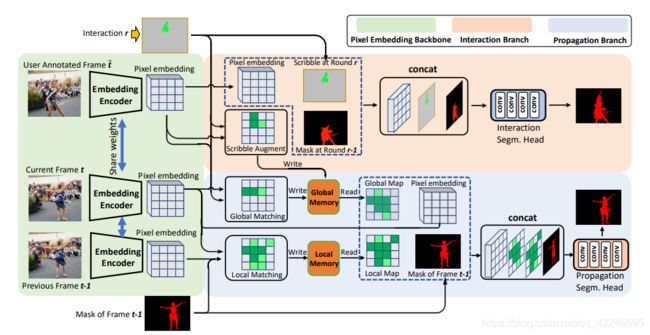
指标:
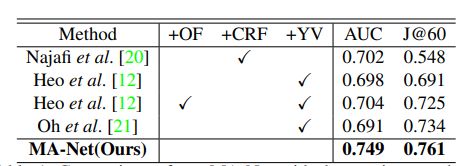
相关
(主要整理了一些关于Video Object Detection、Video Instance Segmentation和Video Captioning等分割相关的任务):
- Memory Enhanced Global-Local Aggregation for Video Object Detection
Yihong Chen, Yue Cao, Han Hu, Liwei Wang
链接: arxiv. - Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution
Xiaoyu Xiang, Yapeng Tian, Yulun Zhang, Yun Fu, Jan P. Allebach, Chenliang Xu
链接: pdf. - SmallBigNet: Integrating Core and Contextual Views for Video Classification
Xianhang Li, Yali Wang, Zhipeng Zhou, Yu Qiao
链接: arxiv. - FastDVDnet: Towards Real-Time Deep Video Denoising Without Flow Estimation
Matias Tassano, Julie Delon, Thomas Veit
链接: arxiv. - Temporally Distributed Networks for Fast Video Semantic Segmentation
Ping Hu, Fabian Caba, Oliver Wang, Zhe Lin, Stan Sclaroff, Federico Perazzi
链接: arxiv. - Syntax-Aware Action Targeting for Video Captioning
Qi Zheng, Chaoyue Wang, Dacheng Tao
链接: pdf. - Spatio-Temporal Graph for Video Captioning With Knowledge Distillation
Boxiao Pan, Haoye Cai, De-An Huang, Kuan-Hui Lee, Adrien Gaidon, Ehsan Adeli, Juan Carlos Niebles
链接: arxiv. - Visual-Textual Capsule Routing for Text-Based Video Segmentation
Bruce McIntosh, Kevin Duarte, Yogesh S Rawat, Mubarak Shah
链接: pdf. - Video Instance Segmentation Tracking With a Modified VAE Architecture
Chung-Ching Lin, Ying Hung, Rogerio Feris, Linglin He
链接: pdf. - Object Relational Graph With Teacher-Recommended Learning for Video Captioning
Ziqi Zhang, Yaya Shi, Chunfeng Yuan, Bing Li, Peijin Wang, Weiming Hu, Zheng-Jun Zha
链接: arxiv.
2020 ECCV
1. Video Object Segmentation with Episodic Graph Memory Networks(spotlight Z-VOS and O-VOS)
Xinkai Lu, Wenguan Wang, Martin Danelljan, Tianfei Zhou, Jianbing Shen, Luc Van Gool
链接: arxiv.
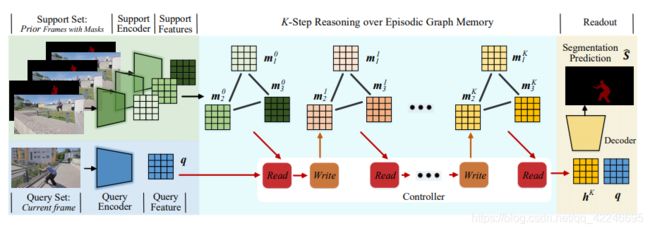
指标:
Z-VOS:use saliency dataset:MSRA10K,DUT; fine-tune on Davis16
J&F Jmean Fmean
DAVIS 16 - 82.5 81.2
Jmean
YTB-Obj 71.4
O-VOS:use saliency dataset:MSRA10K and semantic segmentation dataset:COCO;fine-tune on Davis17 and YTB-VOS
J&F Jmean Fmean
DAVIS 17 82.8 80.2 85.2 0.2s
J&F Js Juns Fs Fsean
YTB-VOS 80.2 80.7 74.0 85.1 80.9
2. Learning What to Learn for Video Object Segmentation(oral O-VOS)
Goutam Bhat, Felix Järemo Lawin, Martin Danelljan, Andreas Robinson, Michael Felsberg, Luc Van Gool, Radu Timofte
链接: arxiv.
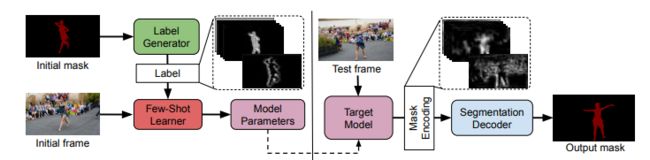
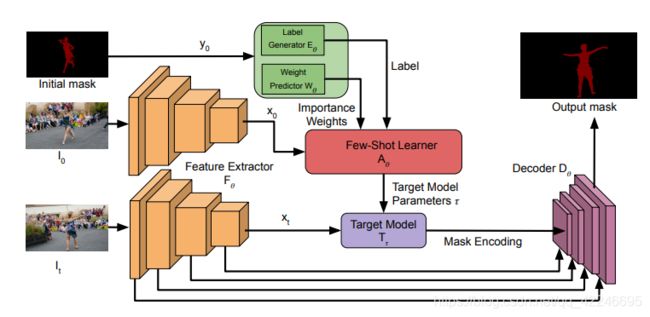
指标:
O-VOS:Davis17 and YTB-VOS 6FPS
Backbone ResNet50 from Mask-RCNN weights size: 832 * 480
J&F Jmean Fmean
DAVIS 17 74.3 72.2 76.3
With additional data 81.6 79.1 84.1
J&F Js Juns Fs Funs
YTB-VOS 80.2 78.3 75.6 82.3 84.4
With additional data 81.5 80.4 76.4 84.9 84.4
3. TENet: Triple Excitation Network for Video Salient Object Detection(spotlight)
Sucheng Ren, Chu Han, Xin Yang, Guoqiang Han, Shengfeng He
链接: arxiv.
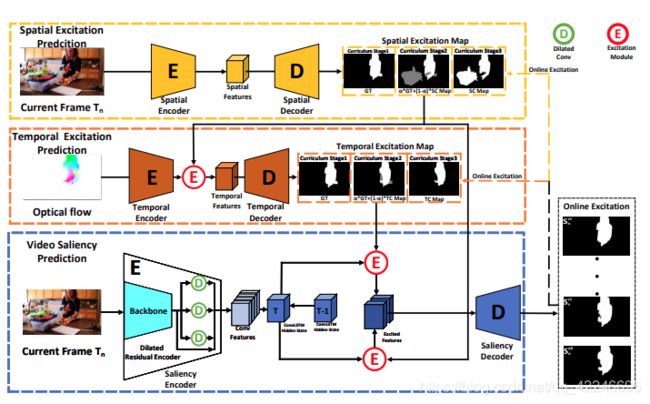
指标:
Training with three datasets DUTS, DAVIS, DAVSOD
Spatial Excitation branch with images from DUTS and DAVIS,
Temporal Excitation branch with optical flow from DAVIS and DAVSOD
the whole model with video from DAVIS and DAVSOD
论文给出的是显著性检测指标,没有Davis的J和F指标
4. Collaborative Video Object Segmentation by Foreground-Background Integration(spotlight O-VOS)
Zongxin Yang, Yunchao Wei, Yi Yang
链接: arxiv.
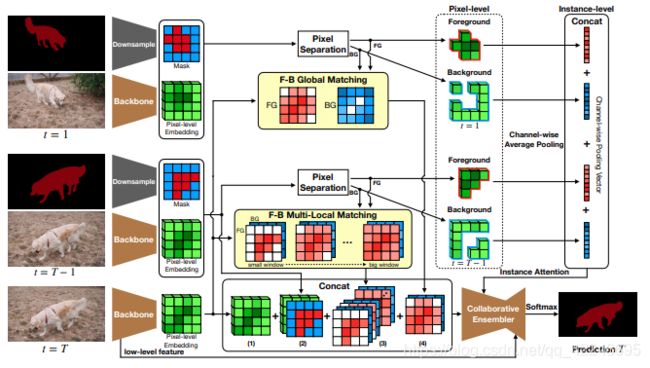
指标:
DeepLabv3+ architecture based on the dilated Resnet-101 as backbone apply batch normalization (BN) in our backbone and pre-train it on ImageNet and COCO.
Training data: Davis 2017 and YTB-VOS
with YTB: Use YTB-VOS training
with PRO:mutimulti-scale & flip strategy :
J&F Jmean Fmean
DAVIS 16 86.1 85.3 86.9 0.18t/s
(with YTB) 89.4 88.3 90.5
(with PRO) 90.7 89.6 91.7 9t/s
DAVIS 17 74.9 72.1 77.7
(with YTB) 81.9 79.1 84.6
(with PRO) 83.3 80.5 86.0
No fine-tuning at test time and no using simulated data in the training process
J&F Js Juns Fs Fsean
YTB-VOS 81.4 81.1 75.3 85.8 83.4
with mutimulti- 82.7 82.2 76.9 86.8 85.0
scale & flip strategy
5. Learning Object Depth from Camera Motion and Video Object Segmentation
Brent A. Griffin, Jason J. Corso
链接: arxiv.
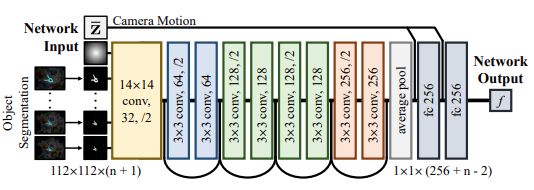
6. Learning Discriminative Feature with CRF for Unsupervised Video Object Segmentation
Mingmin Zhen, Shiwei Li, Lei Zhou, Jiaxiang Shang, Haoan Feng, Tian Fang, Long Quan
链接: arxiv.
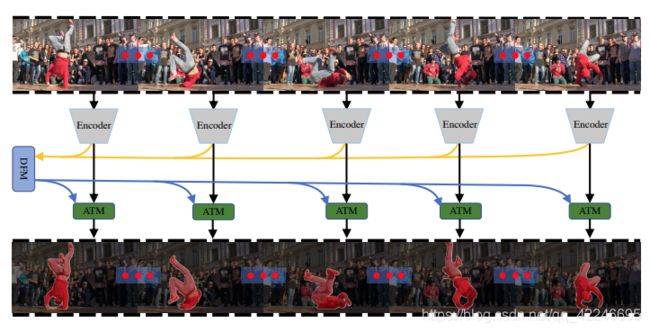
Training data:
backbone :DeepLabV3 Encoder
Image:MSRA10K, DUT;
Video:DAVIS16 DAVIS17 YTB-VOS
No fine-tuning at test time
J&F Jmean Fmean
DAVIS 16 - 83.4 81.8 0.04t/s
Fmean
FBMS 82.3
网络使用了额外的后处理里方法,follow了ICCV 19的andiff的后处理方法:
在Davis 16 80.4
+multiple scales 81.1
+I.Prun. 83.4
论文中还放了在Davis 16,FBMS,ViSal的显著性指标。
7. Kernelized Memory Network for Video Object Segmentation(O-VOS)
Hongje Seong, Junhyuk Hyun, Euntai Kim
链接: arxiv.
链接: 论文阅读.
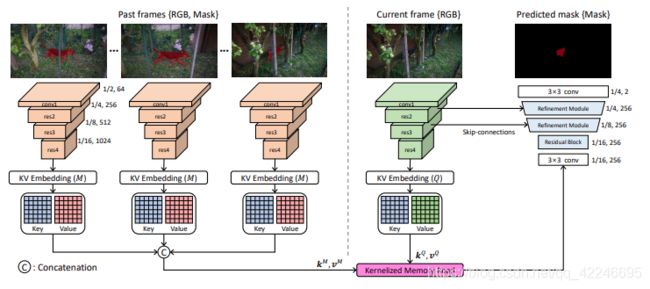
Training data:
Image:MSRA10K, ECSSD, and HKU-IS;
Video:DAVIS16 DAVIS17 YTB-VOS
No online-learning strategy at test time
DAVIS 16 J&F Jmean Fmean
Static Images 74.8 74.7 74.8 0.12s
+Davis 16 87.6 87.1 88.1
+YTB-VOS 90.5 89.5 91.5
DAVIS 17 J&F Jmean Fmean
Static Images 68.9 67.1 70.8 0.12s
+Davis 16 76.0 74.2 77.8
+YTB-VOS 82.8 80.0 85.6
J&F Js Juns Fs Fsean
YTB-VOS 81.4 81.4 75.3 85.6 83.3
8. Interactive Video Object Segmentation Using Global and Local Transfer Modules
Yuk Heo, Yeong Jun Koh, Chang-Su Kim
链接: arxiv.

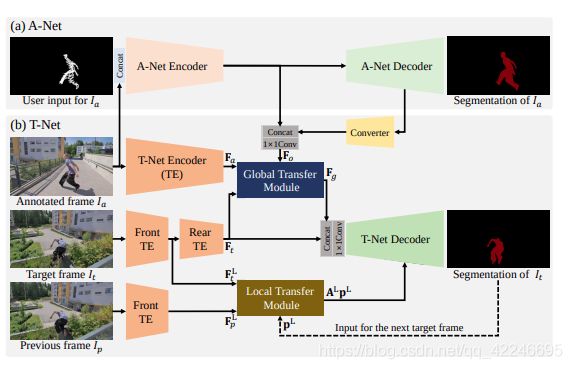
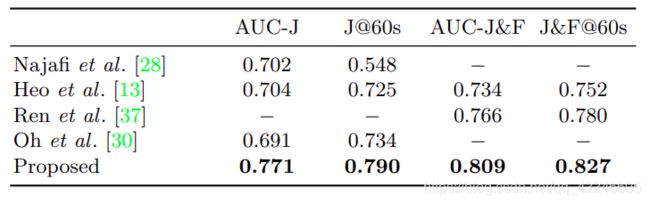
9. URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark
Seonguk Seo1,y, Joon-Young Lee2, and Bohyung Han1
链接: cvf.
链接: 论文阅读.
使用多模态信息,为视频分割数据集添加了caption,利用caption执行了分割。
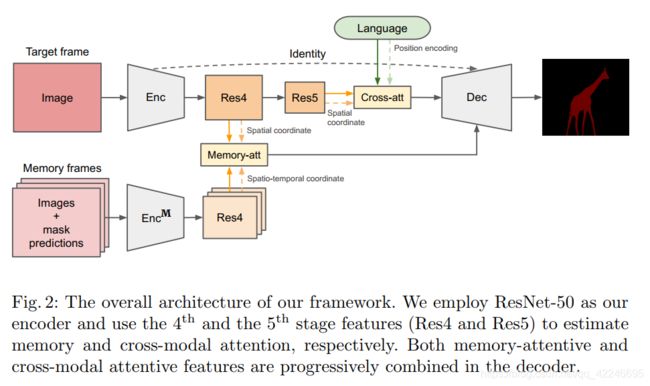
10. Unsupervised Video Object Segmentation with Joint Hotspot Tracking
11. ScribbleBox: Interactive Annotation Framework for Video Object Segmentation
12. Fast Video Object Segmentation using the Global Context Module(O-VOS)
Yu Li, Zhuoran Shen, Ying Shan
链接: arxiv.
链接: 论文阅读.
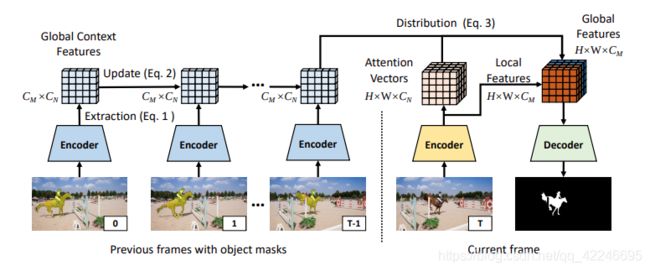
指标:
Training data:
Image:MSRA10K, ECSSD, and HKU-IS;
simulated video clips with frames generated by applying random transformation to static images.
Video:DAVIS16 DAVIS17 YTB-VOS
No fine-tuning at test time
J&F Jmean Fmean
DAVIS 16 86.6 87.6 85.7 0.04t/s
DAVIS 17 71.4 69.3 73.5
J&F Js Juns Fs Fsean
YTB-VOS 73.2 72.6 68.9 75.6 75.7
相关
- CenterNet Heatmap Propagation for Real-time Video Object Detection
- STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos
Ali Athar, Sabarinath Mahadevan, Aljoša Ošep, Laura Leal-Taixé, Bastian Leibe
链接: arxiv. - Efficient Semantic Video Segmentation with Per-frame Inference
Yifan Liu, Chunhua Shen, Changqian Yu, Jingdong Wang
链接: arxiv. - Learning Where to Focus for Efficient Video Object Detection
Zhengkai Jiang, Yu Liu, Ceyuan Yang, Jihao Liu, Peng Gao, Qian Zhang, Shiming Xiang, Chunhong Pan
链接: arxiv. - Mining Inter-Video Proposal Relations for Video Object Detection
- Video Object Detection via Object-level Temporal Aggregation
- Measuring the Importance of Temporal Features in Video Saliency
- Flow-edge Guided Video Completion
- Learning Joint Spatial-Temporal Transformations for Video Inpainting
Yanhong Zeng, Jianlong Fu, Hongyang Chao
链接: arxiv. - Short-Term and Long-Term Context Aggregation Network for Video Inpainting
- Foley Music: Learning to Generate Music from Videos
Chuang Gan, Deng Huang, Peihao Chen, Joshua B. Tenenbaum, Antonio Torralba
链接: arxiv.
2020 BMVC
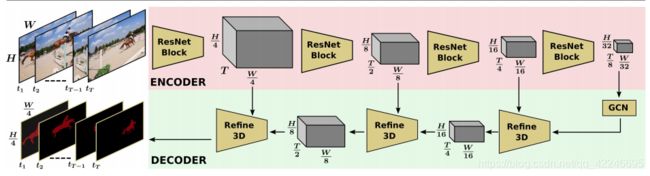
1.Making a Case for 3D Convolutions for Object Segmentation in Videos
Sabarinath Mahadevan, Ali Athar, Aljoša Ošep, Sebastian Hennen, Laura Leal-Taixé, Bastian Leibe
链接: arxiv.
链接: 论文阅读.
2020 NIPS
1. Video Object Segmentation with Adaptive Feature Bank and Uncertain-Region Refinement
Yongqing Liang et.al
链接: arxiv.
代码: github.