Mysql数据库详解(超长文)
Mysql数据库详解(超长文)
- 数据库概论
-
- 数据库语言
-
- DDL
- DML
- DCL
- DQL
- 数据库系统的三级模式结构
-
- 1、模式
- 2、外模式
- 3、内模式
- 关系数据库
-
- 关系
- 码、属性到底是个啥
-
- 超码(superkey):
- 候选码(candidate key)
- 主码(primary key)
- 全码
- 外码
- 主属性
- 非主属性
- 关系的完整性
- SQL语句
-
- 展示数据库
- 创建数据库
- 创建表
- 改变表
- 插入数据
- 修改数据
- 删除数据
- 选择数据
- 删除表
- 关系代数
-
- 选择操作
- 投影操作
- 选择和投影操作
- Join
-
- θ连接
- 等值连接
- 自然连接
- 除法division A/B
- 函数依赖
-
- 平凡函数依赖与非平凡函数依赖
- 完全函数依赖和部分函数依赖
- 传递函数依赖
- 闭包F+
- 关系分解
-
- 无损连接分解
-
- 判断方法1:
- 判断方法2
- 保持依赖的分解
- 范式
-
- 第一范式1NF
- 第二范式2NF
- 第三范式3NF
- BCNF
- 无损连接分解成BCNF和3NF
-
- LLJD-BCNF算法分解成BCNF
- LLJD-DPD-3NF分解成3NF
-
- 最小覆盖Fmin
- LLJD-DPD-3NF
- E-R模型
-
- 两类实体
- 属性
- ER图符号
- 几张表
- 事务与并发控制
-
- 事务的四个特征ACID
-
- 原子性(atomicity)
- 一致性(consistency)
- 隔离性(isolation)
- 持久性(durability)
- 并发控制
-
- TSS算法
- 两个类型的锁
- 锁的兼容表
- 2PL
- X-Lock、S-Lock和UNLock
- 结束语
数据库概论
数据库语言
DDL
数据库模式定义语言DDL(DataDefinition Language),是用于描述数据库中要存储的现实世界实体的语言。一个数据库模式包含该数据库中所有实体的描述定义。这些定义包括结构定义、操作方法定义等。包括了CREATE\ALTER\DROP等,主要用在对表结构、数据结构、表之间的关联关系以及约束等。
DML
DML = Data Manipulation Language,数据操纵语言,命令使用户能够查询数据库以及操作已有数据库中的数据的计算机语言。具体是指是UPDATE更新、INSERT插入、DELETE删除。主要是对数据库中一条或者多条数据进行操纵。
DCL
DCL(DataControl Language)是数据库控制语言。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权力执行DCL
DQL
DQL:Data QueryLanguage ,SELECT语句
数据库系统的三级模式结构
数据库系统的三级模式结构是指数据库系统是由外模式、模式和内模式三级构成。

1、模式
模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
模式的一个具体值称为模式的一个实例。同一个模式可以有多个实例
一个数据库只有一个模式
2、外模式
外模式也称子模式或用户模式,它是数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图。
外模式通常是模式的子集。一个数据库可以有多个外模式
3、内模式
内模式也称存储模式,一个数据库只有一个内模式。
它是数据屋里结构和存储方式的描述,是数据在数据库内部的组织方式。
关系数据库
关系
域(domain) 域是一组具有相同数据类型的值的集合。
关系有三种类型:
- 基本类型(通常又称基本表或基表):实际存在的表
- 查询表 :查询结果对应的表
- 视图表 :基本表或其他视图表导出的表,是虚表,不对应实际存储的数据
关系的特征:
- 更改属性或元组的顺序不会影响关系的含义(列和行可以是任意顺序)
- 一个关系中不应该有任何两个相同的行-没有重复的行
- 关系的任何单元格(行/列交叉点)中不应存在任何多值项
码、属性到底是个啥
超码(superkey):
一个或多个属性的集合,在一个关系中唯一地标识一个元组
特点:
- 可能包含无关属性
- 与其他任何属性组合后还是超码
- 一个关系一定有超码,至少所有属性组合起来一定是超码,即全码
- 不唯一
候选码(candidate key)
能够唯一地标识一个元祖,不可再分
特点:
- 超码的子集
- 其任何真子集都不可能是超码,候选码就是最小的超码
- 没有无关属性
- 不唯一
主码(primary key)
在一个关系中唯一地标识一个元组
特点:
- 是候选码之一
- 唯一或没有,如果设计数据库时不指定就没有
- 如果一个关系有多个候选码,则选定其中一个为主码
全码
关系模式中的所有属性是这个关系模式的候选码
外码
如果关系R1的一组属性FK满足以下两个条件,则它是R1中的外码:
1、存在与主码PK的关系R2,使得FK和PK具有相同数量的具有兼容域的属性。
2、 对于R1中的任何元组t1,或者R2中存在元组t2,使得t1[FK]=t2[PK]或者t1[FK]为空。
foreign key (sid) references suppliers (sid)
主属性
候选码的各个属性
非主属性
不包含在任何候选码中的属性称为非主属性,也称非码属性
关系的完整性
实体完整性、参照完整性、用户定义的完整性
实体完整性和参照完整性被称作关系的两个不变性。
实体完整性:主属性不能为空,各个分量也不能为空.
SQL语句
展示数据库
SHOW DATABASES;
创建数据库
CREATE DATABASE csdn;
创建表
CREATE TABLE mysql(
cid INT(5) NOT NULL,
title VARCHAR(20) NOT NULL,
url VARCHAR(50) NOT NULL,
PRIMARY KEY(cid)
)

改变表
1、把 主码cid改成自增,mysql是表名,change后面第一个是属性名,后面是新的属性信息,想改名字还是类型随便填
ALTER TABLE mysql CHANGE cid cid INT(5) NOT NULL AUTO_INCREMENT;

2、添加新的一列
- ADD 后面跟新增列的信息
ALTER TABLE mysql ADD ttime DATETIME;

3、删除一列
ALTER TABLE mysql DROP COLUMN ttime;

插入数据
1、插入一条
如果是全部属性都一起添加也可以不给mysql后面的值,直接values()也可,default是取默认值,自增吗
INSERT INTO mysql(cid,title,url) VALUES(DEFAULT,"Mysql","https://editor.csdn.net/md?articleId=112726309");

2、同时插入多条
INSERT INTO mysql VALUES(DEFAULT,"Redis","~"),
(DEFAULT,"Zookeeper","~"),
(DEFAULT,"JDBC","~"),
(DEFAULT,"Mybatis","~"),
(DEFAULT,"serlvet","~"),
(DEFAULT,"spring","~"),
(DEFAULT,"springMVC","~"),
(DEFAULT,"springBoot","~"),
(DEFAULT,"Maven","~"),
(DEFAULT,"Linux","~");

修改数据
mysql是表名,把servlet改成Servlet
UPDATE mysql SET title = "Servlet" WHERE cid = 6;
删除数据
删除后面不一定要给主码,但一般都会给主码,因为一个主码只对应一条数据,如果没有后面的where语句,会清空表数据
DELETE FROM mysql WHERE title = "JDBC";
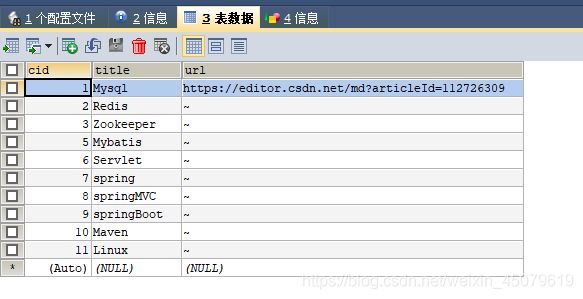
选择数据
SELECT * FROM mysql WHERE url="~";

带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false"

- 还有其他的distinct(消除重复行)、AS(取别名)、sum(求和)、avg(平均)、group
by(分组)、asc(升序)、desc(降序)、UNION(并操作)、INTERSECT(交操作)、EXCEPT(差操作)等这些就移步其他网站找找看吧
删除表
DROP TABLE mysql;
关系代数
选择操作
选择操作检索关系中满足选择条件的元组子集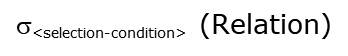

如:找到student表中年龄为19的学生,

相当于sql语句:
select * from student where AGE=19;
如果where子句跟多个条件,可以这样写,中间也可以用AND替换^

相当于sql语句:
select * from student where AGE=20 AND SNAME="ZHONGWEILONG";
-
选择运算的一个的性质是它是可交换的
因此,下面所示的所有表达式都是等价的,

投影操作
投影操作用于从关系中仅选择少数列


如列出所有学生的年龄

相当于sql语句:
select age from student;

选择和投影操作
如:选择年龄为20的学生的名字

相当于sql语句:
select SNAME from student where AGE=20;
总之,一句话,选择操作是拿到行数据,投影操作是拿到列数据。
Join
θ连接

如:
表这样:
然后就这样,dddd

等值连接
如果在所有连接条件中仅使用相等运算符,则连接称为等值连接

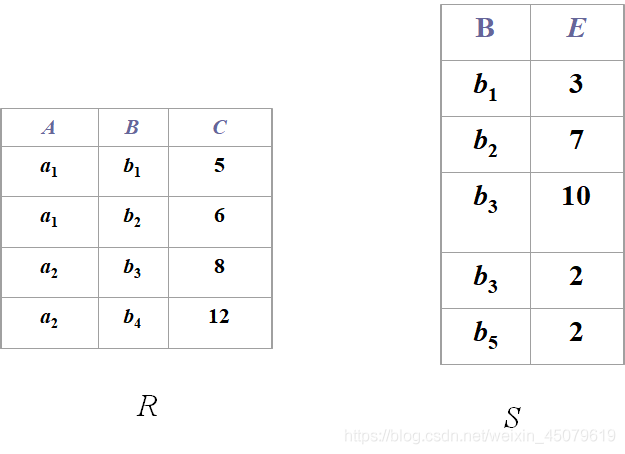
自然连接
笛卡尔积都知道吧,跟这个家伙还是有区别的,看下面的图自己想想看。

使用前面那连个R、S表进行自然连接结果
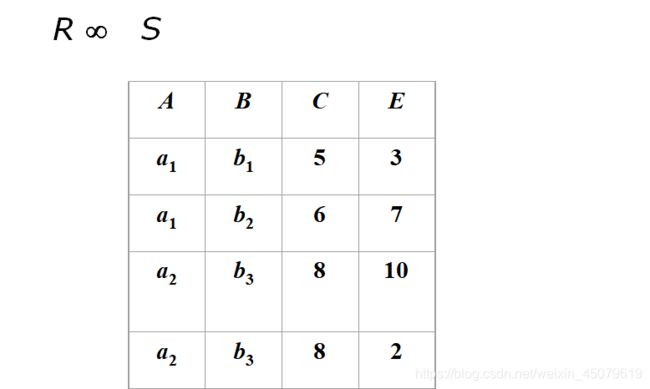
自然连接使用比较方便,如:
找到所有学生的名字和课程编号,需要使用到student和SC(选课表)两张表
- 不使用自然连接
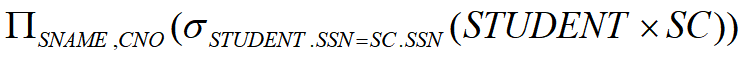
- 使用自然连接

一目了然,dddd。
除法division A/B
在A/B中,B中的属性必须包含在A的schema中,并且结果具有A-B属性,如下图

做个例题:
数据库:

- 获取供应零件P2的供应商suppliers的供应商名称

- 获取至少提供一个红色零件的供应商的供应商名称

你是不是在想怎么用除法来实现的,其实,没用到。
-
获取供应所有零件的供应商的供应商名称

-
获取至少提供供应商S2提供的所有零件的供应商的供应商编号
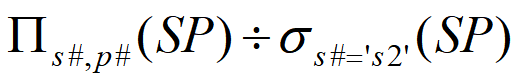
函数依赖
平凡函数依赖与非平凡函数依赖
对于x–>y的概念就相当于函数的概念,y=f(x),一个x有且只有一个唯一的y与之相对应
平凡函数依赖:如果X --> Y ,但 Y ⊆ X,则X --> Y是平凡函数依赖
如:(Sno,Sname) --> Sname
非平凡函数依赖:如果X --> Y,但Y不包含于X,则X --> Y是非平凡函数依赖
如:(Sno,Sname) --> Sgrade
完全函数依赖和部分函数依赖
完全函数依赖:如果y在函数上依赖于x的全部,而不仅仅依赖于某个子集,则y在函数上完全依赖于x
部分函数依赖:如果y在函数上依赖于x的部分而不是全部,则y在函数上部分依赖于x
如:CNO --> CLocation :full FD
{CNO,CNAME} --> CLocation: partial FD(因为CNO就可以决定CLoaction了,CNAME是多余的)
{SSN,CNO} --> HOURS: full FD (HOURS需要SSN和CNO两个才能决定HOURS时)
传递函数依赖
如果x --> z,(z不是候选码和x的子集),同时z --> y,那么 x – > y,即x传递决定y
(不知道怎么描述了,就是这个亚子,理解就行,dddd)
闭包F+
设F是R中的一组FD(函数依赖)。F的闭包是F逻辑上隐含的所有FD的集合
推导可得:


概念太烦了,直接看例子吧:

解:
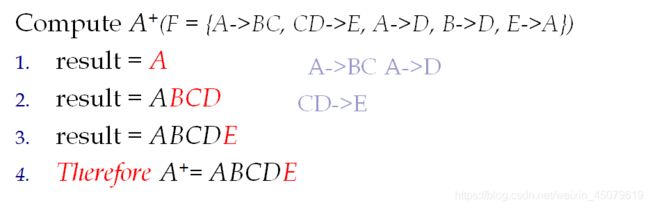
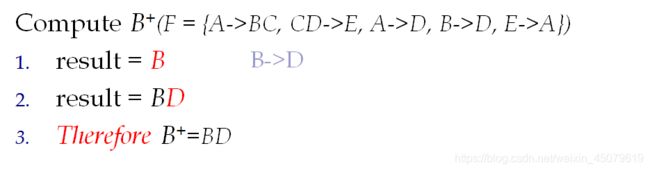
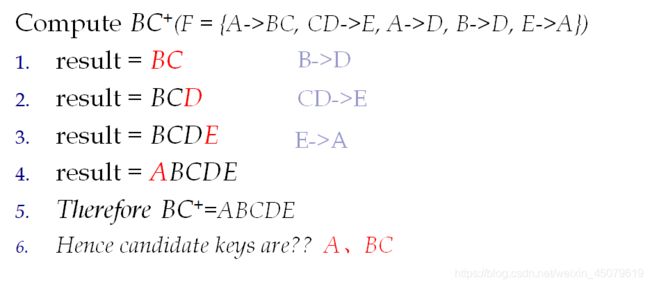
上面求闭包就是为了找候选码(看到这了要是还是不知道候选码是啥建议重头看起,前面有讲),还有另外一个方法就是画图法
- 找出只出现在左边的值(只有出度没有入度)
- 找出只出现在右边的值(只有入度没有出度)
- 找出左右两边都出现的值(既有出度也有入度)
- 查找只出现在左边的值能不能推出所有值,能则是候选码,不能则不是
- 用左边的值加上左右两边都出现的值一个个进行组合查找,如果能推出所有值则是候选码,不能则不是
如:

额,不解释了,自己琢磨一下,解释好麻烦,dddd
关系分解
无损连接分解
判断方法1:
如果{R1,R2}是R的分解,当满足下面其中一个条件就可认为是无损连接分解
1、R1 ∩ R2 → R1 –R2; or
2、R1 ∩ R2 → R2 - R1.
如:


如果分解不只两个呢,就要用另一个算法了
判断方法2
算法:判定无损连接性
输入:关系模式R(A1,A2,…,An),它的函数依赖集F以及分解 ={R1,R2,…,Rk}。
输出:确定 是否具有无损连接性。
方法:
(1)构造一个k行n列的表,第i行对应于关系模式Ri,第j列对应于属性Aj。如果Aj∈Ri,则在第i行第j列上放符号aj,否则放符号bij
(2)逐一检查F中的每一个函数依赖,并修改表中的元素。方法:取F中一个函数依赖X→Y,在X的列中寻找相同的行,然后将这些行中Y的分量改为相同的符号,如果其中有aj,则将bij改为aj;若其中无aj,则改为某一个bij。
(3)反复检查第(2)步,至无改变为止,若存在某一行为a1,a2,…,ak,则分解
具有无损连接性;如果F中所有函数依赖都不能再修改表中的内容,且没有发现这样的行,则分解 不具有无损连接性。
例:已知R
① 构造一个初始的二维表,若“属性”属于“模式”中的属性,则填aj,否则填bij。

② 根据A→C,对上表进行处理,由于属性列A上第1、2、5行相同均为a1,所以将属性列C上的b13、b23、b53改为同一个符号b13(取行号最小值,哪个都可以,但要统一)。

③ 根据B→C,对上表进行处理,由于属性列B上第2、3行相同均为a2,所以将属性列C上的b13、b33改为同一个符号b13(取行号最小值)。

④ 根据C→D,对上表进行处理,由于属性列C上第1、2、3、5行相同均为b13,所以将属性列D上的值均改为同一个符号a4。

⑤ 根据DE→C,对上表进行处理,由于属性列DE上第3、4、5行相同均为a4a5,所以将属性列C上的值均改为同一个符号a3。
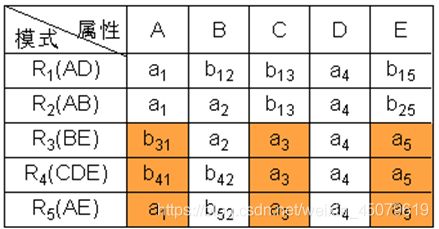
⑥ 根据CE→A,对上表进行处理,由于属性列CE上第3、4、5行相同均为a3a5,所以将属性列A上的值均改为同一个符号a1。

保持依赖的分解
算法:

例如:




给个例题,自己做,就不贴答案

范式
第一范式1NF
数据库的每一列都是不可分割的基本数据项,强调列的原子性,即属性不可再分
第二范式2NF
在1NF基础上,消除了非主属性对于码的部分函数依赖。
就是非主属性完全依赖与主属性,不能只依赖一部分。(完全依赖和部分依赖前面有讲)
第三范式3NF
在2NF的基础上,消除了非主属性对于码的传递函数依赖
即A、B、C,A是主属性,B、C是非主属性,不存在B–>C或者C–>B;
BCNF
在3NF的基础上,消除了主属性的传递函数依赖
无损连接分解成BCNF和3NF
LLJD-BCNF算法分解成BCNF

如:

解:
初始化:D = {P# Pn Pr Mi Mn A}
Ri = {P# Pn Pr Mi Mn A} 不是BCNF因为Mi --> Mn A 是非平凡函数依赖同时Mi不是超码
所以 Ri 被 Mi Mn A 和 P# Pn Pr Mi.替换
D = {Mi Mn A, P# Pn Pr Mi}.
Mi Mn A 是 BCNF因为在 Mi Mn A,中,Mi 是候选码
以此类推·Ri = P#PnPrMi不是BCNF
所以Ri的P#PnPrMi被P#PnMi和P#Pr替代
易得P#PnMi和P#Pr是BCNF
所以D = {Mi Mn A, P# Pn Mi, P# Pr}.
现在,D就是保存依赖的分解。
LLJD-DPD-3NF分解成3NF
最小覆盖Fmin
有三步,特别重要,不能遗漏
1、先把右边的多属性分成单个属性
2、判断是否存在冗余的依赖,即判断去掉一个依赖后是否成立
3、判断是否存在无关属性,即判断左边有多个值去掉一个是否还成立

例如:











LLJD-DPD-3NF

例:先找出候选码,找计算Fmin,Fmin的每个值作为一个分解。



E-R模型
两类实体
强实体:可以独立存在(或者可以唯一地标识自己)。
弱实体:存在依赖于其他(强)实体的存在
属性
简单(或原子)属性:为每个实体取一个不可分割的值。
例如:SSN、GPA、学生状况。
复合属性:获取可以进一步划分为子部分的值。
示例:Name:名字 中间名姓氏
单值属性:为每个实体取一个值(简单或复合)。多值属性(set attributes):为每个实体获取一组值。
例如:书籍作者
存储属性:其值实际存储在数据库中。
派生属性:其值是从其他属性计算出来的
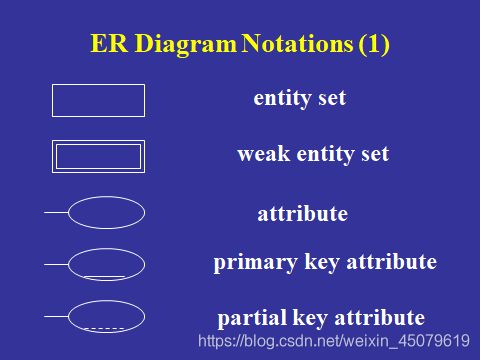
ER图符号


几张表

9张

事务与并发控制
事务的四个特征ACID
原子性、一致性、隔离性和持久性
原子性(atomicity)
一个事务要么全部提交成功,要么全部失败回滚,不能只执行其中的一部分操作,这就是事务的原子性
一致性(consistency)
事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。
如果数据库系统在运行过程中发生故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所作的修改有一部分已写入物理数据库,这是数据库就处于一种不正确的状态,也就是不一致的状态
隔离性(isolation)
事务的隔离性是指在并发环境中,并发的事务时相互隔离的,一个事务的执行不能被其他事务干扰。不同的事务并发操作相同的数据时,每个事务都有各自完成的数据空间,即一个事务内部的操作及使用的数据对其他并发事务时隔离的,并发执行的各个事务之间不能相互干扰。
隔离性又分为四个级别:读未提交(Read Uncommited)、读已提交(Read Commited)、可重复读(Repeatable Read)、串行化(Serializable)
- 读未提交(Read Uncommited)
就是开两个数据库连接A和B,注意如果是使用mysql数据库验证要把事务提交设置成手动的,因为mysql事务默认的是自动提交
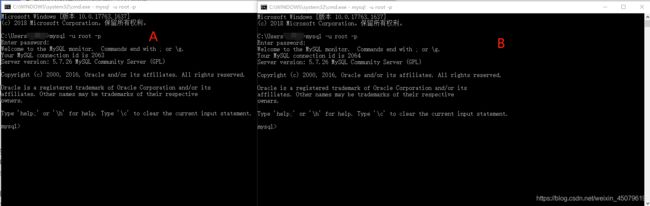
当B连接执行了一个sql语句后未执行commit前,A连接就可以拿到B还未提交的那条sql语句的结果,这就是读未提交。
缺点:可能会出现脏读。因为如果A拿到了B未提交的事务的数据,然后B发现错误进行了事务回滚,那A拿到的数据就是假的数据,这就是脏读。
解决方案:设置隔离级别为读已提交
- 读已提交(Read Commited)
跟第一个的区别是,读已提交就是B连接提交事务后A才能拿到,这就是读已提交。
缺点:会出现不可重复读的结果。就是A第一次读B提交的数据是data1,然后B又更新了这个数据,而A再读时,data1变成了data2,就是在一个事务窗口读同一个值出现了不同的结果,就是不可重复读,通俗点说就是不能够重复读取一个数据的值,因为这个数据的值随时可能发生变化。–执行UPDATE操作时出现
解决方案:设置隔离级别为可重复读
- 可重复读(Repeatable Read)
在开始读取数据(事务开启)时,不再允许修改操作,但是可以进行INSERT操作呀
缺点:会出现幻读。

解决方法:设置隔离级别为可串行化
- 串行化(Serializable)
这个就不用说了,两个事务串行运行,同一个时间只有一个在跑,自己的事自己弄,没有别人干扰,也就不会出现上述的问题了。
缺点:闭着眼睛都知道,肯定是效率低下,比较耗数据库性能了
大多数数据库默认的事务隔离级别是Read committed,比如Sql Server , Oracle。Mysql的默认隔离级别是Repeatable read。
持久性(durability)
一旦事务提交,那么它对数据库中的对应数据的状态的变更就会永久保存到数据库中。–即使发生系统崩溃或机器宕机等故障,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束的状态
并发控制
TSS算法

看不懂了把,看不懂就对了,我一开始也没看懂。
举个例子:
S: R1(X) R2(Y) W1(X) R2(X) W2(Y) W2(X) R3(Y) W3(Y) R4(X) W4(X)
判断这个序列是否是可串行化的?
画个图就好理解了,就是不同事物间如果存在读写冲突就画一条线,让一个先执行再执行
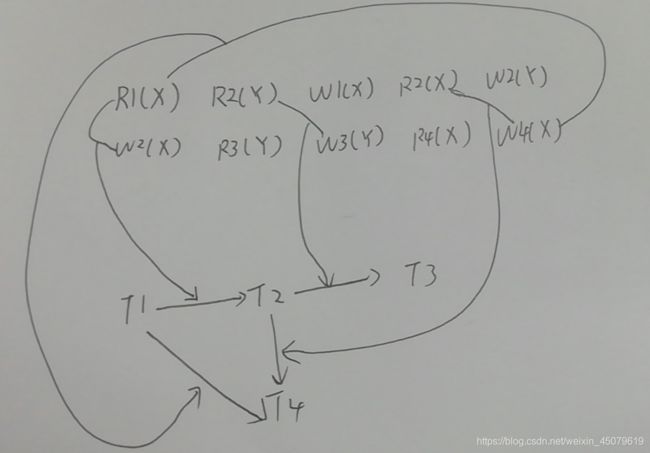
如果存在环就不是可串行化的,不存在就是可串行化。

两个类型的锁

锁的兼容表

2PL
2PL:事务释放锁后,它不能请求新的锁。定理:任何满足2PL协议的调度都是可序列化的。
等待-死方案-非抢占:1、较旧的事务可能会等待较年轻的事务释放数据项。较新的事务从不等待较旧的事务;而是回滚。 2、 在获取所需的数据项之前,一个事务可能会死好几次。
伤口等待方案——先发制人:旧的事务会伤害(强制回滚)年轻的事务,而不是等待它。较年轻的交易可能会等待较年长的交易。可能比等待-死亡方案更少的回滚。
例子:

缺点:
2PL可能导致级联中止。
2PL不能防止死锁。
X-Lock、S-Lock和UNLock
XLock:排它锁/写锁(可读可写)
SLock:共享锁/读锁(可读)
UNLock: 解锁或释放锁


结束语
终于更完了,还有个存储过程和触发器就不更了,码字不易呀!