<转>YARN源码分析(四)-----Journalnode
前言
最近在排查公司Hadoop集群性能问题时,发现Hadoop集群整体处理速度非常缓慢,平时只需要跑几十分钟的任务时间一下子上张到了个把小时,起初怀疑是网络原因,后来证明的确是有一部分这块的原因,但是过了没几天,问题又重现了,这次就比较难定位问题了,后来分析hdfs请求日志和Ganglia的各项监控指标,发现namenode的挤压请求数持续比较大,说明namenode处理速度异常,然后进而分析出是因为写journalnode的editlog速度慢问题导致的,后来发现的确是journalnode的问题引起的,后来的原因是因为journalnode的editlog目录没创建,导致某台节点写edillog一直抛FileNotFoundException,所以在这里提醒大家一定要重视一些小角色,比如JournalNode.在问题排查期间,也对YARN的JournalNode相关部分的代码做了学习,下面是一下学习心得,可能有些地方分析有误,敬请谅解.
JournalNode
可能有些同学没有听说过JournalNode,只听过Hadoop的Datanode,Namenode,因为这个概念是在MR2也就是Yarn中新加的,journalNode的作用是存放EditLog的,在MR1中editlog是和fsimage存放在一起的然后SecondNamenode做定期合并,Yarn在这上面就不用SecondNamanode了.下面是目前的Yarn的架构图,重点关注一下JournalNode的角色.
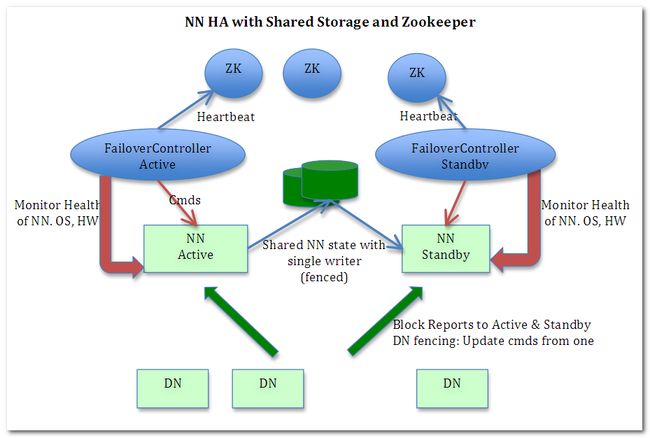
上面在Active Namenode与StandBy Namenode之间的绿色区域就是JournalNode,当然数量不一定只有1个,作用相当于NFS共享文件系统.Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步.
QJM
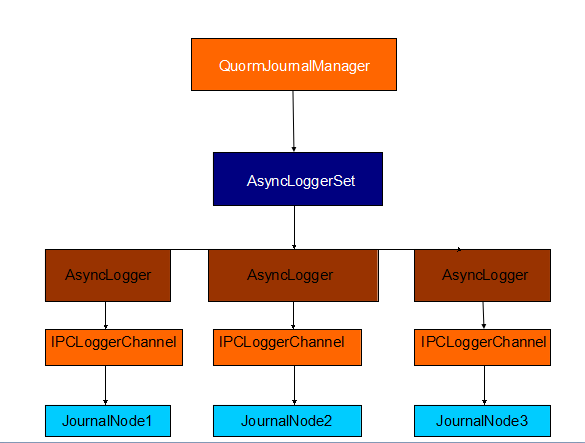
下面从Yarn源码的角度分析一下JournalNode的机制,在配置中定义JournalNode节点的个数是可多个的,所以一定会存在一个类似管理者这样的角色存在,而这个管理者就是QJM,全程QuorumJournalManager.下面是QJM的变量定义:
- /**
- * A JournalManager that writes to a set of remote JournalNodes,
- * requiring a quorum of nodes to ack each write.
- * JournalManager可以写很多记录数据给多个远程JournalNode节点
- */
- @InterfaceAudience.Private
- public class QuorumJournalManager implements JournalManager {
- static final Log LOG = LogFactory.getLog(QuorumJournalManager.class);
- // Timeouts for which the QJM will wait for each of the following actions.
- private final int startSegmentTimeoutMs;
- private final int prepareRecoveryTimeoutMs;
- private final int acceptRecoveryTimeoutMs;
- private final int finalizeSegmentTimeoutMs;
- private final int selectInputStreamsTimeoutMs;
- private final int getJournalStateTimeoutMs;
- private final int newEpochTimeoutMs;
- private final int writeTxnsTimeoutMs;
- // Since these don't occur during normal operation, we can
- // use rather lengthy timeouts, and don't need to make them
- // configurable.
- private static final int FORMAT_TIMEOUT_MS = 60000;
- private static final int HASDATA_TIMEOUT_MS = 60000;
- private static final int CAN_ROLL_BACK_TIMEOUT_MS = 60000;
- private static final int FINALIZE_TIMEOUT_MS = 60000;
- private static final int PRE_UPGRADE_TIMEOUT_MS = 60000;
- private static final int ROLL_BACK_TIMEOUT_MS = 60000;
- private static final int UPGRADE_TIMEOUT_MS = 60000;
- private static final int GET_JOURNAL_CTIME_TIMEOUT_MS = 60000;
- private static final int DISCARD_SEGMENTS_TIMEOUT_MS = 60000;
- private final Configuration conf;
- private final URI uri;
- private final NamespaceInfo nsInfo;
- private boolean isActiveWriter;
- //远程节点存在于AsyncLoggerSet集合中
- private final AsyncLoggerSet loggers;
- private int outputBufferCapacity = 512 * 1024;
- private final URLConnectionFactory connectionFactory;
- static List
createLoggers(Configuration conf, - URI uri, NamespaceInfo nsInfo, AsyncLogger.Factory factory)
- throws IOException {
- List
ret = Lists.newArrayList(); - List
addrs = getLoggerAddresses(uri); - String jid = parseJournalId(uri);
- for (InetSocketAddress addr : addrs) {
- ret.add(factory.createLogger(conf, nsInfo, jid, addr));
- }
- return ret;
- }
- QuorumJournalManager(Configuration conf,
- URI uri, NamespaceInfo nsInfo,
- AsyncLogger.Factory loggerFactory) throws IOException {
- Preconditions.checkArgument(conf != null, "must be configured");
- this.conf = conf;
- this.uri = uri;
- this.nsInfo = nsInfo;
- this.loggers = new AsyncLoggerSet(createLoggers(loggerFactory));
- ...
- /**
- * Wrapper around a set of Loggers, taking care of fanning out
- * calls to the underlying loggers and constructing corresponding
- * {@link QuorumCall} instances.
- */
- class AsyncLoggerSet {
- static final Log LOG = LogFactory.getLog(AsyncLoggerSet.class);
- private final List
loggers; - private static final long INVALID_EPOCH = -1;
- private long myEpoch = INVALID_EPOCH;
- public AsyncLoggerSet(List
loggers) { - this.loggers = ImmutableList.copyOf(loggers);
- }
- /**
- * Channel to a remote JournalNode using Hadoop IPC.
- * All of the calls are run on a separate thread, and return
- * {@link ListenableFuture} instances to wait for their result.
- * This allows calls to be bound together using the {@link QuorumCall}
- * class.
- */
- @InterfaceAudience.Private
- public class IPCLoggerChannel implements AsyncLogger {
- private final Configuration conf;
- //JournalNode通信地址
- protected final InetSocketAddress addr;
- private QJournalProtocol proxy;
- /**
- * Executes tasks submitted to it serially, on a single thread, in FIFO order
- * (generally used for write tasks that should not be reordered).
- * 单线程串行操作线程池
- */
- private final ListeningExecutorService singleThreadExecutor;
- /**
- * Executes tasks submitted to it in parallel with each other and with those
- * submitted to singleThreadExecutor (generally used for read tasks that can
- * be safely reordered and interleaved with writes).
- * 并行操作线程池
- */
- private final ListeningExecutorService parallelExecutor;
- private long ipcSerial = 0;
- private long epoch = -1;
- private long committedTxId = HdfsConstants.INVALID_TXID;
- private final String journalId;
- private final NamespaceInfo nsInfo;
- private URL httpServerURL;
- //journalnode线程metric统计操作
- private final IPCLoggerChannelMetrics metrics;
- ...
- /**
- * The number of bytes of edits data still in the queue.
- * 积压的editlog记录数
- */
- private int queuedEditsSizeBytes = 0;
- /**
- * The highest txid that has been successfully logged on the remote JN.
- * 最高位的事物Id数量
- */
- private long highestAckedTxId = 0;
- /**
- * Nanotime of the last time we successfully journaled some edits
- * to the remote node.
- */
- private long lastAckNanos = 0;
- /**
- * Nanotime of the last time that committedTxId was update. Used
- * to calculate the lag in terms of time, rather than just a number
- * of txns.
- */
- private long lastCommitNanos = 0;
- /**
- * The maximum number of bytes that can be pending in the queue.
- * This keeps the writer from hitting OOME if one of the loggers
- * starts responding really slowly. Eventually, the queue
- * overflows and it starts to treat the logger as having errored.
- */
- private final int queueSizeLimitBytes;
- /**
- * If this logger misses some edits, or restarts in the middle of
- * a segment, the writer won't be able to write any more edits until
- * the beginning of the next segment. Upon detecting this situation,
- * the writer sets this flag to true to avoid sending useless RPCs.
- * 非同步状态指标,判断JournalNode是否掉线
- */
- private boolean outOfSync = false;
- ...
开始执行记录写操作
- @Override
- public ListenableFuture
startLogSegment( final long txid, - final int layoutVersion) {
- return singleThreadExecutor.submit(new Callable
() { - @Override
- public Void call() throws IOException {
- getProxy().startLogSegment(createReqInfo(), txid, layoutVersion);
- synchronized (IPCLoggerChannel.this) {
- if (outOfSync) {
- outOfSync = false;
- QuorumJournalManager.LOG.info(
- "Restarting previously-stopped writes to " +
- IPCLoggerChannel.this + " in segment starting at txid " +
- txid);
- }
- }
- return null;
- }
- });
- }
- @Override
- public ListenableFuture
finalizeLogSegment( - final long startTxId, final long endTxId) {
- return singleThreadExecutor.submit(new Callable
() { - @Override
- public Void call() throws IOException {
- throwIfOutOfSync();
- getProxy().finalizeLogSegment(createReqInfo(), startTxId, endTxId);
- return null;
- }
- });
- }
- @Override
- public void finalizeLogSegment(long firstTxId, long lastTxId)
- throws IOException {
- QuorumCall
- firstTxId, lastTxId);
- loggers.waitForWriteQuorum(q, finalizeSegmentTimeoutMs,
- String.format("finalizeLogSegment(%s-%s)", firstTxId, lastTxId));
- }
JournalNode和Journal
与服务端对应的客户端,对每个JournalNode进行操作执行的类是JournalNode
- /**
- * The JournalNode is a daemon which allows namenodes using
- * the QuorumJournalManager to log and retrieve edits stored
- * remotely. It is a thin wrapper around a local edit log
- * directory with the addition of facilities to participate
- * in the quorum protocol.
- */
- @InterfaceAudience.Private
- public class JournalNode implements Tool, Configurable, JournalNodeMXBean {
- public static final Log LOG = LogFactory.getLog(JournalNode.class);
- private Configuration conf;
- private JournalNodeRpcServer rpcServer;
- private JournalNodeHttpServer httpServer;
- private final Map
- private ObjectName journalNodeInfoBeanName;
- private String httpServerURI;
- private File localDir;
- static {
- HdfsConfiguration.init();
- }
- /**
- * When stopped, the daemon will exit with this code.
- */
- private int resultCode = 0;
- ...
- public void discardSegments(String journalId, long startTxId)
- throws IOException {
- getOrCreateJournal(journalId).discardSegments(startTxId);
- }
- public void doPreUpgrade(String journalId) throws IOException {
- getOrCreateJournal(journalId).doPreUpgrade();
- }
- public void doUpgrade(String journalId, StorageInfo sInfo) throws IOException {
- getOrCreateJournal(journalId).doUpgrade(sInfo);
- }
- public void doFinalize(String journalId) throws IOException {
- getOrCreateJournal(journalId).doFinalize();
- }
- ...
- File[] journalDirs = localDir.listFiles(new FileFilter() {
- @Override
- public boolean accept(File file) {
- return file.isDirectory();
- }
- });
- for (File journalDir : journalDirs) {
- String jid = journalDir.getName();
- if (!status.containsKey(jid)) {
- Map
- jMap.put("Formatted", "true");
- status.put(jid, jMap);
- }
- }
- /**
- * Set up the given Configuration object to point to the set of JournalNodes
- * in this cluster.
- */
- public URI getQuorumJournalURI(String jid) {
- List
addrs = Lists.newArrayList(); - for (JNInfo info : nodes) {
- addrs.add("127.0.0.1:" + info.ipcAddr.getPort());
- }
- String addrsVal = Joiner.on(";").join(addrs);
- LOG.debug("Setting logger addresses to: " + addrsVal);
- try {
- return new URI("qjournal://" + addrsVal + "/" + jid);
- } catch (URISyntaxException e) {
- throw new AssertionError(e);
- }
- }
-
-
dfs.namenode.shared.edits.dir -
qjournal://had1:8485;had2:8485;had3:8485/mycluster
- /**
- * Start a new segment at the given txid. The previous segment
- * must have already been finalized.
- */
- public synchronized void startLogSegment(RequestInfo reqInfo, long txid,
- int layoutVersion) throws IOException {
- assert fjm != null;
- checkFormatted();
- checkRequest(reqInfo);
- if (curSegment != null) {
- LOG.warn("Client is requesting a new log segment " + txid +
- " though we are already writing " + curSegment + ". " +
- "Aborting the current segment in order to begin the new one.");
- // The writer may have lost a connection to us and is now
- // re-connecting after the connection came back.
- // We should abort our own old segment.
- abortCurSegment();
- }
- // Paranoid sanity check: we should never overwrite a finalized log file.
- // Additionally, if it's in-progress, it should have at most 1 transaction.
- // This can happen if the writer crashes exactly at the start of a segment.
- EditLogFile existing = fjm.getLogFile(txid);
- if (existing != null) {
- if (!existing.isInProgress()) {
- throw new IllegalStateException("Already have a finalized segment " +
- existing + " beginning at " + txid);
- }
- ...
全部代码的分析请点击链接https://github.com/linyiqun/hadoop-yarn,后续将会继续更新YARN其他方面的代码分析。
参考源代码
Apach-hadoop-2.7.1(hadoop-hdfs-project)