Python办公自动化(未完,待续)
目录
5 PDF自动化
5.4 pypdf2工具
5.4.1 工具使用说明
5.4.2 PDF旋转
5.4.3 PDF合并
5.4.4 PDF拆分
5.4.5 提取文本
6 PPT自动化
6.1 工具使用说明
6.2 添加文本框
6.3 添加图片
5 PDF自动化
操作PDF的几种常用工具:
- pdfminer:提取文本;解析PDF是一件耗时和耗内存的工作,PDFMiner库使用了lazy parsing的策略,也就是只在需要的时候才去解析(减少时间和内存的使用)
参考链接:http://euske.github.io/pdfminer/programming.html - pdf2htmlEX:将pdf格式转换成html格式,然后再提取信息(注:此工具目前不再维护)
- pdfplumber:提取完整表格
- pypdf2:旋转、合并、拆分PDF
5.4 pypdf2工具
5.4.1 工具使用说明
pypdf2工具不太擅长细节操作(文本提取),但是对于整体操作(PDF旋转、合并、拆分)比较擅长。
-
PDF读模块:PdfFileReader,该对象的属性与方法如下
.numPages:获取PDF的页数
.getPage():获取PDF页面对象 - PDF写模块:PdfFileWriter
from PyPDF2 import PdfFileReader, PdfFileWriter5.4.2 PDF旋转
def PDFrotate(input_file, output_file, rotation):
oldFile = open(input_file,'rb')
pdfReader = PdfFileReader(oldFile)
pdfWriter = PdfFileWriter()
# 对每一页进行旋转(读取-->旋转-->输出)
for i in range(pdfReader.numPages):
pageObj = pdfReader.getPage(i) # 读取
pageObj.rotateClockwise(rotation) # 旋转
pdfWriter.addPage(pageObj) # 输出
# 保存文件
newFile = open(output_file,'wb')
pdfWriter.write(newFile)
oldFile.close()
newFile.close()
PDFrotate('PDF_source/course.pdf', 'PDF_result/course_rotate.pdf', 270)运行结果:

5.4.3 PDF合并
def PDFmerge(input_file, output_file):
pdfWriter = PdfFileWriter()
for path in input_file:
oldFile = open(path,'rb')
pdfReader = PdfFileReader(oldFile)
for i in range(pdfReader.numPages):
pageObj = pdfReader.getPage(i)
pdfWriter.addPage(pageObj)
# oldFile.close() # 加上这一行代码:既不会报错,也会生成PDF,但是PDF无内容
# 保存文件
newFile = open(output_file, 'wb')
pdfWriter.write(newFile)
oldFile.close()
newFile.close()
PDFmerge(['PDF_source/course.pdf', 'PDF_source/2018高新认证名单.pdf'], 'PDF_result/course_merge.pdf')注:oldFile执行close()方法必须在pdfWriter.write()之后,否则一旦将oldFile close掉,pdfWriter中的文本就会丢失。
运行结果:

5.4.4 PDF拆分
def PDFsplit(input_file, output_file):
oldFile = open(input_file,'rb')
pdfReader = PdfFileReader(input_file)
# 拆分,即读取PDF中的每页,单独进行保存
for i in range(pdfReader.numPages):
pageObj = pdfReader.getPage(i)
pdfWriter = PdfFileWriter()
pdfWriter.addPage(pageObj)
output_file_i = f'{output_file}{i}.pdf'
newFile = open(output_file_i, 'wb')
pdfWriter.write(newFile)
newFile.close()
oldFile.close()
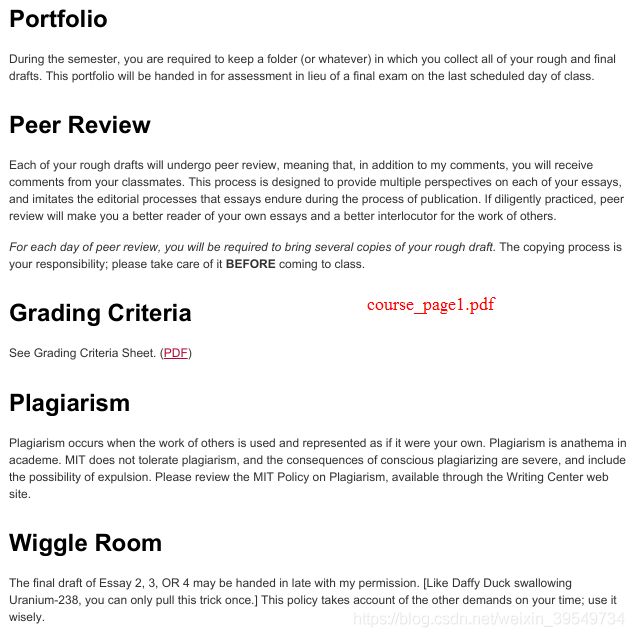
PDFsplit('PDF_source/course.pdf', 'PDF_result/course_page')运行结果:

5.4.5 提取文本
# 读出来的内容(有问题) 主要是没空格
filename = 'PDF_source/The Youtube video recommendation system.pdf'
pdfFileObj=open(filename, 'rb')
pdfReader=PyPDF2.PdfFileReader(pdfFileObj)
print(pdfReader.numPages)
pageObj=pdfReader.getPage(0)
print(pageObj.extractText())运行结果:

6 PPT自动化
6.1 工具使用说明
-
安装:pip install python-pptx
from pptx import Presentation
# 步骤1:创建PPT
ppt = Presentation()
# 步骤2:新建幻灯片slide(使用ppt自带的1-48中模板)
slide_layout = ppt.slide_layouts[0]
slide = ppt.slides.add_slide(slide_layout)
# 步骤3:编写幻灯片slide
title = slide.shapes.title # 设置标题
title.text = "Hello World!" # 设置text
subtitle = slide.placeholders[1] # 使用placeholdes索引获取一页幻灯片中的元素
subtitle.text = "PPT自动化 from python-pptx!" # 设置text
# 步骤4:保存PPT
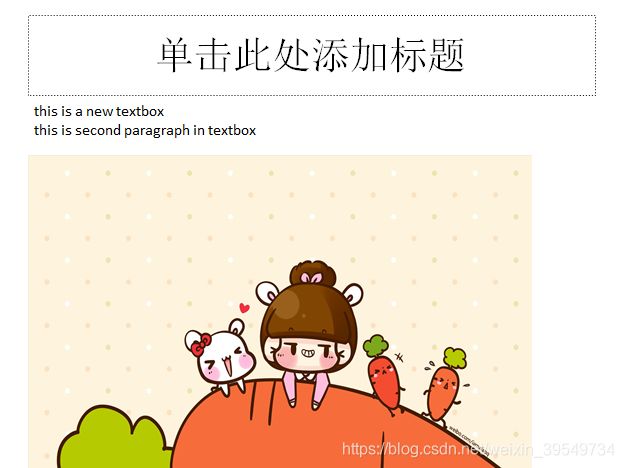
ppt.save('demo.pptx')6.2 添加文本框
from pptx.util import Inches
# 新建幻灯片
slide_layout = ppt.slide_layouts[5]
slide = ppt.slides.add_slide(slide_layout)
# 添加文本框
# 预设位置及大小(left & top为相对位置,width & height为文本框大小)
left, top, width, height = Inches(0.5), Inches(1.6), Inches(4), Inches(1)
textbox = slide.shapes.add_textbox(left, top, width, height)
textbox.text = 'this is a new textbox'
# 在新文本框中添加段落
new_para = textbox.text_frame.add_paragraph()
new_para.text = 'this is second paragraph in textbox'6.3 添加图片
img_path ='pic/pic1.jpg'
left, top, width, height = Inches(0.5), Inches(2.5), Inches(8), Inches(5)
pic = slide.shapes.add_picture(img_path, left, top, width, height)
ppt.save('demo.pptx')运行结果:

更多AI资源请关注公众号:大胡子的AI

欢迎各位AI爱好者加入群聊交流学习:882345565(内有大量免费资源哦!)

版权声明:本文为博主原创文章,未经博主允许不得转载。如要转载请与本人联系。