笔记:新手的Spark指南
macOS Sierra 10.12.4
Spark 1.6.2
Python 2.7
转载请注明出处:http://blog.csdn.net/MrLevo520/article/details/76087612
前言
既然做了Hive的整理,那就把spark的也整理下吧,当做入门指南和自己的笔记吧~与君共勉
Spark基础
Spark是什么?
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用分布式并行计算框架。Spark拥有hadoop MapReduce所具有的优点,但和MapReduce 的最大不同之处在于Spark是基于内存的迭代式计算——Spark的Job处理的中间输出结果可以保存在内存中,从而不再需要读写HDFS,除此之外,一个MapReduce 在计算过程中只有map 和reduce 两个阶段,处理之后就结束了,而在Spark的计算模型中,可以分为n阶段,因为它内存迭代式的,我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。
因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。其不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。是一个用来实现快速而同用的集群计算的平台。— From Spark 工作原理及核心RDD 详解
Spark原理过程
-
使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。
- Driver:运行Application的main()函数并且创建SparkContext
-
Driver根据我们设置的参数(比如说设定任务队列,设定最大内存等)Cluster Manager 申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程,YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
- Executor:是为某Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的Executors
- Cluster Manager:集群管理器,在集群上获取资源的外部服务(例如:Local、Standalone、Mesos或Yarn等集群管理系统)
-
申请到了作业执行所需的资源之后,river进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行,一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完
-
task:最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段)
-
什么是RDD?
全称为弹性分布式数据集;本质上,RDD是种编程抽象,代表可以跨机器进行分割的只读对象集合。RDD可以从一个继承结构(lineage)重建(因此可以容错),通过并行操作访问,可以读写HDFS或S3这样的分布式存储,更重要的是,可以缓存到worker节点的内存中进行立即重用。由于RDD可以被缓存在内存中,Spark对迭代应用特别有效,因为这些应用中,数据是在整个算法运算过程中都可以被重用。大多数机器学习和最优化算法都是迭代的,使得Spark对数据科学来说是个非常有效的工具。另外,由于Spark非常快,可以通过类似Python REPL的命令行提示符交互式访问。
RDD特点
- RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)
- RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。比如每个节点最多放5万数据,结果你每个partition是10万数据。那么就会把partition中的部分数据写入磁盘上,进行保存。(弹性)
- RDD将操作分为两类:transformation与action。无论执行了多少次transformation操作,RDD都不会真正执行运算,只有当action操作被执行时,运算才会触发。而在RDD的内部实现机制中,底层接口则是基于迭代器的,从而使得数据访问变得更高效,也避免了大量中间结果对内存的消耗。
- RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。
RDD在Spark中的地位及作用
这需要从四个方面阐述
-
为什么会有Spark?
因为传统的并行计算模型无法有效的解决迭代计算(iterative)和交互式计算(interactive);而Spark的使命便是解决这两个问题,这也是他存在的价值和理由。
-
Spark如何解决迭代计算?
其主要实现思想就是RDD,把所有计算的数据保存在分布式的内存中。迭代计算通常情况下都是对同一个数据集做反复的迭代计算,数据在内存中将大大提升IO操作。这也是Spark涉及的核心:内存计算。
-
Spark如何实现交互式计算?
因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集。当然你也可以使用python,java,R等接口,spark也提供了相应的操作方式
-
Spark和RDD的关系?
可以理解为:RDD是一种具有容错性基于内存的集群计算抽象方法,Spark则是这个抽象方法的实现。
如何操作RDD?
Step1-获取RDD
-
自己创建个RDD,如以下语句:
rdd = sc.parallelize(['1,2,3,4','5,6,6','9,10,11']) -
从共享的文件系统获取,(如:HDFS)
-
通过已存在的RDD转换
-
将已存在scala集合(只要是Seq对象)并行化,通过调用SparkContext的parallelize方法实现
-
改变现有RDD的之久性;RDD是懒散,短暂的.(RDD的固化:cache缓存至内错;save保存到分布式文件系统)
Step2-操作RDD
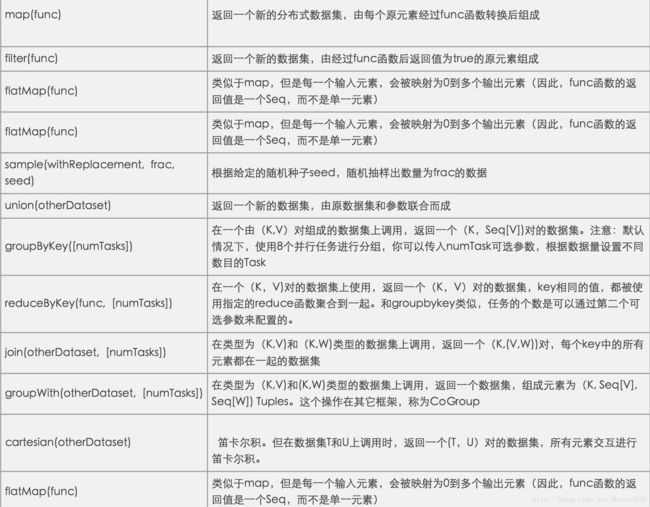
Transformation:根据数据集创建一个新的数据集,计算后返回一个新RDD;例如:Map将数据的每个元素经过某个函数计算后,返回一个新的分布式数据集即RDD。
值得注意的是,RDD的转化操作都是惰性求值得,也就意味着在被调用行动操作之前Spark不会开始计算,相反,Spark会在内部记录下所要求执行的操作的相关信息,因此在调用sc.textFile()时候,数据并没有读取进来,而是在必要的时候才会进行读取。所以也就导致了导入文件的时候感觉很快的错觉
- Transformation的一些例子
def func(a):
line_split = a.split(",")
return sum(map(int,line_split))
data = sc.parallelize(['1,2,3,4','5,6,6','9,10,11']) # 生成rdd
t_rdd= data.map(func) # rdd的Transformation过程
a_rdd = t_rdd.collect() # action过程 [10, 17, 30]
Actions:对数据集计算后返回一个数值value给驱动程序;例如:Reduce将数据集的所有元素用某个函数聚合后,将最终结果返回给程序。返回的是一个新的数据类型,这里注意的是,返回的并不是新的RDD,只有Transformation之后是新的RDD
- Actions具体内容

spark执行步骤
- 定义一个或多个RDD,可以通过获取存储在磁盘上的数据(HDFS,Cassandra,HBase,Local Disk),并行化内存中的某些集合,转换(transform)一个已存在的RDD,或者,缓存或保存。
- 通过传递一个闭包(函数)给RDD上的每个元素来调用RDD上的操作。Spark提供了除了Map和Reduce的80多种高级操作。
- 使用结果RDD的动作(action)(如count、collect、save等)。动作将会启动集群上的worker机器进行计算。
当Spark在一个worker上运行闭包时,闭包中用到的所有变量都会被拷贝到节点上,但是由闭包的局部作用域来维护。Spark提供了两种类型的共享变量,这些变量可以按照限定的方式被所有worker访问。广播变量会被分发给所有worker,但是是只读的。累加器这种变量,worker可以使用关联操作来“加”,通常用作计数器。
Spark实际操作
那么, sc的是什么鬼?
你可以把他理解成由
SparkContext构造出来的实例,通过这个实例我们可以构造自己的RDD
# -*- coding:utf-8 -*-
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
import math
appName ="hellospark" #你的应用程序名称
master= "local"#设置单机
conf = SparkConf().setAppName(appName).setMaster(master)#配置SparkContext
sc = SparkContext(conf=conf)
# 一个简单的wordcount测试
str_ = '''this is a word count test only test show twice'''
data = sc.parallelize(str_.split(" "))
data.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y).collect()
# spark.akka.frameSize: 控制Spark中通信消息的最大容量 (如 task 的输出结果),默认为10M。当处理大数据时,task 的输出可能会大于这个值,需要根据实际数据设置一个更高的值。
# SparkConf为Spark配置类,配置已键值对形式存储,封装了一个ConcurrentHashMap类实例settings用于存储Spark的配置信息;配置项包括:master、appName、Jars、ExecutorEnv等等
# SparkContext用于连接Spark集群、创建RDD、累加器(accumlator)、广播变量(broadcast variables),所以说SparkContext为Spark程序的根
注意sc的构造是怎么来的
方法一:在jupyter中操作(推荐)
这里的推荐是指自己做测试的时候,项目中提交任务还是spark-submit来做,当然,你得把pyspark的kernel配到jupyter中,可参考解决:win远程连接ubuntu服务器安装jupyter,启动pyspark
方法二:使用spark-submit pythonfile.py来实现提交python脚本操作
# 前提是在一个文件夹中,不然要定位文件位置
$ spark-submit --driver-memory 6G --queue 如果有队列填上队列名字 testpy.py 可带参数
# pyspark test
# 中文测试
方法三:使用ipython在pyspark的shell中操作
# 启动local spark:pyspark --master local[2]
# local[2]是开双核的意思,[4]即是开4核
[email protected]:~$ pyspark --master local[2]
In [8]: line = sc.textFile("file:/home/xiaoju/user/xukai/test.tx #创建RDD载入的路径这里是机器路径
...: t")
In [9]: pythonlines = line.filter(lambda line:"test" in line) # 转化操作
In [10]: pythonlines.first() # 行动操作
Out[10]: u'test;'
# 当一个文本读取为RDD时,输入的每一行都会成为RDD的一个元素
In [21]: line.first()
Out[21]: u'this is a test txtfile!'
In [24]: print line.first().split(" ")[0] # 这样就可以流畅使用python进行操作了,只是导入的时候用的是RDD存储
this
In [26]: stringlist = line.first().split(" ")
In [27]: nums = sc.parallelize(stringlist) # 用sparkContext的parallelize制作RDD的,是ParallelCollectionRDD,创建一个并行集合。
In [28]: squared = nums.map(lambda x:x=="this").collect()
In [29]: for num in squared:
...: print num
...:
True
False
False
False
False
In [34]: words = lines.flatMap(lambda line:line.split(" ")).collec
...: t() # 使用collece()才能进行for输出,flatmap文件中的所有行数据仅返回了一个数组对象
In [35]: for i in words:
...: print i
...:
this
is
a
test
# 产生新的键值对pair类型RDD
In [56]: rdd = sc.parallelize([1,2,3,3])
# 操作过程中,转化并不会被执行,需要有个动作操作才被执行,比如collect()
In [57]: rdd.collect()
Out[57]: [1, 2, 3, 3]
In [59]: rdd1 = rdd.map(lambda x:(x,x+1))
In [60]: rdd1.collect()
Out[60]: [(1, 2), (2, 3), (3, 4), (3, 4)]
In [64]: rdd2 = rdd1.filter(lambda x: x[0]>2)
In [65]: rdd2.collect()
Out[65]: [(3, 4), (3, 4)]
In [67]: rdd1.sortByKey().collect()
Out[67]: [(1, 2), (2, 3), (3, 4), (3, 4)]
一些Demo
# -*- coding:utf-8 -*-
# 如果使用jupyter的话,sc已经构造好了,不需要再倒入包
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
import math
appName ="hellospark" #你的应用程序名称
master= "local"#设置单机
conf = SparkConf().setAppName(appName).setMaster(master)#配置SparkContext
sc = SparkContext(conf=conf)
# parallelize:并行化数据,转化为RDD
# 并行集合的一个重要参数是slices,表示数据集切分的份数。Spark将会在集群上为每一份数据起一个任务。
# 典型地,你可以在集群的每个CPU上分布2-4个slices. 一般来说,Spark会尝试根据集群的状况,
# 来自动设定slices的数目。
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data, numSlices=10) # numSlices为分块数目,根据集群数进行分块
#--------------------------------------------------
# textFile读取外部数据
rdd = sc.textFile("file:/xxx/sparkstreaming/test/test.txt") # 以行为单位读取外部文件,并转化为RDD
print rdd.collect()
# 打印出的结果是 [u'lslsllslsiiiiiiiiiii']
#--------------------------------------------------
# map:迭代,对数据集中数据进行单独操作
def my_add(l):
return (l,l)
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data) # 并行化数据集
result = distData.map(my_add)
print (result.collect()) # 返回一个分布数据集
# 打印出的结果 [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)]
#--------------------------------------------------
# filter:过滤数据
def my_add(l):
result = False
if l > 2:
result = True
return result
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)#并行化数据集,分片
result = distData.filter(my_add)
print (result.collect())#返回一个分布数据集
# [3, 4, 5]
# zip:将两个RDD对应元素组合为元组
#--------------------------------------------------
x = sc.parallelize(range(0,5))
y = sc.parallelize(range(1000, 1005))
print x.zip(y).collect()
# [(0, 1000), (1, 1001), (2, 1002), (3, 1003), (4, 1004)]
#union 组合两个RDD
print x.union(x).collect()
# [0, 1, 2, 3, 4, 0, 1, 2, 3, 4]
# Aciton操作
#--------------------------------------------------
# collect:返回RDD中的数据
rdd = sc.parallelize(range(1, 10))
print rdd
print rdd.collect()
# ParallelCollectionRDD[11] at parallelize at PythonRDD.scala:423
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
#--------------------------------------------------
# collectAsMap:以rdd元素为元组,以元组中一个元素作为索引返回RDD中的数据
m = sc.parallelize([('a', 2), (3, 4)]).collectAsMap()
print m['a']
print m[3]
#2
#4
#--------------------------------------------------
# groupby函数:根据提供的方法为RDD分组:
rdd = sc.parallelize([1, 1, 2, 3, 5, 8])
def fun(i):
return i % 2
result = rdd.groupBy(fun).collect()
print [(x, sorted(y)) for (x, y) in result]
# [(0, [2, 8]), (1, [1, 1, 3, 5])]
#--------------------------------------------------
# reduce:对数据集进行运算
rdd = sc.parallelize(range(1, 10))
result = rdd.reduce(lambda a, b: a + b)
print result
# 45
#--------------------------------------------------
a = sc.parallelize([i for i in range(9)], 3)
print a.collect()
#[0, 1, 2, 3, 4, 5, 6, 7, 8]
y = a.map(lambda a:(a,a*2)) # 需要的表现形式为(a,a*2)的形式,而a是传递的参数
print y.collect()
#[(0, 0), (1, 2), (2, 4), (3, 6), (4, 8), (5, 10), (6, 12), (7, 14), (8, 16)]
z = a.map(lambda a:a*2)
print print z.collect()
#[0, 2, 4, 6, 8, 10, 12, 14, 16]
y = a.flatMap(lambda a:(a*2,a*3))
print y.collect();
#[0, 0, 2, 3, 4, 6, 6, 9, 8, 12, 10, 15, 12, 18, 14, 21, 16, 24]
#--------------------------------------------------
# union有点像append
x = sc.parallelize(['A','A','B'])
y = sc.parallelize(['D','C','A'])
z = x.union(y)
z2 = x.intersection(y)
print(x.collect())
#['A', 'A', 'B']
print(y.collect())
#['D', 'C', 'A']
print(z.collect())
#['A', 'A', 'B', 'D', 'C', 'A']
print(z2.collect())
# ['A']
#--------------------------------------------------
x = sc.parallelize([1,2,3])
y = x.groupBy(lambda x: 'A' if (x%2 == 1) else 'B' )
print(x.collect())
#[1, 2, 3]
print([(j[0],[i for i in j[1]]) for j in y.collect()])
#[('A', [1, 3]), ('B', [2])]
#--------------------------------------------------
x=sc.parallelize([1,3,1,2,3])
y=x.countByValue()
print y[1]
#2
#--------------------------------------------------
# 按升序排,取前n个
x = sc.parallelize([1,3,1,2,3,4,1,6])
y=x.takeOrdered(5)
# [1, 1, 1, 2, 3]
小结
- 总的来说,RDD之所以被描述为"弹性",是因为在任何时候都能进行重算,因为保存RDD数据的一台机器失败时,Spark可以使用这种特性来重算出丢弃的部分分区。
- 转化RDD的时候,是返回新的RDD而不是对现有的RDD进行操作,只有在执行动作的时候返回的是其他数据类型 。
Spark进阶
这里会总结下我以前实习时候用到过的一些处理方法
使用MySqldb+Pyspark操作Mysql
- 首先得知道,这个数据库在哪,也就是数据库所在服务器的ip地址,才能进行连接
# 使用ping命令进行所需要连接的数据库的ip地址获取
$ ping 服务器
PING xxxxxx bytes of data.
64 bytes from xxxxxx: icmp_seq=1 ttl=64 time=0.020 ms
- 使用Mysqldb包进行数据库的连接操作
In [22]: import MySQLdb
In [23]: conn = MySQLdb.connect(host=ip地址,user=用户名
...: ,passwd=密码,db='test',charset='utf8')
# 这边连接的时候最好制定数据库,即添加 db="test",charset="utf8",如不制定,则在sql语句中选择上指定的数据库名字
In [24]: cursor = conn.cursor()
In [25]: count = cursor.execute("select count(*) from test_uk ")
In [26]: print cursor.fetchall()
((8L,),)
# 打开服务器上的Mysql查看一下,ok,没问题,获取行数正确
mysql> select * from test_uk;
+----+----+-------+
| id | tp | value |
+----+----+-------+
| 3 | 1 | 0.75 |
| 4 | 5 | 0 |
| 5 | 6 | 2 |
| 6 | 4 | 0 |
| 9 | 7 | 3 |
| 11 | 9 | 2 |
| 12 | 10 | 11 |
| 14 | 13 | 13 |
+----+----+-------+
8 rows in set (0.00 sec)
# 写入test数据库中的tbl_realtime_statis表,记得需要提交
mysql> desc tbl_realtime_statis
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| value | double | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
2 rows in set (0.00 sec)
# 开始执行insert动作
In [38]: cursor.execute('INSERT INTO tbl_realtime_statis (id,value) VALUE
...: S (1,11)')
Out[38]: 1L
In [39]: cursor.connection.commit()
mysql> select * from tbl_realtime_statis;
+------+-------+
| id | value |
+------+-------+
| 1 | 11 |
+------+-------+
1 row in set (0.00 sec)
更多语句参考:python使用mysqldb连接数据库操作方法示例详解
使用spark-submit pythonfile来执行本地txt写入指定数据库的操作
在文件同目录下创建名为txttosql.py的python脚本,填写如下
conn = MySQLdb.connect(host='',user='',passwd='',db='test',charset='utf8')
cursor = conn.cursor()
datapath = "test.txt"
with open(datapath) as f:
for line in f.readlines():
linesplit = line.strip().split(",")
key = int(linesplit[0])
value = int(linesplit[1])
sqlstring = 'INSERT INTO tbl_realtime_statis (id,value) VALUES (%d,%d)'%(key,value)
cursor.execute(sqlstring)
cursor.connection.commit()
cursor.close()
conn.close()
之后执行spark-submit txttosql.py即可,注意数据库如果已有数据,将不会被覆盖,而是之后插入操作
使用JDBC+Pypark进行MySql操作
建一个parallelize的RDD
In [12]: rdd1 = sc.parallelize([(1,'id1',100000,12,1.2),(2,'id2',2000000,13,1.22)])
转化成为DataFrame的RDD
In [13]: rdd2 = rdd1.toDF()
# 会耗费比较长的时间
In [14]: rdd2.collect()
Out[14]:
[Row(_1=1, _2=u'id1', _3=100000, _4=12, _5=1.2),
Row(_1=2, _2=u'id2', _3=2000000, _4=13, _5=1.22)]
In [15]: rdd2.show()
+---+---+-------+---+----+
| _1| _2| _3| _4| _5|
+---+---+-------+---+----+
| 1|id1| 100000| 12| 1.2|
| 2|id2|2000000| 13|1.22|
+---+---+-------+---+----+
In [18]: rdd2.filter("_3 > 100000").show()
+---+---+-------+---+----+
| _1| _2| _3| _4| _5|
+---+---+-------+---+----+
| 2|id2|2000000| 13|1.22|
+---+---+-------+---+----+
# 可以修改别名,貌似只有一次改的?
In [34]: rdd2.withColumnRenamed("_2","name_string").withColumnRenamed("_3","money_bigint")
Out[34]: DataFrame[_1: bigint, name_string: string, money_bigint: bigint, _4: bigint, _5: double]
# 尝试在toDF的时候就写好名字
In [41]: rdd3 = rdd1.toDF(["id_int","name_string","money_bigint","age_double","tall_float"])
In [42]: rdd3.write.jdbc("jdbc:mysql://xxxx/test", "testalltype", "overwrite", {"
...: user":"", "password":""})
# 查看
mysql> select * from testalltype;
+--------+-------------+--------------+------------+------------+
| id_int | name_string | money_bigint | age_double | tall_float |
+--------+-------------+--------------+------------+------------+
| 2 | id2 | 2000000 | 13 | 1.22 |
| 1 | id1 | 100000 | 12 | 1.2 |
+--------+-------------+--------------+------------+------------+
2 rows in set (0.00 sec)
# 插入语句可以用append,使用另一种方法创建dataframe
In [48]: newline = [(932,'Alice', 1929291,2,22.92)]
In [51]: rdd4 = sqlContext.createDataFrame(newline,['id_int','name
...: _string','money_bigint','age_double','tall_float'])
In [52]: rdd4.show()
+------+-----------+------------+----------+-----------+
|id_int|name_string|money_bigint|age_double|tall_float|
+------+-----------+------------+----------+-----------+
| 932| Alice| 1929291| 2| 22.92|
+------+-----------+------------+----------+-----------+
In [55]: rdd4.write.jdbc("jdbc:mysql://xxxx/test","t
...: estalltype","append",{"user":"","password":"
...: "})
# 查看
mysql> select * from testalltype;
+--------+-------------+--------------+------------+------------+
| id_int | name_string | money_bigint | age_double | tall_float |
+--------+-------------+--------------+------------+------------+
| 2 | id2 | 2000000 | 13 | 1.22 |
| 1 | id1 | 100000 | 12 | 1.2 |
| 932 | Alice | 1929291 | 2 | 22.92 |
+--------+-------------+--------------+------------+-------------+
##############使用pyspark+jdbc将本地csv存储到mysql###########
In [1]: datapath = "dataform.csv"
In [2]: with open(datapath) as f:
...: k = 1
...: parallelizelist = []
...: for line in f.readlines():
...: linesplit = line.strip().split("|")
...: tuple_data = tuple(linesplit)
...: if k == 1:
...: tuple_title = linesplit
...: else:
...: parallelizelist.append(tuple_data)
...:
...: k +=1
# 方法1:sqlContext.createDataFrame
In [3]: rdd3 = sqlContext.createDataFrame(parallelizelist,tuple_title)
In [4]: rdd3.write.jdbc("jdbc:mysql://xxxx/test","testallty
...: pe","overwrite",{"user":"","password":"
...: "})
# 方法2:toDF
In [8]: rdd4 = sc.parallelize(parallelizelist)
In [9]: rdd5 = rdd4.toDF(tuple_title)
In [10]: rdd5.write.jdbc("jdbc:mysql://xxxx/test","testallt
...: ype","append",{"user":"","password":""
...: })
Spark对Hive表操作
首先理解下什么是SparkContext, SQLContext 和HiveContext,原文可参考@pig2–让你真正理解什么是SparkContext, SQLContext 和HiveContext这位版主很厉害!这里简单总结下
- SparkContext:用于连接Spark集群、创建RDD、累加器(accumlator)、广播变量(broadcast variables),所以说SparkContext为Spark程序的根,你只要知道它能让一个普通的列表编程rdd就行了,非常牛逼,就是传说中的sc!
- SparkSQL:是spark的一个模块,是spark的一个模块,SparkSQL 用来处理结构化数据,所以SparkSQL你的data必须定义schema.在spark1.3.1,sparksql继承dataframes 和SQL 查询引擎
- SQLContext:spark处理结构化数据的入口。允许创建DataFrame以及sql查询
- HiveContext:spark sql执行引擎,集成hive数据
In [68]: from pyspark.sql import HiveContext,Row
In [69]: hiveCtx = HiveContext(sc)
In [70]: rows = hiveCtx.sql("SELECT * FROM test.table1 limit
...: 5")
In [71]: firstRow = rows.first()
[Stage 32:=====>
[Stage 32:========>
[Stage 32:==========>
[Stage 32:=============>
[Stage 32:================>
[Stage 32:==================>
[Stage 32:=====================>
[Stage 32:======================>
In [72]: print firstRow.business_id
257
In [73]: print firstRow.order_id
3057564118
In [74]: hiveowntest = HiveContext(sc)
In [75]: rows2 = hiveowntest.sql("SELECT * FROM test.owntest")
In [76]: rows2.show()
+--------+---+
| name|age|
+--------+---+
|shangsan| 20|
| lisi| 22|
| zhouwu| 21|
+--------+---+
# 保存入表,其实就是讲hive表读入RDD,然后再写入新的hive表中
In [79]: rows2.saveAsTable("hive_test_spark")
# 然后进入hive中进行操作,虽然有点错误,单还是可以执行查询动作
hive> select * from hive_test_spark;
OK
hive_test_spark.name hive_test_spark.age
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
shangsan 20
lisi 22
zhouwu 21
hive> select * from hive_test_spark where name="shangsan";
OK
hive_test_spark.name hive_test_spark.age
shangsan 20
Time taken: 0.645 seconds, Fetched: 1 row(s)
Pyspark使用本地文件建立Hive表
1.再另一终端,执行如下,将文件put到集群
# 其中spark_write_hive.txt是本地写好的文件,之后的操作是put到hdfs上
$ hadoop fs -put spark_write_hive.txt hdfs:/xxxx/xxxx/
# 查看是否put到hdfs上
$ hadoop fs -cat hdfs:/xxxx/xxxx/spark_write_hive.txt
shangsan,20
lisi,30
2.需要测试的文件已推送到集群上存储,接下来是使用spark并将数据导入到表中
sqlContext = HiveContext(sc)
********
# 建hive表
sqlContext.sql("CREATE TABLE IF NOT EXISTS hive_test_spark2 (key INT,value STRING)")
# 导入数据,注意这里是集群的数据
hivenewtable.sql("LOAD DATA INPATH '/xxxx/xxxx/test.txt' INTO TABLE hive_test_spark2")
********
# 还是推荐以下方式建立外表
In [21]: txttohive = HiveContext(sc)
In [22]: txttohive.sql("CREATE EXTERNAL TABLE IF NOT EXISTS hive_t
...: est_spark3 (name string,age string ) ROW FORMAT DELIMITED
...: FIELDS TERMINATED BY ','")
Out[22]: DataFrame[result: string]
In [23]: txttohive.sql("LOAD DATA INPATH '/xxxx/xxxx/
...: spark_write_hive.txt' INTO TABLE hive_test_s
...: park3")
16/12/22 13:49:35 ERROR KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !!
Out[23]: DataFrame[result: string]
# 查看hive表
hive> select * from hive_test_spark3;
OK
hive_test_spark3.name hive_test_spark3.age
shangsan 20
lisi 30
使用Pyspark 将Hive表转化成rdd操作
from pyspark.sql import HiveContext,Row
hiveCtx = HiveContext(sc)
data_order = hiveCtx.sql("select * from xx.hot_position")
data_order.show(7)
+----+--------+-------+----+-----------+----+-----+---+
|city| badlng| badlat| num|badcaseprec|year|month|day|
+----+--------+-------+----+-----------+----+-----+---+
| xx市|1x6.3213|x9.8959|3597| 0.857|2017| 05| 10|
| xx市| 1x6.379| x9.865|5775| 0.857|2017| 05| 10|
| xx市|1x1.3198|x1.1937|1269| 0.849|2017| 05| 10|
| xx市|1x1.3199|x1.1937|3387| 0.847|2017| 05| 10|
| xx市|1x6.5509|x9.6083|1092| 0.835|2017| 05| 10|
| xx市| 1x1.354|x1.1988|1482| 0.825|2017| 05| 10|
| xx市|1x0.2131|x0.2915|8215| 0.817|2017| 05| 10|
+----+--------+-------+----+-----------+----+-----+---+
only showing top 7 rows
# 将dataframe转化为rdd进行计算
data_order_rdd=data_order.rdd
data_order_rdd.map(lambda x:(x.badlng,x.badlat)).collect()
# output
[(u'1x6.3213', u'x9.8959'),
(u'1x6.379', u'x9.865'),
(u'1x1.3198', u'x1.1937'),
(u'1x1.3199', u'x1.1937'),
(u'1x6.5509', u'x9.6083')]
当然你也可以这样操作
# 进行复合计算
# -*- coding: utf-8 -*-
from math import*
def Distance2(data):# 第二种计算方法
lat2=float(data.split("\t")[1])
lng2=float(data.split("\t")[0])
lat1=39.8959
lng1=116.3213
radlat1=radians(lat1)
radlat2=radians(lat2)
a=radlat1-radlat2
b=radians(lng1)-radians(lng2)
s=2*asin(sqrt(pow(sin(a/2),2)+cos(radlat1)*cos(radlat2)*pow(sin(b/2),2)))
earth_radius=6378.137
s=s*earth_radius
if s<0:
return -s
else:
return s
data_order_rdd.filter(lambda x:x.badlat>'31').map(lambda x:x.badlng+'\t'+x.badlat).map(Distance2).collect()
# 输出
[0.0,
6.010588654903075,
1068.8138888545056,
1068.8177053251293,
1069.6032160827797,
1068.969082793839,
0.07015355066273321]
Spark Streaming
Spark是一个类似于MapReduce的分布式计算框架,其核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
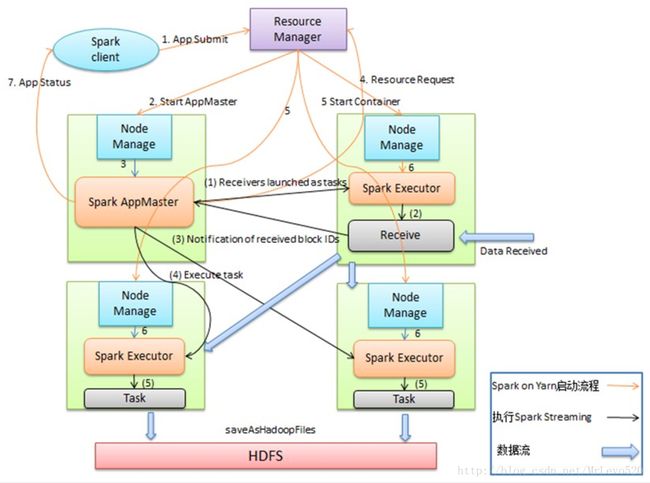
基于云梯Spark on Yarn的Spark Streaming总体架构如图,Spark on Yarn启动后,由Spark AppMaster把Receiver作为一个Task提交给某一个Spark Executor;Receive启动后输入数据,生成数据块,然后通知Spark AppMaster;Spark AppMaster会根据数据块生成相应的Job,并把Job的Task提交给空闲Spark Executor 执行。图中蓝色的粗箭头显示被处理的数据流,输入数据流可以是磁盘、网络和HDFS等,输出可以是HDFS,数据库等。
Spark Streaming的基本原理
将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据,其基本原理如图
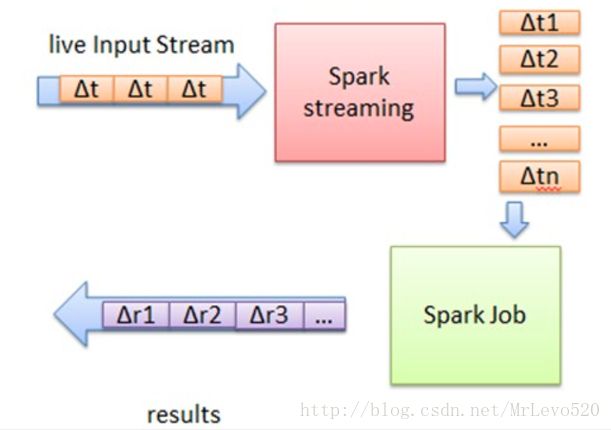
首先,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,最终结果也返回多块。
Spark Streaming的内部原理
使用Spark Streaming编写的程序与编写Spark程序非常相似,在Spark程序中,主要通过操作RDD(Resilient Distributed Datasets弹性分布式数据集)提供的接口,如map、reduce、filter等,实现数据的批处理。而在Spark Streaming中,则通过操作DStream(表示数据流的RDD序列)提供的接口,这些接口和RDD提供的接口类似。
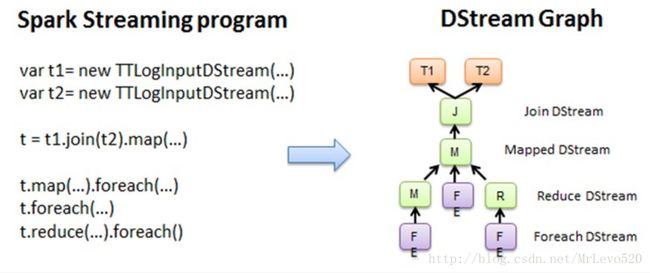
Spark Streaming把程序中对DStream的操作转换为DStream Graph
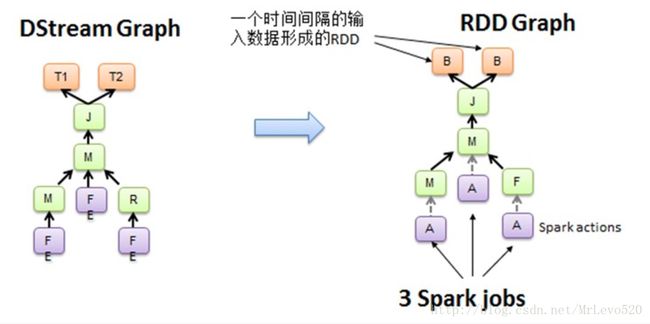
对于每个时间片,DStream Graph都会产生一个RDD Graph;针对每个输出操作(如print、foreach等),Spark Streaming都会创建一个Spark action;对于每个Spark action,Spark Streaming都会产生一个相应的Spark job,并交给JobManager。JobManager中维护着一个Jobs队列, Spark job存储在这个队列中,JobManager把Spark job提交给Spark Scheduler,Spark Scheduler负责调度Ta
Spark Streaming优缺点
优点
- Spark Streaming 内部的实现和调度方式高度依赖 Spark 的 DAG 调度器和 RDD,这就决定了 Spark Streaming 的设计初衷必须是粗粒度方式的,同时,由于 Spark 内部调度器足够快速和高效,可以快速地处理小批量数据,这就获得准实时的特性。
- Spark Streaming 的粗粒度执行方式使其确保“处理且仅处理一次”的特性,同时也可以更方便地实现容错恢复机制。
- 由于 Spark Streaming 的 DStream 本质是 RDD 在流式数据上的抽象,因此基于 RDD 的各种操作也有相应的基于 DStream 的版本,这样就大大降低了用户对于新框架的学习成本,在了解 Spark 的情况下用户将很容易使用 Spark Streaming。
- 由于 DStream 是在 RDD 上的抽象,那么也就更容易与 RDD 进行交互操作,在需要将流式数据和批处理数据结合进行分析的情况下,将会变得非常方便。
缺点
- Spark Streaming 的粗粒度处理方式也造成了不可避免的延迟。在细粒度处理方式下,理想情况下每一条记录都会被实时处理,而在 Spark Streaming 中,数据需要汇总到一定的量后再一次性处理,这就增加了数据处理的延迟,这种延迟是由框架的设计引入的,并不是由网络或其他情况造成的。
- Spark Streaming 当前版本稳定性不是很好。[spark 1.5]
如何使用Spark Streaming
可参考:Spark Streaming 集成 Kafka 总结
作为构建于Spark之上的应用框架,Spark Streaming承袭了Spark的编程风格,对于已经了解Spark的用户来说能够快速地上手。接下来以Spark Streaming官方提供的WordCount代码为例来介绍Spark Streaming的使用方式。
// scala语言编写spark streaming
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent from a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
import org.apache.spark.streaming.StreamingContext._
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
Spark在机器学习中应用
- 官方教程:官网地址pyspark svm
- 数据:sample_libsvm_data.txt
第一步,新建python 文件,取名svmwithsgd.py]
# -*- coding:utf-8 -*-
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
from pyspark.mllib.classification import SVMWithSGD, SVMModel
from pyspark.mllib.regression import LabeledPoint
appName ="hellospark" #你的应用程序名称
master= "local"#设置单机
conf = SparkConf().setAppName(appName).setMaster(master)#配置SparkContext
sc = SparkContext(conf=conf)
# Load and parse the data
def parsePoint(line):
values = [float(x) for x in line.strip().split(' ')]
return LabeledPoint(values[0], values[1:])
data = sc.textFile("newdata.txt")
parsedData = data.map(parsePoint)
# Build the model
model = SVMWithSGD.train(parsedData, iterations=100)
# Evaluating the model on training data
labelsAndPreds = parsedData.map(lambda p: (p.label, model.predict(p.features)))
trainErr = labelsAndPreds.filter(lambda (v, p): v != p).count() / float(parsedData.count())
print("Training Error = " + str(trainErr))
# Save and load model
#model.save(sc, "myModelPath")
#sameModel = SVMModel.load(sc, "myModelPath")
# 最后两段会加载出错
#SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
#SLF4J: Defaulting to no-operation (NOP) logger implementation
#SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
第二步,进行spark-submit 提交任务
$ spark-submit svmwithsgd.py
Pyspark在工作流中套路
详见我的另一篇博客Spark日志清洗一般流程
总结
在实习的过程中,对于不同的任务启用不同的工具,处理手段,技巧等,而对编程语言的选择,其实并不是那么重要,这是一种实现形式罢了,效率的核心还是对数据结构和算法的理解上,大数据处理在我现在的认知范围内,只不过是一种海量数据处理的技术,就像一台机器不够算了,那就搞两台,n台,机械硬盘算起来不够快了,那就加载到内存中算(spark),当然机器之间的通信,任务的派发,最后的汇总这些也是非常值得琢磨的,而设置分配内存,设置mapreduce个数这类的,很多时候都是靠经验来总结,对数据的把握程度,预估上进行判断,如何更快速的处理数据并且开销更低,这里都是属于性能调优里面的。总之,能处理数据,了解t和a用法,并不能说掌握spark,只能说会用这个工具而已,而现实中大多数任务只是挑选工具的过程而已,我们通常是为了close掉任务而去学习一种新的更快的工具,我想这对于工具的理解和学习来说是十分不利的,而越来越多的任务迫使我们没有太多的余力静下心去去更深入的学习和了解,记录和总结。并不想这样。
致谢
-
非常好的pyspark api讲解
-
Spark—SparkContext简单分析
-
Spark入门Python
-
Spark的python编程-初步理解
-
Spark的python编程-初步理解
-
『 Spark 』3. spark 编程模式
-
[翻译]Spark编程指南(Python版)
-
Spark日志清洗一般流程
-
spark参数配置调优
-
Spark排错与优化
-
Spark 工作原理及核心RDD 详解
-
Spark性能优化指南——基础篇