6、集合算法
目录
- 一、Bagging
-
- 随机森林(Random Forest,RF)
- Extra Trees
- Totally Random Trees Embedding
- Isolation Forest
- 多输出任务
- 二、Boosting(提升)
-
- AdaBoost算法
-
- AdaBoost分类算法(自适应提升算法)
- Adaboost回归算法
- 梯度提升Gradient boosting
-
- 一、理论推导
- 二、损失函数和梯度
- 三、优化方法
- 梯度提升树GBDT(Gradient Boosting Decision Tree)
-
- GBDT回归算法
- GBDT分类算法:二分类
- GBDT分类算法:多分类
- 随机梯度提升SGD
- XGBoost
- Light GBM
- 三、Stacking
- Python
-
- 投票分类器
- Bagging:分类
- Bagging:回归
- 随机森林:分类
- 随机森林:回归
- Extra Trees:分类
- Extra Trees:回归
- Totally random forest trees(TRFT)
- Isolation Forest(IForest)
- AdaBoost:分类
- AdaBoost:回归
- GBDT:回归
- GBDT:分类
- XGBoost
-
- 1、核心数据结构:读取数据
- 2、核心模型结构:实例化Booster
- 3、 训练模型:train
- xgboost自带交叉验证
- 学习模型:sklearn风格
-
- 回归
- 分类
- 排序
- 作图
-
- 特征重要性
- 单棵树的可视化
- 输出到图形
- 模型保存与读取
- XGBoost建模经验
- Light GBM
- 直方梯度增强
- 三、堆积法Stacking
关于集成算法的参考
集成算法Python实现包:ML-Ensemble
- 集成学习框架可分为三种:
Bagging和Boosting都是由基函数线性组合而成。Bagging中的基函数最好是强学习器(多次有放回抽样,总体方差是基函数方差的1/N),否则可能导致整体模型的准确度低。Boosting可以是弱学习器。
- Bagging从训练集中通过随机采样形成每个基模型所需要的子训练集,各模型之间没有关系,对所有基模型预测的结果进行综合(平均或者投票,有hard votiong和soft voting之分)产生最终的预测结果。
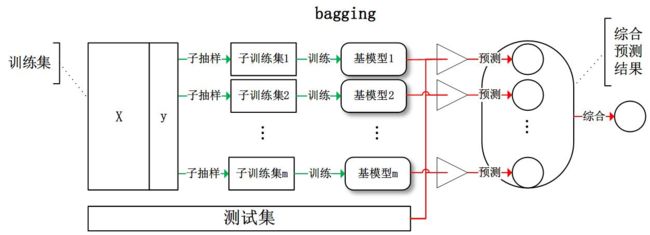
- Boosting训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。对所有基模型预测的结果进行线性综合产生最终的预测结果。
-
- Adaboosting:对同样数据集,每次训练模型后,根据预测结果对样本权重进行调整(提高错误样本权重,降低正确样本权重),然后继续对该批数据进行模型训练;最后将各模型的结果进行综合就是最终结果。
-
- Gradient Boosting:对一批数据进行训练后,对残差再进行训练建立新模型,以此类推,最终结果是各基模型的和。
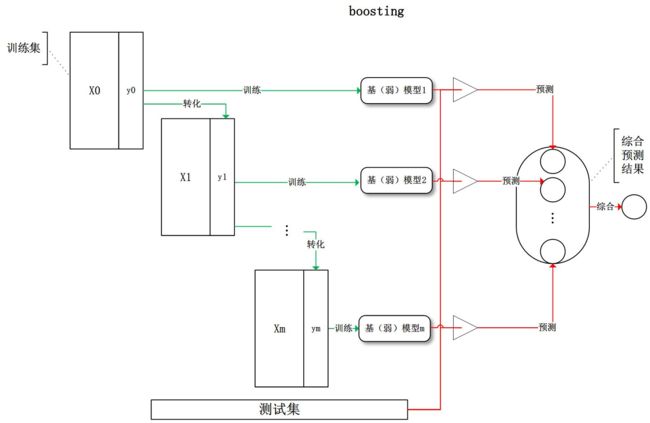
- Gradient Boosting:对一批数据进行训练后,对残差再进行训练建立新模型,以此类推,最终结果是各基模型的和。
- Stacking:将训练好的所有基模型对训练集进行预测,第 j j j个基模型以第 i i i个训练样本的预测值将作为其训练集中的第 i i i个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测
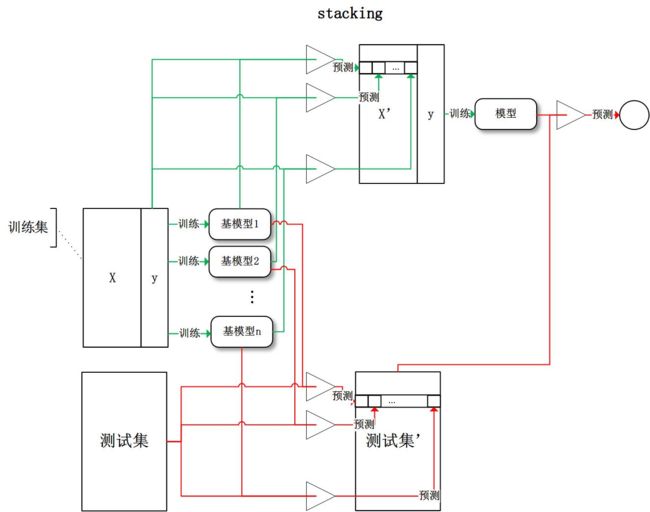
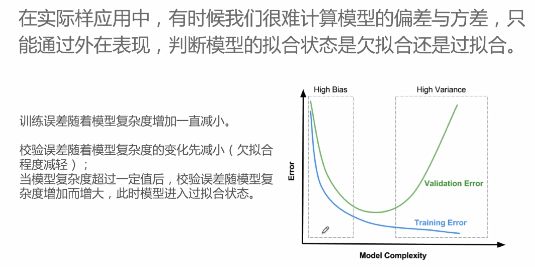
- 偏差和方差
偏差是预测值和真实值之间的差异,体现在训练集的准确度上;方差是预测值作为随机变量时预测结果的离散程度,体现在测试集的准确度上,方差大时容易过拟合。通过集合众多弱学习器来解决高偏差问题,基函数最好是低方差高偏差的。


一、Bagging
Bagging集成算法是Bootstrap Aggregating的缩写,对数据集通过有放回的随机采样建多个模型,各模型之间没有关系;对所有基模型预测的结果进行综合产生最终的预测结果,常用算数平均或最多票数的种类。对弱学习器没有限制,但常用的是决策树和神经网络。
随机采样(bootsrap)是从训练集里用有放回的方式抽取固定个数的样本,之前采集到的样本在放回后仍可能被抽到。
通常随机抽样后的形成的新样本集合大小和原数据集大小相同。若有 m m m个样本,则每次抽中概率为 1 m \frac{1}{m} m1,在 m m m次采样中都为被抽取到的概率是 ( 1 − 1 m ) m (1-\frac{1}{m})^m (1−m1)m,从而有 ( 1 − 1 m ) m → 1 e ≃ 0.368 (1-\frac{1}{m})^m \to \frac{1}{e} \simeq 0.368 (1−m1)m→e1≃0.368,即有约36.8%的样本会始终无法被采集。这部分样本成为袋外样本(Out Of Bag,OOB),通常用于检测模型泛化能力。
Bagging算法由于每次都用随机抽样来训练模型,因此泛化能力强,方差小,但由于未使用全部数据,偏差会大。
随机森林(Random Forest,RF)
随机森林建立在Bagging的基础上,用CART决策树作为弱学习器,对样本进行有放回的随机抽样(同原数据集大小),大小和元数据集相同;再对每个决策树的特征进行随机筛选(是在根节点,不再是全部特征;也可以理解为在节点划分上随机从特征中抽取选择最优划分特征);建每颗树时的有放回样本抽样会有约1/3样本无法被抽到,可用于做袋外估计(OOB,outofbag)来评估性能;最终一个样本的预测结果由各树进行投票或平均。
RandomForest只能接受数值型变量,对于分类变量,需要进行如One-Hot编码的转换。
【重点参数】各树间的相关性与决策树所用特征量有关,特征越多,相关性可能越强;减少使用的特征个数,树的相关性和分类能力都会降低。
【有放回抽样原因】每颗决策树都用完全不同的数据来构建,则每棵树都是“片面”的,缺少共性,对最终的汇总结果没有帮助。
【袋外估计】效果与K折交叉验证相似。
【优点】:可以给出各特征对于输出的重要性矩阵;产生的模型方差小,泛化能力强;采用袋外估计,无需进行K折交叉验证;可以并行计算,速度快;对缺失值不敏感。
【缺点】:对噪音较大的样本集容易过拟合;值比较多的特征容易对模型产生影响。
【特征重要性】判断每个特征在随机森林的每颗树上做了多大的贡献,然后取平均值即可。其中关于贡献的计算方式有:
- 基于基尼指数变化量:该特征在所有树中的变化和 V I M j = ∑ j _ t r e e ( ∑ i _ n o d e ( G b e f o r e _ s p l i t − G l e f t _ n o d e − G r i g h t _ n o d e ) ) VIM_j=\sum_{j\_tree}(\sum_{i\_node}(G_{before\_split}-G_{left\_node}-G_{right\_node})) VIMj=∑j_tree(∑i_node(Gbefore_split−Gleft_node−Gright_node)),之后再做归一化即可 V I M j ∑ V I M j \frac{VIM_j}{\sum VIM_j} ∑VIMjVIMj
- 基于袋外数据错误率:对于一树用OOB样本得到误差 e 1 e_1 e1;然后随机改变OOB中的第 j j j列中样本的顺序,并保持其他列不变,得到新的误差 e 2 e_2 e2。通过 e 1 − e 2 e_1-e_2 e1−e2 来刻画特征 j j j的重要性。依据是,如果一个特征很重要,那么其变动后会非常影响测试误差,如果测试误差没有怎么改变,则说明特征 j j j不重要。
打乱特征j的样本顺序由两种方法:
1)是使用均匀分布或者正态分布随机值来抽样替换原特征;
2)是通过permutation test(随机排序测试、置换检验)将原来的所有N个样本的第 j j j个特征值重新打乱分布(相当于重新洗牌),保证了特征替代值与原特征的分布是近似的(只是重新洗牌而已)。参考
- 经过结点的数目等指。可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的标准。随机森林基于不纯度的排序结果非常鲜明,在得分最高的几个特征之后的特征,得分急剧的下降。参考
随机森林的变种还有Extra Trees(每个决策树都用原始训练集,不抽样;选用随机特征值划分决策树)
随机森林的基评估器都拥有较低的偏差和较高的方差,因为决策树本身是预测比较”准“,比较容易过拟合的模型,装袋法本身也要求基分类器的准确率必须要有50%以上。所以以随机森林为代表的装袋法的训练过程旨在降低方差,即降低模型复杂度。
Extra Trees
Extra trees是基于随机森林,但样本使用原始训练集,在特征划分时随机选择特征并随机选择划分阈值进行划分(不再使用具体准则)。
极大的抑制了过拟合,但增加了拟合的偏差
Totally Random Trees Embedding
简称TRTE,是一种无监督的将低维的数据集映射到高维的方法,从而让映射到高维的数据可以更好的用于分类或回归。
TRTE在数据转化的过程用了类似于RF的方法,建立T个决策树来拟合数据。当决策树建立完毕后,数据集里的每个数据在T个决策树中叶节点的位置也定下来了。从而将样本在每颗决策树中用one-hot(在对应节点为1,不在为0)编码表示的结果按树的顺序合在一起,映射结果维度 n o u t ≤ N o d e ∗ T r e e n_out \le Node*Tree nout≤Node∗Tree。实际上是实现了高维离散化。
示例:有3颗决策树,每个决策树有5个叶子节点,某个数据特征x划分到第一个决策树的第2个叶子节点,第二个决策树的第3个叶子节点,第三个决策树的第5个叶子节点。则x映射后的特征编码为(0,1,0,0,0, 0,0,1,0,0, 0,0,0,0,1),有15维的高维特征。这里特征维度之间加上空格是为了强调三颗决策树各自的子编码。映射到高维特征后,可以继续使用监督学习的各种分类回归算法了。
Isolation Forest
简称IForest,是一种异常点监测方法。
随机采样时,所采子样本量远远小于原始训练集个数(通过部分数据来区分异常点)。每次建立决策树时,随机选择一个划分特征,并随机选择划分阈值。通过较小的决策树深度进行建模(少量异常点检测一般不用大规模树)。
对于异常点的判断是,将测试样本点 x x x用T颗树进行拟合,计算每颗决策树上该样本点所在的叶节点对应的深度 h t ( x ) h_t(x) ht(x),从而可计算平均高度 h ‾ t ( x ) \overline h_t(x) ht(x)。
样本点 x x x对应的异常概率为: s ( x , m ) = 2 − h ‾ ( x ) c ( m ) s(x,m)=2^{-\frac{\overline h(x)}{c(m)}} s(x,m)=2−c(m)h(x),其中 m m m是训练样本个数, c ( m ) = 2 l n ( m − 1 ) + ξ − 2 m − 1 m c(m)=2ln(m-1)+\xi -2\frac{m-1}{m} c(m)=2ln(m−1)+ξ−2mm−1, ξ \xi ξ是欧拉常数。
s ( x , m ) s(x,m) s(x,m)的取值范围是[0,1],取值越接近1,则 x x x是异常点的概率越大。
多输出任务
多输出任务是对一个输入样本会输出多个目标值(多个y,不是y的多个值)。以回归为例,对单输出任务是求解 θ \theta θ使得 X θ = Y X\theta=Y Xθ=Y,二多输出任务是求解 θ = ( θ 1 , θ 2 ) \theta=(\theta_1,\theta_2) θ=(θ1,θ2)使得 X ( θ 1 , θ 2 ) = ( Y 1 , Y 2 ) X(\theta_1,\theta_2)=(Y_1,Y_2) X(θ1,θ2)=(Y1,Y2)。对多输出任务,若各输出间相互独立,则多输出效果同多个单输出任务效果相似;但若各输出间有关联,则结果会不同与单输出任务的组合。
参考:https://www.cnblogs.com/pinard/p/6156009.html
二、Boosting(提升)
【工作机制】首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重。使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2。如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。

Boosting面临四个问题:
- 如何计算学习误差率 e e e?
- 如何得到弱学习器权重系数 α \alpha α?
- 如何更新样本权重向量 D D D?
- 使用何种结合策略?
AdaBoost算法
AdaBoost非常好的参考
AdaBoost算法(Adaptive Boost)可用于分类数据(二分类),对多分类任务,需要将任务通过OvR(一对多)转换成二分类任务;也可以用于回归。
AdaBoost每次都用全部数据,主要通过调整样本权重来建立各次迭代时的弱学习器。能够在学习过程中不断减少训练误差,且训练误差是以指数速度下降的。由于重视误分类样本的权重,因此对异常样本敏感,影响最终的强学习器的预测准确性。
AdaBoost算法可以认为是加法模型(弱学习器的线性组合)、损失函数为指数函数、学习算法为前向分布算法时的学习方法。
AdaBoost分类算法(自适应提升算法)
【思路】初始化时给数据集每个样本一个权重,用带权重的数据集来训练弱学习器。训练出模型后,针对这个模型中预测错误的样本,增加其权重值;对预测正确的样本,减少其权重。再根据计算出的误差给弱学习器一个权重。然后用新的样本权重调整后的样本继续训练新的弱学习器,重复得到B个模型。最后将B个弱学习器用对应的权重加总作为整体的强学习器。各弱学习器间相互依赖(样本权重受上一模型影响)。整个学习过程中使用的都是同一批样本,只是调整样本权重。
【过程】输入:训练集 T = { ( x , y 1 ) , ( x 2 , y 2 ) , . . . ( x m , y m ) } T=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\} T={ (x,y1),(x2,y2),...(xm,ym)};分类y={-1,+1}
- 初始化训练集的权值分布: D ( 1 ) = ( w 1 , 1 , w 1 , 2 , . . . w 1 , m ) ; w 1 , i = 1 m ; i = 1 , 2... m D(1) = (w_{1,1}, w_{1,2}, ...w_{1,m}) ;\;\; w_{1,i}=\frac{1}{m};\;\; i =1,2...m D(1)=(w1,1,w1,2,...w1,m);w1,i=m1;i=1,2...m
- 对 k = 1 、 2 、 … M k=1、2、…M k=1、2、…M
a) 使用有权值分布 D ( k ) D(k) D(k)的训练集学习得到分类器 G k ( x ) G_k(x) Gk(x)(输出0/1)
b) 计算 G k ( x ) G_k(x) Gk(x)在训练集上的分类误差率: e k = ∑ P ( G k ( x i ) ≠ y i ) = ∑ w k , i I ( G k ( x i ) ≠ y i ) e_k=\sum{P(G_k(x_i)≠y_i)}=\sum{w_{k,i}I(G_k(x_i)≠y_i)} ek=∑P(Gk(xi)=yi)=∑wk,iI(Gk(xi)=yi)( I ( G k ( x i ) ≠ y i ) I(G_k(x_i)≠y_i) I(Gk(xi)=yi)是指示函数,与实际类不相同时取1,相同时取0。分类误差率是与实际类别不同的样本的权值和)
c) 计算 G k ( x ) G_k(x) Gk(x)的系数 α m = 1 2 l o g 1 − e k e k \alpha_m=\frac{1}{2}log\frac{1-e_k}{e_k} αm=21logek1−ek,表示基本分类器 G m ( x ) G_m(x) Gm(x)的重要性。误差越小 α \alpha α值越大: e k > 0.5 时 α < 0 e_k>0.5时\alpha <0 ek>0.5时α<0; e k < 0.5 时 α > 0 e_k<0.5时\alpha >0 ek<0.5时α>0。
d) 更新数据集的权值分布: D ( k + 1 ) = ( w k + 1 , 1 , w k + 1 , 2 , . . . w k + 1 , m ) D(k+1)= (w_{k+1,1}, w_{k+1,2}, ...w_{k+1,m}) D(k+1)=(wk+1,1,wk+1,2,...wk+1,m),
其中 w k + 1 , i = w k , i Z k e − α k y i G k ( x i ) w_{k+1,i}=\frac{w_{k,i}}{Z_k}e^{-\alpha_ky_iG_k(x_i)} wk+1,i=Zkwk,ie−αkyiGk(xi), Z k = ∑ w k , i e − α k y i G k ( x i ) Z_k=\sum{w_{k,i}e^{-\alpha_ky_iG_k(x_i)}} Zk=∑wk,ie−αkyiGk(xi)
实际就是分别改变误分类样本和正确分类样本的权重,使正确分类的权值减小,错误分类的权值变大。 - 构建基本分类器的线性组合: f ( x ) = ∑ α k G k ( x ) = f k − 1 ( x ) + α k G k ( x ) f(x)=\sum{\alpha_kG_k(x)}= f_{k-1}(x) + \alpha_kG_k(x) f(x)=∑αkGk(x)=fk−1(x)+αkGk(x)。 f ( x ) > 0 时 y ^ = 1 f(x)>0时\hat y=1 f(x)>0时y^=1; f ( x ) < 0 时 y ^ = 0 f(x)<0时\hat y=0 f(x)<0时y^=0。 f ( x ) f(x) f(x)值大小反映对应类的预测置信度。
也可以对弱学习器添加正则项(学习步长): f k ( x ) = f k − 1 ( x ) + ν α k G k ( x ) f_{k}(x) = f_{k-1}(x) + \nu\alpha_kG_k(x) fk(x)=fk−1(x)+ναkGk(x), 0 < ν ≤ 1 0 < \nu \leq 1 0<ν≤1。 - 到达指定迭代次数(还可以对树进行限制)或分类误差率达到一定值后停止迭代,得到最终的分类器: G ( x ) = s i g n ( f ( x ) ) = s i g n ( ∑ α k G k ( x ) ) G(x)=sign(f(x))=sign(\sum{\alpha_kG_k(x)}) G(x)=sign(f(x))=sign(∑αkGk(x))
【Adaboost是前向分步学习算法】对第k轮迭代: f k ( x ) = f k − 1 ( x ) + α k G k ( x ) f_{k}(x) = f_{k-1}(x) + \alpha_kG_k(x) fk(x)=fk−1(x)+αkGk(x)
【损失函数为指数函数】定义总体损失函数 a r g m i n ⏟ α , G ∑ i = 1 m e x p ( − y i f k ( x ) ) \underbrace{arg\;min\;}_{\alpha, G} \sum\limits_{i=1}^{m}exp(-y_if_{k}(x)) α,G argmini=1∑mexp(−yifk(x))
利用前向分步学习算法的关系可以得到损失函数为 ( α k , G k ( x ) ) = a r g m i n ⏟ α , G ∑ i = 1 m e x p [ ( − y i ) ( f k − 1 ( x ) + α k G k ( x ) ) ] (\alpha_k, G_k(x)) = \underbrace{arg\;min\;}_{\alpha, G}\sum\limits_{i=1}^{m}exp[(-y_i) (f_{k-1}(x) + \alpha_kG_k(x))] (αk,Gk(x))=α,G argmini=1∑mexp[(−yi)(fk−1(x)+αkGk(x))]
令 w k i ′ = e x p ( − y i f k − 1 ( x ) ) w_{ki}^{'} = exp(-y_if_{k-1}(x)) wki′=exp(−yifk−1(x)),它的值不依赖于 α , G \alpha, G α,G,是上一轮中确定的结果,仅仅依赖于 f k − 1 ( x ) f_{k−1}(x) fk−1(x),随着每一轮迭代而改变,与本轮最小化时所求 G k G_k Gk无关。从而有 ( α k , G k ( x ) ) = a r g m i n ⏟ α , G ∑ i = 1 m w k i ′ e x p [ − y i α k G k ( x ) ] (\alpha_k, G_k(x)) = \underbrace{arg\;min\;}_{\alpha, G}\sum\limits_{i=1}^{m}w_{ki}^{'}exp[-y_i\alpha_k G_k(x)] (αk,Gk(x))=α,G argmini=1∑mwki′exp[−yiαkGk(x)]。
又由于 G k ( x ) = a r g m i n ⏟ G ∑ i = 1 m w k i ′ I ( y i ≠ G ( x i ) ) G_k(x) = \underbrace{arg\;min\;}_{G}\sum\limits_{i=1}^{m}w_{ki}^{'}I(y_i \neq G(x_i)) Gk(x)=G argmini=1∑mwki′I(yi=G(xi)),从而带入损失函数,对 α \alpha α求导并使其为0,可得: α k = 1 2 l o g 1 − e k e k \alpha_k = \frac{1}{2}log\frac{1-e_k}{e_k} αk=21logek1−ek
e k e_k ek即为我们前面的分类误差率: e k = ∑ i = 1 m w k i ’ I ( y i ≠ G ( x i ) ) ∑ i = 1 m w k i ’ = ∑ i = 1 m w k i I ( y i ≠ G ( x i ) ) e_k = \frac{\sum\limits_{i=1}^{m}w_{ki}^{’}I(y_i \neq G(x_i))}{\sum\limits_{i=1}^{m}w_{ki}^{’}} = \sum\limits_{i=1}^{m}w_{ki}I(y_i \neq G(x_i)) ek=i=1∑mwki’i=1∑mwki’I(yi=G(xi))=i=1∑mwkiI(yi=G(xi))
【何时停止建树??】


Adaboost回归算法
对于第 k k k个弱学习器,总体最大误差: E k = m a x ∣ y i − G k ( x i ) ∣ i = 1 , 2... m E_k= max|y_i - G_k(x_i)|\;i=1,2...m Ek=max∣yi−Gk(xi)∣i=1,2...m
对每个样本的误差根据不同定义可以有:若为线性误差,则 e k i = ∣ y i − G k ( x i ) ∣ E k e_{ki}= \frac{|y_i - G_k(x_i)|}{E_k} eki=Ek∣yi−Gk(xi)∣;若为平方误差,则时 e k i = ( y i − G k ( x i ) ) 2 E k 2 e_{ki}= \frac{(y_i - G_k(x_i))^2}{E_k^2} eki=Ek2(yi−Gk(xi))2;若为指数误差,则 e k i = 1 − e x p ( − y i + G k ( x i ) ) E k ) e_{ki}=1-exp(\frac{-y_i + G_k(x_i))}{E_k}) eki=1−exp(Ek−yi+Gk(xi)))。
最终得到第k个弱学习器的误差率: e k = ∑ i = 1 m w k i e k i e_k = \sum\limits_{i=1}^{m}w_{ki}e_{ki} ek=i=1∑mwkieki
第k个弱学习器的样本 i i i的权重 α k , i = e k , i 1 − e k , i \alpha_{k,i}=\frac{e_{k,i}}{1-e_{k,i}} αk,i=1−ek,iek,i,则第 k + 1 k+1 k+1个弱学习器的样本集权重系数为 w k + 1 , i = w k i Z k α k 1 − e k i w_{k+1,i}=\frac{w_{ki}}{Z_k}\alpha_k^{1-e_{ki}} wk+1,i=Zkwkiαk1−eki,其中 Z k = ∑ i = 1 m w k i α k 1 − e k i Z_k = \sum\limits_{i=1}^{m}w_{ki}\alpha_k^{1-e_{ki}} Zk=i=1∑mwkiαk1−eki。
弱学习器的结合策略是对加权的弱学习器,取权重倒数的对数的中位数对应的弱学习器作为强学习器,最终的强回归器为 f ( x ) = G k ∗ ( x ) f(x) =G_{k^*}(x) f(x)=Gk∗(x), G k ∗ ( x ) G_{k^*}(x) Gk∗(x)是 l n 1 α k , k = 1 , 2 , . . . . K ln\frac{1}{\alpha_k}, k=1,2,....K lnαk1,k=1,2,....K的中位数值对应序号 k ∗ k^∗ k∗对应的弱学习器。
梯度提升Gradient boosting
一、理论推导
梯度提升算法是以基函数为变量求解损失函数最小化,基于加法模型,利用前向分布算法,根据泰勒一阶展开式得出基函数尽可能拟合上一模型的负梯度时,能够使损失函数最小化,实现逐渐逼近总体损失函数的局部最优值。
称为Gradient是因为在添加新模型时用了梯度下降算法来实现损失函数最小化。
【加法模型】 F ( x ) = ∑ β m f m ( x ) F(x)=\sum \beta_mf_m(x) F(x)=∑βmfm(x)
【前向分布算法】 F t ( x ) = F t − 1 ( x ) + β t f t ( x ) F_t(x)=F_{t-1}(x)+\beta_tf_t(x) Ft(x)=Ft−1(x)+βtft(x)
【损失函数】总体模型的损失函数: L ( y , F ( x ) ) = ∑ N L ( y i , ∑ m β m f m ( x i ) ) L(y, F(x))=\sum^N L(y_i, \sum^m\beta_mf_m(x_i)) L(y,F(x))=∑NL(yi,∑mβmfm(xi))
【泰勒一阶展开式】 f ( x + Δ x ) = f ( x ) + Δ f ′ ( x ) f(x+\Delta x)=f(x)+\Delta f'(x) f(x+Δx)=f(x)+Δf′(x)
【梯度下降】由于损失 L ( y , F ( x ) ) = ∑ N L ( y i , ∑ m β t f t ( x i ) ) = ∑ L ( y i , F t − 1 ( x i ) + β t f t ( x i ) ) L(y, F(x))=\sum^N L(y_i, \sum^m\beta_tf_t(x_i))=\sum L(y_i, F_{t-1}(x_i)+\beta_tf_t(x_i)) L(y,F(x))=∑NL(yi,∑mβtft(xi))=∑L(yi,Ft−1(xi)+βtft(xi))是关于 F ( x ) F(x) F(x)的函数,对与每个样本,根据一阶泰勒展开式可得 L ( y i , F t − 1 ( x i ) + β t f t ( x i ) ) ≈ F t − 1 ( x i ) + β t f t ( x i ) L ( y i , F t − 1 ( x i ) ) F t − 1 ( x i ) L(y_i, F_{t-1}(x_i)+\beta_tf_t(x_i)) \approx F_{t-1}(x_i)+\beta_t f_t(x_i)\frac{L(y_i,F_{t-1}(x_i))}{F_{t-1}(x_i)} L(yi,Ft−1(xi)+βtft(xi))≈Ft−1(xi)+βtft(xi)Ft−1(xi)L(yi,Ft−1(xi))。由于 β t > 0 \beta_t\gt0 βt>0,从而根据梯度下降知识可知,当 f t ( x i ) = − L ( y i , F t − 1 ( x i ) ) F t − 1 ( x i ) f_t(x_i)=-\frac{L(y_i, F_{t-1}(x_i))}{F_{t-1}(x_i)} ft(xi)=−Ft−1(xi)L(yi,Ft−1(xi))(梯度下降)时有(平方项大于0), L ( y i , F t − 1 ( x i ) ) ≥ L ( y i , F t ( x i ) ) L(y_i,F_{t-1}(x_i))\ge L(y_i,F_t(x_i)) L(yi,Ft−1(xi))≥L(yi,Ft(xi))。此时可成功降低每个样本点上的预测损失。从而有 F t ( x ) = F t − 1 ( x ) + f t ( x ) F_t(x)=F_{t-1}(x)+f_t(x) Ft(x)=Ft−1(x)+ft(x)。参考,非常好的参考
以上是基于损失函数对总体模型 F ( x ) F(x) F(x)可导的,但 F ( x ) F(x) F(x)是否关于x可导不一定(即 f ( x ) f(x) f(x)是否对x可导)。
对于 β t \beta_t βt可以通过以为搜索找到: β t = a r g m i n β ∑ L ( y i , h t − 1 ( x i ) + β f t ( x i ) ) \beta_t=argmin_{\beta}\sum L(y_i, h_{t-1}(x_i)+\beta f_t(x_i)) βt=argminβ∑L(yi,ht−1(xi)+βft(xi))。
对初始的 f 0 ( x ) f_0(x) f0(x),可以用常量,如均值等。
对于不同的基函数、不同的损失函数,都可以用上述解法来做。当损失函数为 L ( F ) = ( y − F ) 2 L(F)=(y-F)^2 L(F)=(y−F)2时, 对 F F F的导数(不是对x求导)是 2 ( y − F ) 2(y-F) 2(y−F),这就是残差,从而新的函数 f m ( x ) f_m(x) fm(x)对伪残差的最大拟合实际就是对上轮迭代所得残差的最大拟合。若损失函数为其他函数时未必。
如此迭代不断找到新的 f ( x ) f(x) f(x)使总体损失函数变小,此方法即为梯度提升。
【推导方法二】
若 L L L关于 F F F二阶可导,还可以从极值角度考虑,令 L ′ = 0 L'=0 L′=0,而 L ′ L' L′可用泰勒展开式进行展开,从而可以计算出 f m f_m fm的具体形式参考:

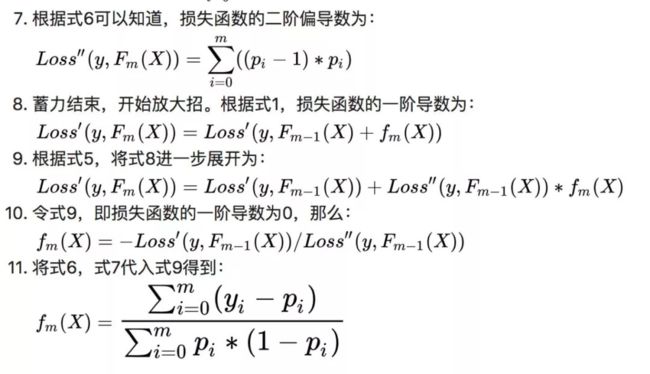
二、损失函数和梯度
【回归任务】
均方误差损失函数 L ( y m , F m ( x ) ) = 1 2 ( y − F m ( x ) ) 2 L(y_m, F_{m}(x))=\frac{1}{2}(y-F_{m}(x))^2 L(ym,Fm(x))=21(y−Fm(x))2此时梯度就是残差 y − F ( x ) y-F(x) y−F(x)。
绝对损失函数 L ( y , F ( x ) ) = ∣ y − F ( x ) ∣ L(y, F(x))=|y-F(x)| L(y,F(x))=∣y−F(x)∣,梯度是 s i g n ( y − F ( x ) ) sign(y-F(x)) sign(y−F(x))。
【分类任务】
二分类任务用逻辑回归的损失函数(logistic loss): L ( y , F ( x ) ) = y l o g p + ( 1 − y ) l o g ( 1 − p ) L(y,F(x))=ylogp+(1-y)log(1-p) L(y,F(x))=ylogp+(1−y)log(1−p),其中 p = 1 1 + e − F ( x ) p=\frac{1}{1+e^{-F(x)}} p=1+e−F(x)1,梯度是 y − 1 1 + e − F m − 1 ( x ) y-\frac{1}{1+e^{-F_{m-1}(x)}} y−1+e−Fm−1(x)1。
多分类任务使用Sofmax的损失函数。
指数损失函数 L ( y m , F m ( x ) ) = e ( − y ∗ F m ( x ) ) L(y_m, F_{m}(x))=e^{(-y*F_m(x))} L(ym,Fm(x))=e(−y∗Fm(x))。当损失函数为指数函数式,梯度提升算法相当于二分类的Adaboost算法参考
【示例】以逻辑回归为例,对每个类,预测其概率时,形成 y ^ ( i ) = ( p 1 , p 2 , p n ) \hat y^{(i)}=(p_1,p_2,p_n) y^(i)=(p1,p2,pn),对实际所属类可视为概率1,其余为0,如 y ( i ) = ( 1 , 0 , 0 ) y^{(i)}=(1,0,0) y(i)=(1,0,0),从而可以计算 y ^ ( i ) \hat y^{(i)} y^(i)与 y ( i ) y^{(i)} y(i)间的距离,从而构造 f ( x ) f(x) f(x)的损失函数并计算伪残差,之后再对该伪残差继续用逻辑回归建模,理论上直到所有残差为零时(或达到阈值)停止。分类的损失函数可以是预测类与真实类不一致的数量、叶节点的熵按叶节点占总体样本的比重做加权后的值……。
三、优化方法
【正则化】在使用提升方法时,通常会在模型权值基础上再增加一个学习率 v v v(衰减因子Shrinkage),将上轮迭代的结果以一定比例缩减,削弱每个基函数的影响,让后面有更大的学习空间: F t ( x ) = F t − 1 ( x ) + v ⋅ β t f t ( x ) F_t(x)=F_{t-1}(x)+v·\beta_tf_t(x) Ft(x)=Ft−1(x)+v⋅βtft(x)。一般会把学习率设置得小一点( v < 0.1 v\lt 0.1 v<0.1),然后迭代次数设置得大一点。
另外在每次迭代时对样本可以进行随机无放回抽样,从而增加模型随机性,减小方差,即随机梯度提升SGD方法。
梯度提升树GBDT(Gradient Boosting Decision Tree)
参考1 参考2 很好的参考
【特点】梯度提升树是基函数为CART回归树的梯度提升法的应用。GBDT的核心在于每次对上轮所得总体模型的负梯度进行拟合(损失函数是均方误差时就是对上轮残差进行拟合),通过累加所有树的结果作为最终结果(分类树的结果无法累加,故GBDT中的树都是回归树)。虽然调整后可用于分类任务(通过基函数返回概率),但基函数不是分类学习器。最终结果是对各树结果的加权求和得到总体结果
GBDT主要由三个概念组成:Regression Decistion Tree(即DT),Gradient Boosting(即GB),Shrinkage (算法的一个重要演进分枝,目前大部分源码都按该版本实现)
【基函数】最好是低方差和高偏差的,从而可以通过多次迭代减小偏差。
CART决策树不用很深,可接受单个基函数的高偏差,通过集合来减小偏差。
【损失函数】GBDT可以用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
【A、分类算法常用损失函数】:
- 指数损失函数 L ( y , f ( x ) ) = e x p ( − y f ( x ) ) L(y, f(x)) = exp(-yf(x)) L(y,f(x))=exp(−yf(x)),其负梯度计算和叶节点的最佳负梯度拟合参见Adaboost。
- 对数损失函数,分为二元分类和多元分类两种。
B、回归算法常用损失函数】:
- 均方差 L ( y , f ( x ) ) = ( y − f ( x ) ) 2 L(y, f(x)) =(y-f(x))^2 L(y,f(x))=(y−f(x))2
- 绝对损失 L ( y , f ( x ) ) = ∣ y − f ( x ) ∣ L(y, f(x)) =|y-f(x)| L(y,f(x))=∣y−f(x)∣,对应负梯度为: s i g n ( y i − f ( x i ) ) sign(y_i-f(x_i)) sign(yi−f(xi))
- Huber损失,是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下: L ( y , f ( x ) ) = { 1 2 ( y − f ( x ) ) 2 ∣ y − f ( x ) ∣ ≤ δ δ ( ∣ y − f ( x ) ∣ − δ 2 ) ∣ y − f ( x ) ∣ > δ L(y, f(x))= \begin{cases} \frac{1}{2}(y-f(x))^2& {|y-f(x)| \leq \delta}\\ \delta(|y-f(x)| - \frac{\delta}{2})& {|y-f(x)| > \delta} \end{cases} L(y,f(x))={ 21(y−f(x))2δ(∣y−f(x)∣−2δ)∣y−f(x)∣≤δ∣y−f(x)∣>δ。对应负梯度误差是: r ( y i , f ( x i ) ) = { y i − f ( x i ) ∣ y i − f ( x i ) ∣ ≤ δ δ s i g n ( y i − f ( x i ) ) ∣ y i − f ( x i ) ∣ > δ r(y_i, f(x_i))= \begin{cases} y_i-f(x_i)& {|y_i-f(x_i)| \leq \delta}\\ \delta sign(y_i-f(x_i))& {|y_i-f(x_i)| > \delta} \end{cases} r(yi,f(xi))={ yi−f(xi)δsign(yi−f(xi))∣yi−f(xi)∣≤δ∣yi−f(xi)∣>δ
- 分位数损失函数,对应的是分位数回归的损失函数: L ( y , f ( x ) ) = ∑ y ≥ f ( x ) θ ∣ y − f ( x ) ∣ + ∑ y < f ( x ) ( 1 − θ ) ∣ y − f ( x ) ∣ L(y, f(x)) =\sum\limits_{y \geq f(x)}\theta|y - f(x)| + \sum\limits_{y < f(x)}(1-\theta)|y - f(x)| L(y,f(x))=y≥f(x)∑θ∣y−f(x)∣+y<f(x)∑(1−θ)∣y−f(x)∣, 其中 θ \theta θ为分位数,需要我们在回归前指定。对应的负梯度误差为: r ( y i , f ( x i ) ) = { θ y i ≥ f ( x i ) θ − 1 y i < f ( x i ) r(y_i, f(x_i))= \begin{cases} \theta& { y_i \geq f(x_i)}\\ \theta - 1 & {y_i < f(x_i) } \end{cases} r(yi,f(xi))={ θθ−1yi≥f(xi)yi<f(xi)
对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
【正则化】:
- 一种是对弱学习器添加学习率。
- 第二种正则化的方式是通过子采样比例(subsample)。取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。
使用了子采样的GBDT有时也称作随机梯度提升树(Stochastic Gradient Boosting Tree, SGBT)。由于使用了子采样,程序可以通过采样分发到不同的任务去做boosting的迭代过程,最后形成新树,从而减少弱学习器难以并行学习的弱点。通过自采样的SGBT可以达到部分并行 - 第三种是对于弱学习器即CART回归树进行正则化剪枝。
GBDT回归算法
每次随机无放回抽样建立CART决策树,总体损失函数用均方差(决策树的损失函数依赖于决策树)。对第 t t t轮迭代,有上一次迭代的残差(伪残差) r t − 1 , i r_{t-1,i} rt−1,i。参考 过程示例
- 利用 ( x i , r t − 1 , i ) ( i = 1 , 2 , . . n ) (x_i,r_{t-1,i})\;\; (i=1,2,..n) (xi,rt−1,i)(i=1,2,..n)拟合一颗CART回归树,对应的叶节点区域 R t j , j = 1 , 2 , . . . , J R_{tj}, j =1,2,..., J Rtj,j=1,2,...,J,其中 J J J为叶节点的个数。每一个叶结点的样本都可以使CART回归决策树的损失函数最小(拟合叶子节点中的残差最好),叶节点的输出值 b m j b_{mj} bmj如下:
b t j = a r g m i n ⏟ b ∑ x i ∈ R t j L ( y i , f t − 1 ( x i ) + b ) b_{tj} = \underbrace{arg\; min}_{b}\sum\limits_{x_i \in R_{tj}} L(y_i,f_{t-1}(x_i) +b) btj=b argminxi∈Rtj∑L(yi,ft−1(xi)+b)。即用标签(上轮的残差或梯度值)的平均值表示该叶子节点拟合到的值: b t j = a v e x i ∈ R m j r t − 1 , i b_{tj}=ave_{ x_i\in R_{mj}}r_{t-1,i} btj=avexi∈Rmjrt−1,i。 - 得到本轮的决策树拟合函数如下: h t ( x ) = ∑ j = 1 J b t j I ( x ∈ R t j ) h_t(x) = \sum\limits_{j=1}^{J}b_{tj}I(x \in R_{tj}) ht(x)=j=1∑JbtjI(x∈Rtj)。
从而本轮得到的强学习器: F t ( x ) = F t − 1 ( x ) + γ t f t ( x ) = F t − 1 ( x ) + ∑ j = 1 J b t j I ( x ϵ R t j ) F_{t}(x) = F_{t-1}(x)+\gamma_{t}f_t(x)=F_{t-1}(x)+\sum_{j=1}^{J}b_{tj}I(x \epsilon R_{tj}) Ft(x)=Ft−1(x)+γtft(x)=Ft−1(x)+∑j=1JbtjI(xϵRtj)
b t j b_{tj} btj可以看作是基于损失函数 L L L的每个叶子节点的最理想的常数更新值,也可以认为是既有下降方向,又有下降步长的值。
树的建立依赖于树模型自身(如用基尼指数作为分割准则),之后获得伪残差才是关键。
【问题】具体如何确定各树的权重
GBDT分类算法:二分类
过程同GBDT回归算法,但使用损失函数不同:用指数损失函数,则GBDT退化为Adaboost算法;用对数似然损失函数,类似逻辑回归,可得到预测概率值。参考
A)以对数似然损失函数logloss作为损失函数为例: y ∈ { 0 , 1 } y \in \{0,1\} y∈{ 0,1}好示例参考 参考
- 选取对数似然函数为损失函数:
L ( y i , F m ( x i ) ) = − l n ( p i y i ( 1 − p i ) ( 1 − y i ) ) = − ( y i l o g p i + ( 1 − y i ) l o g ( 1 − p i ) ) \large L\left(y_i,F_m(x_i)\right)=-ln(p_i^{y_i}(1-p_i)^{(1-y_i)})=-(y_ilogp_i+(1-y_i)log(1-p_i)) L(yi,Fm(xi))=−ln(piyi(1−pi)(1−yi))=−(yilogpi+(1−yi)log(1−pi)),其中 p i = 1 1 + e − F ( x i ) \large p_i=\frac{1}{1+e^{-F(x_i)}} pi=1+e−F(xi)1是标签为1的概率。将 p i p_i pi带入可得 L ( y i , F m ( x i ) ) = − ( y i F m ( x i ) − l o g ( 1 + e F m ( x i ) ) ) \large L\left(y_i,F_m(x_i)\right)=-(y_iF_m(x_i)-log(1+e^{F_m(x_i)})) L(yi,Fm(xi))=−(yiFm(xi)−log(1+eFm(xi)))。 F ( x i ) = l o g ( p i 1 − p i ) F(x_i)=log(\frac{p_i}{1-p_i}) F(xi)=log(1−pipi) - 初始化: F 0 ( x ) = l o g ( ∑ i = 1 N y i ∑ i = 1 N ( 1 − y i ) ) F_0(x)=log\left(\frac{\sum_{i=1}^N y_i}{\sum_{i=1}^N(1-y_i)}\right) F0(x)=log(∑i=1N(1−yi)∑i=1Nyi),以样本中标签为1类的样本与标签为0类的样本量之比的对数(对数几率)作为 F 0 ( x ) F_0(x) F0(x)的初始值(第一次预测)。
F ( x ) F(x) F(x)就是模型最终输出的连续值,是样本 x x x经过所建立的多棵树后,在每棵树中对应叶节点的梯度的累加。 F ( x ) F(x) F(x)可看做是逻辑回归中的 f ( x ) = w T x f(x)=w^Tx f(x)=wTx。将最终输出 F ( x ) F(x) F(x)通过Sigmod函数可转换为对应的概率。通过不断拟合F来得到更好的p,从而获得与真实概率(0/1)最接近的预测概率p。 - 在第 m m m轮( m ≥ 1 m \ge 1 m≥1)迭代中, 损失函数 L L L所对应的负梯度为: r i = − [ ∂ L ( y i , F ( x i ) ) ∂ F ( x i ) ] F ( x ) = F m − 1 ( x ) = y i − 1 1 + e − F m − 1 ( x i ) = y i − p ^ i \large r_i=-\left[\frac{\partial L(y_i,F(\mathbf{x}_i))}{\partial F(\mathbf{x}_i)}\right]_{F(x)=F_{m-1}(x)}=y_i-\frac{1}{1+e^{-F_{m-1}(x_i)}}=y_i-\hat p_i ri=−[∂F(xi)∂L(yi,F(xi))]F(x)=Fm−1(x)=yi−1+e−Fm−1(xi)1=yi−p^i, y i y_i yi是标签为1对应的概率0/1。每次拟合的相当于是 w T x w^Tx wTx部分的残差,可转化为剩余的概率(预测为1)。
- 令对数似然函数对 F 0 ( x ) F_0(x) F0(x)求导后的梯度 r 0 r_0 r0为零,可求解出最优解的 F 0 ( x ) = l o g ( ∑ i = 1 N y i ∑ i = 1 N ( 1 − y i ) ) F_0(x)=log\left(\frac{\sum_{i=1}^N y_i}{\sum_{i=1}^N(1-y_i)}\right) F0(x)=log(∑i=1N(1−yi)∑i=1Nyi)。从而可以由 F 0 F_0 F0计算对应的负梯度 r 0 r_0 r0,之后开始对梯度进行拟合。
- 对 ( x , r m − 1 ) (x, r_{m-1}) (x,rm−1)用CART回归树进行最优拟合(可对决策树的生成进行具体设置,树不易过深),所得决策树叶节点 j j j对应的估计值计算公式为:
γ m j = ∑ x i ∈ R m j r m − 1 , i ∑ x i ∈ R m j ( y i − r m − 1 , i ) ⋅ ( 1 − y i + r m − 1 , i ) \gamma_{mj} =\frac{\sum_{x_i\in R_{mj} \large r_{m-1,i}}}{\sum_{x_{i} \in R_{mj}} \large( y_i - r_{m-1,i})·(1-y_i+\large r_{m-1,i})} γmj=∑xi∈Rmj(yi−rm−1,i)⋅(1−yi+rm−1,i)∑xi∈Rmjrm−1,i( L ′ = 0 L'=0 L′=0时 L L L可获极值,而 L ′ L' L′可按泰勒展开式展开一次,从而可解得 f m ( x ) = ∑ y i − p i ∑ p i ∗ ( 1 − p i ) f_m(x)=\frac{\sum y_i-p_i}{\sum p_i*(1-p_i)} fm(x)=∑pi∗(1−pi)∑yi−pi,将 p p p由 r = y − p r=y-p r=y−p表示即可参考), r m − 1 , i \large r_{m-1,i} rm−1,i是样本 x i x_i xi在上轮中的梯度值, R m j R_{mj} Rmj是第 m m m轮生成的第 j j j个叶节点构成的空间 R R R。实际是模型乘以模型对应的权重后的结果,可以认为是既有负梯度方向(树实现了对上轮的梯度的最大拟合),又有学习步长的值。 - 综上,第 m m m轮迭代后,总体模型 F m ( x ) = F m − 1 ( x ) + ∑ j = 1 J γ m j I ( x ∈ R m j ) F_m(x)=F_{m-1}(x)+\sum_{j=1}^J\large \gamma_{mj} I(x \in R_{mj}) Fm(x)=Fm−1(x)+∑j=1JγmjI(x∈Rmj), I ( x ∈ R m j ) I(x\in R_{mj}) I(x∈Rmj)是当 x x x在第 m m m颗树的第 j j j叶节点空间 R R R时为1,否则为0。
属于1分类的概率为 p i = 1 1 + e − F ( x i ) \large p_i=\frac{1}{1+e^{-F(x_i)}} pi=1+e−F(xi)1;属于0分类的概率为 p i = e − F ( x i ) 1 + e − F ( x i ) \large p_i=\frac{e^{-F(x_i)}}{1+e^{-F(x_i)}} pi=1+e−F(xi)e−F(xi) - 重复3~6,直到达到指定迭代次数、梯度变化小于阈值时停止。
B)以指数损失作为损失函数为: y ∈ { − 1 , + 1 } y \in\{-1, +1\} y∈{ −1,+1}
- 损失函数: L ( y , F ( x ) ) = l o g ( 1 + e x p ( − 2 y F ( x ) ) ) L(y, F(x)) = log(1+ exp(-2yF(x))) L(y,F(x))=log(1+exp(−2yF(x))), F ( x ) = 1 2 l o g [ P r ( y = 1 ∣ x ) P r ( y = − 1 ∣ x ) ] F(x)=\frac{1}{2}log[\frac{Pr(y=1|x)}{Pr(y=-1|x)}] F(x)=21log[Pr(y=−1∣x)Pr(y=1∣x)],其中 P r ( y = 1 ∣ x ) Pr(y=1|x) Pr(y=1∣x)是预测 x x x为1的概率, P r ( y = − 1 ∣ x ) Pr(y=-1|x) Pr(y=−1∣x)是预测x为-1的概率。
- 对应负梯度为: r m − 1 , i = − [ ∂ L ( y , F ( x i ) ) ) ∂ F ( x i ) ] F ( x ) = F m − 1 ( x ) = 2 y i 1 + e x p ( 2 y i F m − 1 ( x i ) ) r_{m-1,i} = -\bigg[\frac{\partial L(y, F(x_i)))}{\partial F(x_i)}\bigg]_{F(x) = F_{m-1}\;\; (x)} = \frac{2y_i}{1+exp(2y_iF_{m-1}(x_i))} rm−1,i=−[∂F(xi)∂L(y,F(xi)))]F(x)=Fm−1(x)=1+exp(2yiFm−1(xi))2yi
- 初始化 F 0 ( x ) F_0(x) F0(x),之后和计算出 R 0 , i R_{0,i} R0,i
- 第 m m m轮迭代中,用 ( x , r m − 1 ) (x, r_{m-1}) (x,rm−1)构建决策树,对 r m − 1 r_{m-1} rm−1进行拟合,从而决策树的叶节点 j j j的估计值计算公式为:
γ m j = a r g m i n r ∑ x i ∈ R m j l o g ( 1 + e x p ( − 2 y i ( F m − 1 ( x i ) + γ ) ) ) \gamma_{mj} = argmin_{r}\sum_{x_{i}\in R_{mj}} log(1+exp(-2y_{i}(F_{m-1}(x_{i})+\gamma))) γmj=argminr∑xi∈Rmjlog(1+exp(−2yi(Fm−1(xi)+γ)))
一般用近似结果: γ m j = ∑ x i ∈ R m j r m − 1 , i ∑ x i ∈ R m j ∣ r m − 1 , i ∣ ( 2 − ∣ r m − 1 , i ∣ ) \gamma_{mj}=\frac{\sum_{x_{i} \in R_{mj}} \large r_{m-1, i} }{\sum_{x_{i} \in R_{mj}} |\large r_{m-1, i}|(2-|\large r_{m-1, i}|) } γmj=∑xi∈Rmj∣rm−1,i∣(2−∣rm−1,i∣)∑xi∈Rmjrm−1,i - 最终输出模型为 F m ( x ) = F m − 1 ( x ) + γ m j I ( x i ∈ R t j ) F_m(x)=F_{m-1}(x)+\gamma_{mj}I(x_i \in R_{tj}) Fm(x)=Fm−1(x)+γmjI(xi∈Rtj),从而有 p + ( x ) = p = 1 1 + e − 2 F ( x ) p_{+}(x)=p= \frac{1}{1+e^{-2F(x)}} p+(x)=p=1+e−2F(x)1, p − ( x ) = 1 − p = 1 1 + e 2 F ( x ) p_{-}(x)=1-p= \frac{1}{1+e^{2F(x)}} p−(x)=1−p=1+e2F(x)1。从而可以利用概率进行分类。
除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索,二元GBDT分类和GBDT回归算法过程相同。
GBDT分类算法:多分类
采用OvR,实质上是在每轮训练时都是同时训练多颗树:是否A类一颗树,是否B类一个数,是否C类一棵树…,真实类的概率视为1,其余视为0,从而可以计算负梯度(残差),损失函数用对数似然损失函数。非常好的实例参考
对某轮训练,假设类别数为K,则对数似然损失函数为: L ( y , f ( x ) ) = − ∑ k = 1 K y k l o g p k ( x ) L(y, f(x)) = - \sum\limits_{k=1}^{K}y_klog\;p_k(x) L(y,f(x))=−k=1∑Kyklogpk(x),其中如果样本x输出类别为 k k k,则 y k = 1 y_k=1 yk=1,否则为0。实际是本轮的K颗树之和。
在本轮的K颗树中,每颗树对样本x预测结果为 f l ( x ) f_l(x) fl(x),则可综合得属于第 k k k类的概率 p k ( x ) p_k(x) pk(x)的表达式为: p k ( x ) = e x p ( f k ( x ) ) ∑ l = 1 K e x p ( f l ( x ) ) p_k(x) =\frac{exp(f_k(x))}{\sum\limits_{l=1}^{K} exp(f_l(x))} pk(x)=l=1∑Kexp(fl(x))exp(fk(x))
结合上面两式,我们可以计算出第 t t t轮的第 i i i个样本属于类别 l l l时的负梯度(伪残差)为: r t i l = − [ ∂ L ( y i , f ( x i ) ) ) ∂ f ( x i ) ] f k ( x ) = f l , t − 1 ( x ) = y i l − p l , t − 1 ( x i ) r_{til} = -\bigg[\frac{\partial L(y_i, f(x_i)))}{\partial f(x_i)}\bigg]_{f_k(x) = f_{l, t-1}\;\; (x)} = y_{il} - p_{l, t-1}(x_i) rtil=−[∂f(xi)∂L(yi,f(xi)))]fk(x)=fl,t−1(x)=yil−pl,t−1(xi)
这里的误差就是样本 i i i在OvR策略下,对应类别为 l l l时的真实概率(是则为1,否为0)和 t − 1 t−1 t−1轮预测概率的差值。
对于生成的决策树,我们各个叶子节点 J J J的最佳负梯度拟合值为: c t j l = a r g m i n ⏟ c j l ∑ i = 0 m ∑ k = 1 K L ( y k , f t − 1 , l ( x ) + ∑ j = 0 J c j l I ( x i ∈ R t j ) ) c_{tjl} = \underbrace{arg\; min}_{c_{jl}}\sum\limits_{i=0}^{m}\sum\limits_{k=1}^{K} L(y_k, f_{t-1, l}(x) + \sum\limits_{j=0}^{J}c_{jl} I(x_i \in R_{tj})) ctjl=cjl argmini=0∑mk=1∑KL(yk,ft−1,l(x)+j=0∑JcjlI(xi∈Rtj))
一般使用近似值代替: c t j l = K − 1 K ∑ x i ∈ R t j l r t i l ∑ x i ∈ R t i l ∣ r t i l ∣ ( 1 − ∣ r t i l ∣ ) c_{tjl} = \frac{K-1}{K} \; \frac{\sum\limits_{x_i \in R_{tjl}}r_{til}}{\sum\limits_{x_i \in R_{til}}|r_{til}|(1-|r_{til}|)} ctjl=KK−1xi∈Rtil∑∣rtil∣(1−∣rtil∣)xi∈Rtjl∑rtil
从而可以继续对残差进行建模拟合,重复上述过程。
除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索,多元GBDT分类和二元GBDT分类以及GBDT回归算法过程相同。
参考
随机梯度提升SGD
全称Stochastic gradient boosting,每次迭代都对残差样本采用无放回的降采样,用部分样本训练基函数的参数,从而防止过拟合。令训练样本数占所有残差有样本的比例为g,当g=1时为原始模型。推荐使用样本比例 0.5 ≤ g ≤ 0.8 0.5\le g \le 0.8 0.5≤g≤0.8。
较小的g能够增强随机性,防止过拟合,并且收敛速度快。降采样的另一好处是可以用剩余样本做模型验证。
XGBoost
是eXtreme Gradient Boosting的简写。只能用于回归,对分类是通过预测概率后进行判断所属类别。XGBoost只能接受数值型变量,对于分类变量,需要进行如One-Hot编码的转换。 原文slide 参考
【优点】
当新增分裂带来负增益时,GBM会停止分裂,而XGBoost会一直分裂到指定的最大深度,然后回过头来进行监枝。XGBoost允许在每一轮boosting迭代中使用交叉验证,以便获取最优boosting迭代次数;GMB使用网格搜索,只能检测有限个值。XGBoost和GBM都支持在线学习,即继续已有模型进行训练。最终结果是对各树叶子节点进行加权求和。
- 除了回归决策树,还可以使用线性分类器。
- 可以自定义损失函数,用损失函数计算一阶和二阶导;也可以用自定义损失函数的一阶导和二阶导。
- 通过正则化对树的节点数、节点权重进行惩罚,减少过拟合,降低了方差
在目标函数中添加了正则化。叶子节点个数+叶子节点权重的L2正则化。max_depth,min_child_weight,gamma
列抽样。训练时只使用一部分的特征。colsample_bytree
子采样。每轮计算可以不使用全部样本,类似bagging。包括subsample。
early stopping。如果经过固定的迭代次数后,并没有在验证集上改善性能,停止训练过程。
shrinkage。调小学习率增加树的数量,为了给后面的训练留出更多的空间。减小learning_rate,同时增加estimator
- xgboost借鉴了随机森林的做法,支持列抽样(拆分节点时??),不仅能降低过拟合,还能减少计算。GBDT中无此项。
- 支持缺失值,对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- XGBoost在根据特征进行节点拆分时使用了并行计算(树的建立仍是串行,Boosting一般为串行计算),并使用C语言,速度快。(xgboost在训练之前,先对数据进行排序,然后保存block结构,后面的迭代中重复的使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行)。xgboost还提出了一种可并行的近似直方图算法,对连续变量用于高效地生成候选的分割点(将数据分箱,用分箱的中心线来做对比,从而减少计算最下分割点时的次数):由于XGBoost是一种boosting算法,树的训练是串行的,不能并行。这里的并行指的是特征维度的并行。在训练之前,每个特征按特征值对样本进行预排序,并存储为Block结构,在后面查找特征分割点时可以重复使用,而且特征已经被存储为一个个block结构,那么在寻找每个特征的最佳分割点时,可以利用多线程对每个block并行计算。
- 由于“随机森林族”本身具有过拟合特性,因此XGBoost也有该特性。

【理论】
对模型预测,通过对基函数进行迭代集成作为整体预测结果,每次都是对上次建模后的残差建立新模型,然后和之前的模型结合作为整体最终模型(从而形成迭代)。对损失函数,将基函数视为一个变量,从而可对损失函数使用梯度提升,利用泰勒二阶展开式进行目标损失函数简化,又因迭代时前t-1次结果已定,所以仅与求解当前最优基函数有关。损失函数 L L L对基函数 f f f进行二阶泰勒展开式来计算,称为XGBoost方法可理解为一阶泰勒展开式就是GBDT)。XGBoost要求弱学习器必须是可以进行回归计算,从而可将历次迭代(树模型就是每棵树)结果求和获取整体最终结果,同GBDT要求相同。
1、集成算法表示: y ^ i ( t ) = y ^ i ( t − 1 ) + f t ( x i ) = ∑ t = 1 T f t ( x i ) = ∑ t = 1 T − 1 f t ( x i ) + f T ( x i ) \hat y_i^{(t)}= \hat y_i^{(t-1)}+f_t(x_i)=\sum^T_{t=1}f_t(x_i)=\sum^{T-1}_{t=1}f_t(x_i)+f_T(x_i) y^i(t)=y^i(t−1)+ft(xi)=∑t=1Tft(xi)=∑t=1T−1ft(xi)+fT(xi),即对第 i i i个样本的预测,是通过前 t − 1 t-1 t−1个基函数预测结果与当前基函数 f T f_T fT预测结果之和,此即为整体结果。
2、损失函数可表示为 L ( f t ) = ∑ t T L ( y i , y ^ i t ) = ∑ t T L ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + ∑ t T Ω ( f t ) + C L(f_t)=\sum_t^T L(y_i, \hat y_i^t)=\sum_t^T L(y_i, \hat y_i^{(t-1)}+f_t(x_i))+\sum_t^T\Omega(f_t)+C L(ft)=∑tTL(yi,y^it)=∑tTL(yi,y^i(t−1)+ft(xi))+∑tTΩ(ft)+C, f t f_t ft是基函数(如树模型), Ω ( f t ) \Omega(f_t) Ω(ft)是关于 f t f_t ft的函数的复杂度(如正则项),C是可能的常数项,t是第t次迭代。损失函数可以理解成是根据 泛 化 误 差 = 偏 差 2 + 方 差 + 随 机 误 差 2 泛化误差=偏差^2+方差+随机误差^2 泛化误差=偏差2+方差+随机误差2构造的。
常用损失函数:
- 均方误差: L ( y i , y ^ i ) = ( y i − y ^ i ) 2 L(y_i, \hat y_i)=(y_i-\hat y_i)^2 L(yi,y^i)=(yi−y^i)2
- 逻辑回归损失函数: L ( y i , y ^ i ) = y i l n ( 1 + e − y ^ i ) + ( 1 − y i ) l n ( 1 + e y ^ i ) L(y_i, \hat y_i)=y_iln(1+e^{-\hat y_i})+(1-y_i)ln(1+e^{\hat y_i}) L(yi,y^i)=yiln(1+e−y^i)+(1−yi)ln(1+ey^i) ,
一阶导 g = ∂ L ( y , F t − 1 ) F t − 1 = − y ( 1 − 1 1 + e F t − 1 ) + ( 1 − y ) 1 1 + e − y t − 1 = P r e d − L a b e l g=\frac{\partial L(y, F_{t-1})}{F_{t-1}}=-y(1-\frac{1}{1+e^{F_{t-1}}})+(1-y)\frac{1}{1+e^{-y_{t-1}}}=Pred-Label g=Ft−1∂L(y,Ft−1)=−y(1−1+eFt−11)+(1−y)1+e−yt−11=Pred−Label
二阶导 h = ∂ 2 L ( y , F t − 1 ) F t − 1 = e − y t − 1 ( 1 + e − y t − 1 ) 2 = P r e d ∗ ( 1 − P r e d ) h=\frac{\partial^2 L(y, F_{t-1})}{F_{t-1}}=\frac{e^{-y_{t-1}}}{(1+e^{-y_{t-1}})^2}=Pred*(1-Pred) h=Ft−1∂2L(y,Ft−1)=(1+e−yt−1)2e−yt−1=Pred∗(1−Pred)
3、通过泰勒展开式对损失函数进行简化:
由于二阶泰勒展开式 f ( x + △ x ) ≈ f ( x ) + f ′ ( x ) △ x + 1 2 f ′ ′ ( x ) △ x 2 f(x+\triangle x)\approx f(x)+f'(x)\triangle x+\frac{1}{2}f''(x)\triangle x^2 f(x+△x)≈f(x)+f′(x)△x+21f′′(x)△x2,对 L ( y i t , y ^ i ( t − 1 ) ) L(y^t_i,\hat y_i^{(t-1)}) L(yit,y^i(t−1)),因 y i t y_i^t yit是已知值,所以对第t次迭代 L ( y i t , y ^ i ( t − 1 ) ) 可 表 示 为 F ( y ^ i ( t − 1 ) + f t ( x i ) ) L(y^t_i,\hat y_i^{(t-1)})可表示为F(\hat y_i^{(t-1)}+f_t(x_i)) L(yit,y^i(t−1))可表示为F(y^i(t−1)+ft(xi)),从而可对 F F F按照泰勒展开式进行展开,即:
F ( y ^ i ( t − 1 ) + f t ( x i ) ) ≈ F ( y ^ i ( t − 1 ) ) + f t ( x i ) ∗ ∂ F ( y ^ i ( t − 1 ) ) ∂ y ^ i ( t − 1 ) + 1 2 f t 2 ( x i ) ∗ ∂ 2 F ( y ^ i ( t − 1 ) ) ∂ ( y ^ i ( t − 1 ) ) 2 ≈ l ( y i t , y ^ i ( t − 1 ) ) + f t ( x i ) ∗ ∂ l ( y i t , y ^ i ( t − 1 ) ) ∂ y ^ i ( t − 1 ) + 1 2 f t 2 ( x i ) ∗ ∂ 2 l ( y i t , y ^ i ( t − 1 ) ) ∂ ( y ^ i ( t − 1 ) ) 2 ≈ l ( y i t , y ^ i ( t − 1 ) ) + f t ( x i ) ∗ g i + 1 2 f t 2 ( x i ) ∗ h i = ∑ i m [ l ( y i , y ^ i ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] F(\hat y_i^{(t-1)}+f_t(x_i)) \approx F(\hat y_i^{(t-1)}) + f_t(x_i)*\frac{\partial F(\hat y_i^{(t-1)})}{\partial \hat y_i^{(t-1)}}+\frac{1}{2}f_t^2(x_i)*\frac{\partial^2F(\hat y_i^{(t-1)})}{\partial (\hat y_i^{(t-1)})^2} \approx l(y_i^t,\hat y_i^{(t-1)})+ f_t(x_i)*\frac{\partial l(y_i^t,\hat y_i^{(t-1)})}{\partial \hat y_i^{(t-1)}}+\frac{1}{2}f_t^2(x_i)*\frac{\partial^2l(y_i^t,\hat y_i^{(t-1)})}{\partial (\hat y_i^{(t-1)})^2} \approx l(y_i^t,\hat y_i^{(t-1)})+f_t(x_i)*g_i+\frac{1}{2}f_t^2(x_i)*h_i = \sum_i^m [l(y_i, \hat y_i^{(t-1)})+g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)] F(y^i(t−1)+ft(xi))≈F(y^i(t−1))+ft(xi)∗∂y^i(t−1)∂F(y^i(t−1))+21ft2(xi)∗∂(y^i(t−1))2∂2F(y^i(t−1))≈l(yit,y^i(t−1))+ft(xi)∗∂y^i(t−1)∂l(yit,y^i(t−1))+21ft2(xi)∗∂(y^i(t−1))2∂2l(yit,y^i(t−1))≈l(yit,y^i(t−1))+ft(xi)∗gi+21ft2(xi)∗hi=∑im[l(yi,y^i(t−1))+gift(xi)+21hift2(xi)],其中m是所有样本, l ( y i t , y ^ i ( t − 1 ) ) l(y_i^t,\hat y_i^{(t-1)}) l(yit,y^i(t−1))是根据之前预测结果得到的常量。
对 ∑ t T Ω ( f t ) = ∑ t T − 1 Ω ( f t ) + Ω ( f T ) \sum_t^T\Omega(f_t)=\sum_t^{T-1}\Omega(f_t)+\Omega(f_T) ∑tTΩ(ft)=∑tT−1Ω(ft)+Ω(fT),其中 ∑ t T − 1 Ω ( f t ) \sum_t^{T-1}\Omega(f_t) ∑tT−1Ω(ft)是根据前 T − 1 T-1 T−1次迭代获得的常量。
综合上边,将常量剔除,总体损失函数通过泰勒二阶展开式可简化为 L ( f t ) = ∑ t T L ( y i , y ^ i t ) = ∑ t T L ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + ∑ t T Ω ( f t ) = ∑ i m [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) L(f_t)=\sum_t^T L(y_i, \hat y_i^t)=\sum_t^T L(y_i, \hat y_i^{(t-1)}+f_t(x_i))+\sum_t^T\Omega(f_t)=\sum_i^m [g_if_t(x_i)+\frac{1}{2}h_if_t^2(x_i)]+\Omega(f_t) L(ft)=∑tTL(yi,y^it)=∑tTL(yi,y^i(t−1)+ft(xi))+∑tTΩ(ft)=∑im[gift(xi)+21hift2(xi)]+Ω(ft),此时只需对第t次迭代找到最优的基模型 f t f_t ft即可(不是GBDT中用来求极值,只是进行简化)。
上式含义:在尽可能对目标值进行拟合以实现预测误差尽可能小的基础上,弱学习器应当有尽可能少的节点,节点取值也尽量偏差不大(防止过拟合风险)
4、对基函数是树模型的损失函数,用树的叶节点表示基函数
对基函数是决策树模型的 f ( x ) f(x) f(x),其结果可表示为叶节点数T、叶节点的值 w = ( w 1 , w 2 , … w T ) w=(w_1,w_2,…w_T) w=(w1,w2,…wT)的组合,样本 x x x在决策树中的结果可表示为 f ( x ) = w q ( x ) f(x)=w_{q(x)} f(x)=wq(x),其中 q ( x ) q(x) q(x)是第 q q q个节点。可以对叶节点数 T T T和叶节点值 w w w(拟合得到的)分别施加惩罚项,得到: Ω ( f t ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \Omega(f_t)=\gamma T+\frac{1}{2}\lambda\sum_{j=1}^Tw_j^2 Ω(ft)=γT+21λ∑j=1Twj2,其中 T T T是决策树叶节点个数, w j w_j wj是第 j j j个叶节点对应的值(后面会被求解出来)。公式对决策树的惩罚方式不是唯一的,可定义其他形式,如L1正则项 1 2 α ∑ j = 1 T ∣ w j ∣ \frac{1}{2}\alpha\sum_{j=1}^T|w_j| 21α∑j=1T∣wj∣,或是L1+L2正则项一起用。引入正则项控制过拟合是GBDT没有的。
对第 t t