【论文笔记】 Reinforcement-Learning-Guided Source Code Summarization using Hierarchical Attention
1 INTRODUCTION
软件维护blablabla……代码注释blablabla……
好的代码注释应具有以下特征:(1) 正确性,正确地阐明代码的意图;(2) 流利,使维护者易于阅读和理解;(3) 一致性,遵循标准的样式/格式。
现有的研究:统计语言模型,模板和规则,神经机器翻译等。
研究的局限性和作者的一些见解:
- 直接输入代码作为文本,不考虑代码的层次结构(能够通过不同上下文的不同token为注释生成提供更全面的表征)。
- 只用简单的时序特征来表示代码,如token 序列,而其他能够捕获注释和程序之间相关性的代码特性并未探索(控制流图CFGs,抽象语法树AST,程序变量的类型等)
- 现有的训练方法为“teacher-forcing”模型,受到Exposure Bias的影响(在测试阶段无法获得ground truth,并且之前生成的词作为输入用于预测后续单词),模型仅基于ground truth来进行训练,无法暴露自身的错误。
teacher forcing 概念参考
上述问题解决方案:基于层次attention的学习方式+actor-critic强化学习
- 使用类型增强的AST序列来替代基于AST的树结构表示,并用控制流补全代码表示;解决限制(2)。
- 采用hierarchical attention network (HAN)对不同的代码序列进行编码;解决限制(1)。
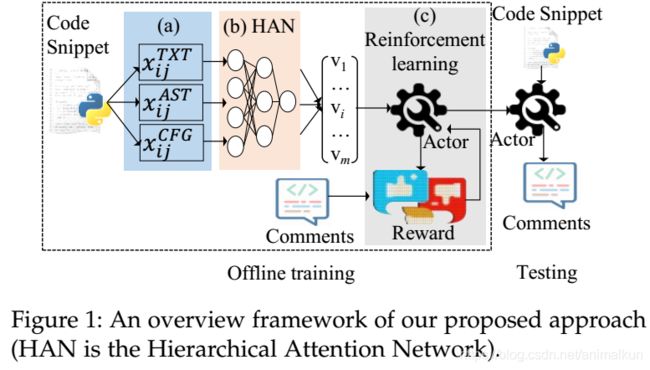
框架概述:
- 离线训练阶段:
- 大规模带注释的
- 三种序列:非结构化级别 —— xTXT (纯代码序列), 结构化级别 —— xAST(类型增强AST),xCFG (控制流)(图1(a))
- hierarchical attention network (HAN) 进行编码和集成 (图1(b))
- 注释对输入深度强化学习模型进行训练 (图1©)
- 大规模带注释的
- 在线总结阶段:
- 向actor网络中输入一个给定代码片段,生成相应注释。
贡献点:
-
新的思路:提出了一种深度强化学习框架Actor-Critic网络来生成注释
-
广泛的算法:提出HAN学习方法,总结利用多个代码特性反映代码层次结构
-
评估:在真实数据集上达成了最优的性能
2 PRELIMINARIES
预备知识:
2.1 语言模型
概率预测
2.2 RNN 编码器-解码器模型
- 编码器
- 解码器
- 训练目标(loss)
2.3 强化学习
强化学习与环境相互作用,从奖励信号中学习最优策略,潜在地解决极大似然引入的Exposure Bias问题。
在基于强化学习框架中,除了生成序列的概率, 还会在训练模型时计算reward作为反馈,以减轻Exposure Bias问题。文本生成过程可以视作马尔科夫决策过程(MDP){S, A, P, R, γ },在MDP设置中,时刻t的状态st由代码片段x和预测的单词y0, y1, … , yt组成,动作空间定义为描绘单词的词典У,yt∈У。相应的,状态转移函数P定义为s{t+1} = {st, yt},动作(即单词)yt 成为后续状态s{t+1} 的一部分,并得到奖励rt+1 。这一过程的目标是找到一个策略,最大化模型生成语句的期望奖励:
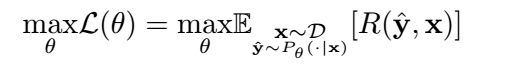
θ \theta θ 是需要学习的策略参数,D是训练集,y_hat 是预测的动作(单词),R是奖励函数。
总体目标仍然是对给定代码片段x生成单词序列,并最大化期望奖励。学习策略的方法主要分两种:(1) 基于策略,通过策略梯度直接优化策略;(2) 基于值,学习Q-函数,每次选择具有最高Q-值的动作。由于基于策略的方法存在方差问题,基于值的方法存在偏差问题,因此本文采取二者相结合的actor-critc学习方法。
3 ILLUSTRATIVE EXAMPLE
展示例子:
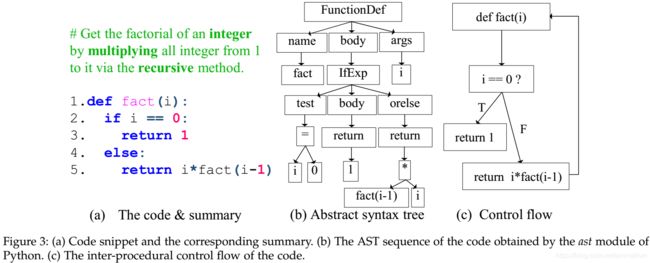
图3(a)是一个简单的Python代码示例,通过递归函数获得整数的阶乘,图3(b)是图3(a)中代码的AST,图3©是程序执行顺序的控制流程图。该代码的理想注释(绿色)如图3(a)所示,三个突出显示的单词语义可以由不同的代码表示精确地捕获,例如,plain text (用于 multiplying), type-augmented AST (用于integer) 和 CFG (用于 recursive)。
在不同的代码表示中,token和语句的顺序会有所不同。本文使用了代码的三种结构化和非结构化信息,纯文本、AST和CFG。基于纯文本,代码表示为 “def fact ( i ) : if i == 0 : ……”;基于AST,代码表示为{ stmt = FunctionDef ( identifier fact, arguments i, stmt body ) ; body = IfExp (expr test, expr body , expr orelse) ; …};基于CFG,由于递归调用,后续的token从def开始。
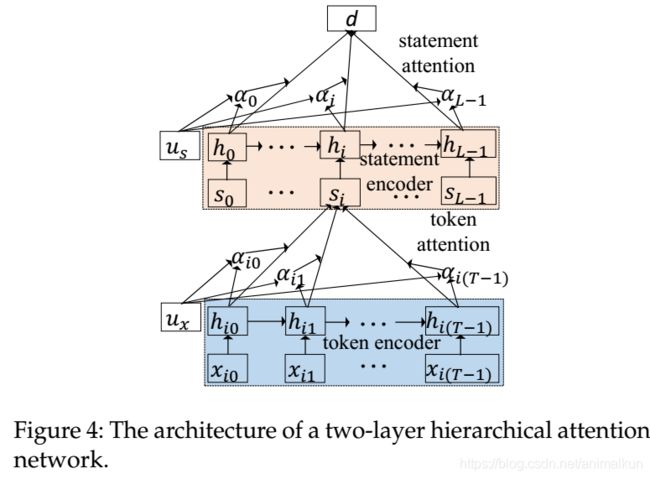
图3(a)中可以观察到语句1由def、fact、和 i 组成,而整个函数由语句1-5组成,这样的层次结构能够由一个两层的注意力网络进行捕获(包括token层和statement层),如图4所示。底层对每个语句 s i s_i si的token x i t x_{it} xit进行编码即这一条语句的向量, α i \alpha_i αi和 α i t \alpha_{it} αit分别表示第i个语句和第i个语句的第t个token的权重。
本文就是利用这三种代码表示以及HAN,分别对不同的token和语句序列生成三种不同的向量,最后把三个向量连接起来产生最后的代码表示,精确地捕获token之间和语句之间的关系。
4 THE DRL-GUIDED CODE SUMMARIZATION VIA HIERARCHICAL ATTENTION NETWORK
通过层次注意力网络实现深度强化学习引导的代码摘要。
本文方法遵循已成功应用于AlpahGo的Actor-Critic网络框架,并把框架分为四个子模块,如图5:
- 用于解释程序的非结构化和结构化信息的代码表示
- 用于将代码表示编码为隐藏空间中的向量的混合分层注意力网络
- 文本生成,根据前一词生成后续词的基于LSTM的生成网络
- 用于评价生成词的质量的critic网络

4.1 Source Code Representations
源代码表示,首先用一组符号 {. , ” ’ ( ) { } : ! - (space) } 对代码进行分割和token化,全部字母小写,并使用Word2Vec对token进行词嵌入,未定义的token作为未知单词处理。
有以下三种代码表示:纯文本、类型增强的抽象语法树和控制流图。
4.1.1 Plain Text
纯文本
最直接普通的文本表示,对于代码的词法级表示的关键见解:注释总是从源代码的词法项中提取,比如函数名、变量名等等。
4.1.2 Type-augmented Abstract Syntax Tree
类型增强的抽象语法树
本文首先利用python的AST模块获取AST序列,然后,为了利用额外的类型信息来增加派生的AST序列,抽象了token的类型信息,并将它们与代码的AST序列集成。例如,图3(a)中,通过在变量“1”上注释“integer”类,将第2行表示为“if integer i == integer 1”。
总之就是对每个节点都增加了类型信息。
4.1.3 Control Flow Graph
控制流图
本文提取了控制流图(CFG)作为代码的另一种语法级表示,CFG上的每个节点代表一条由一系列token组成的语句,连接两个节点的每条边表示程序的控制流。
某种意义上应该跟type-augemented AST一样,作为AST的一种补充。
4.2 Hybrid Hierarchical Attention Network
每个代码部分都对生成注释有自己的贡献,而token和语句高度依赖上下文,具体为,相同的token或语句在不同的上下文中可能有不同的重要性,而代码又具有层次结构(token形成语句,语句形成函数),因此,在NLP领域获得成功的HAN自然地用在代码表示上,分别为单个token和语句分配权重(attention)。注意力不仅能带来更好的性能,而且还可以洞察token/语句和相应的摘要之间的相关性,这有利于生成高质量的注释。
本文采用两层attention网络(一个token layer和一个statement layer),如图5(b)所示。该网络由四个部分组成:token序列编码器、token级注意层、语句编码器和语句级注意层。
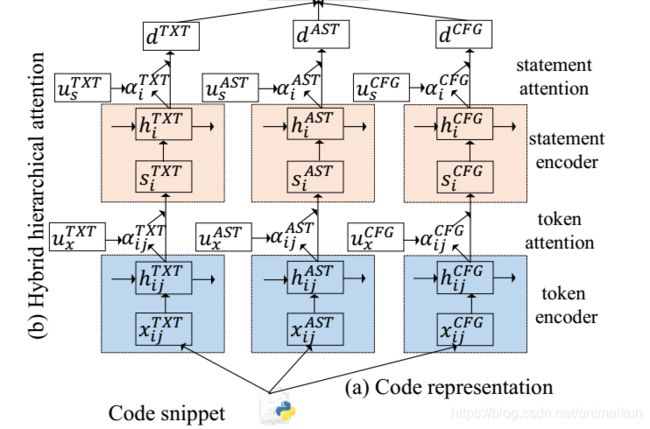
假设 d T X T 、 d A S T 和 d C F G d^{TXT}、d^{AST}和d^{CFG} dTXT、dAST和dCFG是通过编码纯文本、AST和CFG这三种代码表示形式得到的向量,把它们合并到一个混合向量 d d d来表示代码。该网络的具体内容如下:
token编码器:给定一个语句 s i s_i si,它有 T i T_i Ti个token, x i 0 , . . . , x i T i − 1 x_{i0},...,x_{iT_{i-1}} xi0,...,xiTi−1。本文首先用嵌入矩阵 W i W_i Wi把所有token 嵌入到词向量中,即 v i t = W i x i t v_{it}=W_{ix_{it}} vit=Wixit,然后用LSTM从 x i 0 x_{i0} xi0到 x i T i − 1 x_{iT_{i-1}} xiTi−1读取语句 s i s_i si来获得相应的token注释:
v i t = W i x i t , t ∈ [ 0 , T i ) v_{it}=W_{i}x_{it},t∈[0,T_i) vit=Wixit,t∈[0,Ti)
h i t = l s t m ( v i t ) , t ∈ [ 0 , T I ) h_{it}=lstm(v_{it}),t∈[0,T_I) hit=lstm(vit),t∈[0,TI)
token attention:不是所有的token对语句的语义表达都有同样的贡献,如图6所示,代码片段中的“number” 和 “str” 比语句“defcheck number exist(str):” 中的“def”更重要,因为注释中包含“number”和“string”。

因此引入注意力机制来提取对注释生成更重要的token,并把这些token聚合成一个语句向量:
u i t = t a n h ( W x h i t + b x ) u_{it}=tanh(W_xh_{it}+b_x) uit=tanh(Wxhit+bx)
α i t = e x p ( u i t T u x ) ∑ T e x p ( u i t T u x ) \alpha_{it}=\frac {exp(u^T_{it}u_x)}{\sum_Texp(u^T_{it}u_x)} αit=∑Texp(uitTux)exp(uitTux)
s i = ∑ T α i t h i t s_i=\sum_T\alpha_{it}h_{it} si=T∑αithit
α i \alpha_i αi表示语句 s i s_i si中token x i t x_{it} xit的贡献(attention), u x u_x ux是token级的上下文向量,用于根据token对每个语句进行高级表示。
statement attenion:为了奖励在摘要任务中,对相关函数在语义上更加重要的语句,本文对语句也引入了一个注意力网络,表现为语句级的函数向量 u s u_s us,用于衡量语句的重要性:
u i = t a n h ( W s h i + b s ) u_{i}=tanh(W_sh_{i}+b_s) ui=tanh(Wshi+bs)
α i = e x p ( u i T u s ) ∑ L e x p ( u i T u s ) \alpha_{i}=\frac {exp(u^T_{i}u_s)}{\sum_Lexp(u^T_{i}u_s)} αi=∑Lexp(uiTus)exp(uiTus)
d c = ∑ L α i h i d^c=\sum_L\alpha_{i}h_{i} dc=L∑αihi
α i \alpha_i αi表示语句 s i s_i si对于最终向量 d c d^c dc的贡献(attention)
Hybrid Representation of Source Code:对结构化上下文向量(AST和CFG表示)和非结构化上下文向量(纯文本表示)进行整合,即直接拼接 [ d T X T ; d A S T ; d C F G ] [d^{TXT};d^{AST};d^{CFG}] [dTXT;dAST;dCFG],然后输入到单层线性网络形成最终向量 d = W d [ d T X T ; d A S T ; d C F G ] + b d d=W_d[d^{TXT};d^{AST};d^{CFG}]+b_d d=Wd[dTXT;dAST;dCFG]+bd,然后,添加一个隐藏层,使用上下文向量进行预测: s ^ t = t a n h ( W c s t + b d ) \hat s_t=tanh(W_cs_t+b_d) s^t=tanh(Wcst+bd),在解码阶段,初始值 s 0 s_0 s0为 d d d,刷新 t t t步后获得 s t s_t st。
4.3 Text Generation
文本生成
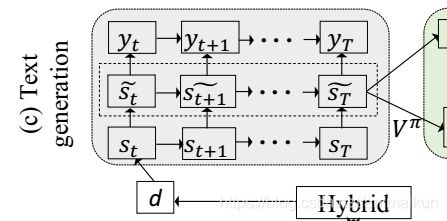
从HAN中获得的代码片段表示用于最后的注释生成,这里设计了一个分层的多维输入,因此采用Input-feeding 注意力机制,使用softmax预测第t个单词。 p π p_\pi pπ表示由行动者网络决定的一个策略 π \pi π, p π ( y t ∣ s t ) p_{\pi}(y_t|s_t) pπ(yt∣st)表示第t个单词 y t y_t yt的概率分布:
p π ( y t ∣ s t ) = s o f t m a x ( W s s ~ t + b s ) p_{\pi}(y_t|s_t)=softmax(W_s\widetilde s_t+b_s ) pπ(yt∣st)=softmax(Wss t+bs)
4.4 Critic Network
传统的编码器-解码器结构会在训练时使用ground truth进行后续单词的预测(Teacher Forcing策略),而在强化学习中,则是通过迭代去优化评价指标来生成注释,如BLEU。本文应用critic网络来近似在时间t处生成的动作的值,发出反馈来迭代地调整网络。与actor网络不同,critic网络在每个解码步骤上输出单个值而不是概率分布。
给定生成的注释、奖励函数 r r r,定义一个值函数 V V V去预测在 t t t时刻状态 s t s_t st的总奖励:
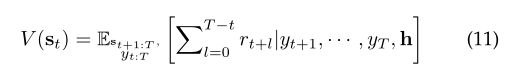
通过奖励函数,在注释序列生成完成后将得到一个评价分数(如BLEU),注:当相关步骤超过最大步骤T或遇到生成序列结束标记(EOS)时,该过程终止。那么基于BLEU的奖励函数可以计算为:
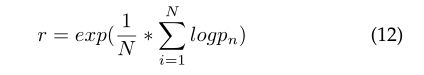
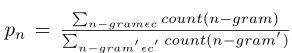
c c c是生成的注释, c ′ c' c′是ground truth。
4.5 Model Training
对于actor网络,训练目标是最小化负的期望奖励,具体定义为 L ( θ ) = − E y 1 , . . . , T ∼ π ( ∑ l = t T r t ) L(\theta)=-\mathbb{E}_{y_1,...,T\sim\pi}(\sum^T_{l=t}r_t) L(θ)=−Ey1,...,T∼π(∑l=tTrt)。把策略定义为生成注释的概率,用策略梯度进行优化。
cirtic网络则希望最小化以下损失函数: L ( ϕ ) = 1 2 ∥ V ( s t ) − V ϕ ( s t ) ∥ 2 L(\phi)=\frac {1}{2}\parallel V(s_t)-V_{\phi}(s_t) \parallel^2 L(ϕ)=21∥V(st)−Vϕ(st)∥2, V ( s t ) V(s_t) V(st)是值函数基于ground truth计算出来的值, V ϕ ( s t ) V_{\phi}(s_t) Vϕ(st)则是critic网络基于生成的注释结合参数 ϕ \phi ϕ预测出来的值。 L ( ϕ ) L(\phi) L(ϕ)收敛后,模型训练完成。
actor的参数 θ \theta θ和critic的参数 ϕ \phi ϕ,所有参数表示为 Θ = { θ , ϕ } \Theta=\{\theta, \phi\} Θ={ θ,ϕ},总的损失表示为 L ( Θ ) = L ( θ ) + L ( ϕ ) L(\Theta)=L(\theta)+L(\phi) L(Θ)=L(θ)+L(ϕ)。
5 EXPERIMENTS AND ANALYSIS
5.1 Dataset Preparation
Python:使用了此前研究工作“Improving automatic source code summarization via deep reinforcement learning”中的Python数据集,108k个代码-注释对,代码和注释的词汇表大小分别为50,400和31,350,前80%作为训练验证集(采用10-fold交叉验证),后20%用于测试集。
JAVA:采用“Deep code comment generation with hybrid lexical and syntactical information,” 中的java项目数据集对本文方法的跨语言性能进行评估,从deepcom的原始数据集中以自上而下的方式选取与本文的python数据集相同数量的训练、验证和测试数据。
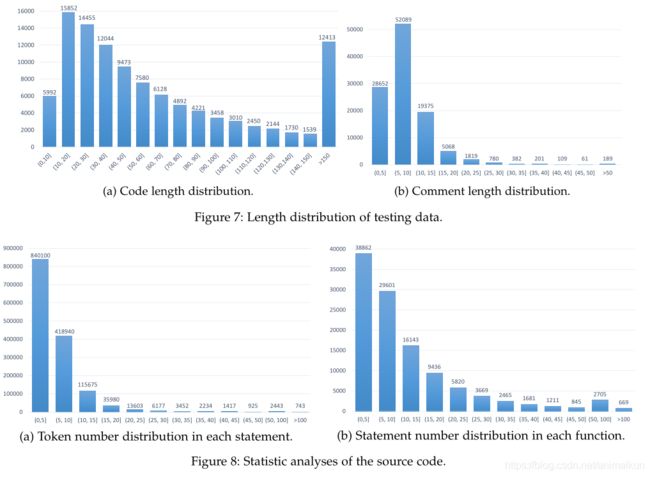
源代码和注释的统计分布:基于大量的GitHub项目对本文采用的Python数据集进行统计分析。图7显示了代码和注释的长度分布,大多数代码片段的长度位于10到80个token之间,几乎所有注释的长度都在5到40之间;图8显示了收集到的数据集代码片段中的token数量和语句数量分布,每个语句中的token数量集中在1到15之间,每个函数中的语句数量集中在2到25之间。
5.2 Evaluation Metrics
本文涉及三个在NLP领域广泛使用的评估指标:BLEU、METEOR、ROUGE-L。
BLEU:
B L E U = e x p ( 1 N ∗ ∑ i = 1 N l o g p n ) BLEU=exp(\frac {1} {N} * \sum_{i=1}^N logp_n) BLEU=exp(N1∗i=1∑Nlogpn)
p n = ∑ n − g r a m ∈ c c o u n t ( n − g r a m ) ∑ n − g r a m ′ ∈ c ′ c o u n t ( n − g r a m ′ ) p_n=\frac {\sum_{n-gram\in c}count(n-gram)} {\sum_{n-gram'\in c'}count(n-gram')} pn=∑n−gram′∈c′count(n−gram′)∑n−gram∈ccount(n−gram)
c c c是生成的注释, c ′ c' c′是ground truth。本文扩展了对BLEU指标的使用:sentence-level BLEU(S-BLEU)和corpus-level BLEU(C-BLEU)。特别地,SBLEU计算每个生成的注释和ground truth之间的BLEU分数,然后计算所有分数的平均值。C-BLEU计算corpus-level的BLEU得分。
METEOR:
M E T E O R = ( 1 − P e n ) F m e a n METEOR=(1-Pen)F_{mean} METEOR=(1−Pen)Fmean
P e n = γ ( c h m ) θ Pen=\gamma (\frac{ch}{m})^\theta Pen=γ(mch)θ F m e a n = P m R m α P m + ( 1 − α ) R m F_{mean}=\frac {P_m R_m}{\alpha P_m +(1-\alpha)R_m} Fmean=αPm+(1−α)RmPmRm
ROUGE-L:
R O U G E − L = ∑ S ∈ c ∑ g r a m l ∈ S C o u n t m a t c h ( g r a m l ) ∑ S ∈ c ∑ g r a m l ∈ S C o u n t ( g r a m l ) ROUGE-L=\frac {\sum_{S\in c}\sum_g ram_l \in SCount_{match}(gram_l)}{\sum_{S\in c}\sum_g ram_l \in SCount(gram_l)} ROUGE−L=∑S∈c∑graml∈SCount(graml)∑S∈c∑graml∈SCountmatch(graml)
其中 l l l 表示token的数量, C o u n t m a t c h ( g r a m l ) Count_{match}(gram_l) Countmatch(graml)计算生成注释中匹配的n-gram的最大数量。
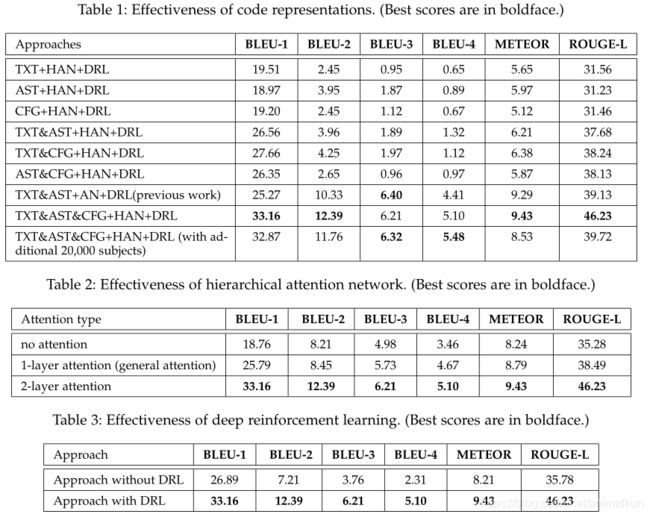
RQ1:我们的方法在生成注释上的有效性?不同代码表示配置的结果如何?
TXT-纯文本,AST-抽象语法树,CFG-控制流程图,HAN-层次注意力网络,DRL-深度强化学习
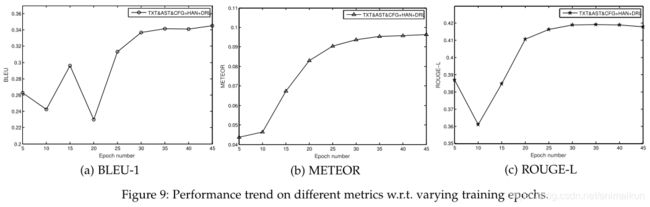
RQ2:不同training epochs的时间消耗和性能趋势?
表5:不同代码表示的时间消耗

图9:epochs的增加对性能影响
RQ3:我们的方法在代码或注释长度不同的数据集上表现如何?
对比中的基线为仅使用单个代码表示的强化学习模型:TXT\AST\CFG,2个特性比一个特性更优:TXT&AST、TXT&CFG和AST&CFG,本文方法用了全部的三个特性,取得最优效果。
图10:不同代码长度下的性能
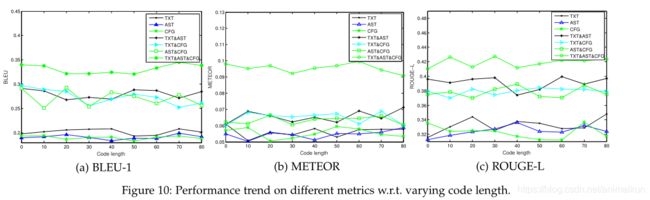
图11:不同注释长度下的性能

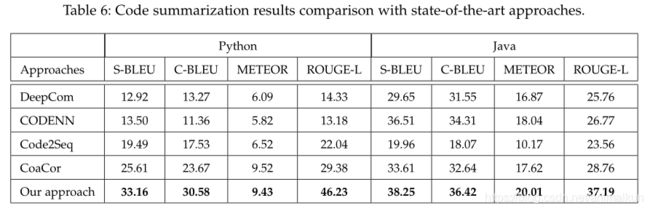
RQ4:与其他方法相比性能如何?
优于此前的研究
RQ5:除了NLP指标,如何广泛地评估我们的方法?
案例研究和用户研究(人工评估)