编译 | CV君
报道 | OpenCV中文网(微信id:iopencv)
本篇继续对目标检测相关论文进行整理,共计 14 篇。包含2D、 3D、雷达、小目标、带方向的、半监督目标检测、弱监督目标定位等。
如有遗漏,欢迎补充。
下载包含这些论文的 WACV 2021 所有论文:
3D目标检测
[1].Cross-Modality 3D Object Detection
跨模态3D目标检测。文中提出一个两阶多模态融合框架,结合最佳状态的双目图像对和点云来进行 3D 目标检测。另外,使用 stereo matching 伪激光雷达点作为一种数据增强方法,以使激光雷达点密集化。
作者 | Ming Zhu, Chao Ma, Pan Ji, Xiaokang Yang
单位 | 上海交通大学;NEC Laboratories America
论文 | https://arxiv.org/abs/2008.10436
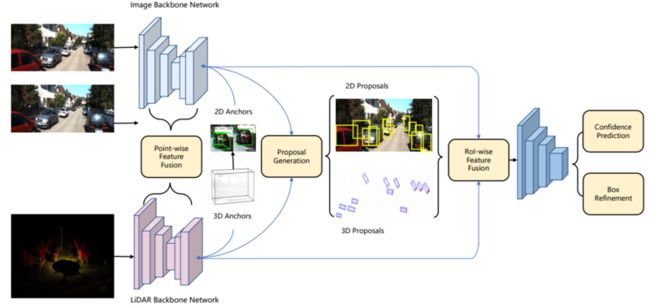
[2].CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection
旨在使用低成本的雷达(redar)替换自动驾驶中的激光雷达,并达到高精度3D目标检测的方法。已开源。
作者 | Ramin Nabati, Hairong Qi
单位 | 田纳西大学诺克斯维尔
论文 | https://arxiv.org/abs/2011.04841
代码 | https://github.com/mrnabati/C...
详解 | CenterFusion:融合雷达与摄像头数据的高精度3D目标检测

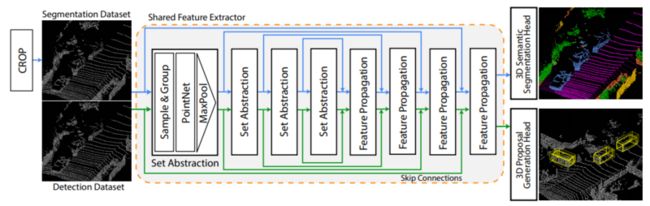
[3].Improving Point Cloud Semantic Segmentation by Learning 3D Object Detection
提出 Detection Aware 3D Semantic Segmentation (DASS) 网络来解决当前架构的局限性。
DASS 可以在保持高精度鸟瞰(BEV)检测结果的同时,将几何相似类的 3D语义分割结果提高到图像 FOV 的 37.8% IoU。
作者 | Ozan Unal, Luc Van Gool, Dengxin Dai
单位 | 苏黎世联邦理工学院;鲁汶大学
论文 | https://arxiv.org/abs/2009.10569
半监督目标检测
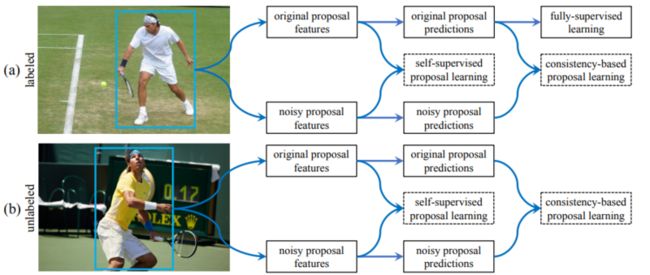
[4].Proposal Learning for Semi-Supervised Object Detection
作者提出一种 proposal 学习方法,从标记和未标记的数据中学习proposal 特征和预测。该方法包括 :
- 一种自监督的 proposal 学习模块,通过 proposal 位置损失和对比损失分别学习上下文感知和噪声粗糙的 proposal 特征
- 一个基于一致性的 proposal 学习模块,通过一致性损失学习噪声鲁棒proposal 特征和预测,用于边界盒分类和回归预测
在COCO数据集上,所提出方法比各种基于 Faster R-CNN 的完全监督基线和数据蒸馏分别高出约 2.0% 和 0.9%。
作者 | Peng Tang, Chetan Ramaiah, Yan Wang, Ran Xu, Caiming Xiong
单位 | Salesforce Research;约翰斯霍普金斯大学
论文 | https://arxiv.org/abs/2001.05086
小目标检测
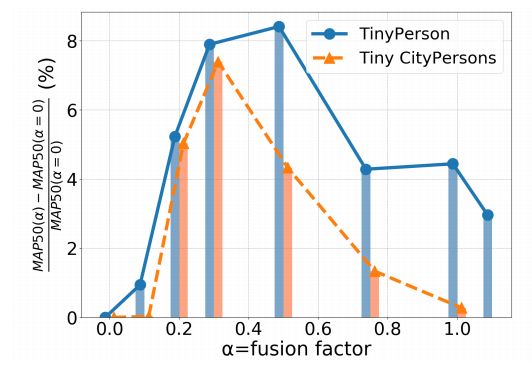
[5].Effective Fusion Factor in FPN for Tiny Object Detection 作者 | Yuqi Gong, Xuehui Yu, Yao Ding, Xiaoke Peng, Jian Zhao, Zhenjun Han 单位 | 国科大;Institute of North Electronic Equipment
论文 | https://arxiv.org/abs/2011.02298
代码 | coming
[6].Oriented Object Detection in Aerial Images With Box Boundary-Aware Vectors
提出一个简单有效的策略:BBAVectors 来描述带方向的目标。BBAVectors 是在同一笛卡尔坐标系中对所有任意方向的目标进行测量。与之前的学习目标的宽度、高度和角度的基线方法相比,BBAVectors的性能更好。
将基于中心关键点的目标检测器扩展到定向目标检测任务中。该模型的特点:单阶段、anchor box free、快速和准确。在 DOTA 和 HRSC2016 数据集上实现了最先进的性能。
作者 | Jingru Yi, Pengxiang Wu, Bo Liu, Qiaoying Huang, Hui Qu, Dimitris Metaxas
单位 | 罗格斯大学
论文 | https://arxiv.org/abs/2008.07043
代码 | https://github.com/yijingru/B...

[7].Generalized Object Detection on Fisheye Cameras for Autonomous Driving: Dataset, Representations and Baseline
鱼眼相机覆盖视野广阔,作者系统全面研究了自动驾驶场景鱼眼相机目标检测,作者提出了新的表示方法,数据集和基线算法,相比于之前的工作,获得了显著的改进。
作者 | Hazem Rashed, Eslam Mohamed, Ganesh Sistu, Varun Ravi Kumar, Ciaran Eising, Ahmad El-Sallab, Senthil Yogamani
单位 | Valeo R&D等
论文 | https://arxiv.org/abs/2012.02124
雷达目标检测
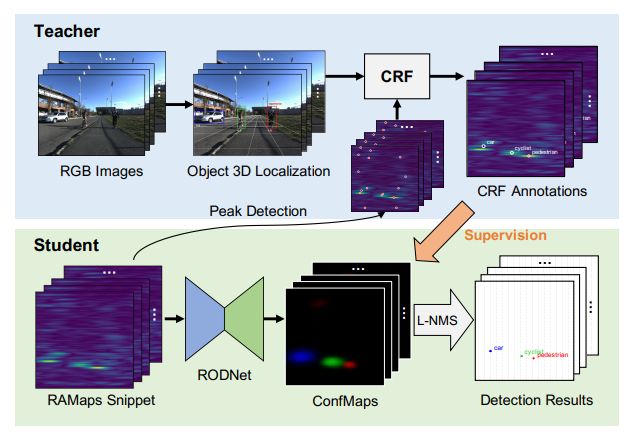
[8].RODNet: Radar Object Detection Using Cross-Modal Supervision
提出一种全新的雷达目标检测网络:RODNet,无需摄像头或激光雷达情况下,用在各种驾驶场景下进行鲁棒的目标检测。一个摄像机-雷达融合(CRF)跨模态监管框架,用于训练 RODNet,无需繁琐且可能不一致的人为标注。
作者还收集了一个新的数据集:CRUW,包含相机和雷达的同步数据,对相机-雷达跨模式研究很有价值。以及一种新的雷达目标检测任务的评价方法,并对其有效性进行了论证。
作者 | Yizhou Wang, Zhongyu Jiang, Xiangyu Gao, Jenq-Neng Hwang, Guanbin Xing, Hui Liu
单位 | 华盛顿大学;Silkwave Holdings Limited
论文 | https://openaccess.thecvf.com...
代码 | https://github.com/yizhou-wan...
数据集 | https://www.cruwdataset.org/
无监督目标定位
Improve CAM With Auto-Adapted Segmentation and Co-Supervised Augmentation
WSOL 弱监督目标定位是一种仅使用图像级标签,而不包含位置注释的目标定位方法。本次工作,主要针对 WSOL 任务,作者提出 CSoA。由两个模块组成,对传统的卷积网络进行改进,在不牺牲识别能力的前提下提高其定位性能。在学习过程中,ConfSeg 模块鼓励网络内部的两个分类器生成更精确和完整的CAM。此外,CoAug 模块基于度量方法对不同样本的 CAM 进行批量调节。
最终模型在两个公共基准上优于所有之前的方法,成为新的最先进技术,为解决 WSOL 问题提供了新的见解。
作者 | Ziyi Kou, Guofeng Cui, Shaojie Wang, Wentian Zhao, Chenliang Xu
单位 | 圣母大学;罗格斯大学;圣路易斯华盛顿大学;Adobe;罗切斯特大学
论文 | https://arxiv.org/abs/1911.07160

目标检测
[9].CPM R-CNN: Calibrating Point-Guided Misalignment in Object Detection
该文指出 Point-Guided 网络中检测精度的瓶颈原因在于两种错位问题,并提出解决方案:CPM R-CNN。提出 cascade mapping 以便获得更完整的box分布,并证明了它的有效性。所设计的简单有效的融合评分结构与原来的相比有很大改进。
与 Faster R-CNN 和基于 ResNet-101 与 FPN 的 Grid R-CNN 相比,所提出方法在 without whistles and bells 情况下分别大幅提高 3.3% 和 1.5% mAP。此外,最佳模型在 COCO 测试设备上的改进幅度较大,达到 49.9%。
作者 | Bin Zhu, Qing Song, Lu Yang, Zhihui Wang, Chun Liu, Mengjie Hu
单位 | 北京邮电大学
论文 | https://arxiv.org/abs/2003.03570
代码 | https://github.com/zhubinQAQ/...
===
[10].Towards Resolving the Challenge of Long-tail Distribution in UAV Images for Object Detection
目前无人机图像目标检测存在的问题是无人机图像类别分布分布,就此问题,作者提出 Dual Sampler and Head detection Network (DSHNet),是首个旨在解决无人机图像中长尾分布的工作。DSHNet 的关键组成是 Class-Biased Samplers (CBS) 和 Bilateral Box Heads (BBH),是为应对尾部类和头部类的双路径方式而开发。
DSHNet显著提升了尾类在不同检测框架上的性能。并在 VisDrone 和UAVDT 数据集上,性能明显优于基础检测器和通用方法。当与图像裁剪方法等数据增广方法相结合时,它实现了新 SOTA。
作者 | Weiping Yu, Taojiannan Yang, Chen Chen
单位 | 北卡罗来纳大学夏洛特分校
论文 | https://arxiv.org/abs/2011.03822
代码 | https://github.com/we1pingyu/...

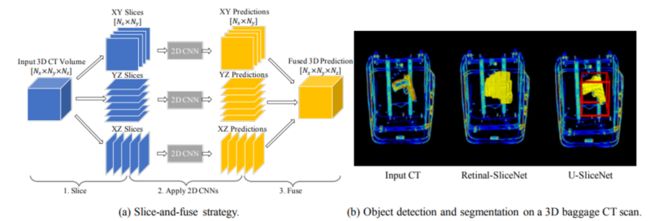
[11].SliceNets -- A Scalable Approach for Object Detection in 3D CT Scans
SliceNets:用于 3D CT扫描中目标检测的可扩展方法
作者 | Anqi Yang, Feng Pan, Vishwanath Saragadam, Duy Dao, Zhuo Hui, Jen-Hao Rick Chang, Aswin C. Sankaranarayanan
单位 | 卡内基梅隆大学;IDSS Corporation
论文 | https://openaccess.thecvf.com...
[12].Class-Agnostic Object Detection
在很多问题中,目标的存在位置信息比类别信息更重要,于是该文作者提出一种新型 class-agnostic(可不知类别的) 目标检测问题表述,作为新的研究方向。制订训练和评估协议,以确定基准和推进研究;设计一个新的对抗式学习框架,用于类诊断检测,强制模型从用于预测的特征中排除 class-specific 信息。实验结果表明,对抗式学习提高了 class-agnostic 识别的检测效率。
作者 | Ayush Jaiswal, Yue Wu, Pradeep Natarajan, Premkumar Natarajan
单位 | Amazon Alexa
论文 | https://arxiv.org/abs/2011.14204

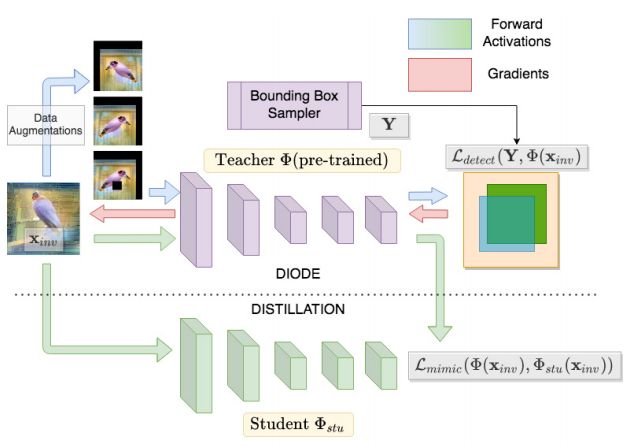
[13].Data-Free Knowledge Distillation for Object Detection
用于目标检测的无数据知识蒸馏技术,由两部分组成:DIODE,通过模型逆映射从预训练检测模型中合成图像的框架;一个无数据模仿学习方法,对从老师对学生合成的图像进行知识蒸馏,用于目标检测。
实验验证了合成图像的质量和通用性,检测效率与域外数据集(0.313 mAP)相比,有显著的改进(0.450 mAP),并且与同域数据集(0.466 mAP)具有竞争力。
作者 | Akshay Chawla, Hongxu Yin, Pavlo Molchanov, Jose Alvarez
单位 | 英伟达
论文 | https://openaccess.thecvf.com...
- END -
编辑:CV君
转载请联系本公众号授权