Python爬虫实战经验分享, siki学院视频下载
爬取并解密某学院在线视频
开始之前, 先了解下pyppeteer和asyncio
pyppeteer和selenium一样都是模拟浏览器行为
1、模拟登录
然后F12或者右键点击检查, 选择模拟手机浏览器(这样会简单一点, 在这安利一个小技巧, 一般网站设置为手机访问有些参数可能会变简单)

点击登录, 查看浏览器地址栏, 找到登录地址http://www.sikiedu.com/login?goto=/
找到微信扫码登录按钮元素
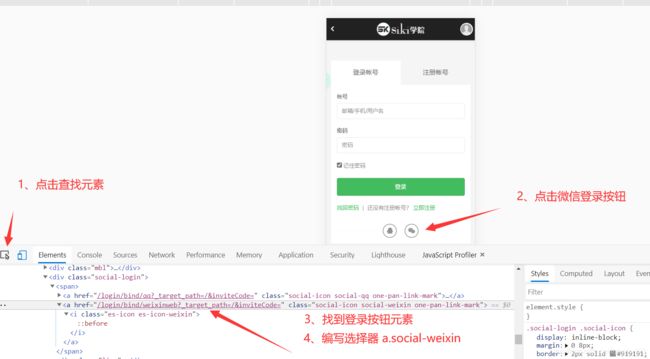
找到登录二维码
和找登录按钮一样, 找到二维码图片

然后简单一点就直接将元素截图, 然后保存, 之后打开图片扫码登录
这里为了更炫酷的效果, 所以将二维码图片识别后, 获取真实登录地址, 最后用终端将包含真实登录地址的二维码显示出来
async def login():
browser = await launch(headless=True, executablePath="C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe") # 这里选择新版edge浏览器, 真的很棒, 还能一键导入chrome浏览器的书签和cookie, 建议更新
page = await browser.newPage() # 创建一个新标签页
# 老规矩设置一下user-agent
await page.setUserAgent("Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/87.0.4280.88")
# 访问登录页
await page.goto('http://www.sikiedu.com/login')
# 点击微信登录
await page.click('a.social-weixin')
# 等到二维码出现
qrcode = await page.waitForSelector("div.wrp_code > img")
await page.waitFor(500) # 等待图片加载
with TemporaryDirectory() as tmpdirname:
await qrcode.screenshot({
"path": os.path.join(tmpdirname, self.qrcode_file)})
# logger.info("等待扫码")
self.show_qrcode(os.path.join(tmpdirname, self.qrcode_file))
await page.evaluate('''() => {
var wx_scan_interval = setInterval(() => {
if ($("#wx_after_scan").is(':visible')) {
$("#wx_after_scan").after('有了cookie, 不难找出获取课程列表等接口, 这里就不一一讲解了, 在最后自己看完整代码
2、下载并解析视频
打开一个自己课程中的任意一个视频


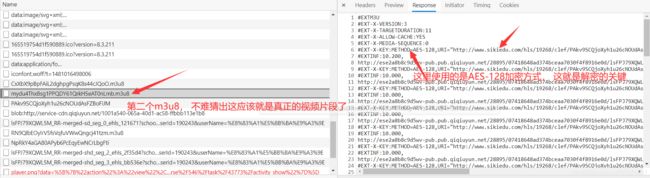
我们还能发现这里有一个AES解密需要的IV 偏移量

然后我们在找到第一个m3u8地址是哪个请求获取的


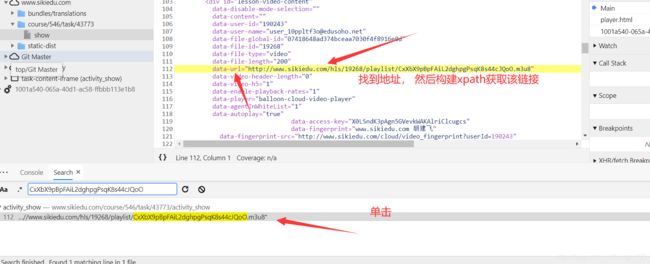
下面分析解密视频

现在key和iv都找到了, 解密就简单了, 随便网上找一个AES解密
3、最后完整代码
运行环境
edge最新版
用到的库
pyppeteer # 模拟浏览器
PIL
pyzbar # 识别二维码
qrcode # 在终端中打印二维码
aiohttp # 异步请求
lxml # 解析html
loguru # 更方便的日志第三方库
tqdm # 简洁在终端显示进度
prettytable # 终端打印表格
import asyncio
from asyncio.locks import Semaphore
from typing import List
from pyppeteer import launch
import os
from PIL import Image
from pyzbar import pyzbar
import qrcode
from tempfile import TemporaryDirectory
import os
from aiohttp import ClientSession
from lxml import etree
from loguru import logger
import re
import os
from Crypto.Cipher import AES
import re
from tqdm import tqdm
import json
from prettytable import PrettyTable # 终端打印表格
logger.add(f"{os.path.expanduser('~')}\AppData\Local\siki\log\log.log", level='DEBUG', format='{time:YYYY-MM-DD HH:mm:ss.SSS} | {level: <8} | {name} :{function} :{line} - {message} ', encoding="UTF-8", rotation="1 MB", retention="5 days")
class Siki(object):
def __init__(self) -> None:
self.qrcode_file = "qrcode.png"
self.cookies = {
}
self.base_url = "http://www.sikiedu.com"
self.qxd = "高清"
self.headers = {
"Host": "www.sikiedu.com",
"Origin": "http://service-cdn.qiqiuyun.net",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/87.0.4280.88"
}
self.max_worker = 80
def show_qrcode(self, file):
url = pyzbar.decode(Image.open(os.path.join(file)), symbols=[
pyzbar.ZBarSymbol.QRCODE])[0].data.decode()
q = qrcode.QRCode()
q.add_data(url)
q.make()
q.print_ascii()
async def login(self):
browser = await launch(headless=True, executablePath="C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe")
page = await browser.newPage()
await page.setUserAgent("Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/87.0.4280.88")
await page.goto('http://www.sikiedu.com/login')
await page.click('a.social-weixin')
qrcode_img = await page.waitForSelector("div.wrp_code > img")
# 直接获取二维码url
# qrcode_url = await (await qrcode_img.getProperty("src")).jsonValue()
# 也可以获取图片然后识别内容
await page.waitFor(500)
with TemporaryDirectory() as tmpdirname:
await qrcode_img.screenshot({
"path": os.path.join(tmpdirname, self.qrcode_file)})
# logger.info("等待扫码")
self.show_qrcode(os.path.join(tmpdirname, self.qrcode_file))
# 等待扫码完成
await page.evaluate('''() => {
var wx_scan_interval = setInterval(() => {
if ($("#wx_after_scan").is(':visible')) {
$("#wx_after_scan").after('\d+?),NAME=(?P\w+)" , lines[i].strip())
if result:
i += 1
url = lines[i].strip()
m3u8info[result.group("name")] = lines[i].strip()
i += 1
if self.qxd in m3u8info:
url = m3u8info[self.qxd]
# 第三层
logger.debug("解析第三层")
with TemporaryDirectory() as tempdir:
response = await self.session.get(url)
all_content = await response.text()
if "#EXTM3U" not in all_content:
raise BaseException("非M3U8的链接")
file_line = all_content.split("\n")
match = re.search(
r"#EXT-X-KEY:METHOD=AES-128,URI=\"(?P.*?)\",IV=(?P0x[\d\w]*)" , all_content)
key_uri = match.group("uri")
response = await self.session.get(key_uri)
key = (await response.text()).strip()
iv = match.group("iv")
iv = int(iv, 16).to_bytes(length=16, byteorder='big')
cryptor = AES.new(key, AES.MODE_CBC, key)
tasks = []
i = 0
sem = Semaphore(self.max_worker)
async with ClientSession(headers={
"user-agent": "user-agent"}) as session:
for url in file_line:
if url.startswith("http"):
tasks.append(self.download(session, url, i, sem))
i += 1
if url.startswith("#EXT-X-ENDLIST"):
break
logger.info("开始下载")
for task in tqdm(asyncio.as_completed(tasks), total=len(tasks)):
num, content = await task
with open(os.path.join(tempdir, f"{num}.ts"), "wb") as f:
f.write(cryptor.decrypt(content))
# 合并
logger.debug("合并中")
coursename = re.sub(r"[^\d\w]", "", coursename)
if not (os.path.exists(f"./{coursename}") and os.path.isdir(f"./{coursename}")):
os.mkdir(f"./{coursename}")
with open(f"./{coursename}/{name}.mp4", "wb") as f:
for num in tqdm(range(i)):
with open(os.path.join(tempdir, f"{num}.ts"), "rb") as ff:
f.write(ff.read())
async def download(self, session, url, num, sem) -> bytes:
async with sem:
response = await session.get(url)
content = await response.content.read()
return num, content
def get_input_list(self, r_input):
"""解析选择的序号
Args:
r_input (str): [原始输入]
>>> get_input_list("1, 2, 3")
[1, 2, 3]
>>> get_input_list("1-3")
[1, 2, 3]
>>> get_input_list("1-4,5,6-8")
[1, 2, 3, 4, 5, 6, 7, 8]
"""
result = []
r_input = re.sub(r"[^\d\-\,]", "", r_input) # 去掉多余不支持的符号
d_s: List[str] = r_input.split(",") # 先按照都好分隔
for d in d_s:
if d.isdigit():
result.append(int(d))
elif "-" in d:
start, end = d.split("-")
result += list(range(int(start), int(end)+1))
return result
if __name__ == "__main__":
try:
asyncio.run(Siki().main())
except Exception as e:
logger.error(f"{e}")
finally:
os.system("pause")
4、运行效果






5、一些小问题
如果终端显示二维码像这样

设置一下等宽字体就行了, 同样在cmd或者powershell也是一样, 设置字体, 百度设置等宽字体
6、声明
仅供学术交流, 请勿违法使用, 如有不足之处或更多技巧,欢迎指教补充。