Spark Streaming架构原理详解!
目录
-
- 一、Spark Streaming功能介绍
-
- (1)概述
- (2)DStream概述
- (3)Storm和Spark Streaming比较
- 二、Spark Streaming服务架构及工作原理
- 三、StreamingContext原理详解
- 四、DStream和Receiver详解
- 五、Spark Streaming基于HDFS的实时计算开发
- 六、Spark Streaming读取并处理Socket流数据
- 七、Spark Streaming结果数据保存到MySQL数据库
- 八、Spark Streaming与Kafka集成进行数据处理
- 九、Spark Streaming 集成Kafka开发- 基于Direct的方式
一、Spark Streaming功能介绍
(1)概述
Spark Streaming是一个基于Spark Core之上的实时计算框架,可以从很多数据源消费数据并对数据进行处理.Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘。在“One Stack rule them all”的基础上,还可以使用Spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
关于spark streaming的更多了解可以见官方文档
http://spark.apache.org/docs/2.4.6/streaming-programming-guide.html#checkpointing
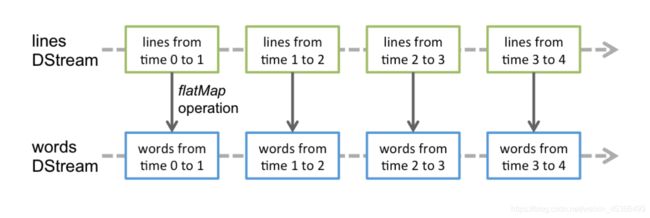
Spark Streaming处理的数据流图:

在内部,它的工作方式如下。Spark Streaming接收实时输入数据流,并将数据分成批处理,然后由Spark引擎进行处理,以生成批处理的最终结果流。

(2)DStream概述
和 Spark 基于 RDD 的概念很相似, Spark Streaming 使用 离散化流 (discretized stream)作 为抽象表示,叫作 DStream。DStream 是随时间推移而收到的数据的序列。 在内部, 每个 时间区间收到的数据都作为 RDD 存在, 而 DStream 是由这些 RDD 所组成的序列(因此 得名“离散化”)。 DStream 可以从各种输入源创建, 比如 Flume、Kafka 或者 HDFS。也可以通过对其他DStream应用高级操作来创建DStream。在内部,DStream表示为RDD序列 。 创 建出来的 DStream 支持两种操作, 一种是 转化操作 (transformation), 会生成一个新的 DStream, 另一种是 输出操作 (output operation) , 可以把数据写入外部系统中。 DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比 如滑动窗口。

- 批数据(batch data):这是化整为零的第一步,将实时流数据以时间片为单位进行分批,将流处理转化为时间片数据的批处理。随着持续时间的推移,这些处理结果就形成了对应的结果数据流了。
- 时间片或批处理时间间隔( batch interval):这是人为地对流数据进行定量的标准,以时间片作为我们拆分流数据的依据。一个时间片的数据对应一个RDD实例。
- 窗口长度(window length):一个窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数
- 滑动时间间隔:前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数
- Input DStream:一个input DStream是一个特殊的DStream,将Spark Streaming连接到一个外部数据源来读取数据。
对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一 个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream 中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的 一个RDD。底层的RDD的transformation操作,其实,还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。
(3)Storm和Spark Streaming比较
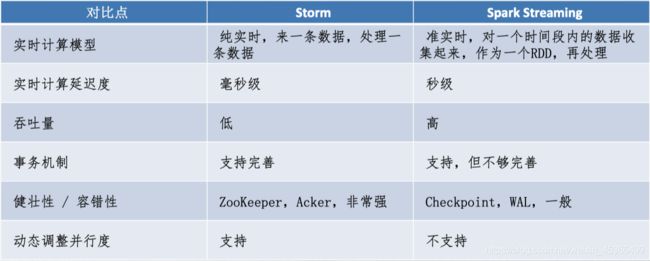
处理模型以及延迟
虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming可以在一个短暂的时间窗口里面处理多条(batches)Event。所以说Storm可以实现亚秒级时延的处理,而Spark Streaming则有一定的时延。
容错和数据保证
然而两者的代价都是容错时候的数据保证,Spark Streaming的容错为有状态的计算提供了更好的支持。在Storm中,每条记录在系统的移动过程中都需要被标记跟踪,所以Storm只能保证每条记录最少被处理一次,但是允许从错误状态恢复时被处理多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确。
任一方面,Spark Streaming仅仅需要在批处理级别对记录进行追踪,所以他能保证每个批处理记录仅仅被处理一次,即使是node节点挂掉。虽然说Storm的 Trident library可以保证一条记录被处理一次,但是它依赖于事务更新状态,而这个过程是很慢的,并且需要由用户去实现。
实现和编程API
Storm主要是由Clojure语言实现,Spark Streaming是由Scala实现。如果你想看看这两个框架是如何实现的或者你想自定义一些东西你就得记住这一点。Storm是由BackType和Twitter开发,而Spark Streaming是在UC Berkeley开发的。
Storm提供了Java API,同时也支持其他语言的API。 Spark Streaming支持Scala和Java语言(其实也支持Python)。
批处理框架集成
Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的。这样你就可以想使用其他批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询。这就减少了单独编写流批量处理程序和历史数据处理程序。
生产支持
Storm已经出现好多年了,而且自从2011年开始就在Twitter内部生产环境中使用,还有其他一些公司。而Spark Streaming是一个新的项目,并且在2013年仅仅被Sharethrough使用(据作者了解)。
Storm是 Hortonworks Hadoop数据平台中流处理的解决方案,而Spark Streaming出现在 MapR的分布式平台和Cloudera的企业数据平台中。除此之外,Databricks是为Spark提供技术支持的公司,包括了Spark Streaming。
虽然说两者都可以在各自的集群框架中运行,但是Storm可以在Mesos上运行, 而Spark Streaming可以在YARN和Mesos上运行。
二、Spark Streaming服务架构及工作原理
Spark Streaming 为每个输入源启动对 应的 接收器 。 接收器以任务的形式运行在应用的执行器进程中, 从输入源收集数据也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset)。 它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默 认行为)。数据保存在执行器进程的内存中,和缓存 RDD 的方式一样 。驱动器程序中的 StreamingContext 会周期性地运行 Spark 作业来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。下图显示了Spark Streaming的整个流程。
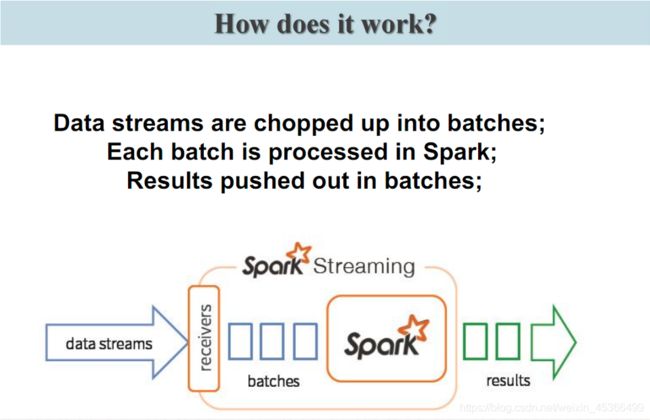
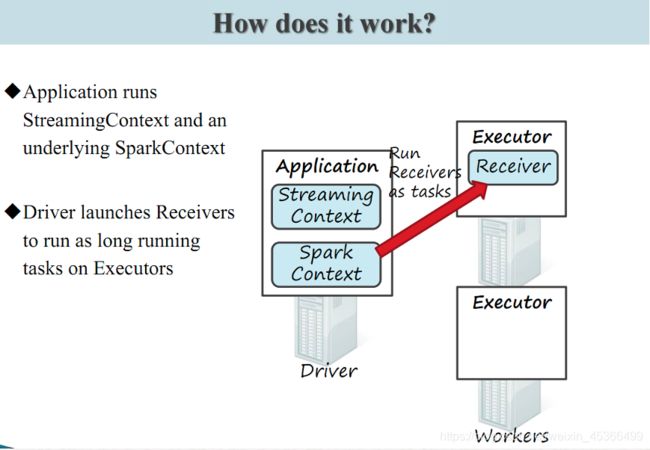
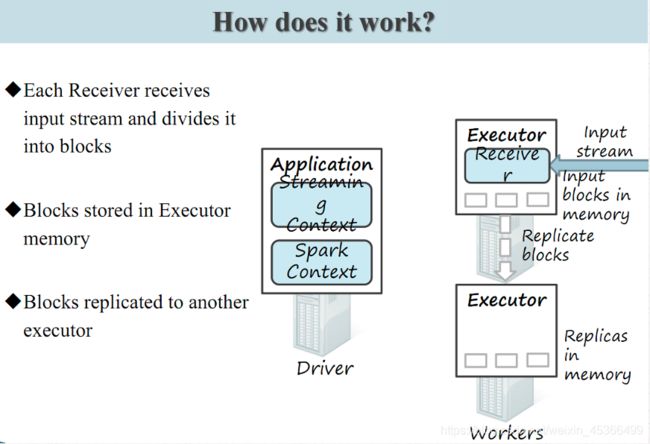
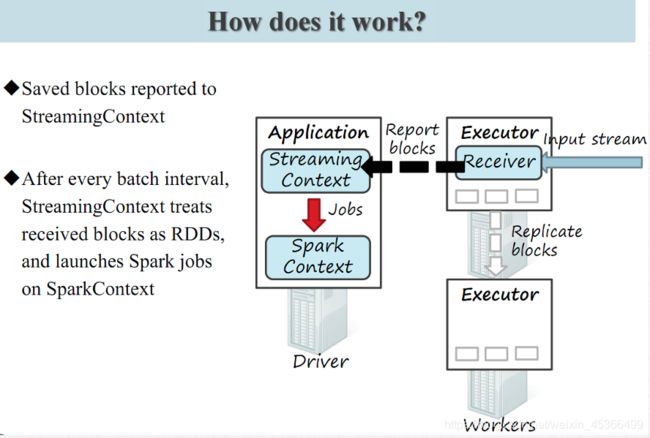
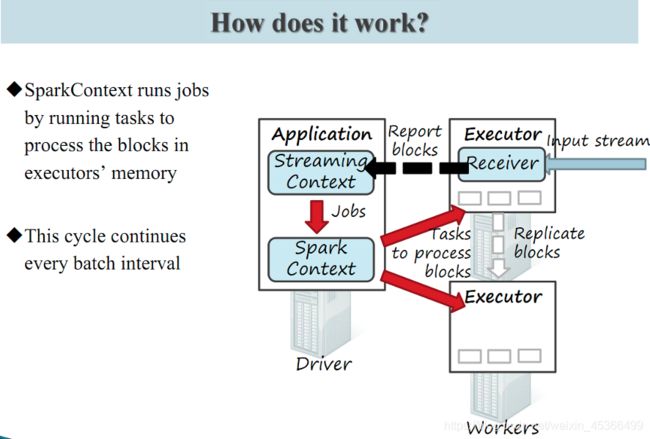

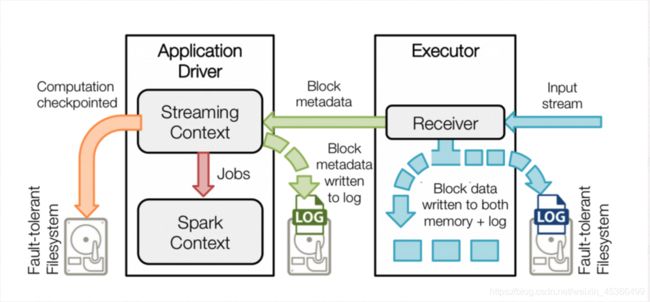
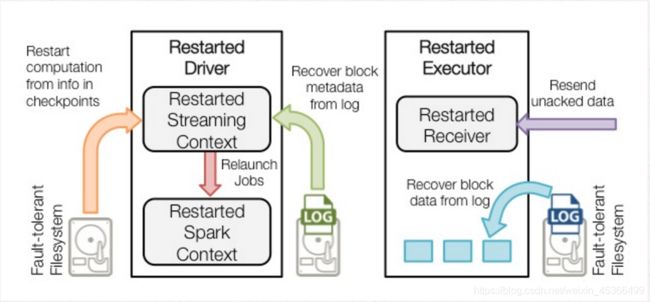
Spark Streaming 在 Spark 各组件中的执行过程:
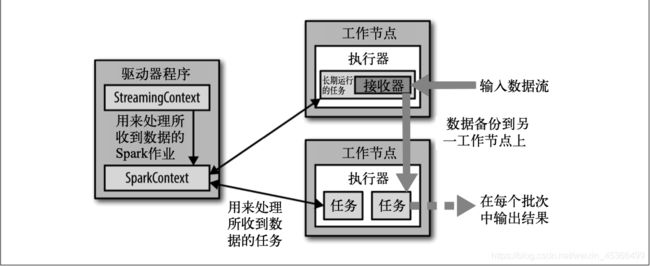
Spark Streaming 对 DStream 提供的容错性与 Spark 为 RDD 所提供的容错性一致:只要输 入数据还在,它就可以使用 RDD 谱系重算出任意状态
三、StreamingContext原理详解
StreamingContext初始化的两种方式
第一种:
val ssc = new StreamingContext(sc, Seconds(1))
第二种:
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
通常我们选择用第一种方法。
appName,是用来在Spark UI上显示的应用名称。master,是一个Spark、Mesos或者Yarn集群的URL,或者 是local[*]。
一个StreamingContext定义之后,必须做以下几件事情:
- 通过创建输入DStream来创建输入数据源。
- 通过对DStream定义transformation和output算子操作,来定义实时计算逻辑。
- 调用StreamingContext的start()方法,来开始实时处理数据。
- 调用StreamingContext的awaitTermination()方法,来等待应用程序的终止。可以使用CTRL+C手动停 止,或者就是让它持续不断的运行进行计算。
- 也可以通过调用StreamingContext的stop()方法,来停止应用程序。
需要注意的要点:
- 只要一个StreamingContext启动之后,就不能再往其中添加任何计算逻辑了。比如执行start()方 法之后,还给某个DStream执行一个算子。
- 一个StreamingContext停止之后,是肯定不能够重启的。调用stop()之后,不能再调用start()
- 一个JVM同时只能有一个StreamingContext启动。在你的应用程序中,不能创建两个 StreamingContext。
- 一个SparkContext可以创建多个StreamingContext,只要上一个先用stop(false)停止,再创建下 一个即可。
四、DStream和Receiver详解
输入DStream代表了来自数据源的输入数据流。在之前的wordcount例子中,lines就是一个输入 DStream(JavaReceiverInputDStream),代表了从netcat(nc)服务接收到的数据流。除了文件数 据流之外,所有的输入DStream都会绑定一个Receiver对象,该对象是一个关键的组件,用来从数据 源接收数据,并将其存储在Spark的内存中,以供后续处理。
Spark Streaming提供了两种内置的数据源支持;
- 1、基础数据源:StreamingContext API中直接提供了对这些数据源的支持,比如文件、socket、 Akka Actor等。
- 2、高级数据源:诸如Kafka、Flume、Kinesis、Twitter等数据源,通过第三方工具类提供支持。这
些数据源的使用,需要引用其依赖。 - 3、自定义数据源:我们可以自己定义数据源,来决定如何接受和存储数据。
要注意的是,如果你想要在实时计算应用中并行接收多条数据流,可以创建多个输入DStream。这样 就会创建多个Receiver,从而并行地接收多个数据流。但是要注意的是,一个Spark Streaming Application的Executor,是一个长时间运行的任务,因此,它会独占分配给Spark Streaming Application的cpu core。从而只要Spark Streaming运行起来以后,这个节点上的cpu core,就没法 给其他应用使用了。
使用本地模式,运行程序时,绝对不能用local或者local[1],因为那样的话,只会给执行输入 DStream的executor分配一个线程。而Spark Streaming底层的原理是,至少要有两条线程,一条线程 用来分配给Receiver接收数据,一条线程用来处理接收到的数据。因此必须使用local[n],n>=2的模 式。
如果不设置Master,也就是直接将Spark Streaming应用提交到集群上运行,那么首先,必须要求集 群节点上,有>1个cpu core,其次,给Spark Streaming的每个executor分配的core,必须>1,这样, 才能保证分配到executor上运行的输入DStream,两条线程并行,一条运行Receiver,接收数据;一 条处理数据。否则的话,只会接收数据,不会处理数据。
五、Spark Streaming基于HDFS的实时计算开发
基于HDFS文件的实时计算,其实就是,监控一个HDFS目录,只要其中有新文件出现,就实时处理。
相当于处理实时的文件流。
streamingContext.fileStream<KeyClass, ValueClass, InputFormatClass>(dataDirectory)
streamingContext.streamingContext.textFileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
Spark Streaming会监视指定的HDFS目录,并且处理出现在目录中的文件。要注意的是,所有放入 HDFS目录中的文件,都必须有相同的格式;必须使用移动或者重命名的方式,将文件移入目录;一旦 处理之后,文件的内容即使改变,也不会再处理了;基于HDFS文件的数据源是没有Receiver的,因此 不会占用一个cpu core。
创建输入流数据源目录:
bin/hdfs dfs -mkdir -p /user/caizhengjie/datas/sparkstreaming
写入数据:
bin/hdfs dfs -put /opt/datas/11.txt /user/caizhengjie/datas/sparkstreaming
bin/hdfs dfs -copyFromLocal /opt/datas/11.txt /user/caizhengjie/datas/sparkstreaming1.txt
源数据节点时间必须与计算节点时间保持同步(重点)
Java语言实现:
package com.kfk.spark.stream;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/12/14
* @time : 2:12 下午
*/
public class HDFSWordCountJava {
public static void main(String[] args) throws InterruptedException {
// Create a local StreamingContext with two working thread and batch interval of 5 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
String path = "hdfs://bigdata-pro-m04:9000/user/caizhengjie/datas/sparkstreaming/";
// hdfs数据源
JavaDStream<String> lines = jssc.textFileStream(path);
// flatmap
JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
// map
JavaPairDStream<String,Integer> pair = words.mapToPair(word -> new Tuple2<>(word,1));
// reduceByKey
JavaPairDStream<String,Integer> wordcount = pair.reduceByKey((x,y) -> x+y);
wordcount.print();
jssc.start();
jssc.awaitTermination();
}
}
Scala语言实现:
package com.kfk.spark.stream
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{
Durations, StreamingContext}
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/12/14
* @time : 8:11 下午
*/
object HDFSWordCountScala {
def main(args: Array[String]): Unit = {
// Create a local StreamingContext with two working thread and batch interval of 5 second
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val jssc = new StreamingContext(conf, Durations.seconds(1))
val path = "hdfs://bigdata-pro-m04:9000/user/caizhengjie/datas/sparkstreaming/"
val lines = jssc.textFileStream(path)
// flatmap
val words = lines.flatMap(word => word.split(" "))
// map
val pair = words.map(x => (x,1))
// reduceByKey
val wordcount = pair.reduceByKey((x,y) => x+y)
wordcount.print()
jssc.start()
jssc.awaitTermination()
}
}
六、Spark Streaming读取并处理Socket流数据
当基于Spark -shell运行Streaming程序时,需要注意要不线程数大于1,要么基于集群
bin/spark-shell --master local[2]
bin/spark-shell --master spark:node1:7077
传递给spark的master URL可以有如下几种:
- local本地单线程
- local[K]本地多线程(指定K个内核)
- 1ocal[*]本地多线程(指定所有可用内核)
- spark://HOST:PORT连接到指定的 Spark standalone clustermaster, 需要指定端口。
- mesos://HOST:PORT 连接到指定的Mesos集群,需要指定端口。
- yarn-client客户端模式连接到YARN集群。需要配置HADOOP_ CONF_ DIR。
- yarn-cluster集群模式连接到YARN集群。需要配置HADOOP_ CONF_ DIR。
NC服务安装并运行Spark Streaming
NetCat 下载地址: http://rpm.pbone.net/index.php3/stat/4/idpl/15991371/dir/scientific_linux_6/com/nc1.84-22.el6.x86_64.rpm.html
这里提供百度云下载
链接: https://pan.baidu.com/s/1pFDTnLihK3ODELhDGkQHRQ 密码: u10t
下载完成之后,将它上传到/opt/Hadoop目录下
然后开始安装:
sudo rpm -ivh nc-1.84-22.el6.x86_64.rpm
首先需要通过使用以下命令将Netcat作为数据服务器运行
nc -lk 9999
下面通过idea工具来编写Spark Streaming程序
Java语言实现
package com.kfk.spark.stream;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* lambda表达式写法
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/12/13
* @time : 9:25 下午
*/
public class WordCountJava {
public static void main(String[] args) throws InterruptedException {
// Create a local StreamingContext with two working thread and batch interval of 5 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("bigdata-pro-m04",9999);
// flatmap
JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
// map
JavaPairDStream<String,Integer> pair = words.mapToPair(word -> new Tuple2<>(word,1));
// reduceByKey
JavaPairDStream<String,Integer> wordcount = pair.reduceByKey((x,y) -> x+y);
wordcount.print();
jssc.start();
jssc.awaitTermination();
}
}
scala语言实现
package com.kfk.spark.stream
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{
Seconds, StreamingContext}
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/12/14
* @time : 12:54 下午
*/
object WordCountScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("bigdata-pro-m04", 9999)
// flatmap
val words = lines.flatMap(word => word.split(" "))
// map
val pair = words.map(x => (x,1))
// reduceByKey
val wordcount = pair.reduceByKey((x,y) => x+y)
wordcount.print()
ssc.start()
ssc.awaitTermination()
}
}
七、Spark Streaming结果数据保存到MySQL数据库
下面我们测试一下Spark Streaming将结果保存到MySQL数据库
还是上面的案例,通过sparkstreaming将单词和次数写入到数据库中
package com.spark.test
import java.sql.DriverManager
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{
Seconds, StreamingContext}
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/9/27
* @time : 3:43 下午
*/
object TestStreaming {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("HdfsTest")
.getOrCreate()
val sc = spark.sparkContext
val ssc = new StreamingContext(sc,Seconds(5))
val lines = ssc.socketTextStream("10.211.55.59",9999)
val words = lines.flatMap(_.split(" ")).map(word => (word,1)).reduceByKey(_ + _)
// 将rdd展开
words.foreachRDD(rdd => rdd.foreachPartition(line =>{
// 加载驱动
Class.forName("com.mysql.jdbc.Driver")
// 过去connection
val conn = DriverManager.getConnection("jdbc:mysql://node1:3306/test","root","199911")
try{
// 遍历每一行数据写入数据库
for (row <- line){
val sql = "insert into wordCount(titleName,count) values('"+row._1+"',"+row._2+")"
conn.prepareStatement(sql).executeUpdate()
}
}finally {
conn.close()
}
}))
words.print()
ssc.start()
ssc.awaitTermination()
}
}
首先启动nc服务
nc -lk 9999
这里我是使用spark-shell运行的,运行的方式:
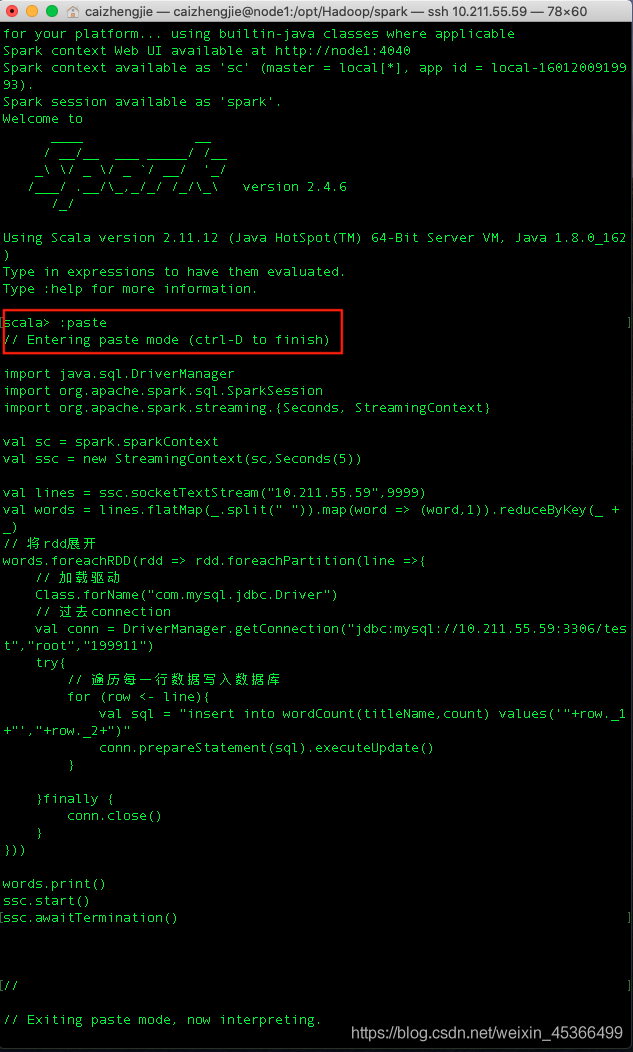
通过使用:paste可以复制多行代码。
查看测试数据:
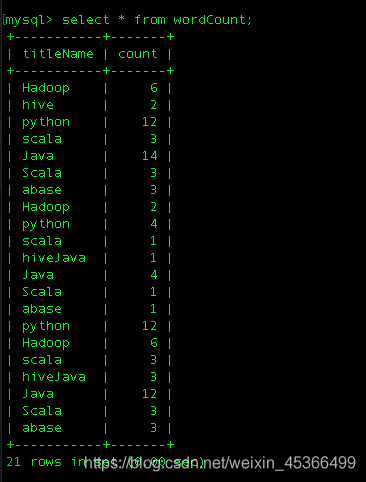
八、Spark Streaming与Kafka集成进行数据处理
Kafka项目在版本0.8和0.10之间引入了新的使用者API,因此有2个单独的相应Spark Streaming包可用。请为您的经纪人和所需功能选择正确的软件包;请注意,0.8集成与以后的0.9和0.10代理兼容,但0.10集成与早期的代理不兼容。
注意:自Spark 2.3.0起已弃用Kafka 0.8支持。
这里我使用的版本是kafka_2.11-2.1.1
相关操作可以看一下官网的解释:
http://spark.apache.org/docs/2.4.6/streaming-kafka-0-10-integration.html
首先加载pom.xml的配置文件
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.binary.version}</artifactId>
<version>${saprk.version}</version>
</dependency>
Creating a Direct Stream
请注意,导入的名称空间包括版本org.apache.spark.streaming.kafka010
Direct方式案例
第一步:启动服务
首先要启动zookeeper,再启动kafka,三台要同时启动
启动zookeeper:
zkServer.sh start
启动kafka
在前台启动kafka,注意查看打印在桌面的日志,有无报错信息
bin/kafka-server-start.sh config/server.properties
如果没有报错信息,启动正常,那么就可以在后台启动了
bin/kafka-server-start.sh -daemon config/server.properties
第二步:创建topic
创建一个分区和一个副本的“spark”的topic
bin/kafka-topics.sh --create --zookeeper bigdata-pro-m04:2181 --replication-factor 1 --partitions 1 --topic spark
第三步:启动sparkstreaming与kafka连接
Java语言实现
package com.kfk.spark.common;
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/12/14
* @time : 8:23 下午
*/
public class CommStreamingContext {
public static JavaStreamingContext getJssc(){
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("CommStreamingContext");
return new JavaStreamingContext(conf, Durations.seconds(2));
}
}
package com.kfk.spark.stream;
import com.kfk.spark.common.CommStreamingContext;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/12/14
* @time : 8:20 下午
*/
public class StreamingKafkaJava {
public static void main(String[] args) throws InterruptedException {
JavaStreamingContext jssc = CommStreamingContext.getJssc();
// sparkstreaming与kafka连接
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "bigdata-pro-m04:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "streaming_kafka_1");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
// 设置topic
Collection<String> topics = Arrays.asList("spark");
// kafka数据源
JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams)
);
// flatmap
JavaDStream<String> words = stream.flatMap(record -> Arrays.asList(record.value().trim().split(" ")).iterator());
// map
JavaPairDStream<String,Integer> pair = words.mapToPair(word -> new Tuple2<>(word,1));
// reduceByKey
JavaPairDStream<String,Integer> wordcount = pair.reduceByKey((x,y) -> x+y);
wordcount.print();
jssc.start();
jssc.awaitTermination();
}
}
scala语言实现:
package com.kfk.spark.stream
import com.kfk.spark.common.CommStreamingContextScala
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
/**
* @author : 蔡政洁
* @email :[email protected]
* @date : 2020/12/14
* @time : 9:56 下午
*/
object StreamingKafkaScala {
def main(args: Array[String]): Unit = {
val jssc = CommStreamingContextScala.getJssc;
// sparkstreaming与kafka连接
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "bigdata-pro-m04:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "streaming_kafka_1",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 设置topic
val topics = Array("spark")
// kafka数据源
val stream = KafkaUtils.createDirectStream[String, String](
jssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
// flatmap
val words = stream.flatMap(record => record.value().trim.split(" "))
// map
val pair = words.map(x => (x,1))
// reduceByKey
val wordcount = pair.reduceByKey((x,y) => x+y)
wordcount.print()
jssc.start()
jssc.awaitTermination()
}
}
运行上面代码,出现下图所示表示连接成功
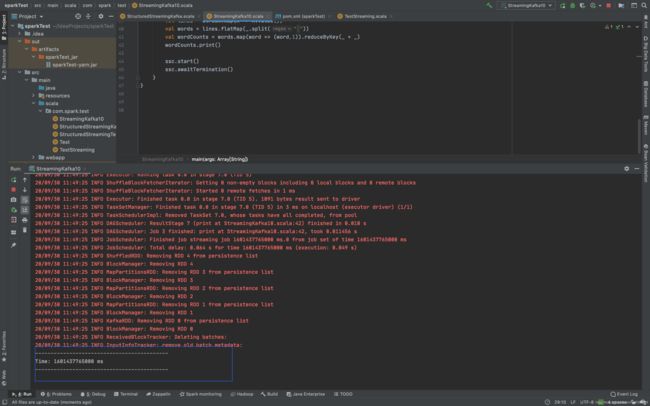
第四步:启动生产者
bin/kafka-console-producer.sh --broker-list bigdata-pro-m04:9092 --topic spark
测试示例:
>java java hive hive
>hadoop hbase java
运行结果:
到这里就表示SparkStreaming与Kafka集成成功!
九、Spark Streaming 集成Kafka开发- 基于Direct的方式
在Spark 1.3之后通过createDirectStream替代掉原来使用Receiver来接收数据,这种方式会周期性地查询 Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的 job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
这种方式有如下优点:
1、简化并行读取: 如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。 Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系。
2、高性能: 如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低 下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复 制一份到WAL中。而基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复 制,那么就可以通过Kafka的副本进行恢复。
3、一次且仅一次的事务机制:
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费 Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被 处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在 checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次。
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!