在上篇 spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRPCEnv 中,涉及到了Diapatcher 内容,未做过多的剖析。本篇来剖析一下它的工作原理。
Dispatcher 是消息的分发器,负责将消息分发给适合的 endpoint
其实这个类还是比较简单的,先来看它的类图:

我们从成员变量入手分析整个类的内部构造和机理:
1. endpoints是一个 ConcurrentMap[String, EndpointData], 负责存储 endpoint name 和 EndpointData 的映射关系。其中,EndpointData又包含了 endpoint name, RpcEndpoint 以及 NettyRpcEndpointRef 的引用以及Inbox 对象(包含了RpcEndpoint 以及 NettyRpcEndpointRef 的引用)。
2. endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] 包含了 RpcEndpoint 和 RpcEndpointRef 的映射关系。
3. receivers 是一个 LinkedBlockingQueue[EndpointData] 消息阻塞队列,用于存放 EndpointData 对象。它主要用于追踪 那些可能会包含需要处理消息receiver(即EndpointData)。在post消息到Dispatcher 时,一般会先post 到 EndpointData 的 Inbox 中, 然后,再将 EndpointData对象放入 receivers 中,源码如下:
// Posts a message to a specific endpoint. private def postMessage( endpointName: String, message: InboxMessage, callbackIfStopped: (Exception) => Unit): Unit = { val error = synchronized { // 1. 先根据endpoint name从路由中找到data val data = endpoints.get(endpointName) if (stopped) { Some(new RpcEnvStoppedException()) } else if (data == null) { Some(new SparkException(s"Could not find $endpointName.")) } else { // 2. 将待消费的消息发送到 inbox中 data.inbox.post(message) // 3. 将 data 放到待消费的receiver 中 receivers.offer(data) None } } // We don't need to call `onStop` in the `synchronized` block error.foreach(callbackIfStopped) }
4. stopped 标志 Dispatcher 是否已经停止了
5. threadpool 是 ThreadPoolExecutor 对象, 其中的 线程的 core 数量的计算如下:
val availableCores = if (numUsableCores > 0) numUsableCores else Runtime.getRuntime.availableProcessors()val numThreads = nettyEnv.conf.getInt("spark.rpc.netty.dispatcher.numThreads", math.max(2, availableCores))
获取到线程数之后, 会初始化 一个固定的线程池,用来执行 MessageLoop 任务,MessageLoop 是一个Runnable 对象。它会不停地从 receiver 堵塞队列中, 把放入的 EndpointData对象取出来,并且去调用其inbox成员变量的 process 方法。
6. PoisonPill 是一个空的EndpointData对象,起了一个标志位的作用,如果想要停止 Diapatcher ,会把PoisonPill 喂给 receiver 吃,当threadpool 执行 MessageLoop 任务时, 吃到了毒药,马上退出,线程也就死掉了。PoisonPill命名很形象,关闭线程池的方式也是优雅的,是值得我们在工作中去学习和应用的。
从上面的成员变量分析部分可以知道,数据通过 postMessage 方法将 InboxMessage 数据 post 到 EndpointData的Inbox对象中,并将待处理的EndpointData 对象放入到 receivers 中,线程池会不断从这个队列中拿数据,分发数据。
引出Inbox
其实,data 就包含了 RpcEndpoint 和 RpcEndpointRef 对象,本可以在Dispatcher 中就可以调用 endpoint 的方法去处理。为什么还要设计出来一个 Inbox 层次的抽象呢?
下面我们就趁热剖析一下 Inbox 这个对象。
Inbox剖析
Inbox 的官方解释:
An inbox that stores messages for an RpcEndpoint and posts messages to it thread-safely.
其实就是它为RpcEndpoint 对象保存了消息,并且将消息 post给 RpcEndpoint,同时保证了线程的安全性。
类图如下:

跟 put 和 get 语义相似的有两个方法, 分别是post 和 process。其实这两个方法都是给 Dispatcher 对象调用的。post 将数据 存放到 堵塞消息队列队尾, pocess 则堵塞式 从消息队列中取出数据来,并处理之。
这两个关键方法源码如下:
1 def post(message: InboxMessage): Unit = inbox.synchronized { 2 if (stopped) { 3 // We already put "OnStop" into "messages", so we should drop further messages 4 onDrop(message) 5 } else { 6 messages.add(message) 7 false 8 } 9 } 10 11 12 /** 13 * Calls action closure, and calls the endpoint's onError function in the case of exceptions. 14 */ 15 private def safelyCall(endpoint: RpcEndpoint)(action: => Unit): Unit = { 16 try action catch { 17 case NonFatal(e) => 18 try endpoint.onError(e) catch { 19 case NonFatal(ee) => 20 if (stopped) { 21 logDebug("Ignoring error", ee) 22 } else { 23 logError("Ignoring error", ee) 24 } 25 } 26 } 27 } 28 29 /** 30 * Process stored messages. 31 */ 32 def process(dispatcher: Dispatcher): Unit = { 33 var message: InboxMessage = null 34 inbox.synchronized { 35 if (!enableConcurrent && numActiveThreads != 0) { 36 return 37 } 38 message = messages.poll() 39 if (message != null) { 40 numActiveThreads += 1 41 } else { 42 return 43 } 44 } 45 while (true) { 46 safelyCall(endpoint) { 47 message match { 48 case RpcMessage(_sender, content, context) => 49 try { 50 endpoint.receiveAndReply(context).applyOrElse[Any, Unit](content, { msg => 51 throw new SparkException(s"Unsupported message $message from ${_sender}") 52 }) 53 } catch { 54 case e: Throwable => 55 context.sendFailure(e) 56 // Throw the exception -- this exception will be caught by the safelyCall function. 57 // The endpoint's onError function will be called. 58 throw e 59 } 60 61 case OneWayMessage(_sender, content) => 62 endpoint.receive.applyOrElse[Any, Unit](content, { msg => 63 throw new SparkException(s"Unsupported message $message from ${_sender}") 64 }) 65 66 case OnStart => 67 endpoint.onStart() 68 if (!endpoint.isInstanceOf[ThreadSafeRpcEndpoint]) { 69 inbox.synchronized { 70 if (!stopped) { 71 enableConcurrent = true 72 } 73 } 74 } 75 76 case OnStop => 77 val activeThreads = inbox.synchronized { inbox.numActiveThreads } 78 assert(activeThreads == 1, 79 s"There should be only a single active thread but found $activeThreads threads.") 80 dispatcher.removeRpcEndpointRef(endpoint) 81 endpoint.onStop() 82 assert(isEmpty, "OnStop should be the last message") 83 84 case RemoteProcessConnected(remoteAddress) => 85 endpoint.onConnected(remoteAddress) 86 87 case RemoteProcessDisconnected(remoteAddress) => 88 endpoint.onDisconnected(remoteAddress) 89 90 case RemoteProcessConnectionError(cause, remoteAddress) => 91 endpoint.onNetworkError(cause, remoteAddress) 92 } 93 } 94 95 inbox.synchronized { 96 // "enableConcurrent" will be set to false after `onStop` is called, so we should check it 97 // every time. 98 if (!enableConcurrent && numActiveThreads != 1) { 99 // If we are not the only one worker, exit 100 numActiveThreads -= 1 101 return 102 } 103 message = messages.poll() 104 if (message == null) { 105 numActiveThreads -= 1 106 return 107 } 108 } 109 } 110 }
其中,InboxMessage 继承关系如下:

这些InboxMessage子类型在process 方法源码中有体现。其中OneWayMessage和RpcMessage 都是自带消息content 的,其他的几种都是消息事件,本身不带任何除事件类型信息之外的信息。
在process 处理过程中,考虑到了 一次性批量处理消息问题、多线程安全问题、异常抛出问题,多消息分支处理问题等等。
此时可以回答上面我们的疑问了,抽象出来 Inbox 的原因在于,Diapatcher 的职责变得单一,只需要把数据分发就可以了。具体分发数据要如何处理的问题留给了 Inbox,Inbox 把关注点放在了 如何处理这些消息上。考虑并解决了 一次性批量处理消息问题、多线程安全问题、异常抛出问题,多消息分支处理问题等等问题。
Outbox
下面看一下Outbox, 它的内部构造和Inbox很类似,不再剖析。
OutboxMessage的继承关系如下:

其中,OneWayOutboxMessage 的行为是特定的。源码如下:

它没有回调方法。
RpcOutboxMessage 的回调则是通过构造方法传进来的。其源码如下:
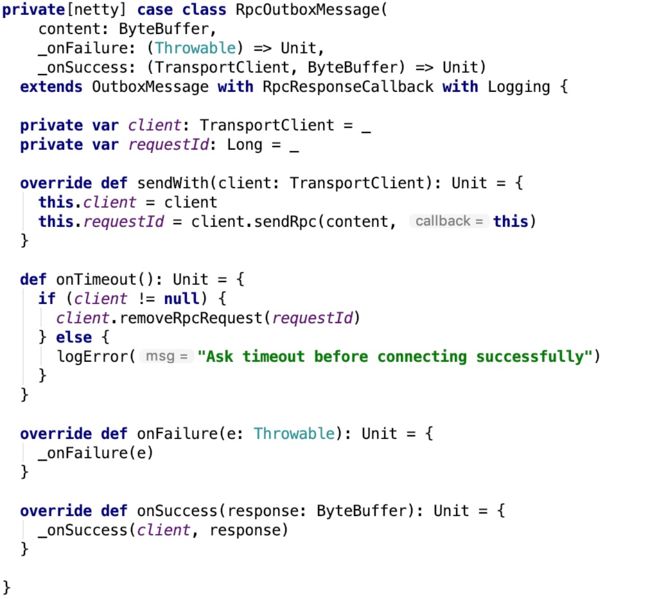
RpcOutboxMessage 是有回调的,回调方法通过构造方法指定,内部onFailure和onSuccess是模板方法。