PP-OCR:实用超轻量级文本识别系统设计详解

相信很多人对今年上半年YOLOv4的出现记忆尤新,YOLOv4在算法设计上吸纳了众多目标检测任务中验证有效的新技术、新trick,从数据处理、模型设计、训练策略等全方位尝试,最终有机组合出在算法精度和效率实现最好平衡的算法。
虽然YOLOv4没有带来新的算法技术或理念,但结果却是工业界非常欢迎的。
前段时间,百度公布并开源了OCR领域的新算法PP-OCR,其也是从工业界实用性角度出发,集近年来深度学习、OCR、模型压缩等技术进展之大成者,今天我们就一起来看看作者都做了哪些工作。
该文作者信息:

论文地址:
PP-OCR: A Practical Ultra Lightweight OCR System
开源地址:
https://github.com/PaddlePaddle/PaddleOCR
作者全部来自百度。
01
算法架构
典型的OCR系统,按照流程分为两大支:
1)先检测后识别(detection then recognition);
2)端到端识别(end to end text spotting);
作者们选择传统的先文本检测后文本识别的流程,另外对于检测到的文本,作者使用了校正模块。所以整体流程如下:

主要分文本检测、检测包围框校正和文本识别三部分。从上图可以看出这三部分主要使用的技术:
1)文本检测:
可微分二值化文本检测方法(DB ,Liao et al. 2020,更多详情: 高达82 fps的实时文本检测,华科AAAI2020提出可微分二值化模块),其为今年新出现的速度快精度高的方法,如下图:

除此之外,作者使用了6种技术来增强模型表示能力降低模型大小。
分别为:
1.1 Light Backbone 轻主干网
mv3代表作者使用了MobileNetv3作为骨干网,如下图:

作者对今年出现的轻量级网络结构进行了比较实验,发现在文本检测问题中用MobileNetv3 做骨干网的效果最好,MobileNetV3_large_x0.5 取得了最好的结果。
1.2 Light Head 轻检测头
检测部分是FPN结构,定义更小的inner_channels,使模型大幅减小,而精度几乎不下降。模型从 7 M 减小到4.1M。
1.3 Remove SE 去除SE模块
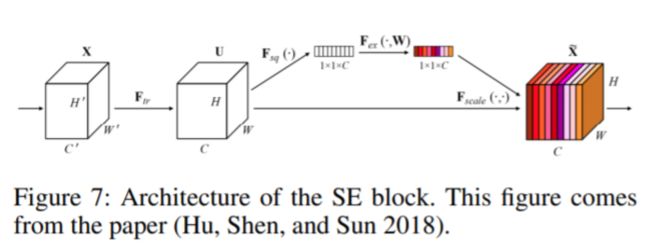
作者返现在文本检测问题中,去除主干网中的SE模块,精度几乎不变,计算量和参数两大幅减少,模型从4.1M降到2.5M。
1.4 Cosine Learning Rate Decay 余弦学习率衰减

作者发现用余弦学习率衰减方法比阶梯式衰减得到的检测精度更高。
1.5 Learning Rate Warm-up
训练中使用学习率Warm-up ,也是有效的。
1.6 FPGM Pruner 剪枝

对于设计好的模型,依然很有必要进行剪枝,作者使用了FPGM (He et al. 2019b),去掉不重要的网络部分。
以上结合,模型经优化压缩后仅1.4M。
2)检测包围框校正:
一般从检测包围框通过一定的几何变换即可得到归一化后的文本区域,但作者发现在大量的文本图像中,检测到的文本需要进行方向旋转,这部分作者使用直接分类的方法进行判断,同样也是使用MobieNetv3做特征提取。
2.1 Light backbone 轻骨干网
使用MobileNetV3_small_x0.35做主干网。
2.2 Data Augmentation 数据增广
出了常规的旋转、透视变换、模糊,作者尝试了大量的数据增广方法(
AutoAugment (Cubuk et al. 2019),RandAugment (Cubuk et al. 2020), CutOut (DeVries and Taylor 2017), RandErasing (Zhong et al. 2020), HideAndSeek (Singh and Lee 2017), GridMask (Chen 2020), Mixup(Zhang et al. 2017) 和 Cutmix (Yun et al. 2019). ),最终发现只有RandAugment 和RandErasing 是有效的。
最后作者使用了常规增广和RandAugment 。
2.3 Input Resolution 输入分辨率提升
输入分辨率越高,一般精度会更高。作者把分辨率调高。
2.4 PACT Quantization PACT量化
同样这部分对模型进行了压缩,使用PACT量化方法。
最终方向分类网络的模型大小是0.5M。
3)文本识别:
文本使用作者使用被广泛使用的CRNN方法(Shi, Bai, and Yao 2016),

3.1 Light Backbone
识别部分使用 MobileNetV3_small_x0.5作为骨干网。
3.2 Data Augmentation
数据增广部分出了基本数据变换之外,还使用了TIA (Luo et al. 2020),如下:

3.3 Cosine Learning Rate Decay
同上。
3.4 Feature Map Resolution
为了适应文本这种横纵比比较高的图像,作者修改了下采样的stride,修改了特征图的分辨率。

3.5 Regularization Parameters
使用 L2_decay正则化,作者发现这部分对识别精度又重要影响。
3.6 Learning Rate Warm-up
同上。
3.7 Light Head
设置最终的序列特征维度 48。
3.8 Pretrained Model
使用合成数据预训练,精度得到重要改进。
3.9 PACT Quantization
同上,该部分代码在 https://github.com/PaddlePaddle/PaddleSlim/ 有。
02
训练数据及结果
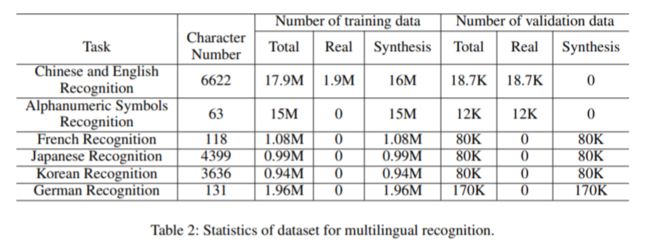
要想得到实用的模型,训练数据必须够大够好,以下是在检测、方向分类、识别三个问题中作者实用的数据规模:

不同语言类型,采用的训练数据的规模:
最终作者得到的模型结果:

因为训练数据的原因,这里的精度实在作者收集的数据集上得到的。
作为实用OCR模型,除了3.5M超轻量OCR模型可供大家实用外,百度还提供了多语言预训练模型(英、德、法、韩、日),支持自定义训练和丰富的部署方式。
03
识别效果
下图为使用PP-OCR文本检测识别的结果:


无论是对文档图像还是场景图像,PP-OCR都有不俗的表现。
作者们已将其做成产品,上传图像体验地址:
https://www.paddlepaddle.org.cn/hub/scene/ocr
04
总结
从论文描述可知,PP-OCR并没有特别的新发明,透漏着浓浓的炼丹风,但这的确是设计工业界算法的思路。
其中有不少值得借鉴的地方,比如骨干网的选择,学习率衰减的方法,不要盲目迷信上图像增广,合成数据对改进精度也很有意义等。
最后,9月26日,飞桨将举办OCR方向的线下沙龙活动,在北京的朋友可以现场跟作者交流。

(扫描海报中的二维码即可报名或加入OCR技术交流群)
更多飞桨的相关内容,请参阅以下文档。
官网地址:https://www.paddlepaddle.org.cn
·飞桨PaddleOCR项目地址·
GitHub:
https://github.com/PaddlePaddle/PaddleOCR
Gitee:
https://gitee.com/paddlepaddle/PaddleOCR
·飞桨PaddleSlim项目地址·
GitHub:
https://github.com/PaddlePaddle/PaddleSlim
Gitee:
https://gitee.com/paddlepaddle/PaddleSlim
也可以点击“阅读原文”加入线下交流