python爬虫:Python-requests模块学习笔记总结
文章目录
- 前言
- 一、requests模块使用
-
- 1.1 requests模块发送get请求
- 1.2 response响应对象
- 1.3 response.text与response.content的区别
- 1.4 通过对response.content进行decode,来解决中文乱码
- 1.5 response响应对象的其他常用的属性和方法
- 二、requests模块发送请求
-
- 2.1 发送带headers的请求
-
- 2.1.1思考
- 2.1.2 携带请求头发送请求的方法
- 2.2 发送带参数的请求
-
- 2.2.1 在url携带参数
- 2.2.2 通过params携带参数字典
- 2.3 在headers参数中携带cookie
-
- 2.3.1 github登录抓包分析
- 3.3.2 完成代码
- 2.4 cookie参数的使用
- 2.5 cookiejar对象转换为cookies字典的方法
- 2.6 超时timeout的使用
- 2.7 代理proxies的使用
-
- 2.7.1 理解使用代理的过程
- 2.7.2正向代理和反向代理
-
- 2.7.3 代理IP(代理服务器)的分类
- 2.7.4 proxies代理参数的使用
- 2.8 使用verify参数忽略CA正数
- 三、 requests模块发送post请求
-
- 3.1 requests发送post请求的方法
- 四、利用requests.session进行状态保持
-
- 4.1 requests.session的作用及应用场景
- 4.2 requests.session的使用方法
- 4.3 实例:模拟登录github
- 精彩链接
- 最后
前言
爬虫的门槛不高,高就在于往后余生的每一次实操都会让你崩溃。在这个大数据的时代,数据就是金钱!所以越来越多的企业重视数据,然后再通过爬虫的手段获取公开的数数据,为企业项目进行赋能。
上一篇文章中,我带大家入门了爬虫,知道什么是爬虫,对爬虫有了大体的了解。
本篇博文将带领大家进入新的内容,爬虫最常用的库:requests库,最后并以综合案例模拟登录github,带你实战。
一、requests模块使用
本次文章主要分享的是requests这个http模块的使用,该模块主要用于发起请求获取响应,该模块有很多替代模块,比如说urllib模块,但是在工作中使用最多的是requests模块,requests的代码语法简单易懂,相对于臃肿的urllib模块,使用requests模块写爬虫会大大减少代码量,而且实现某一功能会更简单,因此推荐大家使用requests模块。
知识点
- 掌握headers参数的使用
- 掌握发送带参数的使用
- 掌握headers中携带cookies
- 掌握cookies参数的使用
- 掌握cookieJar的掌握方法
- 掌握超时参数timeout的使用
- 掌握ip参数proxies的使用
- 掌握verify参数,忽略CA证书
- 掌握requests模块
1.1 requests模块发送get请求
1、需求:通过requests向百度发送请求,获取页面的源码
2、运行下面代码观察打印结果
demo1.py
import requests
#目标url
url = 'http://www.baidu.com'
# 向url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
1.2 response响应对象
观察上面代码运行的结果观察发现,有好多乱码,这是因为编码与解码所使用的字符集不同造成的;我们尝试使用下边的办法来解决中文乱码问题。
demo2.py
import requests
#目标url
url = 'http://www.baidu.com'
# 向url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.content.decode()) # 注意这里
1、response.text是requests模块按照charset模块推测出的编码字符串进行解码的结果。
2、网络传输的字符串都是bytes类型的数据,所以requests.text = response.content.decode(‘推测出来的编码字符集’)
3、我们可以在网页源码中搜索charset,尝试参考该编码的字符集,注意:存在不准确的情况。
1.3 response.text与response.content的区别
- response.text
类型:str
解码类型:requests模块自动根据http头部对响应的编码做出有根据的推测,推测文本编码。
我们可以手动设定编码格式
demo3.py
import requests
#目标url
url = 'http://www.baidu.com'
# 向url发送get请求
response = requests.get(url)
response.encoding='utf-8'
# 打印响应内容
print(response.text)
- response.content
类型:bytes
解码类型:没有设定。可以自行进行设定。
知识点:掌握利用decode函数对requests.content解决中文乱码
1.4 通过对response.content进行decode,来解决中文乱码
- response.content.decode() 默认utf-8
- response.content.decode(‘GBK’)
- 常见的字符集编码
utf-8
gbk
gb2312
ascill(读音:阿斯克码)
iso-8859-1
知识点:掌握利用decode函数对requests.content解决中文乱码
1.5 response响应对象的其他常用的属性和方法
response = requests.get(url)中response是发送请求获取的响应对象;response响应对象中除了text,content获取响应内容以外还有其他常用的属性或方法。
- response.url 响应的URL,有时候响应的URL和请求的URL并不样。
- response.status_code 响应状态码
- response.headers 响应头
- response.request.headers 响应头对应的请求头
- response.request._cookies 响应对应请求的cookies,返回cookieJar类型
- response.cookies 响应的cookie(经过了set-cookie动作)返回cookieJar类型
- response.json() 自动将json字符串类型的响应内容转换为Python对象(dict or list)
demo4.py
import requests
#目标url
url = 'http://www.baidu.com'
# 向url发送get请求
response = requests.get(url)
response.encoding='utf-8'
print(response.url)
print(response.status_code)
print(response.request.headers)
print(response.headers)
print(response.request._cookies)
print(response.cookies)
知识点:掌握response响应对象的其他常用属性
二、requests模块发送请求
2.1 发送带headers的请求
我们先写一个获取百度首页的代码
demo5.py
import requests
#目标url
url = 'http://www.baidu.com'
# 向url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.content.decode())
# 打印对应请求头信息
print(response.request.headers)
2.1.1思考
1、对比浏览器上百度网页的源码和代码中百度首页的源码,看看有什么不同?
查看网页源代码的方法:
- 右键-查看网页源代码
- 右键-检查
2、对比url响应内容和代码中的百度首页的源码,有什么不同?
-
查看对应url响应内容的方法:
-
右键-检查
-
点击network
-
勾选Preserve log
-
刷新页面
-
查看Name栏下和浏览器地址栏相同的URL的response
3、代码中的百度首页的源码非常少,为什么?
需要带上请求头信息
回顾爬虫的概念,模拟浏览器,欺骗服务器,获取和浏览器一致的内容
请求头中有很多字段,其中User-Agent字段必不可少,表示客户端的操作系统以及浏览器的信息
2.1.2 携带请求头发送请求的方法
requests.get(url, headers)
- headers 参数接收字典形式的请求头
- 请求头字段名为key,字段对应的操作为value
demo6.py
import requests
#目标url
url = 'http://www.baidu.com'
# 构造请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36"}
# 向url发送get请求
response = requests.get(url, headers=headers)
# 打印响应内容
print(response.content.decode())
# 打印对应请求头信息
print(response.request.headers)
2.2 发送带参数的请求
我们在使用百度的时候经常发现URL地址中会有一个==?==,那么该问号后面的就是请求参数,又叫做查询字符串。
2.2.1 在url携带参数
直接对含有参数的url发送请求
demo7.py
import requests
#目标url
url = 'https://www.baidu.com/s?wd=Python'
# 构造请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36"}
# 向url发送get请求
response = requests.get(url, headers=headers)
with open('baidu.html', 'wb') as f:
f.write(response.content)
2.2.2 通过params携带参数字典
- 构建请求参数字典
- 向接口发送请求时带上参数字典,设置字典参数params。
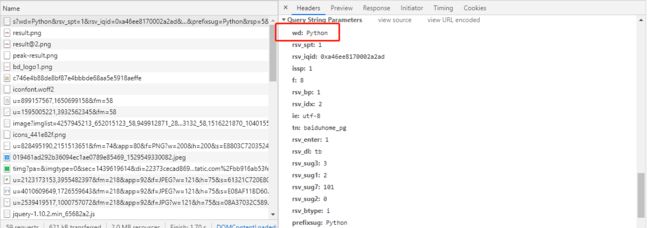
demo8.py
import requests
#目标url
url = 'https://www.baidu.com/s?'
# 请求参数是一个字典,即wd=Python
kw = {
'wd': 'python'}
# 构造请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36"}
# 向url发送get请求
response = requests.get(url, headers=headers, params=kw)
with open('baidu1.html', 'wb') as f:
f.write(response.content)
知识点:掌握发送带参数的请求方法
2.3 在headers参数中携带cookie
网站经常利用请求头中的Cookie字段来做用户状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求,我们以github为例。
2.3.1 github登录抓包分析
- 打开浏览器,右键-检查,点击network,勾选Preserve log
- 访问github登录的url地址:https://github.com/login
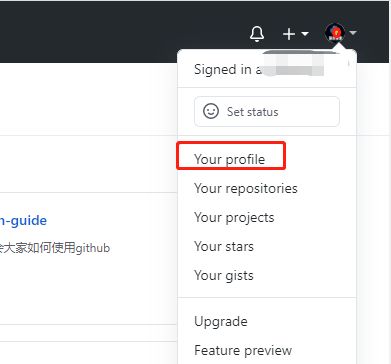
- 输入账号密码,点击登录后,访问一个需要登录后才能获取正确内容的URL。比如点击右上角的Your profle访问https://github.com/USER_NAME
- 确定URL后,再确定发送该请求所需要的请求头中的User-Agent和cookie
3.3.2 完成代码
- 从浏览器中复制User-Agent和cookie
- 浏览器中的请求头字段和值与headers参数中必须一致
- headers请求参数字典中的cookie键对应的值是字符串
demo9.py
import requests
headers = {
'Cookie': '你的cookie'
}
url = 'https://github.com/Zhimin7'
response = requests.get(url, headers=headers)
with open('github_withcookie.html', 'wb') as f:
f.write(response.content)

接下来写一个不包含cookie的爬虫,看看对比后的结果
demo10.py
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
url = 'https://github.com/Zhimin7'
response = requests.get(url, headers=headers)
with open('github_without_cookie.html', 'wb') as f:
f.write(response.content)

不同之处就相当明显了。
2.4 cookie参数的使用
上一个小节中我们在headers参数中携带cookie,也可以使用专门的cookie参数
1.cookie参数的形式:字典
cookies = {‘cookie的name’ : ‘cookie的value’}
- 该字典对应请求头中cookie的字符串
- 等号左边对应cookie的key
- 等号右边对应cookie的value
2.cookies参数的使用方法
response = requests.get(url, cookies)
3.将cookie字符串转换为cookies参数所需要的字典
cookie_dict = {cookie.split('=')[0] : cookie.split('=')[-1] for cookie in temp.split(';')}
当然,如果你的字典生成式学的不够熟悉的话,那你可以使用较为稳妥方法
demo11.py
temp = 'octo=GH1.1.1102395001.1582362358; _ga=GA1.2.454155278.1582362359; _device_id=0442b4dd494cafc0301c2ad3e9eeca31; experiment:homepage_signup_flow=eyJ2ZXJzaW9uIjoiMSIsInJvbGxPdXRQbGFjZW1lbnQiOjI1LjY3MjIzNTIyOTQ0MTk1Miwic3ViZ3JvdXAiOiJjb250cm9sIiwiY3JlYXRlZEF0IjoiMjAyMC0wMy0yNlQxNDozNToxNC45ODdaIiwidXBkYXRlZEF0IjoiMjAyMC0wMy0yNlQxNDozNToxNC45ODdaIn0=; user_session=vsC4WPrJRjDLSTC3Up0h0D5i0Knfyah9hGXzhfrchfW_5eyc; __Host-user_session_same_site=vsC4WPrJRjDLSTC3Up0h0D5i0Knfyah9hGXzhfrchfW_5eyc; logged_in=yes; dotcom_user=Zhimin7; has_recent_activity=1; tz=Asia%2FShanghai; _gh_sess=e9HSDZpXyMNlwvsRH7kjV39DisarWcGKdXqnr65Z3VfFlChN0onUNHwROBPqX2yfS9WudAE71IQF2h7TRiVQ3rvVp1KbvbmfOOkULatFZsHoVRi5UUCI%2FY8wz0QVBLXF3VY0WgLwoUoZhaJ5MhPG%2F22am%2Bowt2XigTISZm289i%2BCYxkDvWz8N7J61WTPz9i3--3YPo3PUW%2B3asHJSS--AmjAHcbcaKfU%2BneNyzA13w%3D%3D'
cookie_list = temp.split(';')
cookies = {
}
for cookie in cookie_list:
cookies[cookie.split('=')[0]] = cookie.split('=')[-1]
print(cookies)
2.5 cookiejar对象转换为cookies字典的方法
使用request获取的Response对象,具有cookie属性。该属性值是一个cookieJar类型,包含了对方服务器设置在本地的cookie。我们如何将其转换为cookie字典呢?
1.转换方法
cookie_dict = requests.utils.dict_from_cookieJar(response.cookies)
2.其中response.cookies返回的就是cookieJar类型的对象。
3.requests.utils.dict_from_cookieJar函数返回cookie字典。
demo12.py
from requests import utils
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
print(type(response.cookies))
print(response.cookies)
# 将cookieJar转换为dict
dict_cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(dict_cookies)
# 将dict转换为cookieJar
jar_cookies = requests.utils.cookiejar_from_dict(dict_cookies)
print(jar_cookies)
不过这种方法会造成域名缺失,不是很常用。在接下来的章节中会具体说明如何使用cookie保存会话。
2.6 超时timeout的使用
在平时上网的过程中,我们经常会遇到网络波动,这个时候,一个请求等待了很久的时间仍然没有结果。
在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就会报错。
1.超时参数timeout的使用方法
reponse = requests.get(url, timeout=3)
*timeout=3,表示3秒内程序访问服务器仍然没有响应,程序就会终止运行并报错
2.7 代理proxies的使用
2.7.1 理解使用代理的过程
1.代理IP是一个IP,指向的是一个代理服务器
2.代理服务器能够帮我们向目标服务器发起请求
代理服务器的意思是在浏览器与服务器之间搭建一个桥梁,相当于用Python向代理服务器发起请求,在通过代理服务器向服务器发起请求。服务器返回响应也是如此,服务器将响应返回给代理服务器,代理服务器再将响应返回给浏览器。
2.7.2正向代理和反向代理
前面提到proxy参数指定的代理IP指向的是正向代理服务器,那么相应的就有反向代理服务器;现在来了解一下正向代理服务器和反向代理服务器的区别
- 从发送请求一方的角度,来区分正向和反向代理
- 为浏览器或客户端(发送请求的一方)转发请求的,叫做正向代理,如VPN
- 不为浏览器或客户端(发送请求的一方)转发请求,而是为最终处理请求的服务器转发请求的,叫做反向代理,浏览器不知道服务器的真实IP地址,如NGINX
2.7.3 代理IP(代理服务器)的分类
- 透明代理:透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以直接看到你是谁。
- 匿名代理:使用匿名代理,别人只能知道你用了代理,无法知道你是谁。
- 高匿代理:高匿代理让别人不知道你使用了代理,所以最好的选择,毫无疑问使用高匿代理效果最好。
根据网站所使用的协议不同,需要使用相应协议的代理服务。从代理服务器请求的协议可以分为:
- http代理:目标url为http协议
- https代理:目标urlhttps协议
2.7.4 proxies代理参数的使用
为了让服务器以为是不同客户端发送的请求,防止频繁向同一个域名发送请求被封IP,所以我们要使用代理IP。
response = requests.get(url, proxies=proxies)
proxies的形式:字典
proxies = {
'http':'http://12.32.56.78:8000',
'https':'https://12.32.56.78:8000'
}
注意:如果proxies字典中含有多个键值对,发送请求的时候将按照url地址的协议来选择使用相应的代理IP。
2.8 使用verify参数忽略CA正数
在使用浏览器上网的时候,有时会看到,【您的链接不是私密连接】
- 原因:该网站的CA证书没有经过【受信任的证书颁发机构】的认证
所以作为爬虫,我们需要避免这种情况的发生,必须无视这个信息。
import requests
url = '' # 填写没有认证的URL
response = requests.get(url, verify=False)
三、 requests模块发送post请求
思考哪些地方会用到POST请求
- 注册登录
- 需要传输文本内容
所以同样我们爬虫也需要在这两个方面模拟浏览器发送post请求
3.1 requests发送post请求的方法
- response = requests.post(url, data=data)
- data参数接收一个字典
- response模块发送post请求函数和发送get请求的方法是一样的
四、利用requests.session进行状态保持
requests模块中的session类能够自动的处理发送请求获取响应的过程中产生cookie,进而达到状态保持的目的
4.1 requests.session的作用及应用场景
- requests.session的作用
自动处理cookie,即下一次请求会自动带上前一次的cookie
- requests.session的应用场景
自动处理连续请求多次请求过程产生的cookie
4.2 requests.session的使用方法
session示例在请求一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再用session请求网站的时候,会带上前一次的cookie
session = requests.session() #实例化session对象
response = session.get(url, headers, ...)
response = session.post(url, data, ...)
- session发送get请求和post请求的参数,与requests模块发送请求的参数完全一致
4.3 实例:模拟登录github
github_sesseion.py
import requests
from lxml import etree
class GitHub(object):
def __init__(self):
self.session = requests.session()
self.session.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
self.login_url = 'https://github.com/login'
def login(self):
response = self.session.get(self.login_url)
html = etree.HTML(response.content.decode())
return html
def get_token(self):
authenticity_token = self.login().xpath('//form/input[1]/@value')[0]
return authenticity_token
def get_timestamp_secret(self):
timestamp_secret = self.login().xpath('//div[@class="auth-form-body mt-3"]/input[11]/@value')[0]
return timestamp_secret
def get_timestamp(self):
timestamp = self.login().xpath('//div[@class="auth-form-body mt-3"]/input[10]/@value')[0]
return timestamp
def get_profile(self):
url_session = 'https://github.com/session'
url_profile = 'https://github.com/Zhimin7'
data = {
'commit': 'Sign in',
'authenticity_token': self.get_token(),
'ga_id':'',
'login': '你的邮箱',
'password': '你的密码',
'webauthn - support': 'supported',
'webauthn - iuvpaa - support': 'supported',
'return_to':'',
'allow_signup':'',
'client_id':''
'integration:',
'required_field_86b0':'',
'timestamp': self.get_timestamp(),
'timestamp_secret': self.get_timestamp_secret()
}
self.session.post(url_session, data=data)
html = self.session.get(url_profile).content
with open('github.html', 'wb') as f:
f.write(html)
print('获取完毕')
if __name__ == "__main__":
github = GitHub()
github.get_token()
github.get_timestamp()
github.get_timestamp_secret()
github.get_profile()
精彩链接
Python爬虫:什么是Python爬虫?怎么样玩爬虫?
最后
如果你读到了这里,那么说明我的这篇文章内容还是不错的,也希望你能给我一键三连(点赞、关注、留言)。毕竟码了这么多字我也是花费了不少的心力的,你的鼓励就是我创作的最大动力。
路漫漫其修远兮,吾将上下而求索
我是啃书君,一个专注于学习的的人,关注我,更多精彩内容我们下期再见!
respect