sparkSQL sparkSQL之DataFrame和DataSet
sparkSQL之DataFrame
- DataFrame
-
- DataFrame发展
- DataFrame是什么
-
- DataFrame的优点
- DataFrame和RDD的优缺点
-
- RDD
- DataFrame
- 读取文件构建DataFrame
-
-
- 读取文本文件创建DataFrame
- 读取json文件创建DataFrame
- 读取parquet文件创建DataFrame
-
- DataFrame常用操作
-
- DSL风格语法
- SQL风格语法
- DataSet
-
- 构建DataSet
- RDD、DataFrame和DataSet的区别
- 该什么时候使用 DataFrame 或 Dataset 呢?
- 总结
DataFrame
DataFrame发展
- DataFrame前身是schemaRDD,schemaRDD直接继承RDD,是RDD的一个实现类
- 在spark1.3.0之后把schemaRDD改名为DataFrame,它不在继承自RDD,而是自己实现RDD上的一些功能(如 map filter flatmap等等)
- 可以把dataFrame转换成一个rdd,调用如下的rdd方法
val rdd1=dataFrame.rdd
DataFrame是什么
可以简单的把DataFrame理解成RDD+schema元信息
DataFrame有如下特征:
- 在spark中,DataFrame是一种以RDD为基础的分布式数据集,类似传统数据库的二维表格
- DataFrame带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称(如下图的 name age height)和类型(如下图的 string int double),但底层做了更多优化
- DataFrame可以从很多数据源构建对象
- 如,已经存在的RDD、结构化文件、外部数据库、Hive表。
- RDD可以把它的内部元素看成是一个java对象
- DataFrame内部是一个个Row对象,它表示一行一行的数据
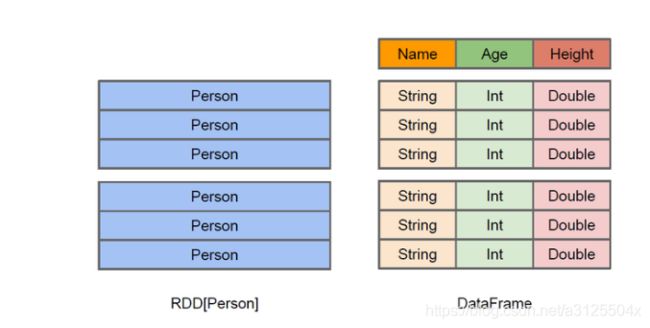
上图直观地体现了DataFrame和RDD的区别。
- 左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。
- 而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。
DataFrame的优点
DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等
- 提升执行效率
RDD API是函数式的,强调不变性,在大部分场景下倾向于创建新对象而不是修改老对象。这一特点虽然带来了干净整洁的API,却也使得Spark应用程序在运行期倾向于创建大量临时对象,对GC造成压力。在现有RDD API的基础之上,我们固然可以利用mapPartitions方法来重载RDD单个分片内的数据创建方式,用复用可变对象的方式来减小对象分配和GC的开销,但这牺牲了代码的可读性,而且要求开发者对Spark运行时机制有一定的了解,门槛较高。另一方面,Spark SQL在框架内部已经在各种可能的情况下尽量重用对象,这样做虽然在内部会打破了不变性,但在将数据返回给用户时,还会重新转为不可变数据。利用 DataFrame API进行开发,可以免费地享受到这些优化效果。
- 减少数据读取
分析大数据,最快的方法就是 ——忽略它。这里的“忽略”并不是熟视无睹,而是根据查询条件进行恰当的剪枝。
上文讨论分区表时提到的分区剪 枝便是其中一种——当查询的过滤条件中涉及到分区列时,我们可以根据查询条件剪掉肯定不包含目标数据的分区目录,从而减少IO。
对于一些“智能”数据格 式,Spark SQL还可以根据数据文件中附带的统计信息来进行剪枝。简单来说,在这类数据格式中,数据是分段保存的,每段数据都带有最大值、最小值、null值数量等 一些基本的统计信息。当统计信息表名某一数据段肯定不包括符合查询条件的目标数据时,该数据段就可以直接跳过(例如某整数列a某段的最大值为100,而查询条件要求a > 200)。
此外,Spark SQL也可以充分利用RCFile、ORC、Parquet等列式存储格式的优势,仅扫描查询真正涉及的列,忽略其余列的数据。
- 执行优化

人口数据分析示例
为了说明查询优化,我们来看上图展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
得到的优化执行计划在转换成物 理执行计划的过程中,还可以根据具体的数据源的特性将过滤条件下推至数据源内。最右侧的物理执行计划中Filter之所以消失不见,就是因为溶入了用于执行最终的读取操作的表扫描节点内。
对于普通开发者而言,查询优化 器的意义在于,即便是经验并不丰富的程序员写出的次优的查询,也可以被尽量转换为高效的形式予以执行。
DataFrame和RDD的优缺点
DataFrame和RDD的优缺点对比主要是由DataFrame引入了schema元信息和off-heap带来的
RDD
- RDD优点
- 编译时类型安全:编译时会对类型进行检查,及时发现错误
- 具有面对对象编程的风格
- RDD缺点
- 构建大量java对象占用了大量heap堆空间,导致频繁的GC(RDD[java对象])
由于数据集RDD它的数据量比较大,后期都需要存储在heap堆中,这里有heap堆中的内存空间有限, 出现频繁的垃圾回收(GC),程序在进行垃圾回收的过程中,所有的任务都是暂停。影响程序执行的效率
- 构建大量java对象占用了大量heap堆空间,导致频繁的GC(RDD[java对象])
- 数据的序列和反序列化性能开销很大
在分布式程序中,对象(对象的内容和结构)是先进行序列化,发送到其他服务器,进行大量的网络传输, 然后接受到这些序列化的数据之后,再进行反序列化来恢复该对象
DataFrame
DataFrame引入了schema元信息和off-heap,同时为其带来了相应的优点和缺点。
-
DataFrame优点
- DataFrame引入off-heap的好处:
- 大量的对象构建直接使用操作系统层面上的内存,不在使用heap堆中的内存,这样一来heap堆中的内存空间就比较充足,不会导致频繁GC,程序的运行效率比较高,它是解决了RDD构建大量的java对象占用了大量heap堆空间,导致频繁的GC这个缺点
- DataFrame引入了schema元信息(就是数据结构的描述信息)的好处:
- 后期spark程序中的大量对象在进行网络传输的时候,只需要把数据的内容本身进行序列化就可以,数据结构信息可以省略掉。这样一来数据网络传输的数据量是有所减少,数据的序列化和反序列性能开销就不是很大了。它是解决了RDD数据的序列化和反序列性能开销很大这个缺点
- DataFrame引入off-heap的好处:
-
DataFrame缺点
- 编译时类型不安全,只有运行时才会报错
//只有在运行时才报错 case class Person(name : String , age : Int) val dataframe = sqlContect.read.json("people.json") dataframe.filter("salary > 10000").show => throws Exception : cannot resolve 'salary' given input age , name - 不再具有面向对象的编程风格
- 编译时类型不安全,只有运行时才会报错
读取文件构建DataFrame
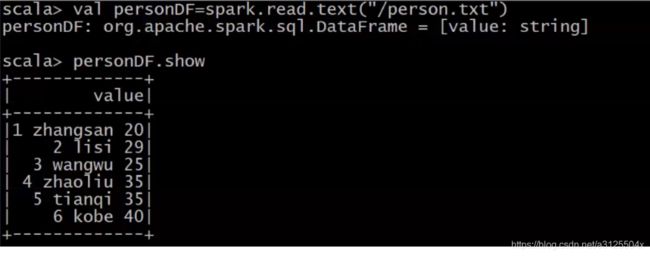
读取文本文件创建DataFrame
- 第一种方式
val personDF=spark.read.text("/person.txt")
//org.apache.spark.sql.DataFrame = [value: string]
//打印schema信息
personDF.printSchema
//展示数据
personDF.show
- 第二种方式
//加载数据
val rdd1=sc.textFile("/person.txt").map(x=>x.split(" "))
//定义一个样例类
case class Person(id:String,name:String,age:Int)
//把rdd与样例类进行关联
val personRDD=rdd1.map(x=>Person(x(0),x(1),x(2).toInt))
//把rdd转换成DataFrame
val personDF=personRDD.toDF
//打印schema信息
personDF.printSchema
//展示数据
personDF.show
示例
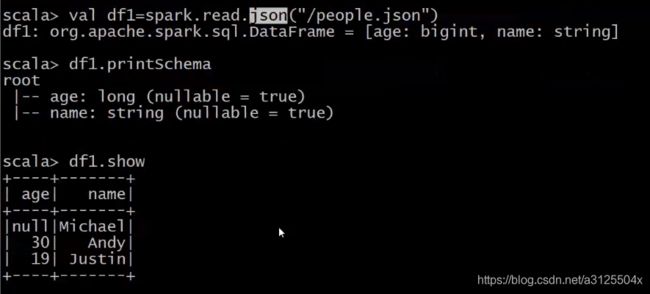
读取json文件创建DataFrame
val peopleDF=spark.read.json("/people.json")
//打印schema信息
peopleDF.printSchema
//展示数据
peopleDF.show
示例

读取parquet文件创建DataFrame
val usersDF=spark.read.parquet("/users.parquet")
//打印schema信息
usersDF.printSchema
//展示数据
usersDF.show
示例

DataFrame常用操作
从读取DataFrame对象的数据时
- 通过DSL风格从ROW对象通过对应函数获得相应的数据
- 通过字段名获得数据
- 通过索引值获得数据(从0开始)
- 通过SQL风格,直接写SQL语句即可
DSL风格语法
//加载数据
val rdd1=sc.textFile("/person.txt").map(x=>x.split(" "))
//定义一个样例类
case class Person(id:String,name:String,age:Int)
//把rdd与样例类进行关联
val personRDD=rdd1.map(x=>Person(x(0),x(1),x(2).toInt))
//把rdd转换成DataFrame
val personDF=personRDD.toDF
//打印schema信息
personDF.printSchema
//展示数据
personDF.show
//查询指定的字段 获取指定列
personDF.select("name").show
personDF.select($"name").show
personDF.select(col("name").show
//实现age+1 $ 转义
personDF.select($"name",$"age",$"age"+1)).show
// & 都加或者都不加,只加一个报错
//personDF.select($"name",$"age",).show
//实现age大于30过滤
personDF.filter($"age" > 30).show
//按照age分组统计次数
personDF.groupBy("age").count.show
//按照age分组统计次数降序
personDF.groupBy("age").count().sort($"count".desc)show
//使用foreach获取每一个row对象中的name字段 可以通过字段名称获取 也可以通过下标获取
personDF.foreach(row =>println(row.getAs[String]("name")))
personDF.foreach(row =>println(row.get(1)))
personDF.foreach(row =>println(row.getString(1)))
personDF.foreach(row =>println(row.getAs[String](1)))
SQL风格语法
//DataFrame注册成表
personDF.createTempView("person")
//使用SparkSession调用sql方法统计查询
spark.sql("select * from person").show
spark.sql("select name from person").show
spark.sql("select name,age from person").show
spark.sql("select * from person where age >30").show
spark.sql("select count(*) from person where age >30").show
spark.sql("select age,count(*) from person group by age").show
spark.sql("select age,count(*) as count from person group by age").show
spark.sql("select * from person order by age desc").show
DataSet
- DataSet是分布式的数据集合,DataSet提供了强类型支持,在RDD的每行数据加了类型约束
- Datset是在spark1.6中新添加的接口。它集中了RDD的优点(强类型和可以使用强大的lambda函数)以及使用了sparkSQL优化的执行引擎。
构建DataSet
- 通过sparkSession调用createDataSet方法
val ds=spark.createDataset(1 to 10) //scala集合
val ds=spark.createDataset(sc.textFile("/person.txt")) //rdd
- 使用scala集合和RDD调用toDS方法
sc.textFile("/person.txt").toDS
List(1,2,3,4,5).toDS
- 把一个DataFrame转换成DataSet
val dataSet=dataFrame.as[强类型]
- 通过一个DataSet转换生成一个新的DataSet
List(1,2,3,4,5).toDS.map(x=>x*10)
RDD、DataFrame和DataSet的区别
从DataFrame源码可以看出,DataFrame(在2.X之后)实际上是DataSet的一个特例,即对Dataset的元素为Row时起了一个别名
type DataFrame = Dataset[Row]
/**
* @since 1.3.0
*/
@InterfaceStability.Stable
object Row
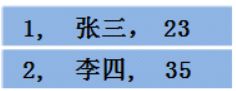
RDD
- 设RDD的两行数据如下
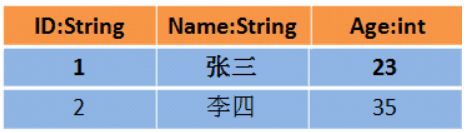
DataFrame
- 对应的DataFrame可能如下
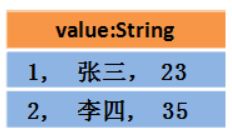
DataSet
- 对应的DataSet可能如下
- 当行元素是ROW时,是DataFrame(同时也是DataSet)
- 当行元素是String对象时是DataSet,不是DataFrame
- 对应的DataSet可能如下(每行数据是People这个Object)

该什么时候使用 DataFrame 或 Dataset 呢?
- 如果你需要丰富的语义、高级抽象和特定领域专用的 API,那就使用 DataFrame 或 Dataset;
- 如果你的处理需要对半结构化数据进行高级处理,如 filter、map、aggregation、average、sum、SQL - 查询、列式访问或使用 lambda 函数,那就使用 DataFrame 或 Dataset;
- 如果你想在编译时就有高度的类型安全,想要有类型的 JVM 对象,用上 Catalyst 优化,并得益于 Tungsten 生成的高效代码,那就使用 Dataset;
- 如果你想在不同的 Spark 库之间使用一致和简化的 API,那就使用 DataFrame 或 Dataset;
- 如果你是 R 语言使用者,就用 DataFrame;
- 如果你是 Python 语言使用者,就用 DataFrame,在需要更细致的控制时就退回去使用 RDD;
此段引用自此链接
总结
总之,在什么时候该选用RDD、DataFrame 或Dataset 看起来好像挺明显。前者可以提供底层的功能和控制,后者支持定制的视图和结构,可以提供高级和特定领域的操作,节约空间并快速运行。
当我们回顾从早期版本的Spark 中获得的经验教训时,我们问自己该如何为开发者简化Spark 呢?该如何优化它,让它性能更高呢?我们决定把底层的RDD API 进行高级抽象,成为DataFrame 和Dataset,用它们在Catalyst 优化器和Tungsten 之上构建跨库的一致数据抽象。
DataFrame 和 Dataset,或 RDD API,按你的实际需要和场景选一个来用吧,当你像大多数开发者一样对数据进行结构化或半结构化的处理时,我不会有丝毫惊讶。
此段引用自此链接