Selenium 根据输入的公司名称来爬取公司的详细信息
Selenium 根据输入的公司名称来爬取天眼查中的公司的详细信息
- 1、下载驱动并设置环境变量
-
- 1.1、查看你的浏览器的版本
- 1.2、下载对应版本的ChromeDriver驱动
- 1.3、设置环境变量
- 2、使用驱动打开谷歌浏览器
- 3、登录天眼查,输入账号密码
- 4、将爬取到的信息处理成一个dataframe,方便保存为csv文件
- 5、输入公司名,可爬取到该公司的详细信息(除非该公司不存在,否则都可以得到该公司的详细信息)
- ps:如果大家在driver.find_elements_by_xpath这里遇到点错误,可能是天眼查那边更新了网页代码,大家可以根据这个操作来更新代码。
- 本博客仅作学习教程,重在介绍如何使用selenium,不建议大家爬取数据量太大的公司名称及其详细信息。
1、下载驱动并设置环境变量
1.1、查看你的浏览器的版本
在网址栏输入:chrome://version
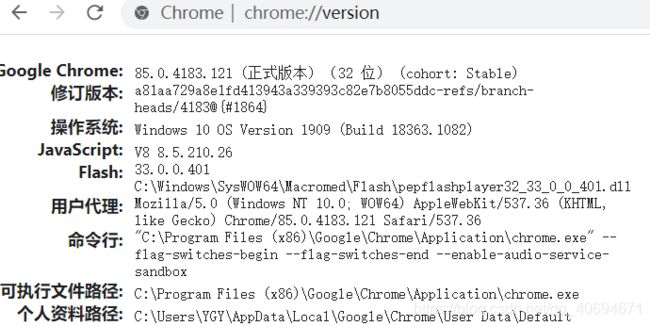
我的浏览器的版本是85.0.4183。
1.2、下载对应版本的ChromeDriver驱动
网址如下:http://chromedriver.storage.googleapis.com/index.html
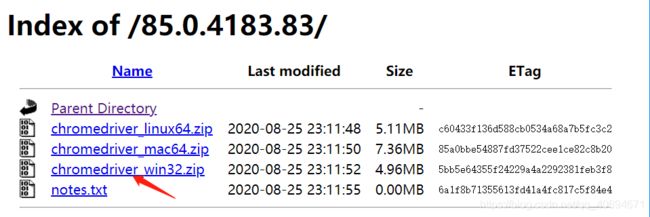
因为我的谷歌版本是85.0.4183,所以我下载的ChromeDriver驱动对应的也是85.0.4183版本的。
1.3、设置环境变量
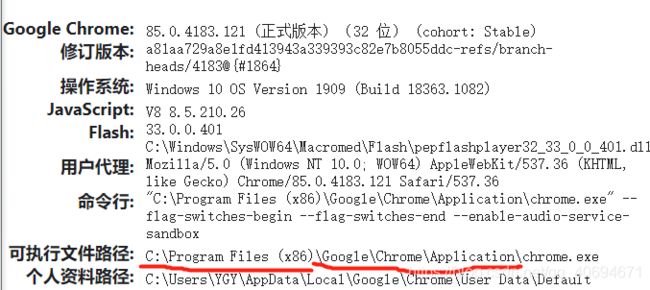
第一步:把下载好的zip压缩包解压,然后把里面的chromedriver.exe复制到谷歌浏览器的安装目录去。忘记谷歌浏览器的安装目录的人可以在1.1的图片那看可执行文件路径那里。
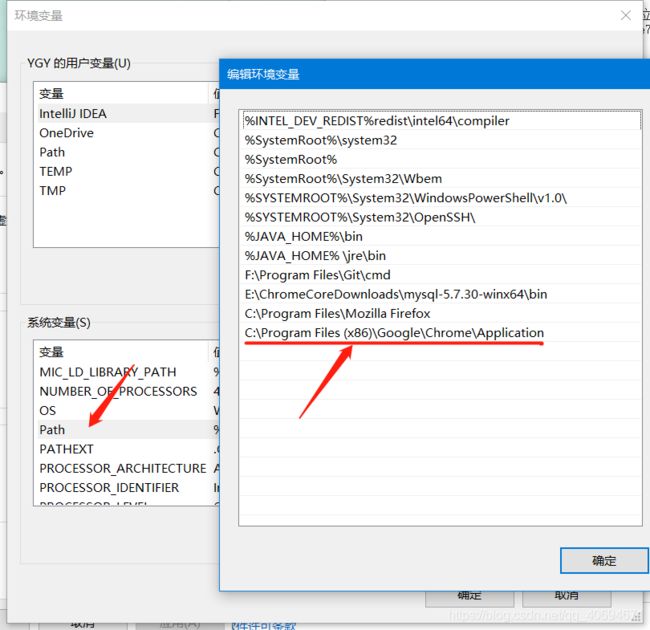
第二步:复制成功后,把这个目录复制一遍,添加到系统的环境变量里的path。
2、使用驱动打开谷歌浏览器
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#图像处理标准库
from PIL import Image
#鼠标操作
from selenium.webdriver.common.action_chains import ActionChains
#等待时间 产生随机数
import time,random
#创建浏览器对象
driver = webdriver.Chrome()
3、登录天眼查,输入账号密码
driver.get("https://www.tianyancha.com/")
time.sleep(3)
# 点击登录按钮
driver.find_elements_by_xpath('//a[@class="link-white"]')[0].click()
# 点击密码登录
time.sleep(1)
driver.find_elements_by_xpath('//div[@class="title-tab text-center"]')[0].click()
driver.find_elements_by_xpath('//div[@tyc-event-ch="LoginPage.PasswordLogin"]')[0].click()
time.sleep(2)
# 输入手机号
input1 = driver.find_element_by_name("phone")
input1.send_keys("手机号码") # 手机号码
time.sleep(2)
# 输入密码
input2 = driver.find_element_by_name("password")
input2.send_keys("密码") # 密码
# 点击登录按钮
driver.find_elements_by_xpath('//div[@class="btn -xl btn-primary -block"]')[0].click()
然后滑动验证自己划一下,反正只需要登录一次就行
4、将爬取到的信息处理成一个dataframe,方便保存为csv文件
import pandas as pd
def message_to_df(message,company):
registered_capital = []
contributed_capital = []
Date_of_Establishment = []
ManagementForms = []
Unified_social_credit_code = []
companyNo = []
Taxpayer_Identification_Number =[]
Organization_Code = []
company_type = []
industry = []
Approved_date = []
Registration_Authority = []
Business_Term = []
staff_size = []
Number_of_participants = []
former_name = []
Business_Scope = []
registered_capital.append(message.split('注册资本')[1].split('\n')[1])
contributed_capital.append(message.split('实缴资本')[1].split('\n')[0])
Date_of_Establishment.append(message.split('成立日期')[1].split('\n')[1])
ManagementForms.append(message.split('经营状态')[1].split('\n')[0])
Unified_social_credit_code.append(message.split('统一社会信用代码')[1].split('\n')[1].split(' ')[0])
companyNo.append(message.split('工商注册号')[1].split('\n')[0])
Taxpayer_Identification_Number.append(message.split('纳税人识别号')[1].split('\n')[1].split(' ')[0])
Organization_Code.append(message.split('组织机构代码')[1].split('\n')[1])
company_type.append(message.split('公司类型')[1].split(' ')[1])
industry.append(message.split('行业')[1].split('\n')[0])
Approved_date.append(message.split('核准日期')[1].split(' ')[1])
Registration_Authority.append(message.split('登记机关')[1].split('\n')[0])
Business_Term.append(message.split('营业期限')[1].split(' ')[1])
staff_size.append(message.split('人员规模')[1].split(' ')[1])
Number_of_participants.append(message.split('参保人数')[1].split('\n')[0])
former_name.append(message.split('曾用名')[1].split(' ')[1])
Business_Scope.append(message.split('经营范围')[1].split(' ')[1])
df = pd.DataFrame({'公司':company,\
'注册资本':registered_capital,\
'实缴资本':contributed_capital,\
'成立日期':Date_of_Establishment,\
'经营状态':ManagementForms,\
'统一社会信用代码':Unified_social_credit_code,\
'工商注册号':companyNo,\
'纳税人识别号':Taxpayer_Identification_Number,\
'组织机构代码':Organization_Code,\
'公司类型':company_type,\
'行业':industry,\
'核准日期':Approved_date,\
'登记机关':Registration_Authority,\
'营业期限':Business_Term,\
'人员规模':staff_size,\
'参保人数':Number_of_participants,\
'曾用名':former_name,\
'经营范围':Business_Scope})
return df
5、输入公司名,可爬取到该公司的详细信息(除非该公司不存在,否则都可以得到该公司的详细信息)
①更改该列表可得自己想要得到的公司的详细信息
companys = ['深圳市腾讯计算机系统有限公司','阿里巴巴(中国)有限公司']
②运行得到处理结果,然后将其存储在自定义的csv文件中。
def get_company_message(company):
driver.get("https://www.tianyancha.com/search?key={}".format(company))
# 进入相关公司的详情页面
href = driver.find_elements_by_xpath('//a[@tyc-event-ch="CompanySearch.Company"]')[0].get_attribute('href')
driver.get(href)
time.sleep(5)
message = driver.find_elements_by_xpath('//table[@class="table -striped-col -border-top-none -breakall"]')[0].text
return message
for company in companys:
try:
messages = get_company_message(company)
except:
pass
else:
df = message_to_df(messages,company)
if(company==companys[0]):
df.to_csv('自己目录的绝对路径/company.csv',index=False,header=True)
else:
df.to_csv('自己目录的绝对路径/company.csv',mode='a+',index=False,header=False)
time.sleep(3)
至此,就可以得到这两家公司的一些详细信息。
ps:如果大家在driver.find_elements_by_xpath这里遇到点错误,可能是天眼查那边更新了网页代码,大家可以根据这个操作来更新代码。
①按F12进入开发者调试页面
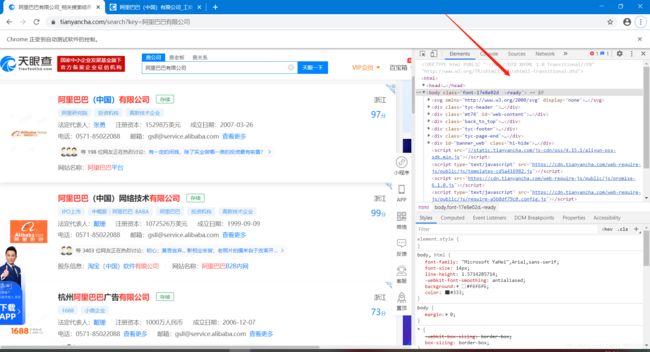
②就点击“阿里巴巴(中国)有限公司”这个点击操作而言,右击,然后选择“检查”选项,然后就可以看到开发者调试页面那里也自动跳转到了相关的位置。
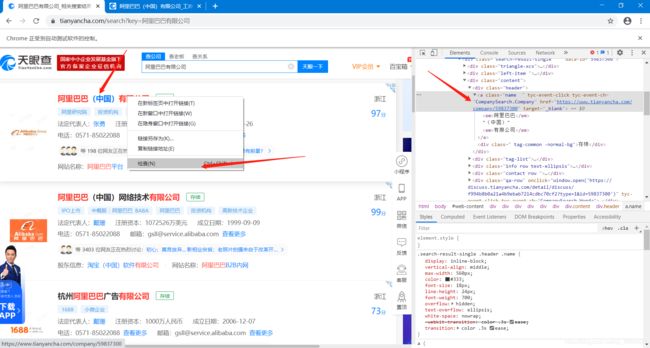
③在开发者调试页面那里继续双击,然后右击,在copy选项那里选择Copy XPath,就可以得到相关的Xpath了。比如我现在2020年10月份点的时候,是://*[@id=“web-content”]/div/div[1]/div[2]/div[2]/div[1]/div/div[3]/div[1]/a。
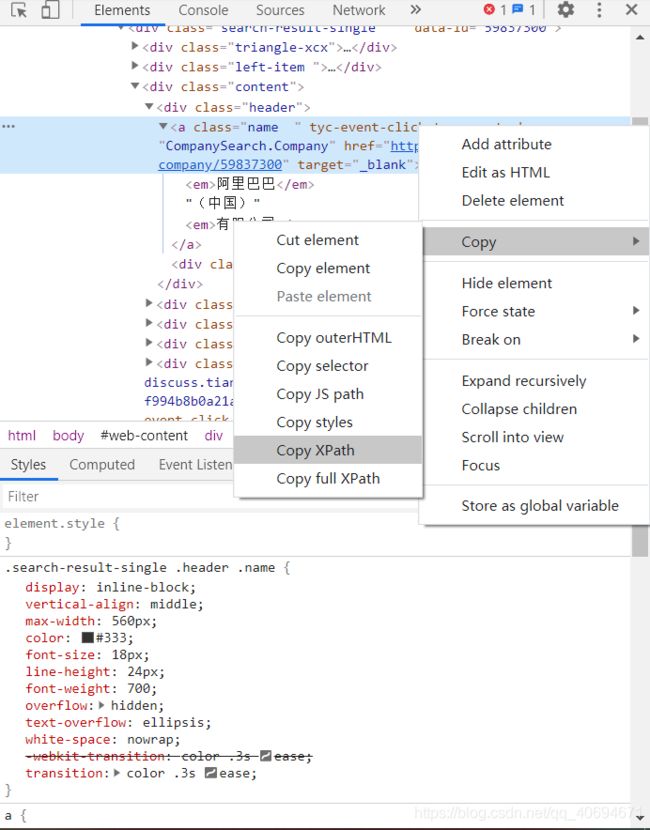
最后,大家需要注意的是,爬取的时候需要适当的设置一下睡眠时间,不然会被检测到是爬虫机器人在操作,可能会弹出弹窗让你验证,这样会导致爬取的信息不完整。第二个就是某个时间段爬取量尽量不要太大,不然也是会被检测到的,天眼查的小哥哥小姐姐防爬虫措施做得挺好的。
# 附上完整代码
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#图像处理标准库
from PIL import Image
#鼠标操作
from selenium.webdriver.common.action_chains import ActionChains
#等待时间 产生随机数
import time,random
#创建浏览器对象
driver = webdriver.Chrome()
driver.get("https://www.tianyancha.com/")
time.sleep(3)
# 点击登录按钮
driver.find_elements_by_xpath('//a[@class="link-white"]')[0].click()
# 点击密码登录
time.sleep(1)
driver.find_elements_by_xpath('//div[@class="title-tab text-center"]')[0].click()
driver.find_elements_by_xpath('//div[@tyc-event-ch="LoginPage.PasswordLogin"]')[0].click()
time.sleep(2)
# 输入手机号
input1 = driver.find_element_by_name("phone")
input1.send_keys("手机号码") # 手机号码
time.sleep(2)
# 输入密码
input2 = driver.find_element_by_name("password")
input2.send_keys("密码") # 密码
# 点击登录按钮
driver.find_elements_by_xpath('//div[@class="btn -xl btn-primary -block"]')[0].click()
import pandas as pd
def message_to_df(message,company):
registered_capital = []
contributed_capital = []
Date_of_Establishment = []
ManagementForms = []
Unified_social_credit_code = []
companyNo = []
Taxpayer_Identification_Number =[]
Organization_Code = []
company_type = []
industry = []
Approved_date = []
Registration_Authority = []
Business_Term = []
staff_size = []
Number_of_participants = []
former_name = []
Business_Scope = []
registered_capital.append(message.split('注册资本')[1].split('\n')[1])
contributed_capital.append(message.split('实缴资本')[1].split('\n')[0])
Date_of_Establishment.append(message.split('成立日期')[1].split('\n')[1])
ManagementForms.append(message.split('经营状态')[1].split('\n')[0])
Unified_social_credit_code.append(message.split('统一社会信用代码')[1].split('\n')[1].split(' ')[0])
companyNo.append(message.split('工商注册号')[1].split('\n')[0])
Taxpayer_Identification_Number.append(message.split('纳税人识别号')[1].split('\n')[1].split(' ')[0])
Organization_Code.append(message.split('组织机构代码')[1].split('\n')[1])
company_type.append(message.split('公司类型')[1].split(' ')[1])
industry.append(message.split('行业')[1].split('\n')[0])
Approved_date.append(message.split('核准日期')[1].split(' ')[1])
Registration_Authority.append(message.split('登记机关')[1].split('\n')[0])
Business_Term.append(message.split('营业期限')[1].split(' ')[1])
staff_size.append(message.split('人员规模')[1].split(' ')[1])
Number_of_participants.append(message.split('参保人数')[1].split('\n')[0])
former_name.append(message.split('曾用名')[1].split(' ')[1])
Business_Scope.append(message.split('经营范围')[1].split(' ')[1])
df = pd.DataFrame({'公司':company,\
'注册资本':registered_capital,\
'实缴资本':contributed_capital,\
'成立日期':Date_of_Establishment,\
'经营状态':ManagementForms,\
'统一社会信用代码':Unified_social_credit_code,\
'工商注册号':companyNo,\
'纳税人识别号':Taxpayer_Identification_Number,\
'组织机构代码':Organization_Code,\
'公司类型':company_type,\
'行业':industry,\
'核准日期':Approved_date,\
'登记机关':Registration_Authority,\
'营业期限':Business_Term,\
'人员规模':staff_size,\
'参保人数':Number_of_participants,\
'曾用名':former_name,\
'经营范围':Business_Scope})
return df
companys = ['深圳市腾讯计算机系统有限公司','阿里巴巴(中国)有限公司']
def get_company_message(company):
driver.get("https://www.tianyancha.com/search?key={}".format(company))
# 进入相关公司的详情页面
href = driver.find_elements_by_xpath('//a[@tyc-event-ch="CompanySearch.Company"]')[0].get_attribute('href')
driver.get(href)
time.sleep(5)
message = driver.find_elements_by_xpath('//table[@class="table -striped-col -border-top-none -breakall"]')[0].text
return message
for company in companys:
try:
messages = get_company_message(company)
except:
pass
else:
df = message_to_df(messages,company)
if(company==companys[0]):
df.to_csv('自己目录的绝对路径/company.csv',index=False,header=True)
else:
df.to_csv('自己目录的绝对路径/company.csv',mode='a+',index=False,header=False)
time.sleep(3)
注明:转载需注明原贴链接,利用代码进行非法行为与本人无关