吴恩达机器学习(降维)
目标一:数据压缩
这一章中将讨论第二种无监督学习的问题:降维。
数据压缩不仅能让我们对数据进行压缩,使得数据占用较少的内存和硬盘空间,还能对学习算法进行加速。
(1)二维降到一维:
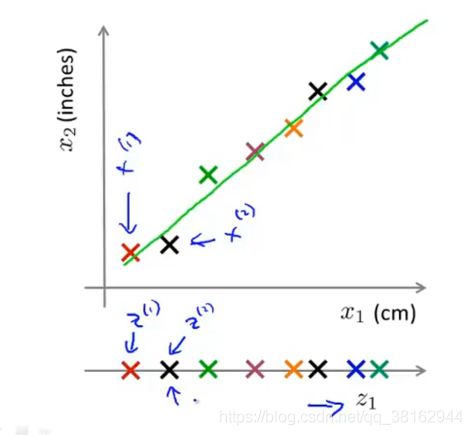
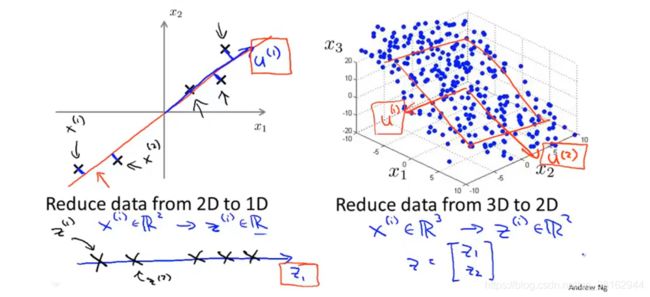
如果能把数据从二维减少到一维,用来减少这种冗余,通过降维,也就说想找出一条线,看起来大多数样本所在的线,所有的数据都投影到这条线上,通过这种做法,能够测量出每个样本在线上的位置。就可以建立新的特征,只需要一个数就能确定新特征。
意味着:之前要用一个二维数字表示的特征可以一维数直接表示。

通过这种方法,就能够把内存的需求减半或者数据空间需求减半。
(2)三维降到二维:
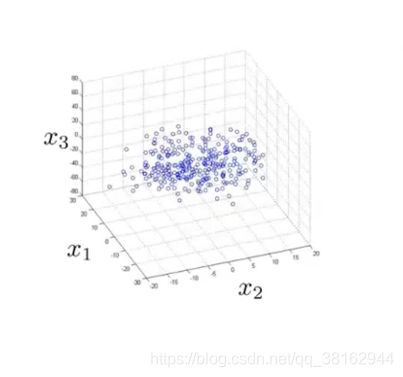
很难看出图中的数据分布在一个平面上,所以这时降维的方法就是把所有的数据都投影到一个二维平面上:
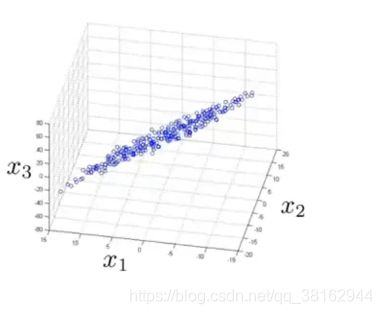
意味着现在可以把每个样本用两个数字表示出来,即下图中的z1、z2。
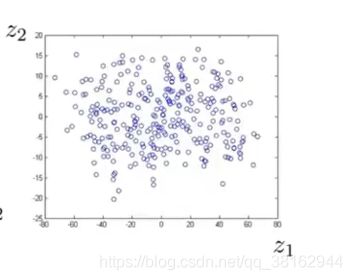
这就是降维以及如何用它来压缩数据,接下来将继续探讨如何用这个技术来对学习算法进行加速。
目标二:可视化数据
用一个具体的例子来说:
假设收集了许多统计数据的大数据集,如下图中的全世界各国的情况:
这里有很多的特征和国家,那么用什么方法能够更好地理解这些数据呢?如何可视化这些数据?
这里有50个特征,但是很难绘制50维的数据,可以用使用降维的方法
 例如用下面二维向量表示:
例如用下面二维向量表示:
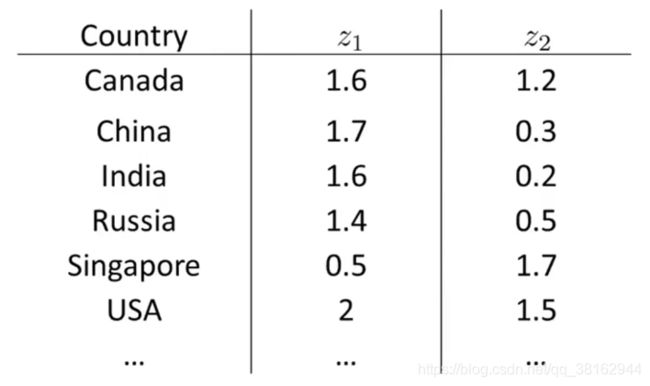
这样的话,如果能用2个数字来表示50个特征,要做是从50维降到2维,就可以把这些国家在二维平面上表示出来,这样做了之后,z的值通常不是你期望的具有物理意义的特征,所以要弄清楚这些特征意味着什么。
在图中,每一个国家都可以用一个点来表示,横轴可能表示国家的经济规模、国家总体经济活跃程度或者总GDP等一些特征,而纵轴可能对应于人均GDP、每个人的幸福程度或者个人经济活跃程度等一些特征,这样就可以通过这个图了解国家的大致情况。
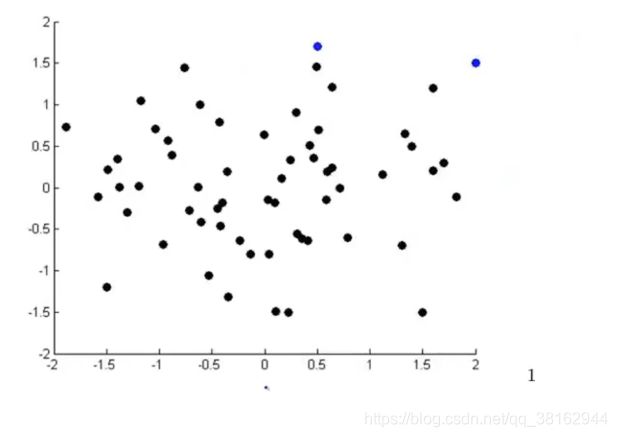
这就是降维如何把高维的数据降到二维或者三维,这样就能把它绘制出来,并更好地理解这些数据。
主成分分析(PCA)问题规划
对降维问题来说,目前最流行的的算法是叫做主成分分析法(PCA),这一节中将谈论PCA的公式描述问题。
假设有如图的数据集,想要将它从二维降到一维,可能会选择图中的线:
通过选择的这条线,发现每个点到它们对应的直线上的投影点之间的距离是非常小的。所以,正式的说,PCA它会找一个低维平面(上图中是这条直线)然后将数据投影在上面,使点到投影点之间的距离的平方最小。(这些距离有时也称为投影误差)
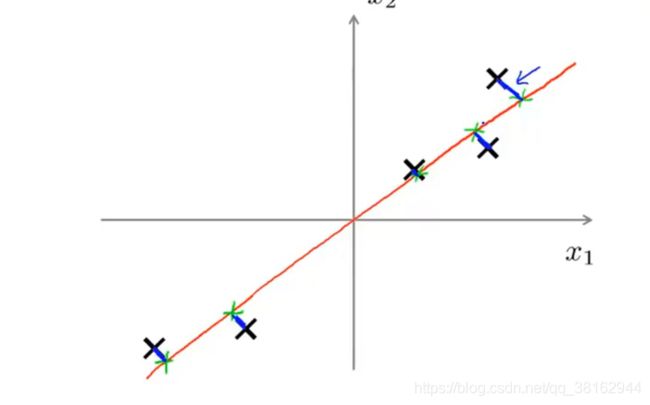
在应用PCA之前,常规的做法是先进行均值归一化和特征规范化,使得特征x1、x2的均值为0,并且其数值在可比较的范围内。
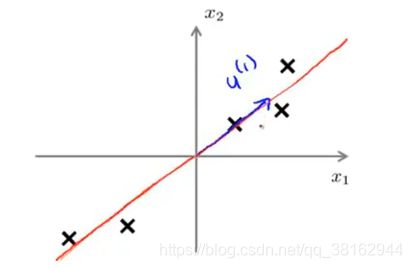
PCA问题的正式定义:PCA做的就是如果想将数据从二维降到一维,要试着找一个向量(假设是向量![]() )投影后能够使最小化投影误差的方向。
)投影后能够使最小化投影误差的方向。
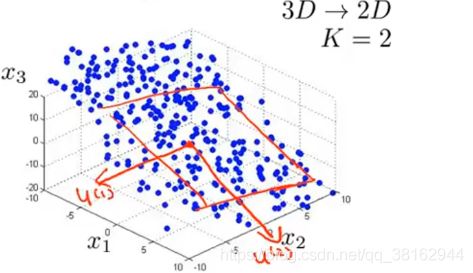
通常的情况是有N维数据,并且想将其降到K维,这时并不是找单个向量来对数据进行投影,而是想寻找K个方向来对数据进行投影,来最小化投影误差。正式的来说:要找出一组向量,要做的是将这些数据投影到这K个向量展开的线性子空间上。举个例子,如果有下图所示的三维点云:

那么也就是要找出一对向量,这两个向量一起定义了一个二维平面,将数据投影到平面上,并且要求数据点投影到平面上的距离最小。
因此,PCA做的是它试图找出一条直线、一个平面或其他维的空间,然后对数据进行投影,以最小化平方投影、90度投影或正交投影的误差。
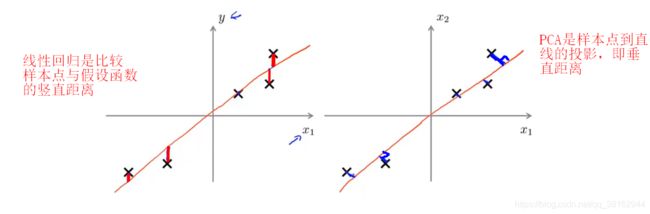
PCA和线性回归的关系如何?
因为讲述PCA的时候经常会画一条直线,看起来有点像线性回归,但事实上PCA不是线性回归,它们是两种不同的算法。线性回归要做的是用所以的x值来预测y,然而在PCA中,没有什么特殊的变量y是需要预测的。
接下来,将主要讨论主成分分析算法。
在应用PCA之前首先是对数据的预处理:执行均值标准化(可能根据数据也要进行特征缩放)
 做完这一系列的数据预处理之后,接下来是PCA算法需要做的:
做完这一系列的数据预处理之后,接下来是PCA算法需要做的:
左边的图:PCA要做的是需要想出一个方法计算两个东西,一个是计算这些向量u^(1),
例如,另一个是如何计算这些数字z。
右边的图:PCA要做的是需要想出一个方法计算两个东西,一个是计算这种情况下的向量u^(1),u(2),另一个是计算这些向量z。
下面是求解过程:
想把n维数据降到k维,首先要做的是计算协方差,然后计算协方差矩阵的特征向量,最终得到的是一个n*n的矩阵U:



这就是PCA算法,虽然没有给出数学上的证明,来证明u(1)、u(2)、z还有其他向量等等,但是得出的过程就是选择了最小化的平方投影误差,PCA要做的是尝试找到一个面或线,把数据投影到这个面或线上,以便于最小化平方投影误差。
主成分数量k选择
在PCA算法中,将n维特征减少为某k维特征表示,这个数字k是PCA算法的一个参数,也被称为主成分个数。这里将探讨一般情况下如何考虑选择这个参数k。
为了选择k,即选择这个主成分的数字,PCA努力做到就是最小化投影误差平方的平均值,因此它试图最小化这个数量,它是原始数据和投影之间的距离,这就是投影误差平方的平均值,同时将定义数据的总方差,就是这些样本的平方和的平均值,所以数据的总方差就是训练集里的所有样本的平均长度,这个说明了我的训练样本的距离零向量的平均距离有多远或者说我的训练样本距离原点有多远。
当试图选择k,一个常见的经验方法是选择最小的值使得这两者之间的比值小于0.01。换句话说,一种常见的方式来选择k是我们想让投影的均方误差,即x和其投影的平均距离除以数据的总方差,这也就是数据的波动程度,希望这个比例可以小于比如0.01或1%,这是另一种表述方式。
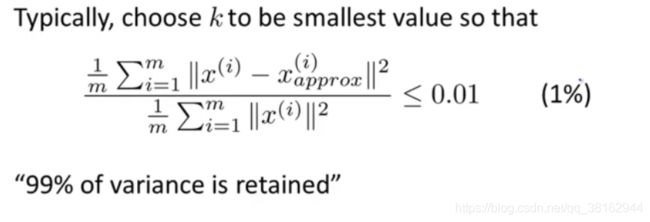
大多数人选择k并不是像多数人谈论的那样直接进行选择,因为这个数无论是0.01或一些其他数值。另一种用PCA的语言来表述的方式是:99%的方差性会被保留,不必纠结这话是什么意思。
“99%的方差性会被保留”只是说左侧的这个量小于0.01,如果你正在使用PCA,想要告诉别人你保留了多少主成分,这样的表述比较好:我选择的k使得99%的方差被保留。这是需要了解的很有用的概念,它的意思其实就是投影的均方误差除以数据总方差不会超过1%。
下面是PCA算法选择k的过程:

如果检查的结果不是小于0.01,将k的值取2,以此类推,直到结果验证正确,此时就可以确定选择的k值。
另一中选择k的方式如下:

压缩重现
在之前的几节的学习中,我们一直把PCA作为压缩算法来讨论。它可以把一个1000维的数据压缩成100维的特征向量,或者把一个三维的数据压缩成二维表示。思考这样的一个问题:如果这是一个压缩算法,就应该有办法从这个压缩表示回到原来高维数据的一种近似表述,所以假设给定100维的Z(i),怎么回到原来的表示X(i)(X(i)可能是1000维),接下来就来介绍如何去做。
在PCA算法中,可能有这样的样本:x(1),x(2),要取这些样本,然后把它们投影到这个一维面上,现在只需一个实数比如z(1)来表示这些点被投影到这个一维面上后的位置,如下图所示,所以给定一个点,要怎么回到原来的二维空间?
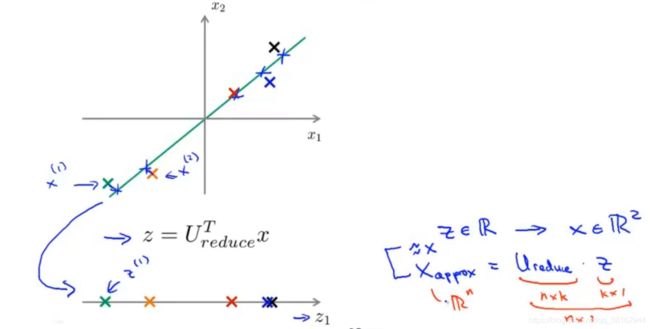
所以如果要反过来求x的话,这个方程就是X(approx)=U(reduce)×Z,这里的是一个n×k的向量,z是一个k×1的向量,把它们乘起来就得到了n×1维,所以是一个n维向量。
PCA的意图就是,如果平方投影误差不太大,这样X(approx)就会很接近原先用来求z的x值了。用图来表示的话就是这个样子(如下图),返回去的这个过程得到的就是这些投影到直线上的点。

用原来的例子,从开始x(1),然后得到z(1),如果z(1)把代到这个式子里,得到X(approx)1,它在R^2空间里,继续做同样的步骤,下一点就是X(approx)2,所以这是一个对原始数据不错的近似。
以上就是如何从低维表示z回到未压缩的数据表示,得到一个原来数据x的近似,也把这个过程叫做原始数据的重构,这一过程就是通过压缩表示,重建原来的数据x。
所以给定一个未标注的数据集,现在知道如何应用PCA把高维数据特征x映射到低维的表示z,从这章节的学习中,也知道了如何把低维表示z映射回到原来的高维数据的一个近似表示。
应用PCA的建议
这一节中将介绍如何使PCA加快学习算法的效率,并给出如何应用PCA算法的相关的建议。
PCA加速学习算法的方法:
假设有一个监督学习的问题,有训练集,假设具有很高的维度,比如说是一个10000维的特征向量,在实际应用中,可能是一个计算机视觉的问题,有一些100*100的图片,就会有10000个像素点。
对于这种高维度的特征向量,运行学习算法时将变得非常慢,而幸运的是,用PCA算法,可以减少数据的维度,从而使得算法运行更加高效。可以按照以下步骤来做:

这样得出了新的训练集,接着,可以把这个低维的训练集输入一个学习算法(可能是神经网络或者逻辑回归)。
注意:PCA所做的是定义一个从x到z的映射,这个映射只能通过在训练集上运行PCA来定义,具体地说,PCA学习的这个映射所做的就是计算一系列参数,进行特征缩放和均值归一化等等;在训练集上,找到所有的参数后,可以把这个映射用在交叉验证集或者测试集的其他样本中。
PCA的应用:
(1)首先可以进行压缩,可能需要它来减少存储数据所需的存储器或硬盘空间;
(2)使用PCA去加速学习算法;
以上两个应用中,为了选择K,经常会计算出方差保留的百分比(通常99%)。
(3)可视化应用。(一般选择k=2或3)
PCA的误用:
(1)尝试用PCA去防止过拟合,以下是不要误用的原因:
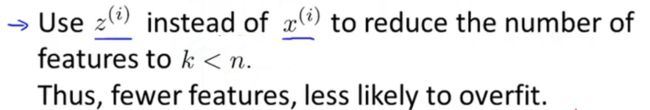
如果真担心过拟合问题,可以使用之前说到的正则化 方法来解决。
(2)有一些人在设计机器学习系统时,可能会写下这样的计划:

其实,在写下包含PCA的项目计划之前,应该思考这样的问题:如果直接去做而不使用PCA会怎么样?
在实现PCA之前,直接做你想做的事,首先考虑使用最原始的数据x(i),只有这么做不能达到目的的情况下,才考虑使用PCA和z(i)。
这就是PCA算法的介绍,PCA是非常常用的最强大的无监督学习算法之一,所以通过本章的学习,希望可以使用PCA去完成各种不同的目标。