吴恩达机器学习课后习题ex6支持向量机(python实现)
支持向量机
- 支持向量机
- 垃圾邮件分类
支持向量机
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
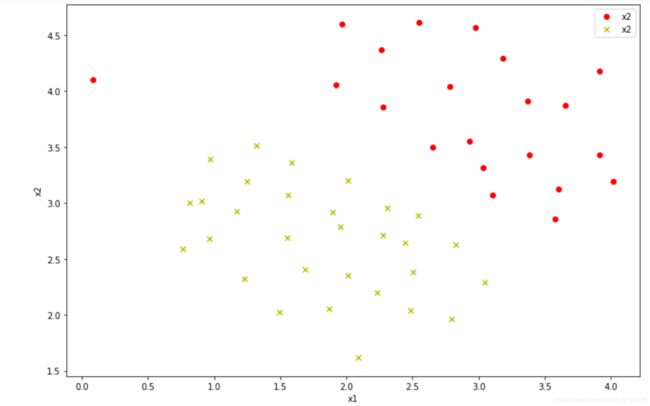
data1=loadmat('./data/ex6data1.mat')
data=pd.DataFrame(data1['X'],columns=['x1','x2'])
data['y']=data1['y']
positive=data[data['y']==1]
negative=data[data['y']==0]
fig,ax=plt.subplots(figsize=(12,8))
ax.scatter(positive['x1'],positive['x2'],c='r',marker='o')
ax.scatter(negative['x1'],negative['x2'],c='y',marker='x')
ax.legend()
ax.set_xlabel('x1')
ax.set_ylabel('x2')
plt.show()
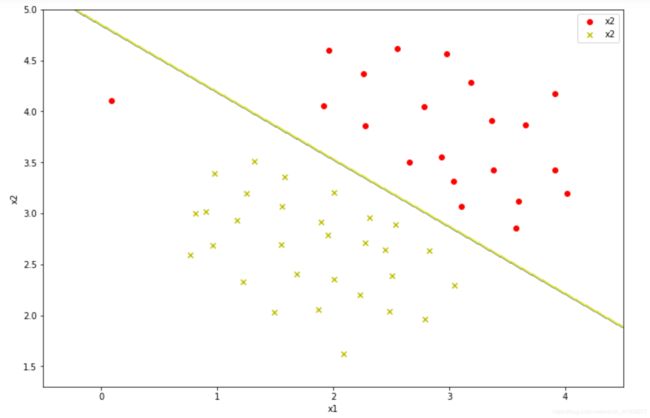
from sklearn.svm import SVC
svc1=SVC(C=1,kernel='linear')
svc1.fit(data1['X'],data1['y'].ravel())#拟合
#当前分类器的准确率
svc1.score(data1['X'],data1['y'].ravel())
准确率是0.9803921568627451
def plot_decisionboundary(model):
x=np.linspace(-0.5,4.5,500)
y=np.linspace(1.3,5,500)
xx,yy=np.meshgrid(x,y)
##预测值这段代码中ravel函数将多维数组降为一维,仍返回array数组,元素以列排列。之后调用np.c_[]将xx.ravel()得到的列后增加以列yy.ravel()。
#这时每行元素变为了[[x1,y1],[x2,y2]]
z=model.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
plt.contour(xx,yy,zz)
positive=data[data['y']==1]
negative=data[data['y']==0]
fig,ax=plt.subplots(figsize=(12,8))
ax.scatter(positive['x1'],positive['x2'],c='r',marker='o')
ax.scatter(negative['x1'],negative['x2'],c='y',marker='x')
ax.legend()
ax.set_xlabel('x1')
ax.set_ylabel('x2')
plot_boundary(svc1)
plt.show()
垃圾邮件分类
with open('data/emailSample1.txt','r') as f:
email=f.read()
print(email)
对邮件进行预处理
Lower-casing: The entire email is converted into lower case, so that captialization is ignored (e.g., IndIcaTE is treated the same as Indicate).
• Stripping HTML: All HTML tags are removed from the emails.Many emails often come with HTML formatting; we remove all the HTML tags, so that only the content remains.
• Normalizing URLs: All URLs are replaced with the text \httpaddr".
• Normalizing Email Addresses: All email addresses are replaced with the text \emailaddr".
• Normalizing Numbers: All numbers are replaced with the text \number".
• Normalizing Dollars: All dollar signs ($) are replaced with the text \dollar".
• Word Stemming: Words are reduced to their stemmed form. For example, \discount", \discounts", \discounted" and \discounting" are all replaced with \discount". Sometimes, the Stemmer actually strips off additional characters from the end, so \include", \includes", \included", and \including" are all replaced with \includ".
• Removal of non-words: Non-words and punctuation have been removed. All white spaces (tabs, newlines, spaces) have all been trimmed to a single space character.
import re
from stemming.porter2 import stem
import nltk, nltk.stem.porter
def prepocess(email): #字符串
email=email.lower() #小写
email=re.sub('<[^<>]>',' ',email) #去掉html
email=re.sub('(http|https)://[^\s]*','httpaddr',email) #Normalizing URLs
email=re.sub('[^\s]+@[^\s]+','emailaddr',email) #Normalizing email
email=re.sub('[\$]+','number',email) #Normalizing Numbers
email=re.sub('[\d]+','dollar',email)
return email
#完成后两步预处理
def email2list(email):
stemmer = nltk.stem.porter.PorterStemmer()
#先进行之前的预处理
email=prepocess(email)
tokens = re.split('[\@\$\/\#\.\-\:\&\*\+\=\[\]\?\!\(\)\{\}\,\'\"\>\_\<\;\%]', email)
tokenlist=[]
for token in tokens:
token=re.sub('[^a-zA-Z0-9]','',token)
stemmed=stemmer.stem(token) #提取词根
if not len(token): continue
tokenlist.append(stemmed)
return tokenlist #字符串列表
#Vocabulary List
def list2indics(email,vocab):
tokenlist=email2list(email)
index=[i for i in range(len(vocab)) if vocab[i] in tokenlist]
return index
#提取特征,变成0,1格式的向量
def extractfeature(email):
df=pd.read_table('data/vocab.txt',names=['words'])
vocab=df.values
vector=np.zeros(len(vocab))
index=list2indics(email,vocab)
for i in index:
vector[i]=1
return vector
准备的spamTrain.mat和spamTest.mat数据集是已经经过预处理的0,1向量,可以直接使用SVC函数
train_data=loadmat('data/spamTrain.mat')
train_x=train_data['X']
train_y=train_data['y']
test_data=loadmat('data/spamTest.mat')
test_x=test_data['Xtest']
test_y=test_data['ytest']
model=SVC(kernel='linear')
model.fit(train_x,train_y.ravel())
predtrain=model.score(train_x,train_y)
predtest=model.score(test_x,test_y)
predtrain,predtest
(0.99975, 0.978)