2019独角兽企业重金招聘Python工程师标准>>> 
关于MongoDb
1、MongoDB是一个开源的、基于分布式的、面向文档存储的非关系型数据库。
2、是非关系型数据库当中功能最丰富、最像关系数据库的。
3、由C++编写, MongoDB可以运行在Windows、unix、OSX、Solaris系统上,支持32位和64位应用,提供多种编程语言的驱动程序。
4、旨在为WEB应用提供可扩展的高性能数据存储解决方案。
5、MongoDB高性能、易部署、易使用,存储数据非常方便。
MongoDb特点
MongoDB最大的特点是支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB的主要特点:面向文档、模式自由、高可用性、水平拓展、支持丰富。
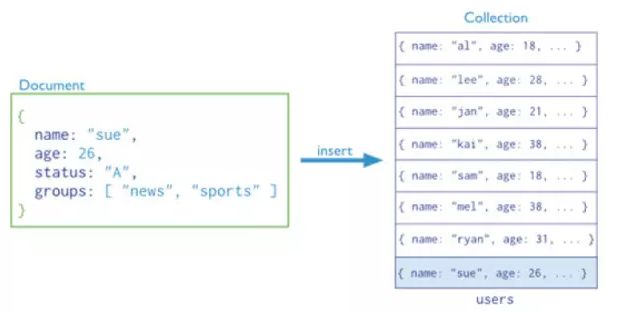
面向文档
文档就是存储在MongoDB中的一条记录,是一个由键值对组成的数据结构。如{"company":"itcast","address":"Beijing"}。作为面向文档(Document-Oriented)的数据库,document之于collection,record之于table。
模式自由
文档是MongoDB中数据的基本单元,集合则可以被看作是没有模式的表。
模式自由(schema-free),每一个Document都包含了元数据信息,每个文档之间不强迫要求使用相同的格式,同时他们也支持各种索引。由于没有模式需要更改,通常不需要迁移大量数据。比如一个student文档:
{"name":"C++lover","like":{"Linux系统编程","分布式系统","MongoDB"}}
高可用性
高可用性(High Availability,HA)是尽量缩短因维护和崩溃所导致的停机时间,以提高系统和应用的可用性。MongoDB支持在复制集(Replica Set)通过异步复制达到故障转移,自动恢复,集群中主服务器崩溃停止服务和丢失数据,备份服务器通过选举获得大多数投票成为主节点,以此来实现高可用。该模式下为实现读写分离而在备份节点上进行读操作,由于备份服务器实时同步主服务器Oplog写操作,虽然适当的一些读也是可分担部分主节点的任务,但是有增加从节点的延时风险。最新的MongoDB3.0提供了MVCC机制,实现了文档级别的并发控制,进一步提高了并发性能。
水平拓展
MongoDB不推荐使用从节点实现读性能拓展,而是使用分片Shard。MongoDB支持分片技术,它能够支持并行处理和水平扩展。通过自动分片技术,Shard能够在多个片之间分发数据,可以让MongoDB的部署解决单个服务器的硬件限制而不需要增加应用程序的复杂性,解决包括RAM和磁盘I/O的限制,一个片通常也是一个复制集。
支持丰富
MongoDB除了提供以上丰富的功能支持,另外还提供了丰富的BSON数据类型,官方还有MongoDB的官方driver支持(C/C++、C#、Java、Node.js、Perl、PHP、Python、Ruby、Scala),另外社区支持了MongoDB的Go,Erlang的驱动。
此外MongoDB内置MapReduce引擎等聚合框架,空间地理数据的索引,GridFS等适合多种业务需求。
MongoDb优势
1、结构灵活,表结构更改比较自由,不用每次alter的时候付出代价,适合业务快速迭代,而且json原生和大多数的语言有天然的契合。还支持数组,嵌套文档等数据类型
2、自带高可用,自动主从切换(副本集)
3、自带水平分片(分片),内置了路由,配置管理。应用只要连接路由,对应用来说是透明的。
什么是NoSQL
NoSQL,指的是非关系型的数据库。NoSQL 有时也称作 Not Only SQL(意即"不仅仅是SQL") 的缩写,是对不同于传 统的关系型数据库的数据库管理系统的统称。NoSQL 用于超大规模数据的存储。(例如谷歌 或 Facebook 每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的 模式,无需多余操作就可以横向扩展。
为什么NoSQL快?(MongoDB写入过程)
都知道NoSQL快,关键快在,MongoDB修改的是内存的文档,接着就直接返回了。这过程的详细信息如下:
Mongo使用了内存映射技术 - 写入数据时候只要在内存里完成就可以返回给应用程序,而保存到硬体的操作则在后台异步完成。
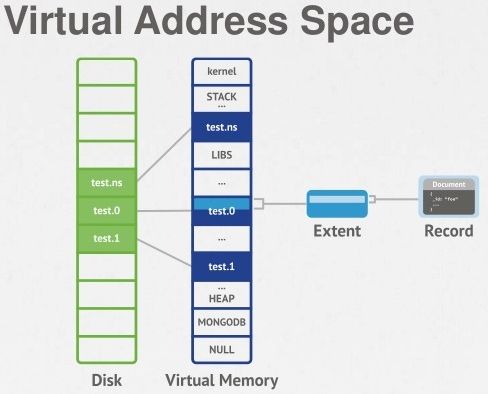
先了解一下Memeory-Mapped Files
1、内存映射文件是OS通过mmap在内存中创建一个数据文件,这样就把文件映射到一个虚拟内存的区域。
2、虚拟内存对于进程来说,是一个物理内存的抽象,寻址空间大小为2^64
3、操作系统通过mmap来把进程所需的所有数据映射到这个地址空间(红线),然后再把当前需要处理的数据映射到物理内存(灰线)
4、当进程访问某个数据时,如果数据不在虚拟内存里,触发page fault,然后OS从硬盘里把数据加载进虚拟内存和物理内存
5、如果物理内存满了,触发swap-out操作,这时有些数据就需要写回磁盘,如果是纯粹的内存数据,写回swap分区,如果不是就写回磁盘。

MongoDB的存储模型
MongoDB把文档写进内存之后就返回了,那么接下来的数据的一致性问题、持久化问题,由journal日志来实现了。
默认情况下mongodb每100毫秒往journal文件中flush一次数据,
默认每隔60秒,MongoDB请求操作系统将Shared view刷新输出到磁盘,
此外,journal日志还可以用来做备份容灾。
这样Mongo的一次数据写入过程才算完成。
MongoDB的 journal 与 oplog
journal
journal 是 MongoDB 存储引擎层的概念,目前 MongoDB主要支持 mmapv1、wiredtiger、mongorocks 等存储引擎,都支持配置journal。
MongoDB 所有的数据写入、读取最终都是调存储引擎层的接口来存储、读取数据,journal 是存储引擎存储数据时的一种辅助机制。
以wiredtiger 为例,如果不配置 journal,写入 wiredtiger 的数据,并不会立即持久化存储;
而是每分钟会做一次全量的checkpoint(storage.syncPeriodSecs配置项,默认为1分钟),将所有的数据持久化。
如果中间出现宕机,那么数据只能恢复到最近的一次checkpoint,这样最多可能丢掉1分钟的数据。
所以建议「一定要开启journal」,开启 journal 后,每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。
这样即使出现宕机,启动时 Wiredtiger 会先将数据恢复到最近的一次checkpoint的点,然后重放后续的 journal 操作日志来恢复数据。
MongoDB 里的 journal 行为 主要由2个参数控制,
storage.journal.enabled 决定是否开启journal,
storage.journal.commitInternalMs 决定 journal 刷盘的间隔,默认为100ms,
用户也可以通过写入时指定 writeConcern 为 {j: ture} 来每次写入时都确保 journal 刷盘。
oplog
oplog 是 MongoDB 主从复制层面的一个概念,通过 oplog 来实现复制集节点间数据同步,
客户端将数据写入到 Primary,
Primary 写入数据后会记录一条 oplog,
Secondary 从 Primary(或其他 Secondary )拉取 oplog 并重放,来确保复制集里每个节点存储相同的数据。
oplog 在 MongoDB 里是一个普通的 capped collection,对于存储引擎来说,oplog只是一部分普通的数据而已。
MongoDB 的一次写入
MongoDB 复制集里写入一个文档时,需要修改如下数据
- 将文档数据写入对应的集合
- 更新集合的所有索引信息
- 写入一条oplog用于同步
上面3个修改操作,需要确保要么都成功,要么都失败,不能出现部分成功的情况,否则
- 如果数据写入成功,但索引写入失败,那么会出现某个数据,通过全表扫描能读取到,但通过索引就无法读取
- 如果数据、索引都写入成功,但 oplog 写入不成功,那么写入操作就不能正常的同步到备节点,出现主备数据不一致的情况
MongoDB 在写入数据时,会将上述3个操作放到一个 wiredtiger 的事务里,确保「原子性」。
beginTransaction();
writeDataToColleciton();
writeCollectionIndex();
writeOplog();
commitTransaction();
wiredtiger 提交事务时,会将所有修改操作应用,并将上述3个操作写入到一条 journal 操作日志里;后台会周期性的checkpoint,将修改持久化,并移除无用的journal。
从数据布局看,oplog 与 journal 的关系

journal 与oplog谁先写入?
- oplog 与 journal 是 MongoDB 里不同层次的概念,放在一起比先后本身是不合理的。
- oplog 在 MongoDB 里是一个普通的集合,所以 oplog 的写入与普通集合的写入并无区别。
- 一次写入,会对应数据、索引,oplog的修改,而这3个修改,会对应一条journal操作日志。
MongoDB副本集与读写分离
故障切换恢复
副本集能够自动进行故障切换恢复。如果primary掉线或者无反应且多数的副本集成员能够相互连接,则选出一个新的primary。
在多数情况下,当primary宕机、不可用或者是不适合做primary时,在没有管理者干预的几秒后会进行故障切换。
如果MongoDB部署没有如预期那样进行故障切换,则可能是下面的问题:
- 剩余的成员个数少于副本集的一半
- 没有成员有资格成为primary
副本集优势
1、在实际生产环境中,一个Mongod风险会很高,在某段时间内,数据库发生了奔溃,会有一段时间内数据库不可用。硬件出了问题,需要将数据拷贝到另一个电脑上。
2、官方建议在所有的生产环境中都使用副本集,即使一台多态服务器中出现错误,也可以保证应用程序的正常运行和数据安全。
副本集操作
1、副本集的配置中不能使用Localhost作为副本集的配置,其它节点将无法识别。
2、使用rs.add()添加副本集
3、rs.remove()删除副本集
选举机制
当任意的故障切换发生,都会伴随着选举的出现,以此来决定哪个成员成为primary。
选举提供了一种机制,用于副本集中的成员无需管理员的干预,自动的选出一个新的primary。选举可以让副本集快速和坚决的从故障中恢复。当primary变为不可达时,secondary成员发起选举,第一个收到大多数选票的成员成为新的primary。
前提:
每个成员自能要求自己被选举成为主节点,只能为申请成为主节点的候选人投票
当一个备份节点无法与主节点联通时 她就自行联系并请求其他成员将自己选举为主节点,其他成员做几项理性的检查
- 自身是否能够与主节点联通
- 希望被选举为主节点的备份节点的数据是否是最新
- 有没有其他更高优先级的成员可以被选举为主节点
心跳
每个成员都需要知道其他成员的状态:哪个是主节点,哪个可以作为同步源,哪个挂掉了。
为了维护最新视图,每个成员每个两秒就会向其他成员发送一条心跳请求,心跳请求信息量很小,用于检查每个成员的状态。
心跳的最重要的功能之一:就是让主节点知道自己是否满足集合大多数的条件。如果主节点不再得到大多数服务器的支撑,他就会退位变成备份节点.
副本集的优先级
副本集当中的节点即使使用了较高的优先级,但是如果数据不够新,依旧不会成为主节点。
通过设置slaveDelay要求成员的优先级为0,延迟备份节点的数据将比主节点的数据延迟指定时间,以防止主节点在某一段时间内发生了异常影响备份节点的数据。
一般这种情况下,要求备份节点的为隐藏节点,防止读操作定向于该节点。如果不希望某个节点被客户端读,可以设置该节点为隐藏节点。比如我们只是希望一个冗余备份,那么可以使用一个不太好的服务器设置为隐藏节点进行容灾。
读写分离
官网中建议不使用向从节点取数据。原因:
1、所有的从节点拥有与主节点一样的写入负载,读的加入会增加其负载
2、对于分片的集合,在平衡器的关系下,数据的返回结果可能会缺失或者重复某部分数据。
3、相对而言,官方建议使用shard来分散读写请求。
使用的场景;
1、异地的分布式部署
2、故障切换,在紧急情况下向从节点读数据
副本集总结:
副本集不是为了提高读性能存在的,在进行oplog的时候,读操作是被阻塞的。
提高读取性能应该使用分片和索引,它的存在更多是作为数据冗余,备份。
尤其当主库本来就面临着大量的写入压力,对于副本集的节点,也同样会面临写的压力。
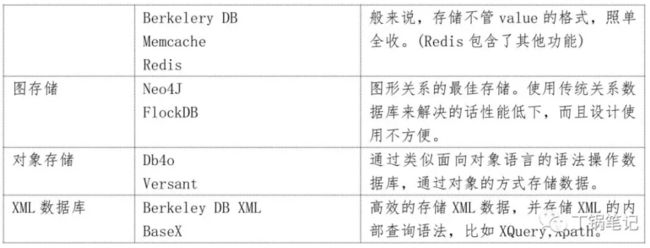
关系型数据库 PK 非关系型数据库
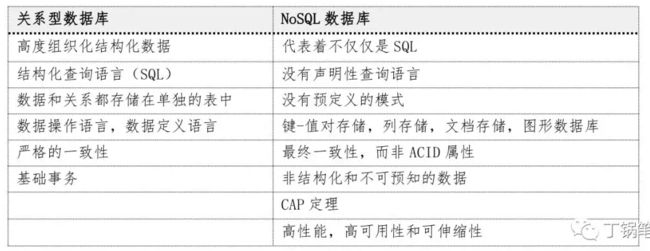
关系型数据库 PK 非关系型数据库
ACID
-
原子性(Atomicity)
-
一致性(Consistency)
-
隔离性(Isolation)
-
持久性 (Durable)
CAP原理
在计算机科学中, CAP 定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性(Consistency) (所有节点在同一时间具有相同的数据)
可用性(Availability) (保证每个请求不管成功或者失败都有响应)
分区容错性(Partition tolerance) (系统中任意信息的丢失或失败不影响系统的继续运行)
CAP 理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。 因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP - 满足一致性,分区容错性的系统,通常性能不是特别高。
AP - 满足可用性,分区容错性的系统,通常可能对一致性要求低一些。 MongoDB默认就是满足Ap的,弱事务性。
MongoDB的数据结构与关系型数据库数据结构对比
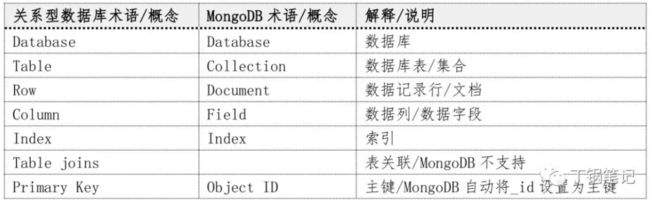
MongoDB 中的数据类型


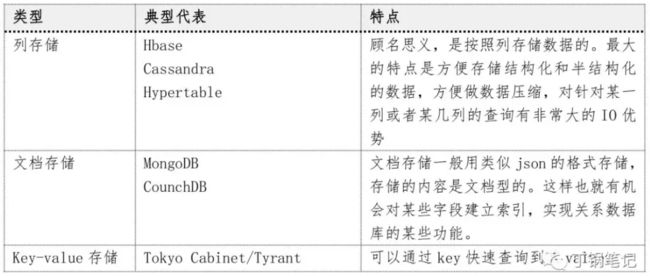
MongoDB的应用场景和不适用场景
1、适用场景
1)网站实时数据:MongoDB 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
2)数据缓存:由于性能很高,MongoDB 也适合作为信息基础设施的缓存层。在系统重启之后,由 MongoDB 搭建的持久化缓存层可以避免下层的数据源过载。
3)大尺寸、低价值数据存储:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
4)高伸缩性场景:MongoDB 非常适合由数十或数百台服务器组成的数据库。MongoDB 的路线图中已经包含对 MapReduce 引擎的内置支持。
5)对象或 JSON 数据存储:MongoDB 的 BSON 数据格式非常适合文档化格式的存储及查询。
2、不适用场景
1)高度事务性系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
2)传统的商业智能应用:针对特定问题的 BI 数据库会对产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
3)需要复杂 SQL 查询的问题。
MongoDB 不仅仅是数据库,更多的使用是将 MongoDB 作为一个数据库中间件在实际应用中合理划分使用细节,这一点对于 MongoDB 应用来讲至关重要!
MongoDb对事务的支持性
MongoDB只支持行级的事务,或者说支持原子性,单行的操作要么全部成功,要么全部失败。
需要事务的话,得自己用代码实现二次提交作,模拟事务的功能,官方文档有相关的说明。
https://docs.mongodb.com/manual/tutorial/perform-two-phase-commits/
不过,MongoDB 将在4.0版本中正式推出多文档ACID事务支持。ACID 多文档事务,可以理解为关系型数据库的多行事务。
MongoDb数据库备份
常用而且通用的方法就是mongodump
备份还有这几种方法:
1. mongoexport(这个是逻辑备份,备份出json和csv)
2. 做磁盘快照
3. 停机后冷拷贝
MongoDb大数据迁移
一般来说mongodump来迁移即可。
集群迁移的话,建议直接在目标服务器上面搭建从节点。全部搭建完之后,把新的从节点升级为主节点,再把老机器剔除出集群。
不过如果数据量太大,而且平时数据更改很频繁的话,初始化同步的过程可能Oplog不够用。
方案1
先升级到3.4版本,这个版本在初始化同步的时候会抓取oplog
方案2
停机一台从节点,物理复制到局域网中心机器,当从节点启动
这台从节点配置一个大oplog,然后迁移目标端的从节点从这台oplog从节点同步
MongoDb搭建、安装
建立数据库目录
mac: \data\db
windows: C:\data\db
启动 MongoDB
执行mongod
-
默认数据库目录为 /data/db
-
默认端口为 27017
-
PATH环境变量
-
读写权限
// 最基本
mongod
// 指定dbpath
mongod --dbpath ~/data/db/mongo
// 指定端口
mongod --dbpath ~/data/db/mongo --port 12345
// 启用安全认证
mongod --dbpath ~/data/db/mongo --port 12345 --auth
// 帮助
mongod --help连接 MongoDB
执行mongo
➜ mongo
MongoDB shell version v4.0.4
connecting to: mongodb://127.0.0.1:27017
...
>
或访问http://localhost:27017
It looks like you are trying to access MongoDB over HTTP on the native driver port.
MongoDB Shell
是一个JavaScript Shell,可以进行简单数学运算
> 1 + 1
2
>
Help查看命令提示
help
db.help();
db.yourColl.help();
db.youColl.find().help();
rs.help();
查看数据库
使用show dbs命令,查看数据库列表
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
skel 0.000GB
test 0.000GB
使用db命令,查看当前数据库
> db
testdb.getName();
db; db和getName方法是一样的效果,都可以查询当前使用的数据库显示当前db状态
db.stats();当前db版本
db.version();查看当前db的链接机器地址
db.getMongo();
切换/创建数据库
使用use命令,如果存在则切换,如果不存在则创建,并切换
> use moc
switched to db moc
删除数据库
切换到需要删除的数据库,使用db.dropDatabase()命令删除
> db
moc
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
moc 0.000GB
skel 0.000GB
test 0.000GB
> db.dropDatabase()
{ "dropped" : "moc", "ok" : 1 }
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
skel 0.000GB
test 0.000GB
克隆/复制
从指定主机上克隆数据库
db.cloneDatabase(“127.0.0.1”); 将指定机器上的数据库的数据克隆到当前数据库从指定的机器上复制指定数据库数据到某个数据库
db.copyDatabase("mydb", "temp", "127.0.0.1");将本机的mydb的数据复制到temp数据库中
修复
修复当前数据库
db.repairDatabase();
创建一个聚集集合(table)
db.createCollection(“collName”, {size: 20, capped: 5, max: 100});//创建成功会显示{“ok”:1}
//判断集合是否为定容量db.collName.isCapped();得到指定名称的聚集集合(table)
db.getCollection("account");得到当前db的所有聚集集合
db.getCollectionNames();显示当前db所有聚集索引的状态
db.printCollectionStats();
用户相关
添加一个用户
db.addUser("name");
db.addUser("userName", "pwd123", true); 添加用户、设置密码、是否只读数据库认证、安全模式
db.auth("userName", "123123");显示当前所有用户
show users;删除用户
db.removeUser("userName");
添加,insert
在mongodb中是不存在表的概念的,而是把数据存放到集合中。
向集合person中插入数据,文档使用json格式
> db.person.insert({"name":"moc","age":18})
WriteResult({ "nInserted" : 1 })
> db.person.insert({"name":"jim","age":19})
WriteResult({ "nInserted" : 1 })
> db.person.insert({"name":"cleopard","age":18,"t})
2018-12-12T09:35:08.348+0800 E QUERY [js] SyntaxError: unterminated string literal @(shell):1:45db.users.save({name: ‘zhangsan', age: 25, sex: true});
添加的数据的数据列,没有固定,根据添加的数据为准查找,find
不加参数,表示查询所有内容
> db.person.find()
{ "_id" : ObjectId("5c106438b50d4391049cc17c"), "name" : "moc", "age" : 18 }
{ "_id" : ObjectId("5c10644cb50d4391049cc17d"), "name" : "jim", "age" : 19 }相当于:select* from person;
默认每页显示20条记录,当显示不下的情况下,可以用it迭代命令查询下一页数据。注意:键入it命令不能带“;”
但是你可以设置每页显示数据的大小,用DBQuery.shellBatchSize= 50;这样每页就显示50条记录了。
“_id”: 这个字段是数据库默认给我们加的GUID,目的就是保证数据的唯一性
find可以添加参数,参数同样是json格式
> db.person.find({"name":"moc"})
{ "_id" : ObjectId("5c106438b50d4391049cc17c"), "name" : "moc", "age" : 18 }
查询去掉后的当前聚集集合中的某列的重复数据
db.userInfo.distinct("name");
会过滤掉name中的相同数据
相当于:select distict name from userInfo;
更新,update
update方法的第一个参数为“查找的条件”,第二个参数为“更新的值”,同样参数也都是json格式
> db.person.update({"name":"jim"},{"name" : "cleopard", "age" : 20})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.person.find({"name":"jim"})
> db.person.find({"name":"cleopard"})
{ "_id" : ObjectId("5c10644cb50d439104db.users.update({age: 25}, {$set: {name: 'changeName'}}, false, true);
相当于:`update users set name = ‘changeName’ where age = 25;
db.users.update({name: 'Lisi'}, {$inc: {age: 50}}, false, true);
相当于:update users set age = age + 50 where name = ‘Lisi';
db.users.update({name: 'Lisi'}, {$inc: {age: 50}, $set: {name: 'hoho'}}, false, true);
相当于:update users set age = age + 50, name = ‘hoho' where name = ‘Lisi';
删除,remove
-
如果不带参数执行
remove,则删除所有数据 -
删除不可撤回
> db.person.remove({"name":"cleopard"})
WriteResult({ "nRemoved" : 1 })
> db.person.find()
{ "_id" : ObjectId("5c106438b50d4391049cc17c"), "name" : "moc", "age" : 18 }
# 默认会删除多行
# 只删除一行
db.stuinfo.remove({name:'李四'},{justOne:true})
查询修改删除
db.users.findAndModify({
query: {age: {$gte: 25}},
sort: {age: -1},
update: {$set: {name: 'a2'}, $inc: {age: 2}},
remove: true
});
db.runCommand({ findandmodify : "users",
query: {age: {$gte: 25}},
sort: {age: -1},
update: {$set: {name: 'a2'}, $inc: {age: 2}},
remove: true
});update 或 remove 其中一个是必须的参数; 其他参数可选。
参数 详解 默认值
query 查询过滤条件 {}
sort 如果多个文档符合查询过滤条件,将以该参数指定的排列方式选择出排在首位的对象,该对象将被操作 {}
remove 若为true,被选中对象将在返回前被删除 N/A
update 一个 修改器对象
N/A
new 若为true,将返回修改后的对象而不是原始对象。在删除操作中,该参数被忽略。 false
fields 参见Retrieving a Subset of Fields (1.5.0+)
All fields
upsert 创建新对象若查询结果为空。 示例 (1.5.4+)
false
多样化查询
首先创建一个数据,添加如下数据
use stu
db.stu.insert({name:'小花',sex:'男',age:18,address:'武汉'})
db.stu.insert({name:'小王',sex:'女',age:20,address:'广州'})
db.stu.insert({name:'小赵',sex:'女',age:25,address:'上海'})
db.stu.insert({name:'小陈',sex:'男',age:10,address:'北京'})
db.stu.insert({name:'小杜',sex:'男',age:30,address:'南京'})
db.stu.insert({name:'小二',sex:'女',age:23,address:'深圳'})
# 查询性别为男的
db.stu.find({sex:'男'})
# 改变格式输出
db.stu.find({sex:'男'}).pretty()
# 查询性别为男的只显示一个
db.stu.findOne({sex:'男'})
# 查询年龄为20的
db.stu.find({age:20})
# 比较运算符
小于:$lt
# 查询年龄大于20的
db.stu.find({age:{$lt:20}})
小于等于:$lte
# 查询年龄大于等于20的
db.stu.find({age:{$lte:20}})
大于:$gt
# 查询年龄大于25的
db.stu.find({age:{$gt:25}})
大于等于:$gte
# 查询年龄大于等于25的
db.stu.find({age:{$gte:25}})
不等于:¥ne
# 查询年龄不等于25的
db.stu.find({age:{$ne:25}})
范围运算符
# 查询年龄为18和25的人
db.stu.find({age:{$in:[18,25]}})
# 查询年龄不为18和25的人
db.stu.find({age:{$nin:[18,25]}})
# 多条件查询,年龄为18,并且是在武汉的
db.stu.find({age:18,address:'武汉'})
# 查询年龄为18,或地点在上海的
db.stu.find({$or:[{age:18},{address:'上海'}]})
# 正则表达式查询
# 查询以姓名以小开头的人
db.stu.find({name:/^小/})
或者
db.stu.find({name:{$regex:'^小'}})
# 查询前两行数据
db.stu.find().limit(2)
# 跳过前两行数据
db.stu.find().skip(2)
# 跳过前两行显示两行
db.stu.find().skip(2).limit(2)
# limit和skip组合可以达到分页的效果
# 自定义查询
# 查询年龄等于18的:
db.stu.find({$where:funtion(){return this.age==18}})
# 写法和我们jquery中是一样的。
# 查询年龄为18的name值
db.stu.find({age:18},{name:1})
# 上面还是会显示_id,我们修改成
db.stu.find({age:18},{name:1,_id:0})
# 注意,不想显示_id写成_id:0
# 其他不想显示就不写name:1或age:1,其他字段写成name:0会报错
#查询指定列name、age数据
db.userInfo.find({}, {name: 1, age: 1});
相当于:select name, age from userInfo;
当然name也可以用true或false,当用ture的情况下河name:1效果一样,如果用false就是排除name,显示name以外的列信息。
排序
# 以年龄升序排序
db.stu.find().sort({age:1})
# 以年龄降序排序
db.stu.find().sort({age:-1})
# 多字段排序直接逗号隔开添加就好
# 所有数据只显示name值
db.stu.find({},{name:1,_id:0})
# 查询一共多少行数据
db.stu.find().count()
或者
db.stu.count()
# 查询年龄大于20的有多少数据
db.stu.find({age:{$gt:20}}).count()
或者
db.stu.count({age:{$gt:20})
去重复
# 去除name重复的
db.stu.distinct('name')
# 在年龄大于20的人中去除name重复的
db.stu.distinct('name',{age:{$gt:20}})
#查询name中包含 mongo的数据
db.userInfo.find({name: /mongo/});
//相当于%%
select * from userInfo where name like ‘%mongo%';
#查询name中以mongo开头的
db.userInfo.find({name: /^mongo/});
select * from userInfo where name like ‘mongo%';
#按照某列进行计数
db.userInfo.find({sex: {$exists: true}}).count();
相当于:select count(sex) from userInfo;
数据备份和恢复
这个密令直接在(终端)cmd中输入
备份
mongodump -h 服务器地址 -d 数据库名字 -o 存放的位置
# 在本地就值接不加-h就好了
恢复
mongorestore -h 服务器地址 -d 需要回复的数据库名字 --dir 备份数据库的位置
聚合(aggregate)
简单来说就是将上一次处理的结果交给下一个处理,最后一个处理完输出
我们将每一次的处理叫做管道。
常用管道有:
$group:分组,用于统计结果
$match:用于过滤数据
$project:修改结构,重命名,增加,删除字段,创建计算结果等
$sort:排序
$limit:显示的文档数(显示几行数据)
$skip:跳过前多少数量的文档
$unwind:将数据类型字段拆分
常用表达式
$sum:求和
$avg:平均值
$min:获取最小值
$max:获取最大值
$push:插入一个数组
$first:获取第一个文档数据
$last:获取最后一个文档数据
实例:
# 数据还是上一篇的stu中的数据
# 按照性别分组,并计算有多少人
db.stu.aggregate(
{$group:{_id:"$sex",count:{$sum:1}}}
)
输出:
{ "_id" : "女", "count" : 3 }
{ "_id" : "男", "count" : 3 }
# _id是指定用什么字段分组,需要写成$sex, $sum:1表示此行数据计算为1
# 在上面的基础上计算不同性别的平均值
db.stu.aggregate(
{$group:{_id:"$sex",count:{$sum:1},svg_age:{$avg:'$age'}}}
)
输出:
{ "_id" : "女", "count" : 3, "agv_age" : 22.666666666666668 }
{ "_id" : "男", "count" : 3, "agv_age" : 19.333333333333332 }
# 不进行分组,求所有人的数量和年龄平均值
db.stu.aggregate(
{$group:{_id:null,count:{$sum:1},svg_age:{$avg:'$age'}}}
)
# 在按照性别分组,并计算有多少人,计算不同性别的平均值只取count值
# 并且对count进行重命名为sum,不现实其他
db.stu.aggregate(
{$group:{_id:'$sex',count:{$sum:1},agv_age:{$avg:'$age'}}},
{$project:{sum:'$count',_id:0}}
)
# _id会默认显示,需要需要给个0,其他不写则不显示。
输出:
{ "sum" : 3 }
{ "sum" : 3 }
# 在上述例子中过滤sum大于2的
db.stu.aggregate(
{$group:{_id:'$sex',count:{$sum:1},agv_age:{$avg:'$age'}}},
{$project:{sum:'$count',_id:0}}
{$match:{sum:{$gt:2}}}
)
# 排序
# 按照年龄升序,降序就是-1
db.stu.aggregate(
{$sort:{age:1}}
)
# $limit和$skip
# 查询两条消息
db.stu.aggregate(
{$limit:2}
)
# 跳过前两条,显示两条
db.stu.aggregate(
{$skip:2}
{$limit:2}
)
# $unwind
# 对数组拆分
例如插入一条数据
db.test1.insert({_id:1,size:[111,222,333]})
# 拆分
db.test1.aggregate(
{$unwind:'$size'}
)
会输出:
{"_id":1,"size":111}
{"_id":1,"size":222}
{"_id":1,"size":333}
索引
# 插入1000条数据,在MongoDB中可以执行js脚本的
# 你可以插入更多的数据看到更好的效果
for(i=0;i<1000;i++){db.test.insert({name:"test"+i,age:i})}
# 查询一条数据
db.test.find({name:'test888'})
# 查看查询的时间
db.test.find({name:'test888'}).explain('executionStats')
找到executionTimeMillis,后面就是查询的时间单位是毫秒
# 建立索引
db.test.ensureIndex({name:1});
db.userInfo.ensureIndex({name: 1, ts: -1});
# 再次执行
db.test.find({name:'test888'}).explain('executionStats')
查看时间,对比没有建立索引时候的时间,差距是很大的。
# 查看当前集合的索引
db.test.getIndexes()
#读取当前集合的所有index信息
db.users.reIndex();
# 删除索引
db.test.dropIndex()
例如:db.test.dropIndex({name:1})
#删除指定索引
db.users.dropIndex("name_1");
#删除所有索引
db.users.dropIndexes();
# 建立索引如果不想有重复的值可以指定唯一性
# 爬虫去重复可以利用
db.test.ensureIndex({name:1},{'unique':true})
#查看总索引记录大小
db.userInfo.totalIndexSize();
语句块操作
1、简单Hello World
print("Hello World!");
这种写法调用了print函数,和直接写入”Hello World!”的效果是一样的;
2、将一个对象转换成json
tojson(new Object());
tojson(new Object('a'));
3、循环添加数据
\> for (var i = 0; i < 30; i++) {
... db.users.save({name: "u_" + i, age: 22 + i, sex: i % 2});
... };
这样就循环添加了30条数据,同样也可以省略括号的写法
\> for (var i = 0; i < 30; i++) db.users.save({name: "u_" + i, age: 22 + i, sex: i % 2});
也是可以的,当你用db.users.find()查询的时候,显示多条数据而无法一页显示的情况下,可以用it查看下一页的信息;
4、find 游标查询
\>var cursor = db.users.find();
\> while (cursor.hasNext()) {
printjson(cursor.next());
}
这样就查询所有的users信息,同样可以这样写
var cursor = db.users.find();
while (cursor.hasNext()) { printjson(cursor.next); }
同样可以省略{}号
5、forEach迭代循环
db.users.find().forEach(printjson);
forEach中必须传递一个函数来处理每条迭代的数据信息
6、将find游标当数组处理
var cursor = db.users.find();
cursor[4];
取得下标索引为4的那条数据
既然可以当做数组处理,那么就可以获得它的长度:cursor.length();或者cursor.count();
那样我们也可以用循环显示数据
for (var i = 0, len = c.length(); i < len; i++) printjson(c[i]);
7、将find游标转换成数组
\> var arr = db.users.find().toArray();
\> printjson(arr[2]);
用toArray方法将其转换为数组
8、定制我们自己的查询结果
只显示age <= 28的并且只显示age这列数据
db.users.find({age: {$lte: 28}}, {age: 1}).forEach(printjson);
db.users.find({age: {$lte: 28}}, {age: true}).forEach(printjson);
排除age的列
db.users.find({age: {$lte: 28}}, {age: false}).forEach(printjson);
9、forEach传递函数显示信息
db.things.find({x:4}).forEach(function(x) {print(tojson(x));});
其他
1、查询之前的错误信息
db.getPrevError();
2、清除错误记录
db.resetError();查看聚集集合基本信息
1、查看帮助 db.yourColl.help();
2、查询当前集合的数据条数 db.yourColl.count();
3、查看数据空间大小 db.userInfo.dataSize();
4、得到当前聚集集合所在的db db.userInfo.getDB();
5、得到当前聚集的状态 db.userInfo.stats();
6、得到聚集集合总大小 db.userInfo.totalSize();
7、聚集集合储存空间大小 db.userInfo.storageSize();
8、Shard版本信息 db.userInfo.getShardVersion()
9、聚集集合重命名 db.userInfo.renameCollection(“users”); 将userInfo重命名为users
10、删除当前聚集集合 db.userInfo.drop();
show dbs:显示数据库列表
show collections:显示当前数据库中的集合(类似关系数据库中的表)
show users:显示用户
use :切换当前数据库,这和MS-SQL里面的意思一样
db.help():显示数据库操作命令,里面有很多的命令
db.foo.help():显示集合操作命令,同样有很多的命令,foo指的是当前数据库下,一个叫foo的集合,并非真正意义上的命令
db.foo.find():对于当前数据库中的foo集合进行数据查找(由于没有条件,会列出所有数据)
db.foo.find( { a : 1 } ):对于当前数据库中的foo集合进行查找,条件是数据中有一个属性叫a,且a的值为1